Sentry 监控 - Snuba 数据中台架构(Query Processing 简介)

系列
- 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本
- 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps
- Sentry For React 完整接入详解
- Sentry For Vue 完整接入详解
- Sentry-CLI 使用详解
- Sentry Web 性能监控 - Web Vitals
- Sentry Web 性能监控 - Metrics
- Sentry Web 性能监控 - Trends
- Sentry Web 前端监控 - 最佳实践(官方教程)
- Sentry 后端监控 - 最佳实践(官方教程)
- Sentry 监控 - Discover 大数据查询分析引擎
- Sentry 监控 - Dashboards 数据可视化大屏
- Sentry 监控 - Environments 区分不同部署环境的事件数据
- Sentry 监控 - Security Policy 安全策略报告
- Sentry 监控 - Search 搜索查询实战
- Sentry 监控 - Alerts 告警
- Sentry 监控 - Distributed Tracing 分布式跟踪
- Sentry 监控 - 面向全栈开发人员的分布式跟踪 101 系列教程(一)
- Sentry 监控 - Snuba 数据中台架构简介(Kafka+Clickhouse)
- Sentry 监控 - Snuba 数据中台架构(Data Model 简介)
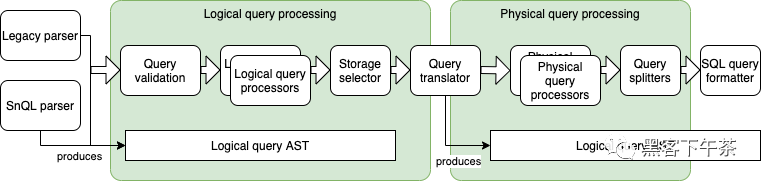
Snuba 有一个查询处理管道,首先将 Snuba 查询语言( legacy 和 SnQL)解析为 AST,然后在 Clickhouse 上执行 SQL 查询。在这两个阶段之间,在 AST 上执行几次传递以应用查询处理转换。
处理管道有两个主要目标:优化查询并防止对我们的基础设施构成危险的查询。
在数据模型上,查询处理流水线分为逻辑部分,进行产品相关处理,物理部分专注于优化查询。
逻辑部分包含查询验证等步骤,以确保它与数据模型匹配或应用自定义函数。 物理部分包括诸如提升标签(promoting tags)和选择预聚合视图(pre-aggregated view)来为查询提供服务等步骤。
查询处理阶段
本节介绍了上述各阶段的代码和示例,并提供了一些提示。
Legacy 和 SnQL 解析器
Snuba 支持两种语言,传统的基于 JSON 的语言和新的名为 SnQL 的语言。除了传统语言不支持的连接和复合查询之外,查询处理管道不会更改是否使用一种或另一种语言。
Snuba 支持两种语言,一种是基于 JSON 的旧语言,另一种是名为 SnQL 的新语言。 除了遗留语言不支持的连接和复合查询之外,无论使用哪种语言,查询处理管道都不会改变。
它们都生成一个逻辑查询AST,该查询由下面数据结构表示。
基于 JSON 的语言旧解析器源码:
SnQL 解析器:
查询验证(Query Validation)
此阶段确保可以运行查询(大多数情况下,我们还没有捕获所有可能的无效查询)。 这个阶段的职责是在无效查询的情况下返回一个 HTTP400,并向用户提供适当的有用消息。
这分为两个子阶段:一般验证(general validation)和实体特定验证(entity specific validation)。
一般验证由一组检查组成,这些检查在解析器生成查询之后立即应用于每个查询。这在 QueryEntity 函数中发生。这包括防止别名阴影(alias shadowing)和函数签名验证(function signature validation)等验证。
- QueryEntity:https://github.com/getsentry/snuba/blob/master/snuba/query/parser/init.py#L91
每个实体也可以以必需列的形式提供一些验证逻辑。这发生在 class Entity(Describable, ABC):。 这允许查询处理拒绝在 project_id 上没有条件或没有时间范围的查询。
逻辑查询处理器(Logical Query Processors)
查询处理器是无状态转换,接收查询对象(及其 AST)并就地转换。这是为逻辑处理器实现的接口。在逻辑阶段,每个实体提供按顺序应用的查询处理器。常见的用例是像 apdex 这样的自定义函数,或者像时间序列处理器(time series processor)那样的计时。
- apdex: https://github.com/getsentry/snuba/blob/10b747da57d7d833374984d5eb31151393577911/snuba/query/processors/performance_expressions.py#L12-L20
- time series processor:https://github.com/getsentry/snuba/blob/master/snuba/query/processors/timeseries_processor.py
查询处理器不应该依赖于在之前或之后执行的其他处理器,并且应该彼此独立。
存储选择器(Storage Selector)
如 Snuba 数据模型中所述,每个实体可以定义多个存储。 多个存储代表多个表,并且出于性能原因可以定义物化视图(materialized views),因为某些视图可以更快地响应某些查询。
在逻辑处理阶段(完全基于实体)结束时,存储选择器可以检查查询并为查询选择合适的存储。 存储选择器在实体数据模型中定义并实现此接口。 一个例子是 Errors 实体,它有两个存储,一个用于一致查询(它们被路由到写入事件的相同节点),另一个只包括我们没有写入的副本来服务大多数查询。 这减少了我们写入的节点上的负载。
查询转换器(Query Translator)
不同的 storage 有不同的 schema(这些反映了 clickhouse 表或视图的 schema)。 它们通常都与实体模型不同,最显着的例子是用于标签 tags[abc] 的可下标表达式,它在 clickhouse 中不存在,其中访问标签看起来像 tags.values[indexOf(tags.key, 'abc')]。
选择 storage 后,需要将查询转换为物理查询。Translator 是一个基于规则的系统,规则由实体(针对每个 storage)定义并按顺序应用。
与查询处理器相反,翻译规则在查询上没有完整的上下文,只能翻译单个表达式。 这使我们能够轻松地编写翻译规则并跨实体重用它们。
这些是 transactions 实体的转换规则。
物理查询处理器(Physical Query Processors)
与逻辑查询处理器相比,物理查询处理器的工作方式非常相似。它们的接口非常相似,语义相同。 不同之处在于它们对物理查询进行操作,因此,它们主要是为优化而设计的。 例如,该处理器在标签上找到相等条件,并将它们替换为标签哈希图(有布隆过滤器索引)上的等效条件,从而使过滤操作更快。
查询拆分器(Query Splitter)
通过将某些查询拆分为多个单独的 Clickhouse 查询并组合每个查询的结果,可以以优化的方式执行某些查询。
两个例子是时间拆分和列拆分。两者都在下面这个文件中。
时间拆分(Time splitting)将一个查询(不包含聚合且已正确排序)在一个可变的时间范围内拆分为多个查询,该时间范围的大小逐渐增大,并在得到足够的结果后按顺序停止执行。
列拆分(Column splitting)拆分筛选和列获取。它对最少数量的列执行查询的筛选部分,以便 Clickhouse 加载较少的列,然后通过第二个查询,仅为第一个查询筛选的行获取缺少的列。
查询格式化器(Query Formatter)
该组件只是将查询格式化为 Clickhouse 查询字符串。
复合查询处理
上面的讨论仅适用于简单查询、复合查询(连接和包含子查询的查询遵循稍微不同的路径)。
上面讨论的简单查询管道不适用于连接查询或包含子查询的查询。 为了使这项工作发挥作用,每个步骤都必须考虑连接的查询和子查询,这会增加过程的复杂性。
为了解决这个问题,我们将每个连接查询转换为多个简单子查询的连接。每个子查询都是一个简单的查询,可以通过上述管道进行处理。这也是运行 Clickhouse 连接(join)的首选方式,因为它允许我们在连接之前应用过滤器。

此类查询的查询处理管道由与上述内容相关的几个附加步骤组成。
子查询生成器(Subquery Generator)
该组件采用一个简单的 SnQL 连接查询,并为连接中的每个表创建一个子查询。
表达式下推(Expressions Push Down)
上一步生成的查询将是一个有效的连接,但效率极低。 这一步基本上是一个连接优化器(join optimizer),它将所有可以成为子查询一部分的表达式下推到子查询中。 这是一个独立于子查询处理的必要步骤,因为 Clickhouse join 引擎不执行任何表达式下推,所以它由 Snuba 来优化查询。
简单查询处理管道(Simple Query Processing Pipeline)
这与上面讨论的从逻辑查询验证到物理查询处理器的管道相同。
连接优化(Join Optimizations)
在处理结束时,我们可以对整个复合查询应用一些优化,例如将 join 转换为 Semi Join。
Sentry 监控 - Snuba 数据中台架构(Query Processing 简介)的更多相关文章
- Sentry 监控 - Snuba 数据中台架构(SnQL 查询语言简介)
本文描述了 Snuba 查询语言 (SnQL). 系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒 ...
- Sentry 监控 - Snuba 数据中台架构(Data Model 简介)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构(编写和测试 Snuba 查询)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台架构简介(Kafka+Clickhouse)
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Snuba 数据中台本地开发环境配置实战
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - 私有 Docker Compose 部署与故障排除详解
内容整理自官方开发文档 系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Map ...
- Sentry 监控 - Environments 区分不同部署环境的事件数据
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- Sentry 监控 - Distributed Tracing 分布式跟踪
系列 1 分钟快速使用 Docker 上手最新版 Sentry-CLI - 创建版本 快速使用 Docker 上手 Sentry-CLI - 30 秒上手 Source Maps Sentry For ...
- 【转】阿里架构总监一次讲透中台架构,13页PPT精华详解
转:https://blog.csdn.net/u011323949/article/details/99542576 本文整理了阿里几位技术专家,如架构总监 谢纯良,中间件技术专家 玄难等几位大牛, ...
随机推荐
- git rebase和git merge的区别
前言: 平时工作中发现一般同事在同步远程代码的时候都是用git pull,其实git pull包含有两个操作,一个是fetch远程的代码,一个是将本地当前的代码和远程代码进行merge,即git ...
- 使用栅格系统开发响应式页面——logo+nav实例
小屏时: 中屏及以上时: <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- Ubuntu 配置、使用samba共享文件夹
安装库 sudo apt install smbclient samba samba-common 启动samba sudo /etc/init.d/samba start 备份配置文件 sudo c ...
- Ubuntu18.04 + NVidia显卡 + Anaconda3 + Tensorflow-GPU 安装、配置、测试 (无需手动安装CUDA)
其中其决定作用的是这篇文章 https://www.pugetsystems.com/labs/hpc/Install-TensorFlow-with-GPU-Support-the-Easy-Wa ...
- Learning ROS: Ubuntu16.04下kinetic开发环境安装和初体验 Install + Configure + Navigating(look around) + Creating a Package(catkin_create_pkg) + Building a Package(catkin_make) + Understanding Nodes
本文主要部分来源于ROS官网的Tutorials. Ubuntu install of ROS Kinetic # Setup your sources.list sudo sh -c 'echo & ...
- 超详细kafka教程来啦
Kafka的概念和入门 Kafka是一个消息系统.由LinkedIn于2011年设计开发. Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度O(1)的方式提供消息持 ...
- 剑指offer(一)——二维数组中的查找
题目描述 在一个二维数组中(每个一维数组的长度相同),每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序.请完成一个函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数 ...
- 性能测试必备命令(3)- lscpu
性能测试必备的 Linux 命令系列,可以看下面链接的文章哦 https://www.cnblogs.com/poloyy/category/1819490.html 介绍 显示有关CPU架构的信息 ...
- Docker 容器间的单向连接
Docker 容器间的单向连接 前言 a. 本文主要为 Docker的视频教程 笔记. b. 环境为 CentOS 7.0 云服务器 c. 上一篇:Dockerfile 自动制作 Docker 镜像( ...
- 手把手教你实现栈以及C#中Stack源码分析
定义 栈又名堆栈,是一种操作受限的线性表,仅能在表尾进行插入和删除操作. 它的特点是先进后出,就好比我们往桶里面放盘子,放的时候都是从下往上一个一个放(入栈),取的时候只能从上往下一个一个取(出栈), ...