初始Hbase
Hbase
定义
HBase是一个开源的非关系型分布式数据库(NoSQL),它参考了谷歌的BigTable建模,实现 的编程语言为 Java。
是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,因此可以容错地存 储海量稀疏的数据
特点
高可靠
高并发读写
面向列
可伸缩
易构建
行存储
优点:写入一次性完成,保持数据完整性
缺点:数据读取过程中产生冗余数据,若有少量数据可以忽略
列存储
优点:读取过程,不会产生冗余数据,特别适合对数据完整性要求不高的大数据领域
缺点:写入效率差,保证数据完整性方面差
优势
海量数据存储
快速随机访问
大量写操作的应用
互联网搜索引擎数据存储
海量数据写入
消息中心
内容服务系统(schema-free)
大表复杂&多维度索引
大批量数据读取
数据模型
| 行键 | 时间戳 | 列族contents | 列族anchor | 列族mime |
|---|---|---|---|---|
| “com.cnn.www” | t9 | anchor:cnnsi.com="CNN" | ||
| t8 | anchor:my.look.ca="CNN.com" | |||
| t6 | contents:html="" | mime:type="text/html" | ||
| t5 | contents:html="" | |||
| t3 | contents:html="" |
RowKey:是Byte array,是表中每条记录的“主键”,方便快速查找,Rowkey的设计非常重要。
Column Family:列族,拥有一个名称(string),包含一个或者多个相关列
Column:属于某一个columnfamily,familyName:columnName,每条记录可动态添加
Version Number:类型为Long,默认值是系统时间戳,可由用户自定义
Value(Cell):Byte array
三维有序
{rowkey => {family => {qualifier => {version => value}}}}
a:cf1:bar:1368394583:7
a:cf1:foo:1368394261:hello
物理模型
Hbase一张表由一个或多个 Hregion组成
记录之间按照Row Key的字典 序排列
Region按大小分割的,每个表 一开始只有一个region,随着 数据不断插入表,region不断 增大,当增大到一个阀值的时 候,Hregion就会等分会两个 新的Hregion。当table中的行 不断增多,就会有越来越多的 Hregion。
表 -> HTable
按RowKey范围分的Region-> HRegion ->Region Servers
HRegion按列族(Column Family) ->多个HStore
HStore -> memstore + HFiles(均为有序的KV)
HFiles -> HDFS
HRegion是Hbase中分布式存 储和负载均衡的最小单元
最小单元就表示不同的 Hregion可以分布在不同的 HRegion server上。
但一个Hregion是不会拆分到 多个server上的。
HRegion虽然是分布式存储的 最小单元,但并不是存储的最 小单元。
系统架构
Client
访问Hbase的接口,并维护Cache加速Region Server的访问
Master
负载均衡,分配Region到RegionServer
DDL:增删改-> table,cf,namespace
类似namenode,管理一些元数据,table
ACL权限控制
Region Server
管理和存储本地的HRegion
维护Region,负责Region的IO请求
本地化:HRegion的数据尽量和数据所属的DataNode在一块,但是这个本地化不能够总是满足和实现
Zookeeper
保证集群中只有一个Master
存储所有Region的入口(ROOT)地址
实时监控Region Server的上下线信息,并通知Master
系统架构图


容错
ZooKeeper协调集群所有节点的共享信息,在HMaster和HRegionServer连接到ZooKeeper后 创建Ephemeral节点,并使用Heartbeat机制维持这个节点的存活状态,如果某个Ephemeral节 点实效,则HMaster会收到通知,并做相应的处理。

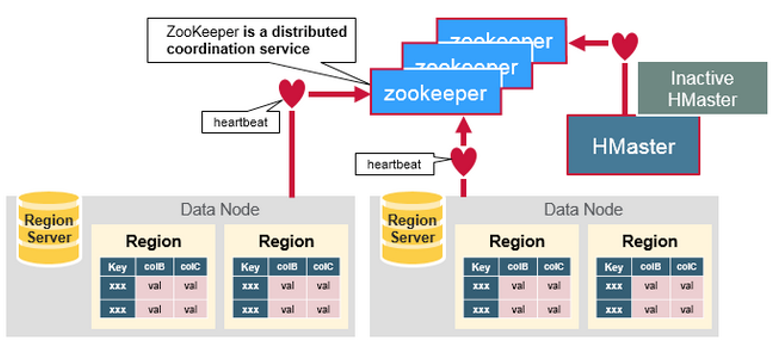
除了HDFS存储信息,HBase还在Zookeeper中存储信息,其中的znode信息:
– /hbase/root-region-server ,Root region的位置
– /hbase/table/-ROOT-,根元数据信息
– /hbase/table/.META.,元数据信息
– /hbase/master,当选的Mater
– /hbase/backup-masters,备选的Master
– /hbase/rs ,Region Server的信息
– /hbase/unassigned,未分配的Region
Master容错
Zookeeper重新选择一个新的Master
无Master过程中,数据读取仍照常进行;
无master过程中,region切分、负载均衡等无法进行
Region Server容错
定时向Zookeeper汇报心跳,如果一旦时间内未出现心跳,Master将该RegionServer上的 Region重新分配到其他RegionServer上,失效服务器上“预写”日志由主服务器进行分割 并派送给新的RegionServer
Zookeeper容错
Zookeeper是一个可靠地服务,一般配置3或5个Zookeeper实例
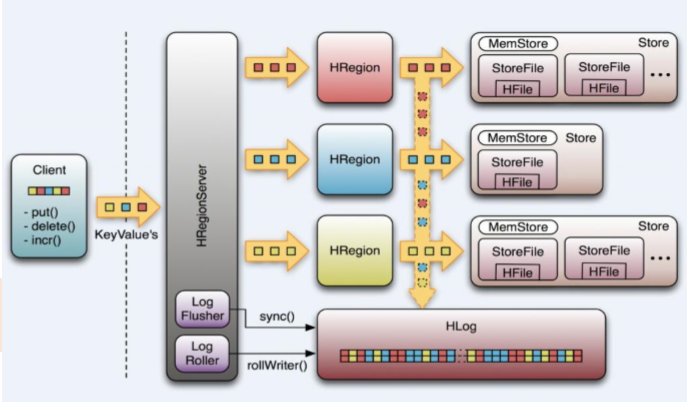
WAL(Write-Ahead-Log)预写日志
是Hbase的RegionServer在处 理数据插入和删除的过程中用 来记录操作内容的一种日志
在每次Put、Delete等一条记录 时,首先将其数据写入到 RegionServer对应的HLog文件的过程
客户端往RegionServer端提交数据的时候,会写WAL日志,只有当WAL日志写成功以后,客户端才会被告诉 提交数据成功,如果写WAL失败会告知客户端提交失败
数据落地的过程
在一个RegionServer上的所有的Region都共享一个 HLog,一次数据的提交是先写WAL,写入成功后,再 写memstore。当memstore值到达一定阈值,就会形 成一个个StoreFile(理解为HFile格式的封装,本质上 还是以HFile的形式存储的)

操作
基本的单行操作:PUT,GET,DELETE
扫描一段范围的Rowkey: SCAN
– 由于Rowkey有序而让Scan变得有效
GET和SCAN支持各种Filter,将逻辑推给Region Server – 以此为基础可以实现复杂的查询
支持一些原子操作:INCREMENT、APPEND、CheckAnd{Put,Delete}
MapReduce
注:在单行上可以加锁,具备强一致性。这能满足很多应用的需求。
特殊表
-ROOT- 表和.META.表是两个比较特殊的表


.META.记录了用户表的 Region信息,.META.可以有多个regoin
-ROOT-记录了.META.表的 Region信息,-ROOT-只有一 个region,Zookeeper中记录 了-ROOT-表的location
Hbase 0.96之后去掉了-ROOT- 表,因为: – 三次请求才能直到用户Table真正所在的位置也是性能低下的 – 即使去掉-ROOT- Table,也还可以支持2^17(131072)个Hregion,对于集群来说,存 储空间也足够
所以目前流程为:
– 从ZooKeeper(/hbase/meta-region-server)中获取hbase:meta的位置( HRegionServer的位置),缓存该位置信息
– 从HRegionServer中查询用户Table对应请求的RowKey所在的HRegionServer,缓存该 位置信息
– 从查询到HRegionServer中读取Row。
写入流程
寻址
从这个过程中,我们发现客户会缓存 这些位置信息,然而第二步它只是缓 存当前RowKey对应的HRegion的位 置,因而如果下一个要查的RowKey 不在同一个HRegion中,则需要继续 查询hbase:meta所在的HRegion, 然而随着时间的推移,客户端缓存的 位置信息越来越多,以至于不需要再 次查找hbase:meta Table的信息,除 非某个HRegion因为宕机或Split被移 动,此时需要重新查询并且更新缓存

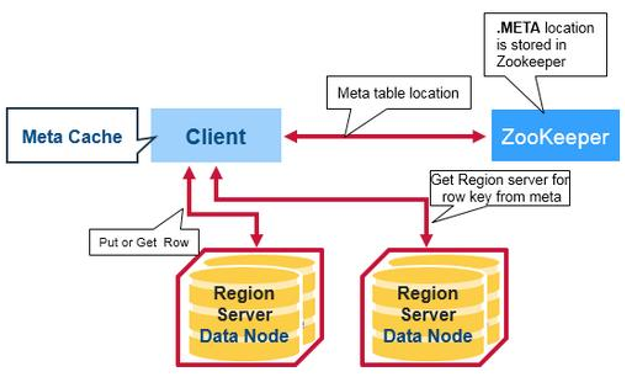
hbase:meta表存储了所有用户HRegion的位置信息


写入流程
当客户端发起一个Put请求时,首先它从hbase:meta表中查出该Put数据最终需要去的 HRegionServer。然后客户端将Put请求发送给相应的HRegionServer,在HRegionServer中 它首先会将该Put操作写入WAL日志(Flush到磁盘中)。
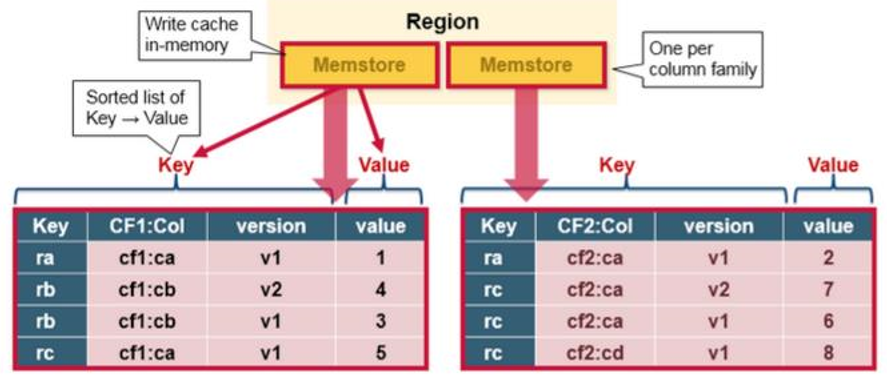
Memstore是一个写缓存,每一个Column Family有一个自己的MemStore

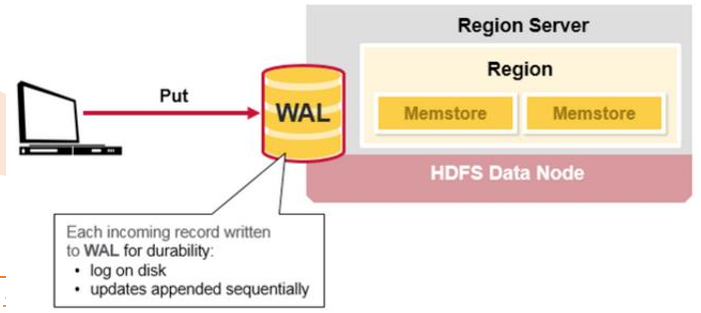
写完WAL日志文件后,HRegionServer根据Put中的TableName和RowKey找到对应的 HRegion,并根据Column Family找到对应的HStore,并将Put写入到该HStore的MemStore 中。此时写成功,并返回通知客户端

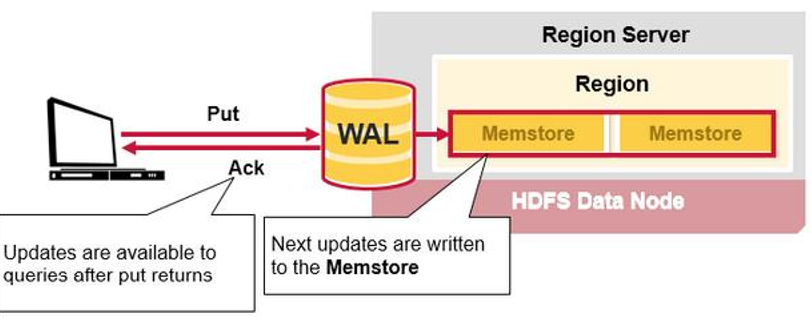
MemStore是一个In Memory Sorted Buffer,在每个HStore中都有一个MemStore,即它是 一个HRegion的一个Column Family对应一个实例。它的排列顺序以RowKey、Column Family、Column的顺序以及Timestamp的倒序。

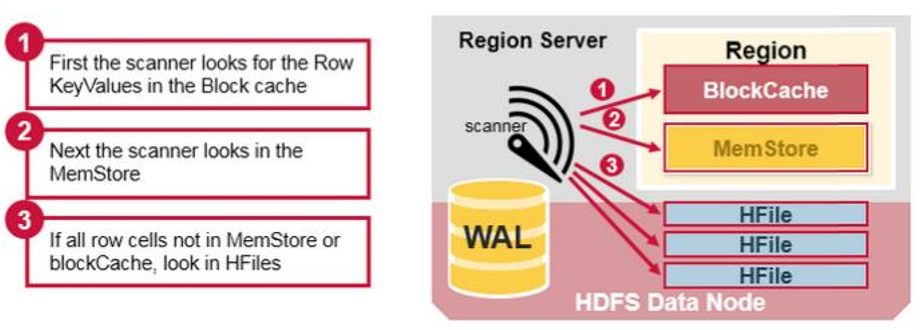
读取流程

HBase中扫瞄的顺序依次是:BlockCache、MemStore、StoreFile(HFile)

Compaction和Split
问题:随着写入不断增多,flush次数不断增多,Hfile文件越来越多,所以Hbase需要对这些文件进行 合并
Compaction会从一个region的一个store中选择一些hfile文件进行合并。合并说来原理很简单,先 从这些待合并的数据文件中读出KeyValues,再按照由小到大排列后写入一个新的文件中。之后,这 个新生成的文件就会取代之前待合并的所有文件对外提供服务 。
Minor Compaction:是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在 这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大 的StoreFile 。
Major Compaction:是指将所有的StoreFile合并成一个StoreFile,这个过程还会清理三类无意义 数据:被删除的数据、TTL过期数据、版本号超过设定版本号的数据 。
Major Compaction时间会持续比较长,整个过程会消耗大量系统资源,对上层业务有比较大的影响 。因此线上业务都会将关闭自动触发Major Compaction功能,改为手动在业务低峰期触发。
Compaction本质:使用短时间的IO消耗以及带宽消耗换取后续查询的低延迟 。
compact的速度远远跟不上HFile生成的速度,这样就会使HFile的数量会越来越多,导致读性 能急剧下降。为了避免这种情况,在HFile的数量过多的时候会限制写请求的速度。
Split – 当一个Region太大时,将其分裂成两个Region 。
Split和Major Compaction可以手动或者自动做。
初始Hbase的更多相关文章
- HBase篇--初始Hbase
一.前述 1.HBase,是一个高可靠性.高性能.面向列.可伸缩.实时读写的分布式数据库.2.利用Hadoop HDFS作为其文件存储系统,利用Hadoop MapReduce来处理HBase中的海量 ...
- 用Hbase存储Log4j日志数据:HbaseAppender
业务需求: 需求很简单,就是把多个系统的日志数据统一存储到Hbase数据库中,方便统一查看和监控. 解决思路: 写针对Hbase存储的Log4j Appender,有一个简单的日志储存策略,把Log4 ...
- hbase官方文档(转)
FROM:http://www.just4e.com/hbase.html Apache HBase™ 参考指南 HBase 官方文档中文版 Copyright © 2012 Apache Soft ...
- HBase官方文档
HBase官方文档 目录 序 1. 入门 1.1. 介绍 1.2. 快速开始 2. Apache HBase (TM)配置 2.1. 基础条件 2.2. HBase 运行模式: 独立和分布式 2.3. ...
- Nutch相关框架安装使用最佳指南(转帖)
Nutch相关框架安装使用最佳指南 Chinese installing and using instruction - The best guidance in installing and u ...
- hbase协处理器编码实例
Observer协处理器通常在一个特定的事件(诸如Get或Put)之前或之后发生,相当于RDBMS中的触发器.Endpoint协处理器则类似于RDBMS中的存储过程,因为它可以让你在RegionSer ...
- 设计与开发一款简单易用的Web报表工具(支持常用关系数据及hadoop、hbase等)
EasyReport是一个简单易用的Web报表工具(支持Hadoop,HBase及各种关系型数据库),它的主要功能是把SQL语句查询出的行列结构转换成HTML表格(Table),并支持表格的跨行(Ro ...
- HBASE数据模型&扩展和负载均衡理论
示例数据模型 HBase中扩展和负载均衡的基本单元成为region,region本质上是以行健排序的连续存储区间.如果region太大,系统会把它们 自动拆分,相反的,就是把多个region合并,以减 ...
- HBase自动分区
HBase扩展和负载均衡的基本单位是Region.Region从本质上说是行的集合.当Region的大小达到一定的阈值,该Region会自动分裂(split),当然也可能是合并(merge),合并可以 ...
随机推荐
- CH#56C 异象石
一道LCA 原题链接 先跑一边\(dfs\),求出每个节点的时间戳,如果我们将有异象石的节点按时间戳从小到大的顺序排列,累加相邻两节点之间的距离(首尾相邻),会发现总和就是答案的两倍. 于是我们只需要 ...
- PS制作纸质复古野外露营插画分享
经常有人说一些复古风,就觉得蛮难,其实制作过程其实没有想象中复杂,从1850年到2017年,通过这160多年里的平面设计,给我们的作品添加上一些新鲜的灵感和活力,本次教程就来教大家用PS做出耐看的纸质 ...
- swift textfiled 输入完毕 return 隐藏键盘 方法
学习swift 真是件头疼的事情 会的人少,又没有OC基础,所以 且学切珍惜吧. 在做登录的时候发现textfiled 自动调用键盘后不能隐藏?头疼 ~~~~询问了好多人 终于有人自写解答 为了方便后 ...
- 条件随机场_CRF
无向图 举例:“Bob drank coffee at Starbucks” 标记方式1:(名词,动词,名词,介词,名词) 称为l 标记方式2:(名词,动词,动词,介词,名词) 挑选出一个最靠谱的: ...
- 如何获取堆的dump 的信息,如何分析
获取方式: 1. jdk 自带启动参数 -XX:+HeapDumpBeforeFullGC -XX:HeapDumpPath=/x/x 产生dump日志,然后用visualVm分析 2. jmap 命 ...
- ServiceDesk Plus更有序地组织IT项目
- MySQL查找SQL耗时瓶颈 SHOW profiles
http://blog.csdn.net/k_scott/article/details/8804384 1.首先查看是否开启profiling功能 SHOW VARIABLES LIKE '%pro ...
- 27、Label 自适应文本 xib
第一步: 第二步: 第三步: 第四步:
- mysql之索引查询2
一 索引的创建 索引减慢了 写的操作,优化了读取的时间 index:普通索引,加速了查找的时间. fulltext:全文索引,可以选用占用空间非常大的文本信息的字段作为索引的字段.使用fulltext ...
- oracle 导出表
由于进项目组是跟着dba做事情的,但是没做多久dba走了,差不多就把数据库方面的“杂事”接下来了. 小白一个,只有敬小慎微的操作.经常看到的高水位和低水位的情况,也不敢去乱动. 搞好今天晚上需要跑数据 ...