deque概述
1、简介
双端队列deque,与vector的最大差异在于:
一、deque运行常数时间对头端或尾端进行元素的插入和删除操作。
二、deque没有所谓的容器概念,因为它是动态地以分段连续空间组合而成随时可以增加一块新的内存空间并拼接起来。
虽然deque也提供随机访问的迭代器,但它的迭代器与list和vector的不一样,其设计相当复杂而精妙。因此,会对各种运算产生一定影响,厨房必要,尽可能的选择使用vetor而非deque。队列示意图如下图所示:

2、deque的中控器
deque在逻辑上看起来是连续的空间,内部确实是一段一段的定量连续空间构成。
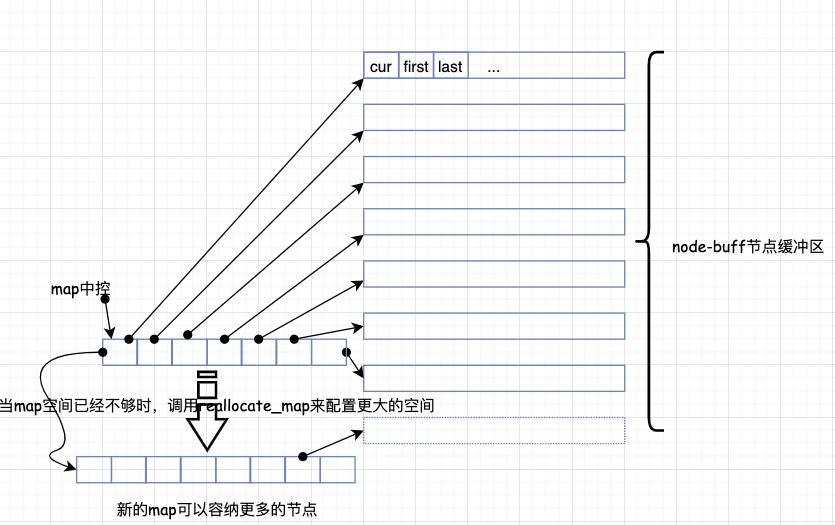
一旦有必要在deque的前端或尾端增加新空间,deque会配置一段定量的连续空间,串联在整个deque的头部或尾部。
deque的设计大师最大的调整应该就是如何在这段分段的定量连续空间上还能维护其整体连续的假象,并提供其随机存取的接口,从而避开了像vector那样的“重新配置-复制-释放”开销三部曲。———这样一来,虽然开销降低,却提高了复杂的迭代器架构。
因此,deque数据结构的设计和迭代前进或后退等操作都非常复杂。
deque采用一块所谓的map(注意,不是stl里面的map容器)作为中控器,其实就是一小块连续空间,其中的每一个元素都是指针,指向另外一段较大的连续线性空间,称之为缓冲区。在后面我们将看到,缓冲区才是deque的存储空间主体。
#ifndef __STL_NON_TYPE_TMPL_PARAM_BUG
template <class T, class Ref, class Ptr, size_t BufSiz>
class deque {
public:
typedef T value_type;
typedef value_type* pointer;
...
protected:
typedef pointer** map_pointer;
map_pointer map;//指向 map,map 是连续空间,其内的每个元素都是一个指针。
size_type map_size;
...
};
deque的结构设计中,map和node-buffer的关系如下:
3、deque的迭代器
deque是分段连续空间,维持其“整体连续”假象的任务,就靠它的迭代器来实现,也就是operator++和operator--两个算子上面。在开发者看来,设计deque迭代器应该具备如下三个特征的结构和功能:
一、既然deque存储空间是分段的连续空间,迭代器应该能够指出当前的连续空间在哪里。
二、因为缓冲区有边界,迭代器还应该能判断当前是否处于缓冲区的边缘,如果是,一旦前进或后退,就必须跳转到下一个或上一个缓冲区。
三、也就是实现前面两种情况的前提,迭代器必须随时控制中控器。
有了这些分析之后,在分析源码时,就显得容易理解了。
#ifndef __STL_NON_TYPE_TMPL_PARAM_BUG
template <class T, class Ref, class Ptr, size_t BufSiz>
class deque {
public:
typedef T value_type;
typedef value_type* pointer;
...
protected:
typedef pointer** map_pointer;
map_pointer map;//指向 map,map 是连续空间,其内的每个元素都是一个指针。
size_type map_size;
...
};
deque的每一个缓冲区设计了三个迭代器:
struct __deque_iterator {
...
typedef T value_type;
T* cur;
T* first;
T* last;
typedef T** map_pointer;
map_pointer node;
...
};
为什么这么设计呢?因为deque是分段连续的空间,下图描绘了deque的中控器、缓冲区、迭代器之间的相互关系:
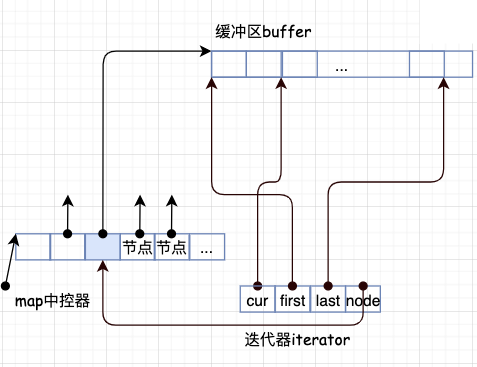
map的每一段都指向一个缓冲区buffre,而缓冲区是需要知道每个元素的位置的,所以需要这些迭代器去访问。其中:
- cur表示当前所指向的位置;
- first表示当前数组中头的位置;
- last表示当前数组中尾的位置。
这样设计显然是为了方便管理,需要注意的是deque的空间由map管理的。它是一个指向指针的指针。所以三个参数都是指向当前的数组,但这样的数组可能有多个,只是每个数组都管理这3个变量。
最后,deque缓冲区的大小由一个全局函数来决定:
inline size_t __deque_buf_size(size_t n, size_t sz) {
return n != 0 ? n : (sz < 512 ? size_t(512 / sz): size_t(1));
}
//如果 n 不为0,则返回 n,表示缓冲区大小由用户自定义
//如果 n == 0,表示 缓冲区大小默认值
//如果 sz = (元素大小 sizeof(value_type)) 小于 512 则返回 521/sz
//如果 sz 不小于 512 则返回 1
用例分析:
假设现在构造一个int类型的deque,设置缓冲区大小等于32,这样一来,每个缓冲区可以容纳32/sizeof(int)=8个元素。经过一番操作之后,deuqe现在有20个元素来,那么成员函数begin()和end()返回的两个迭代器应该是什么样的呢?如下图所示:
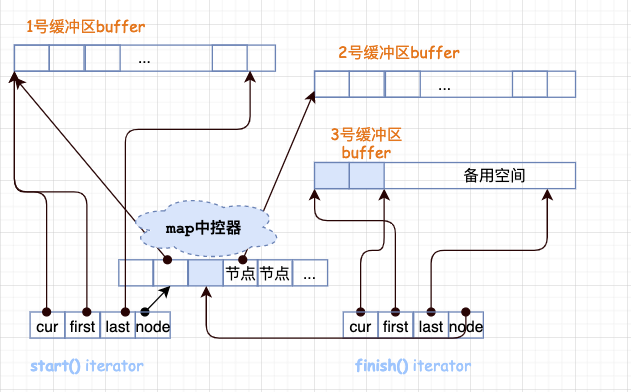
20个元素需要20/8≈3个缓冲区。
所以map运用的三个节点,迭代器start内的cur指针指向缓冲区的第一个元素,迭代器finish内的cur指针指向缓冲区的最后一个元素(的下一个位置)。
注意:最后一个缓冲区尚有备用空间,如果之后还有新元素插入,则直接插入到备用空间。
4、迭代器的操作
迭代器操作包括两种:前进和后退。
operator++操作代表需要切换到下一个元素,这里需要先切后再判断是否已经到达缓冲区到末尾。
self& operator++() {
++cur; //切换至下一个元素
if (cur == last) { //如果已经到达所在缓冲区的末尾
set_node(node+1); //切换下一个节点
cur = first;
}
return *this;
}
operator--操作代表切换到上一个元素所在的位置,需要先判断是否到达缓冲区的头部再后退。
self& operator--() {
if (cur == first) { //如果已经到达所在缓冲区的头部
set_node(node - 1); //切换前一个节点的最后一个元素
cur = last;
}
--cur; //切换前一个元素
return *this;
} //结合前面的分段连续空间,你在想一想这样的设计是不是合理呢?
5、deque的构造和析构函数
deque的构造函数有多个重载函数,接受大部分不同的参数类型,基本上每一个构造函数都会调用create_map_and_nodes,这就是构造函数的核心,后面我们来分析这个函数的实现。
template <class T, class Alloc = alloc, size_t BufSiz = 0>
class deque {
...
public: // Basic types
deque() : start(), finish(), map(0), map_size(0){
create_map_and_nodes(0);
} // 默认构造函数
deque(const deque& x) : start(), finish(), map(0), map_size(0) {
create_map_and_nodes(x.size());
__STL_TRY {
uninitialized_copy(x.begin(), x.end(), start);
}
__STL_UNWIND(destroy_map_and_nodes());
}
// 接受 n:初始化大小, value:初始化的值
deque(size_type n, const value_type& value) : start(), finish(), map(0), map_size(0) {
fill_initialize(n, value);
}
deque(int n, const value_type& value) : start(), finish(), map(0), map_size(0) {
fill_initialize(n, value);
}
deque(long n, const value_type& value) : start(), finish(), map(0), map_size(0){
fill_initialize(n, value);
}
...
下面我们来看下deque的中控器如配置:
void deque<T,Alloc,BufSize>::create_map_and_nodes(size_type_num_elements) {
//需要节点数= (每个元素/每个缓冲区可容纳的元素个数+1)
//如果刚好整除,多配一个节点
size_type num_nodes = num_elements / buffer_size() + 1;
//一个 map 要管理几个节点,最少 8 个,最多是需要节点数+2
map_size = max(initial_map_size(), num_nodes + 2);
map = map_allocator::allocate(map_size);
// 计算出数组的头前面留出来的位置保存并在nstart.
map_pointer nstart = map + (map_size - num_nodes) / 2;
map_pointer nfinish = nstart + num_nodes - 1;
map_pointer cur;//指向所拥有的节点的最中央位置
...
}
注意,分析源码之后发现:deque的begin和end不是一开始就指向map中控器的开通和结尾的,而是指向所拥有的节点的最中央位置。
这样带来的好处是可以使得头尾两边扩充的可能性一样大,换句话说,因为deque是头尾插入都是O(1),所以deque在头和尾都留有空间方便头尾插入。
那么,什么时候map中控器本身需要调整大小呢?触发条件在于reserve_map_at_back和reserve_map_at_font这两个函数来判断,实际操作由reallocate_map来执行。
// 如果 map 尾端的节点备用空间不足,符合条件就配置一个新的map(配置更大的,拷贝原来的,释放原来的)
void reserve_map_at_back (size_type nodes_to_add = 1) {
if (nodes_to_add + 1 > map_size - (finish.node - map))
reallocate_map(nodes_to_add, false);
}
// 如果 map 前端的节点备用空间不足,符合条件就配置一个新的map(配置更大的,拷贝原来的,释放原来的)
void reserve_map_at_front (size_type nodes_to_add = 1) {
if (nodes_to_add > start.node - map)
reallocate_map(nodes_to_add, true);
}
6、deque的插入元素和删除元素
因为deque是能够双向操作,所以其push和pop操作都类似于list,都可以直接有对应的操作,需要注意的是list是链表,并不会涉及到界线的判断,而deque是由数组来存储的,所以需要随时对界限进行判断。
push的实现:
template <class T, class Alloc = alloc, size_t BufSiz = 0>
class deque {
...
public: // push_* and pop_*
// 对尾进行插入
// 判断函数是否达到了数组尾部. 没有达到就直接进行插入
void push_back(const value_type& t) {
if (finish.cur != finish.last - 1) {
construct(finish.cur, t);
++finish.cur;
}
else
push_back_aux(t);
}
// 对头进行插入
// 判断函数是否达到了数组头部. 没有达到就直接进行插入
void push_front(const value_type& t) {
if (start.cur != start.first) {
construct(start.cur - 1, t);
--start.cur;
}
else
push_front_aux(t);
}
...
};
pop的实现:
template <class T, class Alloc = alloc, size_t BufSiz = 0>
class deque {
...
public:
// 对尾部进行操作
// 判断是否达到数组的头部. 没有到达就直接释放
void pop_back() {
if (finish.cur != finish.first) {
--finish.cur;
destroy(finish.cur);
}
else
pop_back_aux();
}
// 对头部进行操作
// 判断是否达到数组的尾部. 没有到达就直接释放
void pop_front() {
if (start.cur != start.last - 1) {
destroy(start.cur);
++start.cur;
}
else
pop_front_aux();
}
...
};
pop和push都先调用了reserve_map_at_XX函数,这些函数主要为了判断前后空间是否足够。
删除操作
构造函数都会调用create_map_and_nodes函数,考虑到deque实现前后插入时间复杂度为O(1),保证了在前后留出了空间,所以push和pop都可以在前面的数组进行操作。
现在来分析erase,因为deque是由数组构成,所以地址空间是连续的,删除也就像vector一样,需要移动所有的元素。
deque为了保证效率尽可能高,就判断删除的位置上中间偏后还是中间偏前来进行移动。
template <class T, class Alloc = alloc, size_t BufSiz = 0>
class deque {
...
public: // erase
iterator erase(iterator pos) {
iterator next = pos;
++next;
difference_type index = pos - start;
// 删除的地方是中间偏前, 移动前面的元素
if (index < (size() >> 1)) {
copy_backward(start, pos, next);
pop_front();
}
// 删除的地方是中间偏后, 移动后面的元素
else {
copy(next, finish, pos);
pop_back();
}
return start + index;
}
// 范围删除, 实际也是调用上面的erase函数.
iterator erase(iterator first, iterator last);
void clear();
...
};
最后说一下insert函数。
deque源码,基本每一个insert重载函数都会调用insert_auto判断插入的位置离头还是尾比较近。
如果离头近,则先将头往前移动,调整将要移动的距离,用copy进行调整。
如果离尾近,则将往前移动,调整将要移动的距离,用copy进行调整。
注意:
push_back则先执行构造再移动node,而push_front是先移动node再进行构造,实现的差异主要是finish是指向最后一个元素的后一个地址,而first指向的是第一个元素的地址,下面pop也是一样的。
deque源码里还有一些其它的成员函数:
reallocate_map:判断中考的容量是否够用,如果不够用,申请更大的空间,拷贝元素过去,修改map和start,finish的指向。
fill_initialize:申请空间,对每个空间进行初始化,最后一个数组单独处理。毕竟最后一个数组一般不会全部填满。
clear:删除所有的元素,分两步执行:
首先,从第二个数组开始到倒数第二个数组一次性全部删除,这样做是考虑到中间的数组肯定都是满的,前后两个数组则不一定是满的,最后删除前后两个数组元素。
deque的swap操作:只是交换了start,finish,map,并没有交换所有的元素。
resize:重新将deque进行调整,实现方式与list一样。
析构函数:分步释放内存。
7、deque总结
deque实际上是在功能上合并了vector和list。
优点:
- 随机访问方便,即支持[]操作和vector.at();
- 在内部方便的进行插入和删除操作;
- 可在两端进行push、pop。
缺点:
- 因为涉及数据结构的维护比较复杂,采用分段连续空间,所以占有内存相对多。
使用区别:
- 如果需要高效的随机存储,而不在乎插入和删除的效率,则使用vector。
- 如果需要大量的插入和删除,而不关心随机存取,则应使用list。
- 如果需要随机存取,且关心亮度数据的插入和删除,则应使用deque。
deque概述的更多相关文章
- deque源码1(deque概述、deque中的控制器)
deque源码1(deque概述.deque中的控制器) deque源码2(deque迭代器.deque的数据结构) deque源码3(deque的构造与内存.ctor.push_back.push_ ...
- STL deque详解
英文原文:http://www.codeproject.com/Articles/5425/An-In-Depth-Study-of-the-STL-Deque-Container 绪言 这篇文章深入 ...
- 带你深入理解STL之Deque容器
在介绍STL的deque的容器之前,我们先来总结一下vector和list的优缺点.vector在内存中是分配一段连续的内存空间进行存储,其迭代器采用原生指针即可,因此其支持随机访问和存储,支持下标操 ...
- deque源码4(deque元素操作:pop_back、pop_front、clear、erase、insert)
deque源码1(deque概述.deque中的控制器) deque源码2(deque迭代器.deque的数据结构) deque源码3(deque的构造与内存.ctor.push_back.push_ ...
- deque源码3(deque的构造与内存、ctor、push_back、push_front)
deque源码1(deque概述.deque中的控制器) deque源码2(deque迭代器.deque的数据结构) deque源码3(deque的构造与内存.ctor.push_back.push_ ...
- deque源码2(deque迭代器、deque的数据结构)
deque源码1(deque概述.deque中的控制器) deque源码2(deque迭代器.deque的数据结构) deque源码3(deque的构造与内存.ctor.push_back.push_ ...
- Deque(队列)
目录 Deque 概述 特点 常用方法 双向队列操作 ArrayDeque Deque 概述 一个线性 collection,支持在两端插入和移除元素.名称 deque 是"double e ...
- 【c++】标准模板库STL入门简介与常见用法
一.STL简介 1.什么是STL STL(Standard Template Library)标准模板库,主要由容器.迭代器.算法.函数对象.内存分配器和适配器六大部分组成.STL已是标准C++的一部 ...
- STL源码剖析读书笔记--第四章--序列式容器
1.什么是序列式容器?什么是关联式容器? 书上给出的解释是,序列式容器中的元素是可序的(可理解为可以按序索引,不管这个索引是像数组一样的随机索引,还是像链表一样的顺序索引),但是元素值在索引顺序的方向 ...
随机推荐
- treecnt 算法马拉松20(告别美国大选及卡斯特罗)
treecnt 基准时间限制:1 秒 空间限制:131072 KB 给定一棵n个节点的树,从1到n标号.选择k个点,你需要选择一些边使得这k个点通过选择的边联通,目标是使得选择的边数最少. 现需要计算 ...
- 【机器学习】matplotlib库练习-函数绘图
# 1创建2个图形区域,一个叫做green,大小是16,8,一个叫做red,大小是10,6 # 2绿色区域画一条绿色的正弦曲线,红色区域化两条线,一条是绿色的正弦曲线,一条是红色的余弦曲线 # 3在g ...
- 第十个知识点:RSA和强RSA问题有什么区别?
第十个知识点:RSA和强RSA问题有什么区别 这个密码学52件事数学知识的第一篇,也是整个系列的第10篇.这篇介绍了RSA问题和Strong-RSA问题,指出了这两种问题的不同之处. 密码学严重依赖于 ...
- Spring Boot实战三:集成RabbitMQ,实现消息确认
Spring Boot集成RabbitMQ相比于Spring集成RabbitMQ简单很多,有兴趣了解Spring集成RabbitMQ的同学可以看我之前的<RabbitMQ学习笔记>系列的博 ...
- 知识增强的预训练语言模型系列之ERNIE:如何为预训练语言模型注入知识
NLP论文解读 |杨健 论文标题: ERNIE:Enhanced Language Representation with Informative Entities 收录会议:ACL 论文链接: ht ...
- 3 - 基于ELK的ElasticSearch 7.8.x技术整理 - 高级篇( 偏理论 )
4.ES高级篇 4.1.集群部署 集群的意思:就是将多个节点归为一体罢了( 这个整体就有一个指定的名字了 ) 4.1.1.window中部署集群 - 了解即可 把下载好的window版的ES中的dat ...
- CAS学习笔记三:SpringBoot自动配置与手动配置过滤器方式集成CAS客户端
本文目标 基于SpringBoot + Maven 分别使用自动配置与手动配置过滤器方式集成CAS客户端. 需要提前搭建 CAS 服务端,参考 https://www.cnblogs.com/hell ...
- nginxWebUI
nginx网页配置工具 github: https://github.com/cym1102/nginxWebUI 功能说明 本项目可以使用WebUI配置nginx的各项功能, 包括http协议转发, ...
- Java实现单词统计
原文链接: https://www.toutiao.com/i6764296608705151496/ 单词统计的是统计一个文件中单词出现的次数,比如下面的数据源 其中,最终出现的次数结果应该是下面的 ...
- 函数实现将 DataFrame 数据直接划分为测试集训练集
虽然 Scikit-Learn 有可以划分数据集的函数 train_test_split ,但在有些特殊情况我们只希望它将 DataFrame 数据直接划分为 train, test 而不是像 tr ...