TensorFlow实战Google深度学习框架8-9章学习笔记
目录
第8章 循环神经网络
循环神经网络的主要用途是处理和预测序列数据。循环神经网络的来源就是为了刻画一个序列当前的输出与之前信息的关系。也就是说,循环神经网络的隐藏层之间的节点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出。下面给出一个长度为2的RNN前向传播示例代码:
import numpy as np X = [1,2]
state = [0.0, 0.0]
w_cell_state = np.asarray([[0.1, 0.2], [0.3, 0.4]])
w_cell_input = np.asarray([0.5, 0.6])
b_cell = np.asarray([0.1, -0.1])
w_output = np.asarray([[1.0], [2.0]])
b_output = 0.1 for i in range(len(X)):
before_activation = np.dot(state, w_cell_state) + X[i] * w_cell_input + b_cell
state = np.tanh(before_activation)
final_output = np.dot(state, w_output) + b_output
print ("before activation: ", before_activation)
print ("state: ", state) print ("output: ", final_output)
运行结果:
before activation: [0.6 0.5]
state: [0.53704957 0.46211716]
output: [1.56128388]
before activation: [1.2923401 1.39225678]
state: [0.85973818 0.88366641]
output: [2.72707101]
循环神经网络可以很好地利用传统神经网络结构不能建模的信息,但同时,这也带来了更大的技术挑战——长期依赖问题。在这些问题中,模型仅仅需要短期内的信息来执行当前的任务。但同样也会有一些上下文场景更加复杂的情况。因此,当预测位置和相关信息之间的文本间隔变得很大时,简单的循环神经网络有可能会丧失学习到距离如此远的信息的能力。或者在复杂语言场景中,有用信息的间隔有大有小、长短不一,循环神经网络的性能也会受到限制。
长短时记忆网络(LSTM)的设计就是为了解决这个问题,在很多任务上,采用LSTM结构的循环神经网络比标准的循环神经网络表现更好。LSTM是一种拥有三个门结构的特殊网络结构,分别为输入门、遗忘门和输出门。
LSTM靠一些“门”的结构让信息有选择性地影响循环神经网络中每一个时刻的状态。所谓“门”的结构就是一个使用sigmoid神经网络和一个按位做乘法的操作,这两个操作合在一起就是一个“门”的结构。之所以该结构叫做“门”,是因为使用sigmoid作为激活函数的全连接神经网络层会输出一个0到1之间的数值,描述当前输入有多少信息量可以通过这个结构。于是这个结构的功能就类似于一扇门,当门打开时(sigmoid神经网络层输出为1时),全部信息都可以通过;当门关上时(sigmoid神经网络层输出为0时),任何信息都无法通过。
第9章 自然语言处理
假设一门语言中所有可能的句子服从某一个概率分布,每个句子出现的概率加起来为1,那么”语言模型”的任务就是预测每个句子在语言中出现的概率。很多生成自然语言文本的应用都依赖语言模型来优化输出文本的流畅性,生成的句子在语言模型中的概率越高,说明其越有可能是一个流畅、自然的句子。
那么,如何计算一个句子的概率呢?首先一个句子可以被看成是一个单词序列:
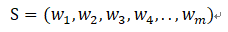
其中m为句子的长度,那么它的概率可以表示为:
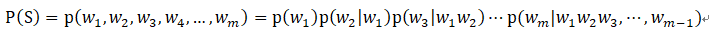
为了控制参数数量,n-gram模型做了一个有限历史假设:当前单词的出现概率仅仅于前面的n-1个单词相关,因此以上公式可以近似为:
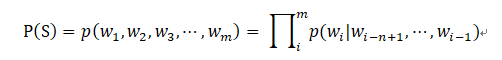
n-gram模型里的n指的是当前单词依赖它前面的单词的个数。通常n可以取1、2、3、4,其中n取1、2、3时分别称为unigram、bigram和trigram。当n越大时,n-gram模型在理论上越准确,但也越复杂,需要的计算量和训练语料数据量也就越大,因此n取大于等于4的情况非常少。
n-gram模型的参数一般采用最大似然估计(Maximum Likelihood Estimation, MLE)方法计算:
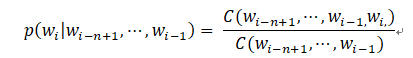
语言模型效果好坏的常用评价指标是复杂度(perplexity),在一个测试集上得到的perplexity越低,说明建模的效果越好。计算perplexity的公式如下:
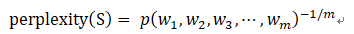
在语言模型的训练中,通常采用perplexity的对数表达形式:
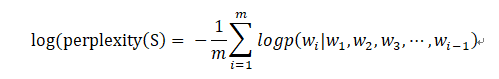
在预测下个单词时,n-gram模型只能考虑前n个单词的信息,这就对语言模型的能力造成了很大的限制。与之相比,循环神经网络可以将任意长度的上文信息存储在隐藏状态中,因此使用循环神经网络作为语言模型有着天然的优势。
基于循环神经网络的神经语言模型相比于正常的循环神经网络,在NLP的应用中主要多了两层:词向量层(embedding)和softmax层。
在输入层,每一个单词用一个实数向量表示,这个向量被称为“词向量”(word embedding)。词向量可以形象地理解为将词汇表嵌入到一个固定维度的实数空间里。将单词编号转化为词向量主要有两大作用:降低输入的维度和增加语义信息。
Softmax层的作用是将循环神经网络大的输出转化为一个单词表中每个单词的输出概率。
Seq2Seq模型的基本思想非常简单——使用一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度的编码中;再使用另一个循环神经网络读取输入句子,将整个句子的信息压缩到一个固定维度的编码中;再使另一个循环神经网络读取这个编码,将其“解压”为目标语言的一个句子。这两个循环神经网络分别称为编码器(Encoder)和解码器(Decoder),这个模型也称为encoder-decoder模型。
在Seq2Seq模型中,编码器将完整的输入句子压缩到一个维度固定的向量中,然后解码器根据这个向量生成输出句子。当输入句子较长时,这个中间向量难以存储足够的信息,就成为这个模型的一个瓶颈。注意力(“Attention”)机制就是为了解决这个问题而设计的。注意力机制允许解码器随时查阅输入句子的部分单词或片段,因此不需要在中间向量中存储所有信息。
解码器在解码的每一步将隐藏状态作为查询的输入来“查询”编码器的隐藏状态,在每个输入的位置计算一个反映与查询输入相关程度的权重,再根据这个权重对输入位置的隐藏状态求加权平均。加权平均后得到的向量称为“context”,表示它时与翻译当前单词最相关的原文信息。在解码下一个单词时,将context作为额外信息输入到循环神经网络中,这样循环神经网络可以时刻读取原文中最相关的信息,而不必完全依赖于上一时刻的隐藏状态。计算j时刻的context的方法如下:
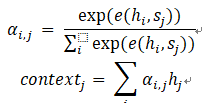
其中 是计算原文各单词与当前解码器状态的“相关度”的函数。最常用的 函数定义是一个带有单个隐藏层的前馈神经网络:
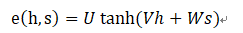
TensorFlow实战Google深度学习框架8-9章学习笔记的更多相关文章
- [Tensorflow实战Google深度学习框架]笔记4
本系列为Tensorflow实战Google深度学习框架知识笔记,仅为博主看书过程中觉得较为重要的知识点,简单摘要下来,内容较为零散,请见谅. 2017-11-06 [第五章] MNIST数字识别问题 ...
- 1 如何使用pb文件保存和恢复模型进行迁移学习(学习Tensorflow 实战google深度学习框架)
学习过程是Tensorflow 实战google深度学习框架一书的第六章的迁移学习环节. 具体见我提出的问题:https://www.tensorflowers.cn/t/5314 参考https:/ ...
- TensorFlow+实战Google深度学习框架学习笔记(5)----神经网络训练步骤
一.TensorFlow实战Google深度学习框架学习 1.步骤: 1.定义神经网络的结构和前向传播的输出结果. 2.定义损失函数以及选择反向传播优化的算法. 3.生成会话(session)并且在训 ...
- 学习《TensorFlow实战Google深度学习框架 (第2版) 》中文PDF和代码
TensorFlow是谷歌2015年开源的主流深度学习框架,目前已得到广泛应用.<TensorFlow:实战Google深度学习框架(第2版)>为TensorFlow入门参考书,帮助快速. ...
- TensorFlow实战Google深度学习框架-人工智能教程-自学人工智能的第二天-深度学习
自学人工智能的第一天 "TensorFlow 是谷歌 2015 年开源的主流深度学习框架,目前已得到广泛应用.本书为 TensorFlow 入门参考书,旨在帮助读者以快速.有效的方式上手 T ...
- TensorFlow实战Google深度学习框架1-4章学习笔记
目录 第1章 深度学习简介 第2章 TensorFlow环境搭建 第3章 TensorFlow入门 第4章 深层神经网络 第1章 深度学习简介 对于许多机器学习问题来说,特征提取不是一件简单的事情 ...
- TensorFlow实战Google深度学习框架10-12章学习笔记
目录 第10章 TensorFlow高层封装 第11章 TensorBoard可视化 第12章 TensorFlow计算加速 第10章 TensorFlow高层封装 目前比较流行的TensorFlow ...
- TensorFlow实战Google深度学习框架5-7章学习笔记
目录 第5章 MNIST数字识别问题 第6章 图像识别与卷积神经网络 第7章 图像数据处理 第5章 MNIST数字识别问题 MNIST是一个非常有名的手写体数字识别数据集,在很多资料中,这个数据集都会 ...
- Tensorflow实战Google深度学习框架-总结-1
第一章:深度学习简介 1⃣️应用有 1.计算机视觉 2.语音识别 3.自然语言处理 4.人机博弈 2⃣️深度学习,机器学习,AI 的关系
- TensorFlow+实战Google深度学习框架学习笔记(10)-----神经网络几种优化方法
神经网络的优化方法: 1.学习率的设置(指数衰减) 2.过拟合问题(Dropout) 3.滑动平均模型(参数更新,使模型在测试数据上更鲁棒) 4.批标准化(解决网络层数加深而产生的问题---如梯度弥散 ...
随机推荐
- shell基本用法
shell是一个命令行解释器,它接收应用程序/ 用户命令,然后调用操作系统内核:功能强大的编程语言: 1. Shell解析器 Linux提供的Shell解析器有: [kris@hadoop datas ...
- hdu 3078 Network (暴力)+【LCA】
<题目链接> 题目大意:给定一颗带点权的树,进行两种操作,k=0,更改某一点的点权,k!=0,输出a~b路径之间权值第k大的点的点权. 解题分析:先通过RMQ的初始化,预处理pre[]数组 ...
- 用单向链表实现两数倒序相加(java实现)
很久没做算法题了,准备重操旧业,于是刷了一波LeetCode,看到一个比较经典的链表算法题,分享出来. 题目 给定两个非空链表来表示两个非负整数.位数按照逆序方式存储,它们的每个节点只存储单个数字.将 ...
- Java内存管理-你真的理解Java中的数据类型吗(十)
勿在流沙筑高台,出来混迟早要还的. 做一个积极的人 编码.改bug.提升自己 我有一个乐园,面向编程,春暖花开! 作为Java程序员,Java 的数据类型这个是一定要知道的! 但是不管是那种数据类型最 ...
- staff
staff英 [stɑ:f] 四大服. 美 [stæf] n.参谋;全体职员;管理人员;权杖adj.职员的;行政工作的;参谋的;作为正式工作人员的v.在…工作;为…配备职员;任职于第三人称单数: st ...
- SpringBoot整合Mybatis完整详细版
记得刚接触SpringBoot时,大吃一惊,世界上居然还有这么省事的框架,立马感叹:SpringBoot是世界上最好的框架.哈哈! 当初跟着教程练习搭建了一个框架,传送门:spring boot + ...
- 2006 ACM 求奇数的和
题目:http://acm.hdu.edu.cn/showproblem.php?pid=2006 注意 sum=1,写在while 不然每次结果会累积 #include <stdio.h> ...
- Android应用的内存管理
管理应用的内存可以分为两个部分内容: 1. 首先需要理解:How Android Manages App Processes and Memory Allocation? 2. 其次需要考虑:我们设计 ...
- 纯js上传文件 很好用
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <meta name ...
- windows提交代码到git仓库
进入git bash git config --global user.name '仓库名' git config --global user.email '2531099@163.com' git ...