MIT6.828 Lab4 Preemptive Multitasking(下)
Lab4 Preemptive Multitasking(下)
lab4的第二部分要求我们实现fork的cow。在整个lab的第一部分我们实现了对多cpu的支持和再多系统环境中的切换,但是最后分析的时候没有分析环境创建的系统调用,这里先补一下对环境创建的系统调用的分析
recall A续
- 这里的分析要从
user/dumpfork.c开始
umain(int argc, char **argv)
{
envid_t who;
int i;
// fork a child process
who = dumbfork();
这里的main函数调用了dumbfork函数。在dumbfork中先执行了sys_exofork这个系统调用来创建新的环境。
这里为新的环境赋予和父环境一样的寄存器信息。并且将新环境的reg_eax寄存器置为0,这表示从子进程返回。而父进程会返回子进程的id。当然这里说的都是环境id。
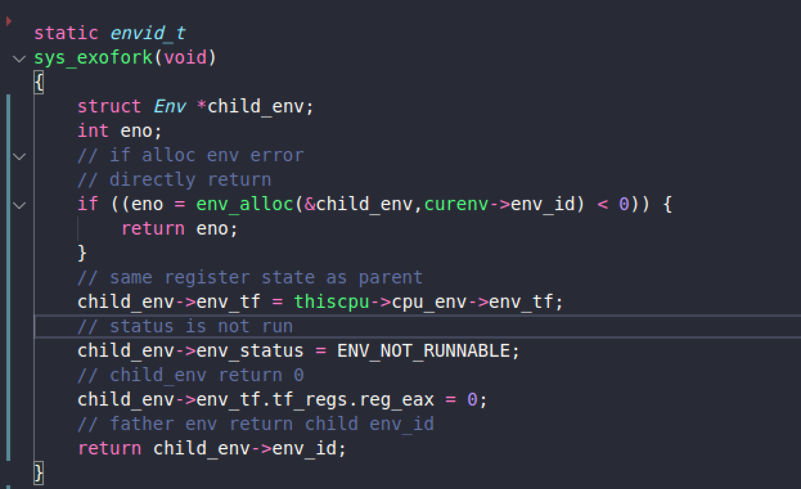
从父进程中返回之后会copy父进程的内容到子进程
// Eagerly copy our entire address space into the child.
// This is NOT what you should do in your fork implementation.
for (addr = (uint8_t*) UTEXT; addr < end; addr += PGSIZE)
duppage(envid, addr);也就是上面这一段。可以发现这段代码还是很简单的。就是逐页来copy父环境的内容---> 子环境中
问题的关键就是
duppage这个函数void
duppage(envid_t dstenv, void *addr)
{
int r; // This is NOT what you should do in your fork.
if ((r = sys_page_alloc(dstenv, addr, PTE_P|PTE_U|PTE_W)) < 0)
panic("sys_page_alloc: %e", r);
if ((r = sys_page_map(dstenv, addr, 0, UTEMP, PTE_P|PTE_U|PTE_W)) < 0)
panic("sys_page_map: %e", r);
memmove(UTEMP, addr, PGSIZE);
if ((r = sys_page_unmap(0, UTEMP)) < 0)
panic("sys_page_unmap: %e", r);
}
这里的
duppage用到了我们实验中实现的三个系统调用,但是好像真正用到的就是第一个。。后面两个只是在测试,我个人看起来是这样的,如果有问题的话,欢迎大家评论指出这里有两个地址需要️注意分别是
UTEXT和UTEMP
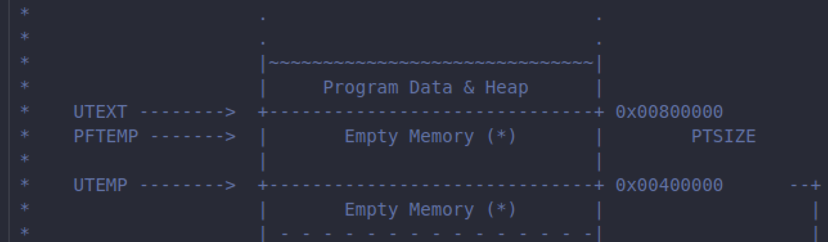
分别表示用户环境的代码段地址和一个用来测试的子环境段。。。
随后执行
sched_yield就可以实现类fork操作
Part B: Copy-on-Write Fork
上面的fork操作是会给子进程分配一个新的内存。并且copy父进程的地址空间过去,但我们知道真正的Linux操作系统并不是这样做的而是利用了cow(写时复制)的技术来实现的
1. User-level page fault handling
一个用户级别的cow的fork函数需要知道哪些page fault是在写保护页时触发的,写时复制只是用户级缺页中断处理的一种。
通常建立地址空间以便page fault提示何时需要执行某些操作。例如大多数Unix内核初始只给新进程的栈映射一个页,以后栈增长会导致page fault从而映射新的页。典型的Unix系统会对进程地址空间的不同区域发生的page fault错误执行不同的处理。例如栈上缺页,会分配和映射新的物理内存。.BSS区域缺页会分配新的全0物理页然后映射。在[csapp]书中有对应的内容。
2. Setting the Page Fault Handler
为了处理自己的缺页中断,用户环境需要在JOS内核中注册缺页中断处理程序的入口。用户环境通过sys_env_set_pgfault_upcall系统调用注册它的缺页中断入口。我们在Env结构体中增加了一个新成员env_pgfault_upcall来记录这一信息。
练习8就是让你实现缺页中断的入口,就是你用写时复制,如果修改了该怎么处理,调用哪个程序去处理。我们需要去实现这个sys_env_set_pgfault_upcall
static int
sys_env_set_pgfault_upcall(envid_t envid, void *func)
{
// LAB 4: Your code here.
struct Env * env;
if(envid2env(envid,&env,1)<0)return -E_BAD_ENV;//先判断进程可不可以用
env->env_pgfault_upcall=func;//意思就是处理中断的时候用func 这个函数。
return 0;
//panic("sys_env_set_pgfault_upcall not implemented");
}
3.Normal and Exception Stacks in User Environments
当缺页中断发生时,内核会返回用户模式来处理该中断。我们需要一个用户异常栈,来模拟内核异常栈。JOS的用户异常栈被定义在虚拟地址UXSTACKTOP。
4. Invoking the User Page Fault Handler
您现在需要更改kern / trap.c中的页面故障处理代码,以处理在用户模式下发生的页面故障。在故障处理程序中需要做下面的事情。
- 判断
curenv->env_pgfault_upcall是否设置。如果没有的话则直接销毁该进程 - 修改
esp,切换到用户异常栈 - 在栈中压入
UTrapframe结构 - 将
eip设置为curenv->env_pgfault_upcall,然后回到用户态执行curenv->env_pgfault_upcall处的代码
UTrapframe结构如下:
<-- UXSTACKTOP
trap-time esp
trap-time eflags
trap-time eip
trap-time eax start of struct PushRegs
trap-time ecx
trap-time edx
trap-time ebx
trap-time esp
trap-time ebp
trap-time esi
trap-time edi end of struct PushRegs
tf_err (error code)
fault_va <-- %esp when handler is run
Exercise 9.
Implement the code in page_fault_handler in kern/trap.c required to dispatch page faults to the user-mode handler. Be sure to take appropriate precautions when writing into the exception stack. (What happens if the user environment runs out of space on the exception stack?)
// LAB 4: Your code here.
// mustbe set upcall
if (curenv->env_pgfault_upcall) {
uintptr_t stack_top = UXSTACKTOP;
if (UXSTACKTOP - PGSIZE < tf->tf_esp && tf->tf_esp < UXSTACKTOP) {
stack_top = tf->tf_esp;
}
uint32_t size = sizeof(struct UTrapframe) + sizeof(uint32_t);
user_mem_assert(curenv, (void *)stack_top - size, size, PTE_U | PTE_W);
struct UTrapframe *utr = (struct UTrapframe *)(stack_top - size);
utr->utf_fault_va = fault_va;
utr->utf_err = tf->tf_err;
utr->utf_regs = tf->tf_regs;
utr->utf_eip = tf->tf_eip;
utr->utf_eflags = tf->tf_eflags;
utr->utf_esp = tf->tf_esp;
curenv->env_tf.tf_eip = (uintptr_t)curenv->env_pgfault_upcall;
curenv->env_tf.tf_esp = (uintptr_t)utr;
env_run(curenv); //重新进入用户态
}
User-mode Page Fault Entrypoint
现在需要实现lib/pfentry.S中的_pgfault_upcall函数,该函数会作为系统调用sys_env_set_pgfault_upcall()的参数。
Exercise 10.
实现lib/pfentry.S中的_pgfault_upcall函数。
// LAB 4: Your code here.
addl $8, %esp // skip utf_fault_va and utf_err
// Restore the trap-time registers. After you do this, you
// can no longer modify any general-purpose registers.
// LAB 4: Your code here.
movl 40(%esp), %eax
movl 32(%esp), %edx
movl %edx, -4(%eax)
popal
addl $4, %esp
// Restore eflags from the stack. After you do this, you can
// no longer use arithmetic operations or anything else that
// modifies eflags.
// LAB 4: Your code here.
popfl
// Switch back to the adjusted trap-time stack.
// LAB 4: Your code here.
popl %esp
// Return to re-execute the instruction that faulted.
// LAB 4: Your code here.
lea -4(%esp), %esp
ret
Exercise 11.
完成lib/pgfault.c中的set_pgfault_handler()
void
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r;
if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
// panic("set_pgfault_handler not implemented");
if (sys_page_alloc(0, (void *)(UXSTACKTOP-PGSIZE), PTE_W | PTE_U | PTE_P) < 0)
{
panic("set_pgfault_handler:sys_page_alloc failed!\n");
}
sys_env_set_pgfault_upcall(0, _pgfault_upcall);
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
}
5. 追踪一次页故障的发生
首先发生页故障的时候就会先通过IDT表找到对应的
handler然后进入
trap.c和trap_dispatch()对于页故障会进入我们指定好的page_fault_handler函数在这里要做的事情就是把utr寄存器初始化好,随后重新进入用户态
追踪了半天终于成功进入用户状态了。
这里有注意到地方如果你直接用在
env_run(curenv)用n的话则会一直跳出去,我这里用si追踪终于进入了用户状态,看见一个正常的地址还是很开心的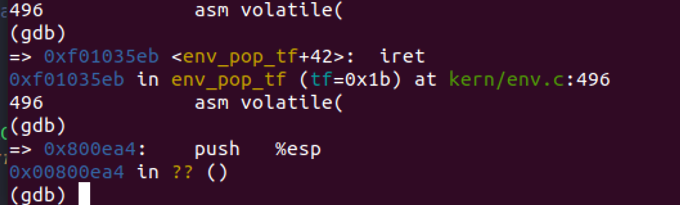
实际上这里就是在
lib/pfentry.S中的_pgfault_upcall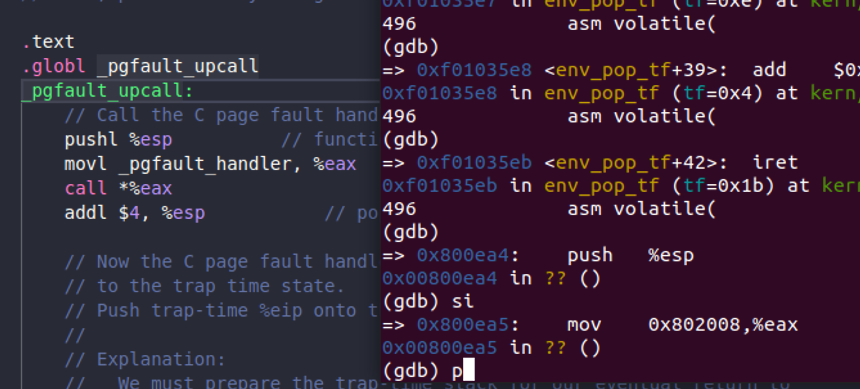
当然在进入这里之前我们已经设置好了
_pgfault_handler通过在我们user env中调用了位于
lib/pgfault.c中我们上述实现的set_pgfault_handler函数void
set_pgfault_handler(void (*handler)(struct UTrapframe *utf))
{
int r; if (_pgfault_handler == 0) {
// First time through!
// LAB 4: Your code here.
// panic("set_pgfault_handler not implemented");
if (sys_page_alloc(0, (void *)(UXSTACKTOP-PGSIZE), PTE_W | PTE_U | PTE_P) < 0)
{
panic("set_pgfault_handler:sys_page_alloc failed!\n");
}
sys_env_set_pgfault_upcall(0, _pgfault_upcall);
}
// Save handler pointer for assembly to call.
_pgfault_handler = handler;
}
这里调用的
call *%eax实际上就是调用了指定的handler函数。对于
user/faultalloc.这个用户程序而言,就是下面这个函数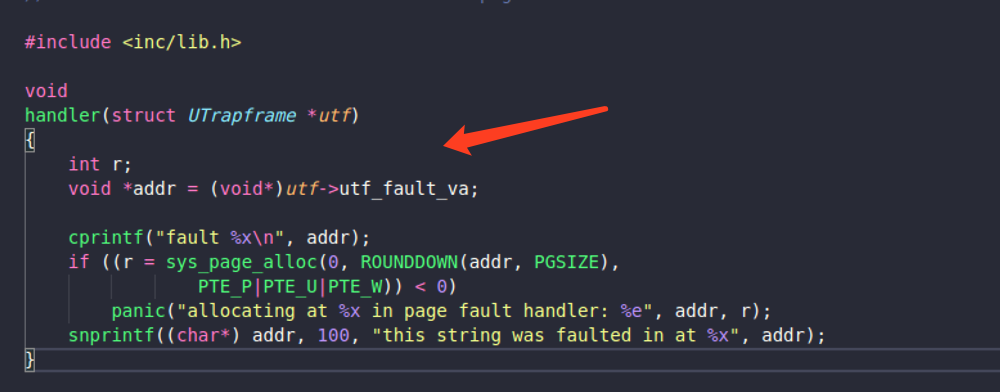
随后我们完成了对于故障处理的全部过程,所以应该返回故障发生的地方继续执行
// LAB 4: Your code here.
addl $8, %esp // skip utf_fault_va and utf_err
// Restore the trap-time registers. After you do this, you
// can no longer modify any general-purpose registers.
// LAB 4: Your code here.
movl 40(%esp), %eax
movl 32(%esp), %edx
movl %edx, -4(%eax)
popal
addl $4, %esp
// Restore eflags from the stack. After you do this, you can
// no longer use arithmetic operations or anything else that
// modifies eflags.
// LAB 4: Your code here.
popfl
// Switch back to the adjusted trap-time stack.
// LAB 4: Your code here.
popl %esp
// Return to re-execute the instruction that faulted.
// LAB 4: Your code here.
lea -4(%esp), %esp
ret
上面这一堆汇编代码看起来非常麻烦。
实际上他要做的就是把esp寄存器设置成原来故障发生前的esp。
并且把eip寄存器设置成故障发生的地方,表示接下来要继续执行这里。
6. Implementing Copy-on-Write Fork
partB的最后就是要让我们实现写时复制的功能,在dumpfork函数中我们已经有过类似的fork函数,只不过这里我们要实现cow的fork。整个fork函数的流程如下
- 父进程将
pgfault函数作为c语言实现的页处理错误,会用到之前lab中实现set_pgfault_handler的函数 - 父进程会调用
sys_exofork创建一个子进程 - 在
UTOP之下的在地址空间里的每一个可写或cow的页,父进程就会调用duppage它会将cow页映射到子进程的地址空间,然后重新映射cow页到自己的地址的空间。duppage将COW的页的PTEs设置为不能写的,然后在PTE的avail域设置PTE_COW来区别 copy-on-write pages及真正的只读页。 - 父进程为子进程设置用户页错误入口
- 子进程现在可以运行,然后父进程将其标记为可运行
当父子进程试图写一个尚未写过的copy-on-write页写时,就会产生一个页错误。下面是用户页错误处理的控制流:
- 内核把页错误传递到
_pgfault_upcall,调用fork()的pgfault()处理页错误。 - pgfault()检查错误码是否等于FEC_WR,这表示这是一个写页错误。同时检测对应页的PTE标记为PTE_COW。否则直接panic。
- pgfault()分配一个映射在一个临时位置的新的页,然后将错误页中的内容复制进去。然后页错误处理程序映射新的页到引起page fault的虚拟地址,并设置PTE具有读写权限。
用户级的lib/fork.c必须访问用户环境的页表完成以上的几个操作(例如将一个页对应的PTE标记为PTE_COW。内核映射用户环境的页表到虚拟地址UVPT的用意就在于此。它使用了一种聪明的手段让用户代码很方便的检索PTE。lib/entry.S设置uvpt和uvpd使得lib/fork.c中的用户代码能够轻松地检索页表信息。
Exercise 12.
Implement fork, duppage and pgfault in lib/fork.c.
关于这个fork的具体实现细节和深入思考,请看这里
1. pgfault实现
pgfault的作用就是创建一个临时页用来写入的。所以这里的新页必须设置
PTE_W这里必须要按照实验给的要求判断
err & FEC_WR以及发生错误的页是一个cow的页
static void
pgfault(struct UTrapframe *utf)
{
void *addr = (void *) utf->utf_fault_va;
uint32_t err = utf->utf_err;
int r;
// Check that the faulting access was (1) a write, and (2) to a
// copy-on-write page. If not, panic.
// Hint:
// Use the read-only page table mappings at uvpt
// (see <inc/memlayout.h>).
// LAB 4: Your code here.
// Allocate a new page, map it at a temporary location (PFTEMP),
// copy the data from the old page to the new page, then move the new
// page to the old page's address.
// Hint:
// You should make three system calls.
if ( !((err & FEC_WR) && (uvpd[PDX(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_P) && (uvpt[PGNUM(addr)] & PTE_COW))) {
panic("must be above reason");
}
// LAB 4: Your code here.
if ((r = sys_page_alloc(0,PFTEMP,PTE_W | PTE_U | PTE_P) < 0)) {
panic("alloc map error, error nubmer is %d\n",r);
}
// addr pgsize assign
addr = ROUNDDOWN(addr, PGSIZE);
memcpy((void *)PFTEMP,addr,PGSIZE);
//
r = sys_page_map(0,(void *)PFTEMP,0,addr,PTE_W | PTE_U | PTE_P);
if (r < 0) {
panic("sysmap error");
}
r = sys_page_unmap(0,(void *) PFTEMP);
if (r < 0) {
panic("page_unmap error");
}
// panic("pgfault not implemented");
}
2. duppage的实现
- 首先明确这个函数的功能就是把制定的
pn页从父进程映射到子进程中 - 并且映射过去要把它标记成
COW - 这里一个主意点是这里先将子进程(子环境)的页标记成了
cow具体原因见链接
static int
duppage(envid_t envid, unsigned pn)
{
int r;
// LAB 4: Your code here.
// panic("duppage not implemented");
void * va = (void *)(pn * PGSIZE);
if ( (uvpt[pn] & PTE_W) || (uvpt[pn] & PTE_COW)) {
r = sys_page_map(0, va, envid, va, PTE_COW | PTE_P | PTE_U);
if (r < 0) {
return r;
}
r = sys_page_map(0,va, 0,va, PTE_U | PTE_COW | PTE_P);
if (r < 0) {
return r;
}
} else {
r = sys_page_map(0,va,envid,va, PTE_P | PTE_U);
if (r < 0) {
return r;
}
}
return 0;
}
3. fork的实现
最后就是fork的实现
- 首先通过系统调用
sys_exofork创建一个子环境。 - 如果返回的是0(也就是如果在子环境中)则直接运行
- 否砸在父环境中要完成copy操作
- 这里的我们要从
UTEXT开始到USTACKTOP为止依次check所有的页,把属于当前父进程的页copy和子进程 - 这里要分配一个页来表示用户进程的异常栈。异常栈的作用在上面已经说过了。
envid_t
fork(void)
{
// LAB 4: Your code here.
// panic("fork not implemented");
envid_t envid;
int r;
unsigned pn;
set_pgfault_handler(pgfault);
envid = sys_exofork();
if (envid < 0) {
panic("sys_exofork: %e", envid);
}
if (envid == 0) {
// we are children
thisenv = &envs[ENVX(sys_getenvid())];
return 0;
}
// for parent
for (pn=PGNUM(UTEXT); pn<PGNUM(USTACKTOP); pn++){
if ((uvpd[pn >> 10] & PTE_P) && (uvpt[pn] & PTE_P))
if ((r = duppage(envid, pn)) < 0)
return r;
}
if ((r = sys_page_alloc(envid,(void *) (UXSTACKTOP - PGSIZE), (PTE_U | PTE_P | PTE_W))) < 0) {
panic("error");
}
extern void _pgfault_upcall(void); //缺页处理
if((r = sys_env_set_pgfault_upcall(envid, _pgfault_upcall)) < 0){
panic("sys_set_pgfault_upcall:%e", r);
}
if ((r = sys_env_set_status(envid, ENV_RUNNABLE)) < 0)//设置成可运行
return r;
return envid;
}
好了上面就是partB的所有内容,做完之后就可以通过partB的测试
Recall PartB
当然在进入PartC之间,照例的分析一下partB。这里发现一个清华小姐姐的博客写的很好
对于整个控制流的过程如下
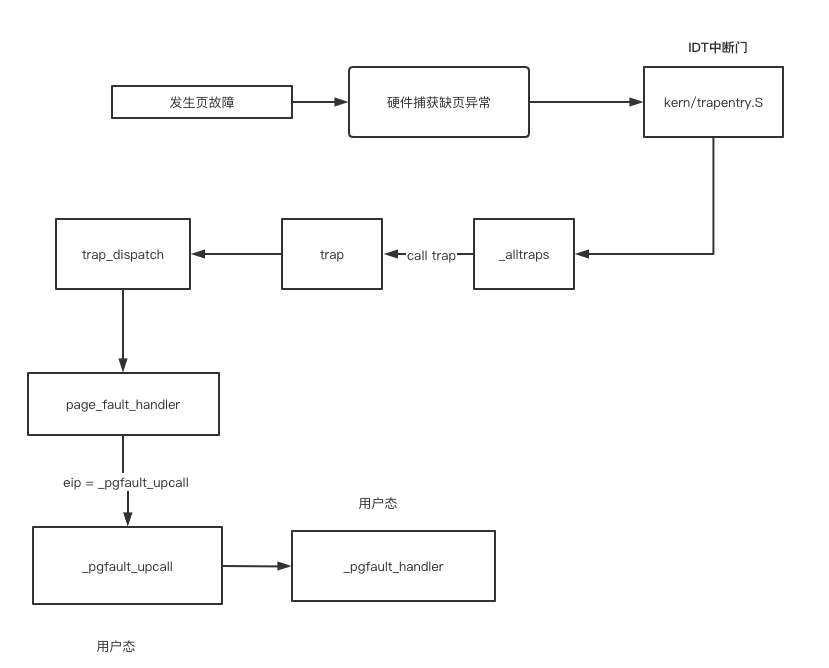
- 而在我们partb部分的写时复制的话,我们修改了之前的
duppage。在新的cow中我们不需要进行新的page_alloc只需要和父进程完全一样的虚拟地址空间(注意是独立的) - 在上面的博客里大佬有讲解了为什么在
page_fault的时候多分配了4字节的空间同时配有图进行分析。
PartC: IPC
在实验4的最后一部分,我们将修改kernel以抢占某些”不配合“的进程【抢占式多任务】,并允许进程之间显式地进行传递消息。
1.Clock Interrupts and Preemption
运行 user/spin 测试程序。这个测试程序fork出一个子进程,这个子进程一旦得到CPU的控制就会spin forever(while(1))。无论是父进程还是kernel都不会重新获得CPU。This is obviously not an ideal situation in terms of protecting the system from bugs or malicious code in user-mode environments, 因为任何用户模式环境只要进入一个无限循环并且永远不退还 CPU,就可能使整个系统陷入停顿(halt)。为了允许内核抢占(preempt )一个运行环境,强制重新控制 CPU,我们必须扩展 JOS 内核来支持来自时钟硬件的外部硬件中断(external hardware interrupts from the clock hardware)。
2. Interrupt discipline
外部中断External Interrupts (即设备中断Device Interrupts)被称为IRQs。有16种可能的IRQs,编号为[0,15]。IRQ 号到 IDT 条目的映射是不固定的。pic_init in picirq.c maps IRQs 0-15 to IDT entries IRQ_OFFSET through IRQ_OFFSET+15。
在inc/trap.h中,IRQ_OFFSET设置为32(十进制)。因此IDT条目32-47对应于 IRQs 0-15。例如,时钟中断是 IRQ0,因此IDT[IRQ _ offset + 0],即IDT[32]存储了the address of the clock’s interrupt handler routine in the kernel。之所以选择这个IRQ_OFFSET值是为了使设备中断与处理器异常不重叠(事实上,在PC运行 MS-DOS的早期,IRQ_OFFSET实际上是零,这确实在处理硬件中断和处理器异常之间造成了巨大的混乱!)。
在 JOS,与 xv6 Unix 相比,我们做了一个关键的简化。外部设备中断在内核中总是禁用的,而和xv6一致,在用户空间中是启用。外部中断由%eflags寄存器的FL_IF标志位控制(见 inc/mmu.h)。当这个位被设置时,外部中断被启用。虽然这个位可以通过几种方式修改,但是由于我们的简化,在进入和离开用户模式时,我们将只通过保存和恢复%eflags寄存器的过程来处理它。
我们必须确保在用户运行时在用户环境中设置FL_IF标志,以便当中断到来时,它被传递到处理器并由中断代码处理。否则,中断将被屏蔽或忽略,直到中断被重新启用。此前,我们在bootloader的第一条指令中设置了中断屏蔽(masked interrupts),到目前为止我们还没有重新启用过它们。
Exercise 13
Modify
kern/trapentry.Sandkern/trap.cto initialize the appropriate entries in the IDT and provide handlers for IRQs 0 through 15.Then modify the code in
env_alloc()inkern/env.cto ensure that user environments are always run with interrupts enabled.Also uncomment the
stiinstruction insched_halt()so that idle CPUs unmask interrupts(不屏蔽中断请求).The processor never pushes an error code when invoking a hardware interrupt handler.
修改kern/trapentry.S和kern/trap.c来初始化IDT中IRQs0-15的入口和处理函数。然后修改env_alloc函数来确保进程在用户态运行时中断是打开的。
模仿原先设置默认中断向量即可,注意在发生硬件中断的时候,不会push error code,在kern/trapentry.S中定义IRQ0-15的处理例程时需要使用TRAPHANDLER_NOEC。
- 在
trap.c中加入IRQ0-15的处理例程
SETGATE(idt[IRQ_OFFSET + 0], 0, GD_KT, irq_0_handler, 0);
SETGATE(idt[IRQ_OFFSET + 1], 0, GD_KT, irq_1_handler, 0);
SETGATE(idt[IRQ_OFFSET + 2], 0, GD_KT, irq_2_handler, 0);
SETGATE(idt[IRQ_OFFSET + 3], 0, GD_KT, irq_3_handler, 0);
SETGATE(idt[IRQ_OFFSET + 4], 0, GD_KT, irq_4_handler, 0);
SETGATE(idt[IRQ_OFFSET + 5], 0, GD_KT, irq_5_handler, 0);
SETGATE(idt[IRQ_OFFSET + 6], 0, GD_KT, irq_6_handler, 0);
SETGATE(idt[IRQ_OFFSET + 7], 0, GD_KT, irq_7_handler, 0);
SETGATE(idt[IRQ_OFFSET + 8], 0, GD_KT, irq_8_handler, 0);
SETGATE(idt[IRQ_OFFSET + 9], 0, GD_KT, irq_9_handler, 0);
SETGATE(idt[IRQ_OFFSET + 10], 0, GD_KT, irq_10_handler, 0);
SETGATE(idt[IRQ_OFFSET + 11], 0, GD_KT, irq_11_handler, 0);
SETGATE(idt[IRQ_OFFSET + 12], 0, GD_KT, irq_12_handler, 0);
SETGATE(idt[IRQ_OFFSET + 13], 0, GD_KT, irq_13_handler, 0);
SETGATE(idt[IRQ_OFFSET + 14], 0, GD_KT, irq_14_handler, 0);
SETGATE(idt[IRQ_OFFSET + 15], 0, GD_KT, irq_15_handler, 0);
- 同时在
trapentry.S中添加
TRAPHANDLER_NOEC(irq_0_handler, IRQ_OFFSET + 0);
TRAPHANDLER_NOEC(irq_1_handler, IRQ_OFFSET + 1);
TRAPHANDLER_NOEC(irq_2_handler, IRQ_OFFSET + 2);
TRAPHANDLER_NOEC(irq_3_handler, IRQ_OFFSET + 3);
TRAPHANDLER_NOEC(irq_4_handler, IRQ_OFFSET + 4);
TRAPHANDLER_NOEC(irq_5_handler, IRQ_OFFSET + 5);
TRAPHANDLER_NOEC(irq_6_handler, IRQ_OFFSET + 6);
TRAPHANDLER_NOEC(irq_7_handler, IRQ_OFFSET + 7);
TRAPHANDLER_NOEC(irq_8_handler, IRQ_OFFSET + 8);
TRAPHANDLER_NOEC(irq_9_handler, IRQ_OFFSET + 9);
TRAPHANDLER_NOEC(irq_10_handler, IRQ_OFFSET + 10);
TRAPHANDLER_NOEC(irq_11_handler, IRQ_OFFSET + 11);
TRAPHANDLER_NOEC(irq_12_handler, IRQ_OFFSET + 12);
TRAPHANDLER_NOEC(irq_13_handler, IRQ_OFFSET + 13);
TRAPHANDLER_NOEC(irq_14_handler, IRQ_OFFSET + 14);
TRAPHANDLER_NOEC(irq_15_handler, IRQ_OFFSET + 15);
在env_alloc函数中为创建的environment设置中断开启。
// Enable interrupts while in user mode.
// LAB 4: Your code here.
e->env_tf.tf_eflags |= FL_IF;
在
sched_halt()中注释sti指令,设置中断开启,允许接受时钟硬件中断
// Reset stack pointer, enable interrupts and then halt. asm volatile ( "movl $0, %%ebp\n" "movl %0, %%esp\n" "pushl $0\n" "pushl $0\n" // Uncomment the following line after completing exercise 13 "sti\n" "1:\n" "hlt\n" "jmp 1b\n" : : "a" (thiscpu->cpu_ts.ts_esp0));
3. Handling Clock Interrupts
在 user/spin程序中,在子进程第一次运行之后,它只是在循环中spin,内核不再能得到控制权。因此我们需要对硬件进行编程来周期性地产生时钟中断,从而迫使CPU控制权回到内核中,故我们可以在不同的用户环境中切换控制。
通过调用 lapic_init and pic_init(from i386_init in init.c)设置了时钟和中断控制器来生成中断。现在需要编写处理这些中断的代码。
Exercise 14.
需要在内核代码中对时钟中断进行处理,调用之前实现的sched_yield,来调度别的environment使用CPU即可:
// Handle clock interrupts. Don't forget to acknowledge the // interrupt using lapic_eoi() before calling the scheduler! // LAB 4: Your code here. if (tf->tf_trapno == IRQ_OFFSET + IRQ_TIMER) { lapic_eoi(); sched_yield(); }
改完上面的代码之后就可以拿到65/80分了
4. Inter-Process communication (IPC)
有非常多进程之间的通信方法,但在这里我们只会实现一个非常简单的方法。实验指导书中有关于一些知识点讲解,但是直接翻译感觉好乱。后面我就直接梳理了
Exercise 15.
1. 实现在kern/syscall.c中的sys_ipc_try_send
- 按照注释提示中去实现各种判断如必须对奇、perm是否合适
- 第一个要注意考虑的是这个srcva必须是页对奇的
- 而且这个
srcva要在UTOP之下表示要发送page currently mapped at 'srcva' - you should set the
checkpermflag to 0,
static int
sys_ipc_try_send(envid_t envid, uint32_t value, void *srcva, unsigned perm)
{
// LAB 4: Your code here.
struct Env *rec_env, *cur_env;
int r;
// get current env
envid2env(0,&cur_env,0));
assert(cur_env);
if ((r = envid2env(envid, &rec_env,0)) < 0) {
return r;
}
if (!rec_env->env_ipc_recving) {
return -E_IPC_NOT_RECV;
}
if ((uintptr_t)srcva < UTOP) {
struct PageInfo *pg;
pte_t *pte;
// if srcva is not page-aligned
// 0x1000 - 1= 0x0111
// if srcva any bit is 1 is not page-aligned
if ((uintptr_t) srcva & (PGSIZE - 1)) {
return -E_INVAL;
}
// perm is inappropriate is same as the sys_page_alloc
if(!(perm & PTE_U) || !(perm & PTE_P) || (perm & (~PTE_SYSCALL))){
return -E_INVAL;
}
// srcva is mapped in the caller's address spcae
if (!(pg = page_lookup(cur_env->env_pgdir,srcva,&pte))) {
return -E_INVAL;
}
// if (perm & PTE_W), but srcva is read-only
if ((perm & PTE_W) && !((*pte) & PTE_W)) {
return -E_INVAL;
}
if ((uintptr_t)rec_env->env_ipc_dstva < UTOP) {
if ((r = page_insert(rec_env->env_pgdir,pg,rec_env->env_ipc_dstva,perm) < 0)) {
return -r;
}
}
}
rec_env->env_ipc_perm = perm;
rec_env->env_ipc_value = value;
rec_env->env_ipc_recving = 0;
rec_env->env_ipc_from = cur_env->env_id;
rec_env->env_status = ENV_RUNNABLE;
rec_env->env_tf.tf_regs.reg_eax = 0;
return 0;
}
2. 实现sys_ipc_recv函数
static int
sys_ipc_recv(void *dstva)
{
// LAB 4: Your code here.
if (((uintptr_t) dstva < UTOP) && ((uintptr_t)dstva & (PGSIZE - 1))) {
return -E_INVAL;
}
struct Env *cur_env;
envid2env(0,&cur_env,0);
assert(cur_env);
cur_env->env_status = ENV_NOT_RUNNABLE;
cur_env->env_ipc_recving = 1;
cur_env->env_ipc_dstva = dstva;
sys_yield();
return 0;
}
3. 随后实现在lib/ipc.c的ipc_recv和ipc_send函数
- 如果
pg = none就把pg设置成UTOP这样在系统调用里面就不会send page - 如果调用
sys_ipc_recv成功的话则就会设置参数
int32_t
ipc_recv(envid_t *from_env_store, void *pg, int *perm_store)
{
// LAB 4: Your code here.
// panic("ipc_recv not implemented");
int error;
if(!pg)pg = (void *)UTOP; //
if((error = sys_ipc_recv(pg)) < 0){
if(from_env_store)*from_env_store = 0;
if(perm_store)*perm_store = 0;
return error;
}
if(from_env_store)*from_env_store = thisenv->env_ipc_from;
if(perm_store)*perm_store = thisenv->env_ipc_perm;
return thisenv->env_ipc_value;
}
- 根据给定的参数目标环境、val、pg、perm调用系统调用发送message
- 如果得到的error code 不是
E_IPC_NOT_RECV则直接panic
void
ipc_send(envid_t to_env, uint32_t val, void *pg, int perm)
{
// LAB 4: Your code here.
// panic("ipc_send not implemented");
if (!pg) {
pg = (void *)UTOP;
}
int r;
while((r = sys_ipc_try_send(to_env,val,pg,perm)) < 0) {
if (r != -E_IPC_NOT_RECV) {
panic("sys_ipc_try_send error %e\n",r);
}
sys_yield();
}
}
MIT6.828 Lab4 Preemptive Multitasking(下)的更多相关文章
- MIT 6.828 Lab04 : Preemptive Multitasking
目录 Part A:Multiprocessor Support and Cooperative Multitasking Multiprocessor Support 虚拟内存图 Exercise ...
- MIT6.828准备:MacOS下搭建xv6和risc-v环境
本文介绍在MacOS下搭建Mit6.828/6.S081 fall2019实验环境的详细过程,包括riscv工具链.qemu和xv6,对于Linux系统同样可以参考. 介绍 只有了解底层原理才能写好上 ...
- MIT6.828 Preemptive Multitasking(上)
Lab4 Preemptive Multitasking(上) PartA : 多处理器支持和协作多任务 在实验的这部分中,我们首先拓展jos使其运行在多处理器系统上,然后实现jos内核一些系统功能调 ...
- MIT-6.828-JOS-lab4:Preemptive Multitasking
Lab 4: Preemptive Multitasking tags: mit-6.828, os 概述 本文是lab4的实验报告,主要围绕进程相关概念进行介绍.主要将四个知识点: 开启多处理器.现 ...
- MIT6.828课程JOS在macOS下的环境配置
本文将介绍如何在macOS下配置MIT6.828 JOS实验的环境. 写JOS之前,在网上搜寻JOS的开发环境,很多博客和文章都提到"不是32位linux就不好配置,会浪费大量时间在配置环境 ...
- 【MIT6.828】centos7下使用Qemu搭建xv6运行环境
title:[MIT6.828]centos7下使用Qemu搭建xv6运行环境 date: "2020-05-05" [MIT6.828]centos7下搭建xv6运行环境 1. ...
- MIT6.828 JOS系统 lab2
MIT6.828 LAB2:http://pdos.csail.mit.edu/6.828/2014/labs/lab2/ LAB2里面主要讲的是系统的分页过程,还有就是简单的虚拟地址到物理地址的过程 ...
- MIT6.828 虚拟地址转化为物理地址——二级分页
这个分页,主要是在mit6.828的lab2的背景下来说的. Mit6.828 Lab2:http://pdos.csail.mit.edu/6.828/2014/labs/lab2/ lab2主要讲 ...
- mit-6.828 Lab Tools
Lab Tools 目录 Lab Tools 写在前面 GDB GNU GPL (通用公共许可证) QEMU ELF 可执行文件的格式 Verbose mode Makefile 写在前面 操作系统小 ...
随机推荐
- IDEA 最实用快捷键【MAC版本】
目录 option + F7 Ctrl + B / Ctrl +鼠标左键(一键两用,可以无限循环的跳过来跳过去,我跳过去了,我又跳回去了) command + E (这个快捷键很有用,为什么我老是用不 ...
- JMeter逻辑控制器完整介绍
JMeter逻辑控制器可以对元件的执行逻辑进行控制,就像编程一样,实现业务需求. JMeter包括了以下逻辑控制器: 一共17种.除了仅一次控制器外,其他控制器下可以嵌套别的种类的逻辑控制器. If ...
- 改进遗传算法之CHC算法简要介绍
简要介绍: CHC算法是Eshelman于1991年提出的一种改进的遗传算法的缩称,第一个C代表跨世代精英选择(Cross generational elitist selection)策略, H代表 ...
- SQL查询要求两个条件同时成立
SELECT * FROM [TABLE] WHERE CASE WHEN O_State='已处理' AND O_Pay='已付' THEN 0 ELSE 1 END=1
- windows 下安装Charles,破解,安装证书,设置可抓取https包
参考地址: https://www.zzzmode.com/mytools/charles/ 一.下载后进行安装 二.安装后进行破解 按照参考中的链接破解即可 三.Charles在windows证书 ...
- Markdown个人常用语法
Markdown实用格式 标题 # 标题一级 ## 标题二级 ### 标题三级 #### 标题四级 ##### 标题五级 ###### 标题六级 粗体.斜体和删除线 **加粗字体** *斜体字体* * ...
- 端午总结Vue3中computed和watch的使用
1使用计算属性 computed 实现按钮是否禁用 我们在有些业务场景的时候,需要将按钮禁用. 这个时候,我们需要使用(disabled)属性来实现. disabled的值是true表示禁用.fals ...
- 简单的Java面向对象程序
上一篇随笔Java静态方法和实例方法的区别以及this的用法,老师看了以后说我还是面向过程的编程,不是面向对象的编程,经过修改以后,整了一个面向对象的出来: /** * 3 延续任务2, 定义表示圆形 ...
- 【NX二次开发】Block UI 截面构建器
属性说明 属性 类型 描述 常规 BlockID String 控件ID Enable Logical 是否可操作 Group ...
- NOIP模拟测试38「金·斯诺·赤」
金 辗转相减见祖宗 高精 #include<bits/stdc++.h> using namespace std; #define A 2000 #define P 1 #define N ...