MapReduce框架原理-Writable序列化
序列化和反序列化
序列化就是把内存中的对象,转换成字节序列(或其他数据传输协议)以便于存储(持久化)和网络传输。
反序列化就是将收到字节序列(或其他数据传输协议)或者是硬盘的持久化数据,转换成内存中的对象。
主要作用是将MR中产生的数据以序列化类型在网络中、不同的电脑中进行数据传递
引入序列化的原因
一般来说,"活的" 对象只生存在内存里,关机断电就没有了。而且"活的"对象只能由本地的进程使用,不能被发送到网络上的另外一台计算机。然而序列化可以存储"活的" 对象,可以将"活的"对象发送到远程计算机,方便分布式处理
Java序列化和大数据序列化的区别
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,header,继承体系等),不便于在网络中高效传输。所以,hadoop自己开发了一套序列化机制(Writable),精简、高效。
Hadoop序列化特点:
- 紧凑:高效使用存储空间。
- 快速:读写数据的额外开销小。
- 可扩展:随着通信协议的升级而可升级
- 互操作:支持多语言的交互
常用数据序列化类型
|
Java类型 |
Hadoop Writable类型 |
|
boolean |
BooleanWritable |
|
byte |
ByteWritable |
|
int |
IntWritable |
|
float |
FloatWritable |
|
long |
LongWritable |
|
double |
DoubleWritable |
|
string |
Text |
|
map |
MapWritable |
|
array |
ArrayWritable |
案例实操
需求
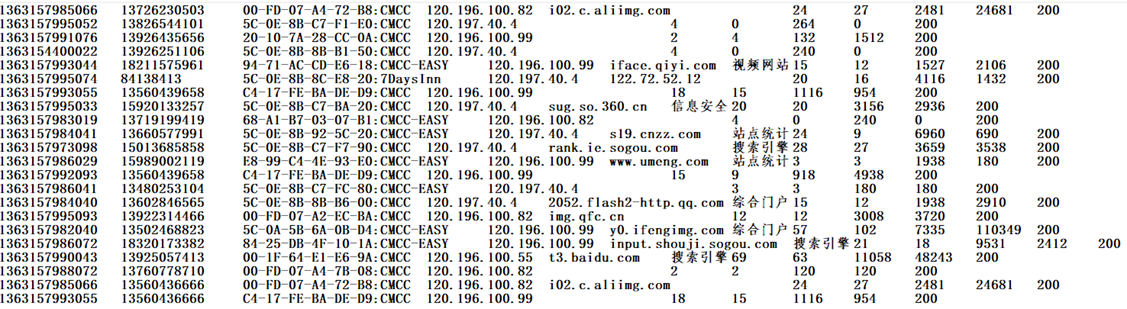
计算每一个手机号总的上行流量、总的下行流量、总流量
环境准备
在HDFS上的 /school 目录下有 phone_data.txt 文件,该文件中记录有手机号的上行流量、下行流量
其中:上行流量:倒数第三列;下行流量:倒数第二列
思路分析
- Map阶段:
读取到每一行数据,将每一行中的数据的手机号、上行流量、下行流量获取出来。
map阶段在去输出中间键值对数据的时候,应该以手机号为key,以上行流量和下行流量为value,发送给reduce
- Reduce阶段:
reduce根据手机号(key)将这个手机对应的所有上行流量和下行流量获取到,累加即可
其中通过实现自定义的bean来封装流量信息,并将bean作为map输出的value来传输
源代码
DataCountMapper.java
public class DataCountMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] fields = line.split("\t");
FlowBean flowBean = new FlowBean();
String phone = fields[1];
int upFlow = Integer.parseInt(fields[fields.length - 3]);
int downFlow = Integer.parseInt(fields[fields.length - 2]);
flowBean.setPhone(phone);
flowBean.setUpFlow(upFlow);
flowBean.setDownFlow(downFlow);
/**
* 将数据以手机号为key,flowBean对象为value写出到reduce
*/
context.write(new Text(phone), flowBean);
}
}
DataCountReducer.java
public class DataCountReducer extends Reducer<Text, FlowBean, NullWritable, FlowBean> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
Iterator<FlowBean> iterator = values.iterator();
int upSum = 0;
int downSum = 0;
while (iterator.hasNext()) {
FlowBean bean = iterator.next();
upSum += bean.getUpFlow();
downSum += bean.getDownFlow();
}
int sum = upSum + downSum;
FlowBean flowBean = new FlowBean();
flowBean.setPhone(key.toString());
flowBean.setUpFlow(upSum);
flowBean.setDownFlow(downSum);
flowBean.setSumFlow(sum);
context.write(NullWritable.get(), flowBean);
}
}
DataCountDriver.java
public class DataCountDriver {
public static void main(String[] args) throws Exception {
// 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 设置jar包
job.setJarByClass(DataCountDriver.class);
// 关联Mapper和Reducer
job.setMapperClass(DataCountMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setReducerClass(DataCountReducer.class);
job.setOutputKeyClass(NullWritable.class);
job.setOutputValueClass(FlowBean.class);
// 管理文件的输入和文件的输出
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.218.55:9000/school/phone_data.txt"));
Path output = new Path("hdfs://192.168.218.55:9000/test/phone_data");
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.218.55:9000"), conf, "root");
if (fs.exists(output)) {
fs.delete(output, true);
}
FileOutputFormat.setOutputPath(job, output);
// 提交运行
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
FlowBean.java
public class FlowBean implements Writable {
/**
* JavaBean对象主要目的是为了封装手机号的上行流量和下行流量,然后在Map阶段当做key-value键值对的value输出到Reduce阶段
*/
private String phone;
private int upFlow;
private int downFlow;
private int sumFlow;
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public int getUpFlow() {
return upFlow;
}
public void setUpFlow(int upFlow) {
this.upFlow = upFlow;
}
public int getDownFlow() {
return downFlow;
}
public void setDownFlow(int downFlow) {
this.downFlow = downFlow;
}
public int getSumFlow() {
return sumFlow;
}
public void setSumFlow(int sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return "FlowBean{" +
"phone='" + phone + '\'' +
", upFlow=" + upFlow +
", downFlow=" + downFlow +
", sumFlow=" + sumFlow +
'}';
}
/**
* 序列化方法:将Java对象的属性值怎么序列化写出
* @param dataOutput
* @throws IOException
*/
@Override
public void write(DataOutput dataOutput) throws IOException {
// 将一个String类型的属性序列化写出成二进制数据
dataOutput.writeUTF(this.phone);
// 将一个String类型的属性序列化写出成二进制数据
dataOutput.writeInt(upFlow);
dataOutput.writeInt(downFlow);
dataOutput.writeInt(sumFlow);
}
/**
* 反序列化方法:怎么将二进制代码转成JavaBean对象属性的值
* 反序列化的时候,读取二进制数据时,不能随便读
* 序列化写出时先写出哪个属性的值,就先读哪个属性值
* @param dataInput
* @throws IOException
*/
@Override
public void readFields(DataInput dataInput) throws IOException {
this.phone = dataInput.readUTF();
this.upFlow = dataInput.readInt();
this.downFlow = dataInput.readInt();
this.sumFlow = dataInput.readInt();
}
}
Notes:
FlowBean是无法直接当做MR程序的key-value键值对的,除非JavaBean对象是hadoop的一个序列化对象
1. 让自定义的JavaBean对象实现一个借口:Writable(Hadoop的序列化接口,实现了这个接口,这个JavaBean对象就可以实现序列化)
2. 重写接口中的两个方法:①序列化的方法---怎么将对象序列化成二进制; ②反序列化的方法---怎么将二进制转成JavaBean对象
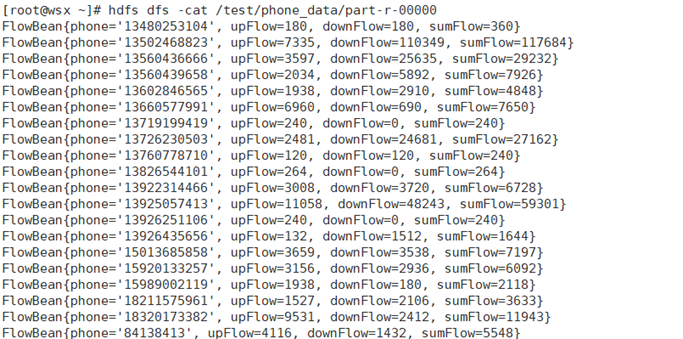
运行截图
总结
如果我们想用一个自定义的JavaBean对象去充当MR程序的key-value键值对的输入和输出,那么JavaBean对象必须实现Hadoop的序列化机制 :
- 实现接口Writable
- 重写write方法---序列化方法,将Java对象的属性值序列化写出
- 重写readFields方法---反序列化方法,将二进制数据反序列化成JavaBean对象的属性值
要求:反序列化的顺序必须是write方法写出数据的顺序
- 如果我们reduce阶段也是输出的JavaBean对象,那么在文件当中数据的格式就是JavaBean对象的toString()方法
MapReduce框架原理-Writable序列化的更多相关文章
- Hadoop(12)-MapReduce框架原理-Hadoop序列化和源码追踪
1.什么是序列化 2.为什么要序列化 3.为什么不用Java的序列化 4.自定义bean对象实现序列化接口(Writable) 在企业开发中往往常用的基本序列化类型不能满足所有需求,比如在Hadoop ...
- java大数据最全课程学习笔记(6)--MapReduce精通(二)--MapReduce框架原理
目前CSDN,博客园,简书同步发表中,更多精彩欢迎访问我的gitee pages 目录 MapReduce精通(二) MapReduce框架原理 MapReduce工作流程 InputFormat数据 ...
- MapReduce框架原理
MapReduce框架原理 3.1 InputFormat数据输入 3.1.1 切片与MapTask并行度决定机制 1.问题引出 MapTask的并行度决定Map阶段的任务处理并发度,进而影响到整个J ...
- Writable序列化
序列化:将内存中的对象 转换成字节序列以便于存储在磁盘上或者用于网络传输. 反序列化:将磁盘或者从网络中接受到的字节序列,装换成内存中的对象. 自定义bean对象(普通java对象)要想序列化传输,必 ...
- Hadoop(18)-MapReduce框架原理-WritableComparable排序和GroupingComparator分组
1.排序概述 2.排序分类 3.WritableComparable案例 这个文件,是大数据-Hadoop生态(12)-Hadoop序列化和源码追踪的输出文件,可以看到,文件根据key,也就是手机号进 ...
- MapReduce 框架原理
1. Hadoop 序列化 1.1 自定义Bean对象实现序列化接口 必须实现 Writable 接口: 反序列化时,需要反射调用空参构造函数,所以必须有空参构造: 重写序列化方法: 重写反序列化方法 ...
- MapReduce之Writable相关类
当要在进程间传递对象或持久化对象的时候,就需要序列化对象成字节流,反之当要将接收到或从磁盘读取的字节流转换为对象,就要进行反序列化.Writable是Hadoop的序列化格式,Hadoop定义了这样一 ...
- Hadoop(17)-MapReduce框架原理-MapReduce流程,Shuffle机制,Partition分区
MapReduce工作流程 1.准备待处理文件 2.job提交前生成一个处理规划 3.将切片信息job.split,配置信息job.xml和我们自己写的jar包交给yarn 4.yarn根据切片规划计 ...
- 为什么hadoop中用到的序列化不是java的serilaziable接口去序列化而是使用Writable序列化框架
继上一个模块之后,此次分析的内容是来到了Hadoop IO相关的模块了,IO系统的模块可谓是一个比较大的模块,在Hadoop Common中的io,主要包括2个大的子模块构成,1个是以Writable ...
随机推荐
- 14、redis安装及数据类型
14.0.服务器配置: 服务器名称 ip地址 controller-node1 172.16.1.90 14.1.什么是redis: 1.redis的特点: (1)redis是一个开源的使用c语言编写 ...
- 校门外的树 (Vijos P1448)
题目链接 描述 校门外有很多树,有苹果树,香蕉树,有会扔石头的,有可以吃掉补充体力的-- 如今学校决定在某个时刻在某一段种上一种树,保证任一时刻不会出现两段相同种类的树,现有两个操作: K=1,K=1 ...
- uniapp 微信小程序 打开文件
uni.downloadFile({ url: item.url, success: (res) => { if (res.statusCode === 200) { uni.openDocum ...
- 开始前端三大基础的js之途
初识 js ...
- springboot项目启动,停止,重启
参考博客 https://www.cnblogs.com/c-h-y/p/10460061.html 打包插件,可以指定启动类 <build> <plugins> <pl ...
- MySQL 查看命令执行时间
查看执行时间 1 show profiles; 2 show variables like "%pro%";查看profiling 是否是on状态: 3 如果是off,则执行se ...
- PHP递归创建多级目录(一道面试题的解题过程)(转)
今天看到一道面试题,要写出一个可以创建多级目录的函数: 我的第一个感觉就是用递归创建,具体思路如下: function Directory($dir){ if(is_dir($dir) || @m ...
- 什么是BSE
BSE (bridge system engineer) 是外包开发人员和客户之前的桥梁. 主要是将客户的需求准确的理解并传达给外包的开发人员,一般情况下也兼开发的 leader 工作. 参考: ht ...
- GitHub 多人协作开发 三种方式(转)
一.Fork 方式 网上介绍比较多的方式(比较大型的开源项目,比如cocos2d-x) 开发者 fork 自己生成一个独立的分支,跟主分支完全独立,pull代码后,项目维护者可根据代码质量决定是否me ...
- 远程cmd操作
<<PSTools.zip>><<Install_PowerCmd.exe>><<cmder_mini.zip>><< ...