学好Python不加班系列之SCRAPY爬虫框架的使用
scrapy是一个爬虫中封装好的一个明星框架。具有高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
对于初学者来说还是需要有一定的基础作为铺垫的学习。我将从下方的思维导图中进行逐步的解析讲述。
实验工具即环境:
笔记本:Y9000X 2020
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
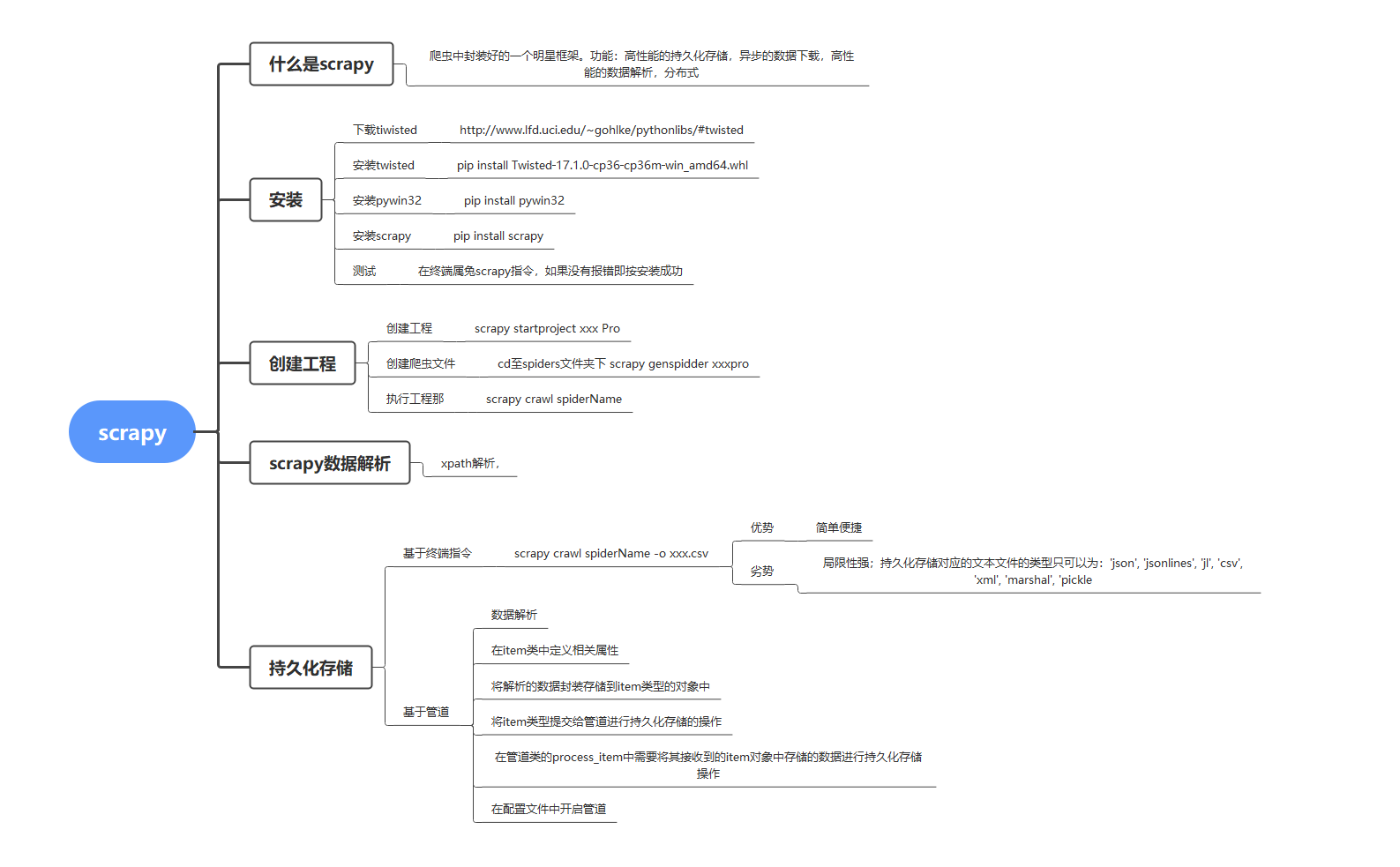
一、安装
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载好后打开终端进行安装scrapy的必要模块
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
安装scrapy:pip install scrapy
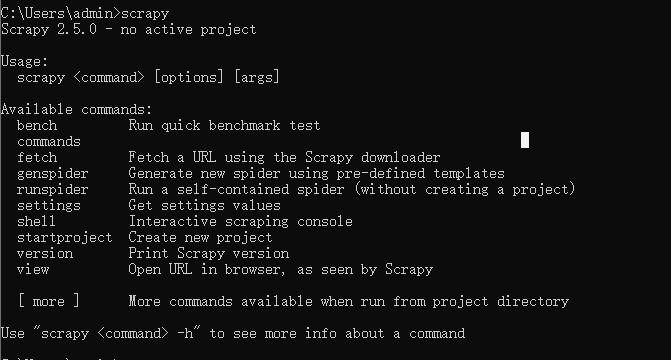
安装完成后在终端输入scrapy如果没有报错即安装成功。
二、创建scrapy的工程
在pycharm中创建好的项目中的中终端输入
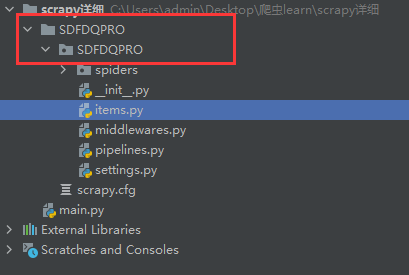
scrapy startproject SDFDQPRO

检查下项目目录即可发现多出了如下的工程目录
三、创建一个爬虫目录
在终端找到之前所创建的工程目录,在此目录下输入scrapy genspider sdfdq_cj http://www.csrc.gov.cn/pub/shandong/
后方网站为中国证券监督管理委员会山东监管局。

运行后可发现工程目录中多出一个名为sdfdq_cj.py的爬虫文件。
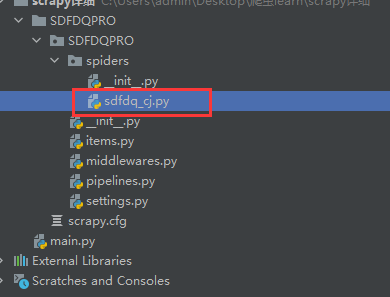
进入到爬虫文件中可以看到如下代码
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
pass
接下来对网站解析选取需要获取的内容
四、数据解析
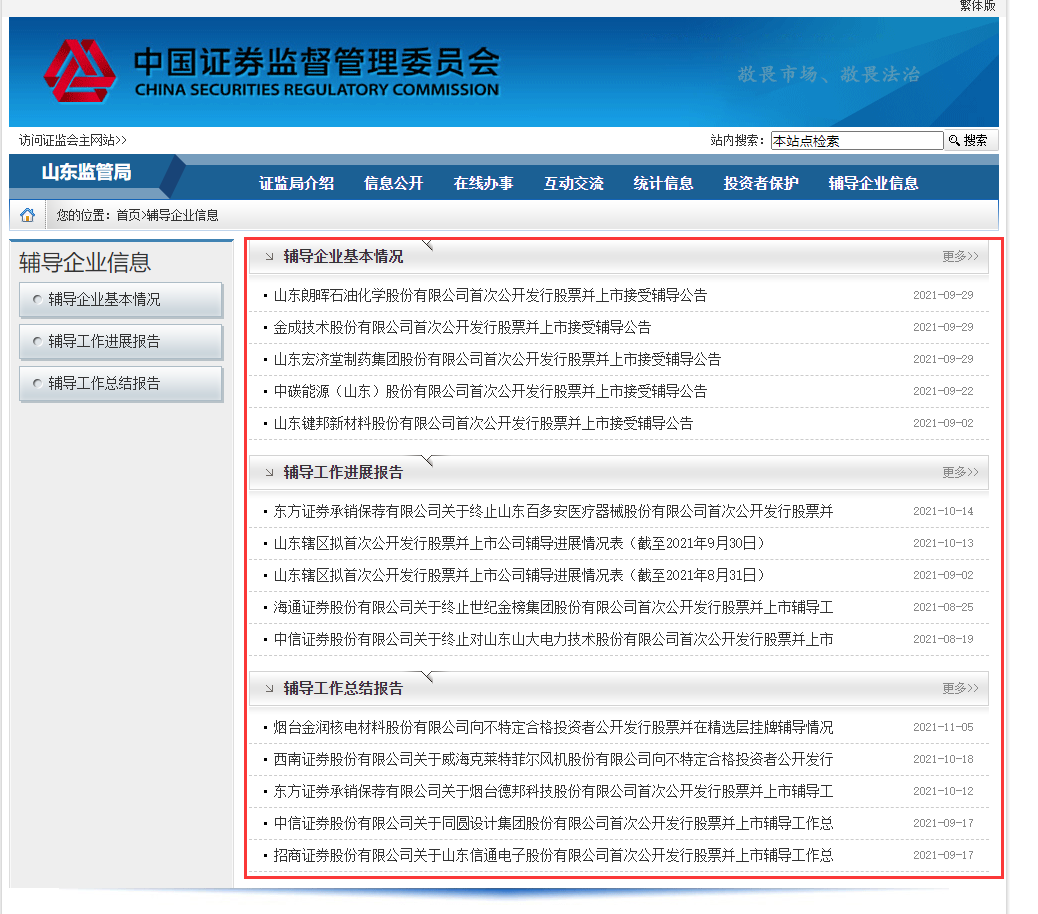
通过对网站的查看可以看出我们需要的是辅导期中的企业基本情况、工作进展报告、工作总结总的标题,日期以及链接。
scrapy对网站的解析沿用了xpath的解析方式。
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response): li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
print('title',title)
print('url',url)
print('date',date)
对网站的内容解析后运行scrapy 终端输入 scrapy crawl sdfdq_cj 注意:此语句的运行目录

可以看到我们想获取的内容:
内容获取到我们必须要将其持久化存储才有意义:
五、scrapy的持久化存储
1)基于指令的持久化存储:
要求:只可以将parse的方法返回值存储到本地的文本文件中
def parse(self, response):
# 创建一个列表接收获取的数据
all_data = []
li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
# 基于终端指令的持久化存储操作
dic = {
'title':title,
'url':url,
'date':date
}
all_data.append(dic)
return all_data
接下来在终端中输入 scrapy crawl sdfdq_cj -o ./sdfdq.csv
将获取的文本内容存储到对应路径下的sdfdq.csv文本文件中

2)基于管道的持久化存储
明天更。。。。。。。。。
学好Python不加班系列之SCRAPY爬虫框架的使用的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
随机推荐
- 你说要你想玩爬虫,但你说你不懂Python正则表达式,我信你个鬼,那你还不来看看?
前言 正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配. re 模块也提供了与这些方法功能完全一致的函数,这些函数使用一个模式字符串做为它们的第一个参数. re.mat ...
- Jmeter压测学习3---通过正则表达式提取token
上一个随笔记录的是用json提取器提取token,这个随笔记录用正则表达式提取token 一.添加正则表达式 登录右击添加->后置处理器->正则表达式提取器 正则提取器参数说明: 要检查的 ...
- Kubernetes client-go Indexer / ThreadSafeStore 源码分析
Kubernetes client-go Indexer / ThreadSafeStore 源码分析 请阅读原文:原文地址 Contents 概述 Indexer 接口 ThreadSafe ...
- Win32窗口框架
Win32窗口框架 WindowClass 单例,负责窗口初始化注册和取消注册: 负责提供静态方法: 放在Window类内部,方便初始化时,wndProc(HandleMsgSetup)的赋值: cl ...
- 移动端多个DIV简单拖拽功能
移动端多个DIV简单拖拽功能. 这个demo与之前写的一个例子差不了多少,只是这个多了一层遍历而已. <!DOCTYPE html> <html lang="en" ...
- C 标准库函数手册摘要
<stdlib.h> int abs( int value ); long int labs( long int value ); 返回参数的绝对值 int rand( void ); v ...
- Go语言核心36讲(Go语言进阶技术二)--学习笔记
08 | container包中的那些容器 我们在上次讨论了数组和切片,当我们提到数组的时候,往往会想起链表.那么 Go 语言的链表是什么样的呢? Go 语言的链表实现在标准库的container/l ...
- 时间轮机制在Redisson分布式锁中的实际应用以及时间轮源码分析
本篇文章主要基于Redisson中实现的分布式锁机制继续进行展开,分析Redisson中的时间轮机制. 在前面分析的Redisson的分布式锁实现中,有一个Watch Dog机制来对锁键进行续约,代码 ...
- 初学Python-day10 函数2
函数 1.函数也是一种数据 函数也是一种数据,可以使用变量保存 回调函数(参数的值还是一个函数) 实例: def test(): print('hello world') def test1(a): ...
- 【UE4 C++】绘制函数 Debug drawing functions
基于UKismetSystemLibrary /** Draw a debug line */ UFUNCTION(BlueprintCallable, Category="Renderin ...