浅析PriorityBlockingQueue优先级队列原理
介绍
当你看本文时,需要具备以下知识点
二叉树、完全二叉树、二叉堆、二叉树的表示方法
如果上述内容不懂也没关系可以先看概念。
PriorityBlockingQueue是一个无界的基于数组的优先级阻塞队列,数组的默认长度是11,虽然指定了数组的长度,但是可以无限的扩充,直到资源消耗尽为止,每次出队都返回优先级别最高的或者最低的元素。其实内部是由平衡二叉树堆来进行排序的,先进行构造二叉树堆,二叉树堆排序出来的数每次第一个元素和最后一个元素进行交换,这样最大的或最小的数就到了最后面,然后最后一个不变,重新构造前面的数组元素以此类推进行堆排序。默认比较器是null,也就是使用队列中元素的compareTo方法进行比较,意味着队列元素要实现Comparable接口。
- PriorityBlockingQueue是一个无界队列,队列满时没有进行阻塞限制,也就是没有notFull进行阻塞,所以put是非阻塞的。
- lock锁独占锁控制只有一个线程进行入队、出队操作。
平衡二叉树堆
二叉堆的本质其实是一个完全二叉树,它分为两种类型:
- 最大堆:最大堆的任何一个父节点的值都大于或等于它的左、右孩子节点的值。
- 最小堆:最小堆的任何一个父节点的值都小于或等于它的左、右孩子节点的值。
二叉堆的根节点叫做堆顶。
最大堆和最小堆的特点:最大堆的堆顶是整个堆中最大元素,最小堆的堆顶是整个堆中最小元素。
我们知道二叉堆内部实现其实是基于数组来实现的,为什么二叉堆又能使用数组来实现呢?因为二叉堆是完全二叉树,并不会浪费空间资源,对于稀疏二叉树如果使用数组来实现会有很多左右结点为空的情况,数组中需要进行占位处理,占位处理就会浪费很多空间,得不偿失,但是二叉堆是一个完全二叉树,所以不会有资源的浪费。
数组下标表示方法:
左节点:2*parent+1
右节点:2*parent+2
n坐标节点父节点:n/2
PriorityBlockingQueue类图结构
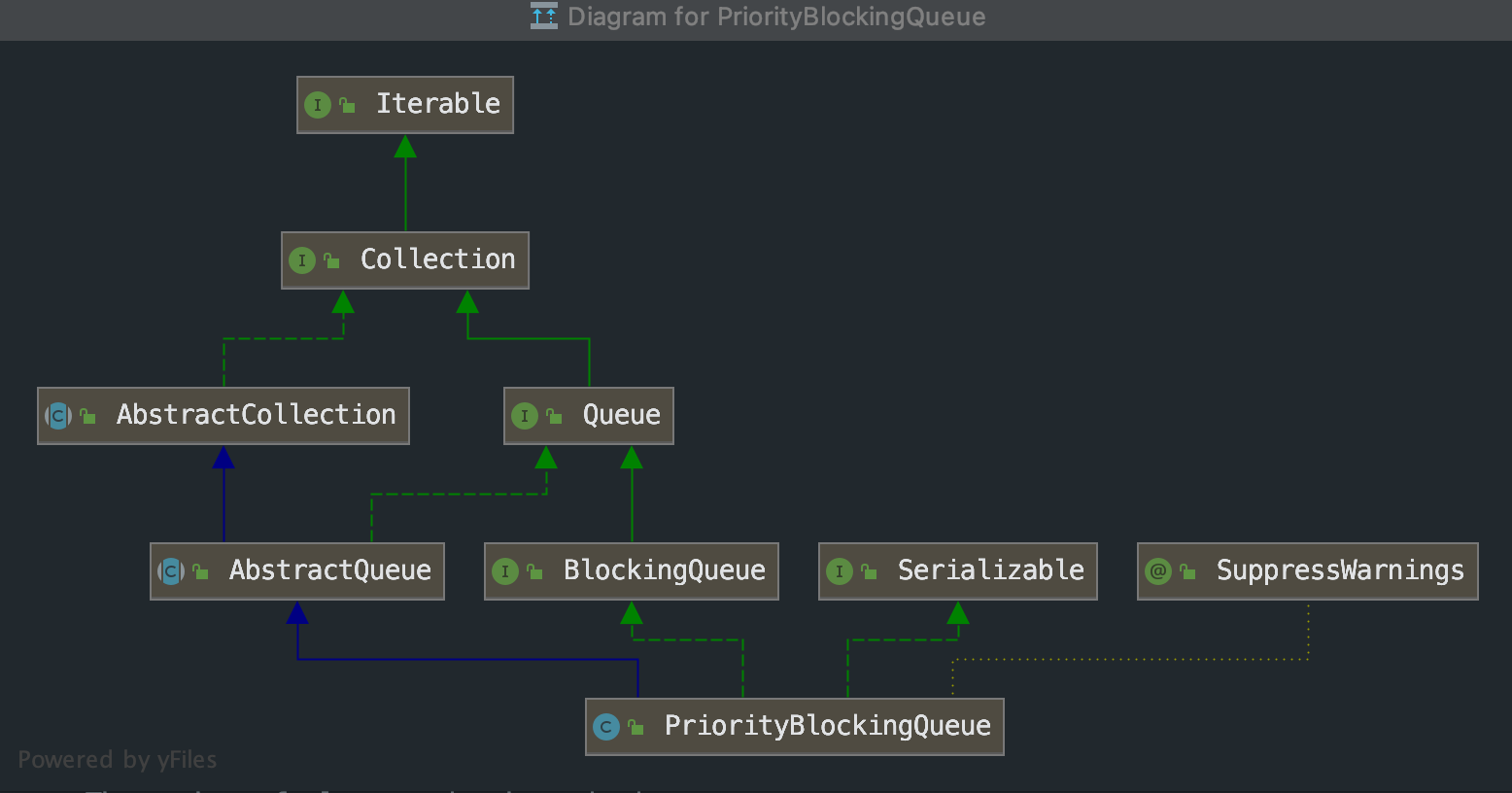
源码分析
通过类图可以清晰的发现它其实也是继承自BlockingQueue接口以及Queue接口,说明也是阻塞队列。在构造函数中默认队列的容量是11,由于上面我们已经提到了,优先队列使用的是二叉堆来实现的,二叉堆实现是根据数组来实现的,所以默认构造器中初始化容量为11,如下代码所示:
/**
* 默认数组长度。
*/
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* 最大数组允许的长度。
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
上面讲述了二叉堆的原理,二叉堆原理肯定是要进行比较大小,默认比较器是null,也就是使用元素的compareTo方法进行比较来确定元素的优先级,就意味着队列元素必须实现Comparable接口,如下是构造函数:
/**
* 创建一个默认长度为11的队列,默认比较器为null。
* Creates a {@code PriorityBlockingQueue} with the default
* initial capacity (11) that orders its elements according to
* their {@linkplain Comparable natural ordering}.
*/
public PriorityBlockingQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
/**
* 创建一个指定数组初始化长度的队列,默认比较器为null。
* Creates a {@code PriorityBlockingQueue} with the specified
* initial capacity that orders its elements according to their
* {@linkplain Comparable natural ordering}.
*
* @param initialCapacity the initial capacity for this priority queue
* @throws IllegalArgumentException if {@code initialCapacity} is less
* than 1
*/
public PriorityBlockingQueue(int initialCapacity) {
this(initialCapacity, null);
}
/**
* 创建一个指定数组初始化长度的队列,比较器可以自己指定。
* Creates a {@code PriorityBlockingQueue} with the specified initial
* capacity that orders its elements according to the specified
* comparator.
*
* @param initialCapacity the initial capacity for this priority queue
* @param comparator the comparator that will be used to order this
* priority queue. If {@code null}, the {@linkplain Comparable
* natural ordering} of the elements will be used.
* @throws IllegalArgumentException if {@code initialCapacity} is less
* than 1
*/
public PriorityBlockingQueue(int initialCapacity,
Comparator<? super E> comparator) {
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
this.comparator = comparator;
this.queue = new Object[initialCapacity];
}
/**
* 传入一个集合,如果集合是SortedSet或PriorityBlockingQueue的话不需要进行堆化,直接使用原有的排序即可,如果不是则需要调用
* heapify方法进行堆初始化操作。
* Creates a {@code PriorityBlockingQueue} containing the elements
* in the specified collection. If the specified collection is a
* {@link SortedSet} or a {@link PriorityQueue}, this
* priority queue will be ordered according to the same ordering.
* Otherwise, this priority queue will be ordered according to the
* {@linkplain Comparable natural ordering} of its elements.
*
* @param c the collection whose elements are to be placed
* into this priority queue
* @throws ClassCastException if elements of the specified collection
* cannot be compared to one another according to the priority
* queue's ordering
* @throws NullPointerException if the specified collection or any
* of its elements are null
*/
public PriorityBlockingQueue(Collection<? extends E> c) {
this.lock = new ReentrantLock();
this.notEmpty = lock.newCondition();
boolean heapify = true; // true表示需要进行堆化也就是初始化基于现有集合初始化一个二叉堆,使用下沉方式。
boolean screen = true; // true表示需要筛选空值
if (c instanceof Sort3edSet<?>) {
// 如果是SortedSet不需要进行堆初始化操作。
SortedSet<? extends E> ss = (SortedSet<? extends E>) c;
this.comparator = (Comparator<? super E>) ss.comparator();
// 不需要进行堆初始化。
heapify = false;
}
else if (c instanceof PriorityBlockingQueue<?>) {
// 如果是PriorityBlockingQueue不需要进行堆初始化操作。
PriorityBlockingQueue<? extends E> pq =
(PriorityBlockingQueue<? extends E>) c;
this.comparator = (Comparator<? super E>) pq.comparator();
// 不需要筛选空值。
screen = false;
if (pq.getClass() == PriorityBlockingQueue.class) // exact match
// 不需要进行堆初始化操作。
heapify = false;
}
// 将集合转换成数组类型。
Object[] a = c.toArray();
// 获取数组的长度大小
int n = a.length;
// If c.toArray incorrectly doesn't return Object[], copy it.
if (a.getClass() != Object[].class)
a = Arrays.copyOf(a, n, Object[].class);
if (screen && (n == 1 || this.comparator != null)) {
for (int i = 0; i < n; ++i)
if (a[i] == null)
throw new NullPointerException();
}
// 将转化数组的对象赋值给队列,以及实际存储的长度。
this.queue = a;
this.size = n;
if (heapify)
// 调整堆大小。
heapify();
}
构造函数中第四个构造函数传递的是一个集合,集合如果是SortSet和PriorityBlockingQueue是不需要进行堆初始化操作,如果是其他集合类型则需要进行堆排序。
private void heapify() {
Object[] array = queue;
int n = size;
// 这里其实就是寻找完全二叉树中最后一个非叶子节点值,由于数组元素是从0开始的下标,长度是从1开始的所以需要减掉1相等于是数组元素下标最后一个元素下标/2得到的值,也就是最后一个元素的父节点。
int half = (n >>> 1) - 1;
Comparator<? super E> cmp = comparator;
if (cmp == null) {
// 循环遍历非叶子节点的值。
for (int i = half; i >= 0; i--)
siftDownComparable(i, (E) array[i], array, n);
}
else {
for (int i = half; i >= 0; i--)
siftDownUsingComparator(i, (E) array[i], array, n, cmp);
}
}
例如我们初始化数组为a=[7,1,3,10,5,2,8,9,6],完全二叉树表示为:
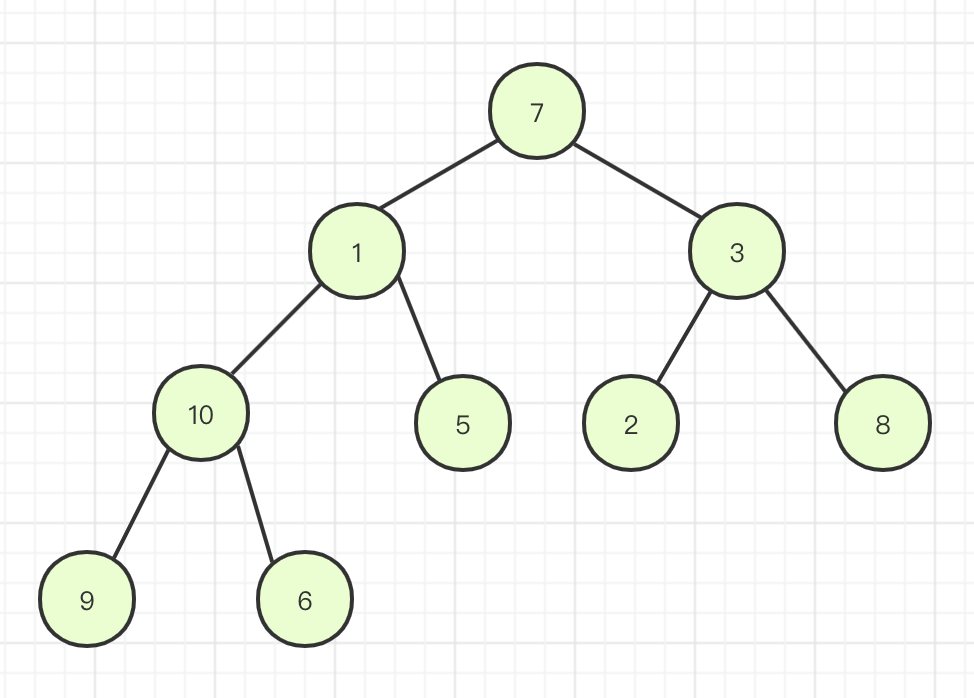
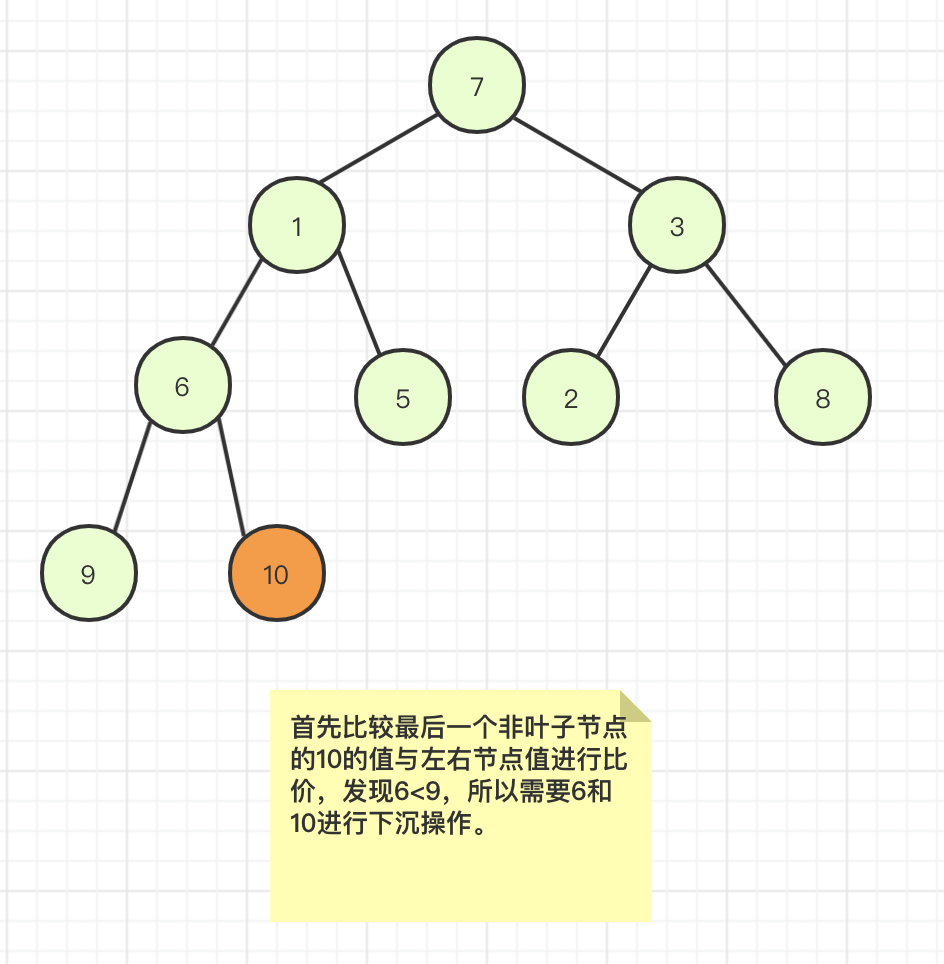
首先half=9/2-1=4-1=3,a[3]=10,刚好是完全二叉树中最后一个非叶子节点,再往上非叶子节点是3,1,7刚好数组下标是递减的,然后针对元素10进行下沉操作,发现左右子树中最小元素是6,则6和10元素进行交换。
然后再下沉元素3,i--操作,得到如下完全二叉树
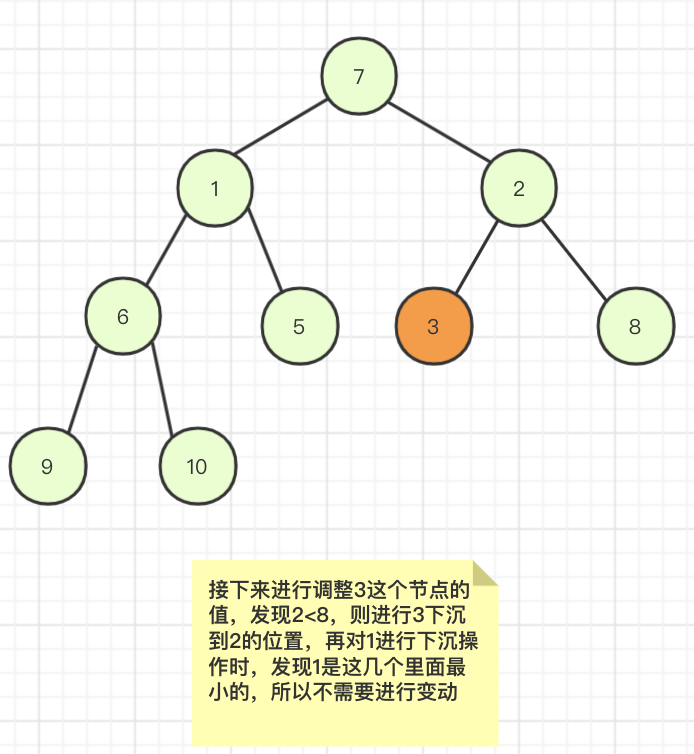
继续遍历下一个非叶子节点,i=2减少1得到i=1,此时a[1]=1左右子节点6和5都比1大所以不需要进行变动,然后i进行减少,则到了i=0,此时a[7]=0,发现左右节点中元素1是最小的,所以先下沉到元素1的位置。
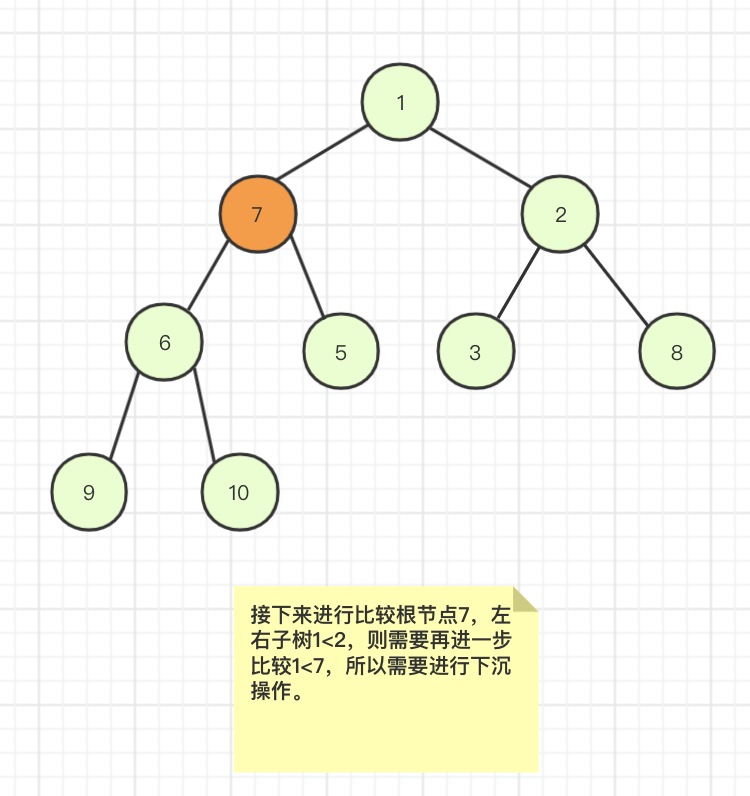
下沉后发现还可以继续下沉,因为左右节点中右节点元素5是最小的所以还需要进行下沉操作。
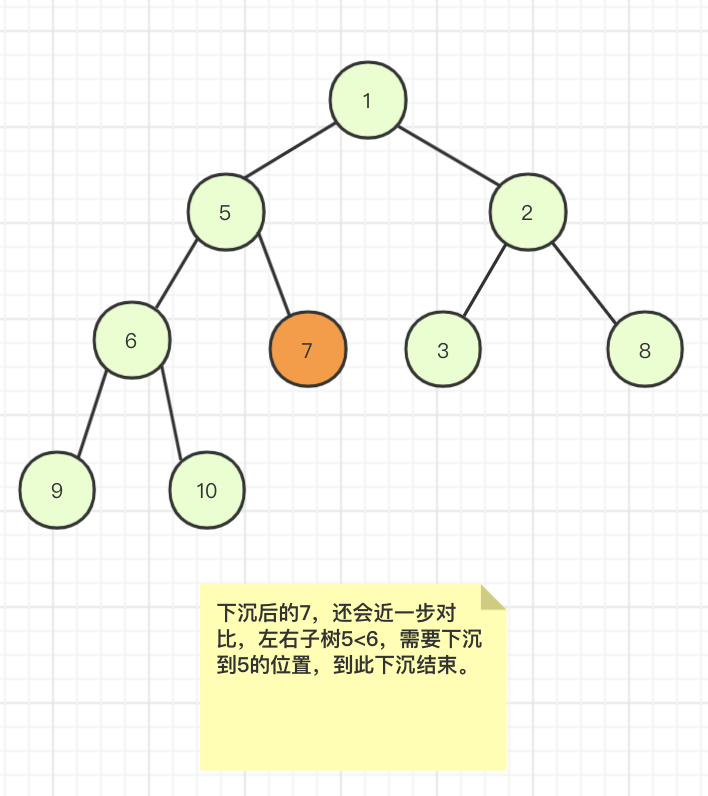
至此下沉结束,二叉堆构建完成。
offer操作
接下来看一下队列是如何进行构建成一个二叉堆的,其实这里面构建二叉堆以及二叉堆获取数据时,会采用上浮和下沉的操作来进行处理整个二叉堆的平衡,详细来看一下offer方法,代码如下所示:
/**
* Inserts the specified element into this priority queue.
* As the queue is unbounded, this method will never return {@code false}.
*
* @param e the element to add
* @return {@code true} (as specified by {@link Queue#offer})
* @throws ClassCastException if the specified element cannot be compared
* with elements currently in the priority queue according to the
* priority queue's ordering
* @throws NullPointerException if the specified element is null
*/
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
// 首先获取锁对象。
final ReentrantLock lock = this.lock;
// 只有一个线程操作入队和出队动作。
lock.lock();
// n代表数组的实际存储内容的大小
// cap代表队列的整体大小,也就是数组的长度。
int n, cap;
Object[] array;
// 如果数组实际长度大于等于数组的长度时,需要进行扩容操作。
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
// 如果用户指定比较器,则使用用户指定的比较器来进行比较,如果没有则使用默认比较器。
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 进行上浮操作。
siftUpComparable(n, e, array);
else
// 进行上浮操作。
siftUpUsingComparator(n, e, array, cmp);
// 实际长度增加1,由于有且仅有一个线程操作队列,所以这里并没有使用原子性操作。
size = n + 1;
// 通知等待的线程,队列已经有数据,可以获取数据。
notEmpty.signal();
} finally {
// 解锁操作。
lock.unlock();
}
// 返回操作成功。
return true;
}
- 首先获取锁对象,控制有且仅有一个线程操作队列。
- 如果数组实际存储的内容大小大于等于数组长度时进行扩容操作,调用
tryGrow方法进行扩容。 - 使用比较器进行比较,进行上浮操作来创建二叉堆。
tryGrow是如何进行扩容的呢?
/**
* Tries to grow array to accommodate at least one more element
* (but normally expand by about 50%), giving up (allowing retry)
* on contention (which we expect to be rare). Call only while
* holding lock.
*
* @param array the heap array
* @param oldCap the length of the array
*/
private void tryGrow(Object[] array, int oldCap) {
// 这里先释放了锁,为什么要释放锁呢?详细请见下面。
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
// 这里allocationSpinLock默认是0,通过CAS来讲该值修改为1,也就是同时只有一个线程进行扩容操作。
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
// 如果原容量小于64,就执行原容量+2,如果原容量大于64,扩大一倍容量。
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
// 新容量超过了最大容量,将容量调整为最大值。
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
// 创建新的数组对象。
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
// 扩容成功,则将值修改为0。
allocationSpinLock = 0;
}
}
// 这里是为了其他线程进入后优先让扩容的线程进行操作。
if (newArray == null) // back off if another thread is allocating
Thread.yield();
// 加锁操作。
lock.lock();
// 将原数据拷贝到新数组中。
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
看似扩容还是很容易理解的,开始的时候为什么要先释放锁呢,然后用CAS控制只有一个线程可以扩容呢?其实可以不释放锁,也能控制只允许一个线程进行扩容操作,但是会产生性能问题,因为当我扩容的时候,一直获得锁会不允许其他线程进行入队和出队操作,扩容的时候先释放锁,也就是可以其他线程进行处理出队和入队操作,例如第一个线程先CAS成功,并且进行扩容中,此时第二个线程进入后allocationSpinLock此时已经等于1了,也就是不会进行扩容操作,而是会直接进入到判断newArray==null,此时线程二发现newArray为null,线程而会调用Thread.yield来让出CPU,目的是让扩容的线程扩容后优先调用lock.lock重新获得锁,但是这又不能完全保证,有可能yield退出了扩容还没有结束,此时线程二获得锁,如果当前数组扩容没有完毕,则线程二会再次调用offer的tryGrow进行扩容操作,再次给扩容线程让出了锁,再次调用yield让出CPU。当扩容线程进行扩容时,其他线程自旋的检测当前线程是否成功,成功了才会进行入队的操作。
扩容成功后就需要构建二叉堆,构建二叉堆调用的是siftUpComparable方法,也就是上浮操作,接下来详细讲解一下上浮操作是如何进行的?
private static <T> void siftUpComparable(int k, T x, Object[] array) {
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
// 找到节点k的父节点。
int parent = (k - 1) >>> 1;
// 获取父节点的值。
Object e = array[parent];
// 比较父节点和插入值的大小,如果插入值大于父节点直接插入到末尾。
if (key.compareTo((T) e) >= 0)
break;
// 将父节点设置到子节点,小数据进行上浮操作。
array[k] = e;
// 将父节点的下标设置给k。
k = parent;
}
// 最后key上浮到k的位置。
array[k] = key;
}
private static <T> void siftUpUsingComparator(int k, T x, Object[] array,
Comparator<? super T> cmp) {
while (k > 0) {
int parent = (k - 1) >>> 1;
Object e = array[parent];
if (cmp.compare(x, (T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = x;
}
为了能够演示算法的整个过程,这里举例来说明一下:
为了演示扩容的过程我们先初始化队列长度为2,后面会进行扩容操作。
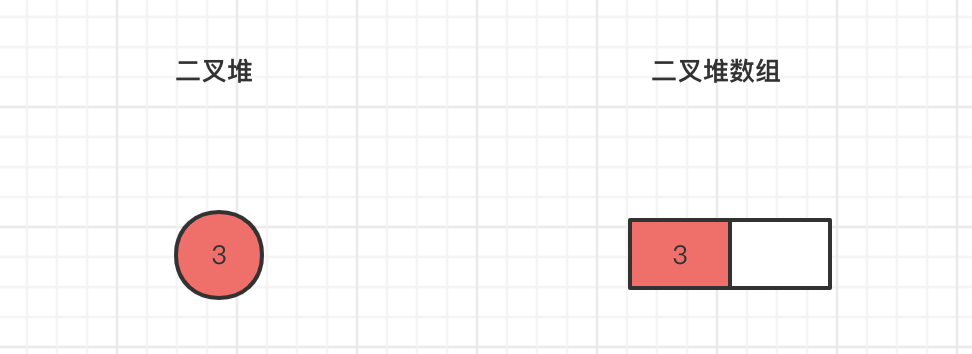
当我们调用offer(3)时,此时k=n=size=0,x是我们要插入的内容,array是二叉堆数组,当我们插入第一个元素是,发现k>0是不成立的,所以直接运行 array[k] = key,此时二叉堆数组只有一个元素3,如下图所示:
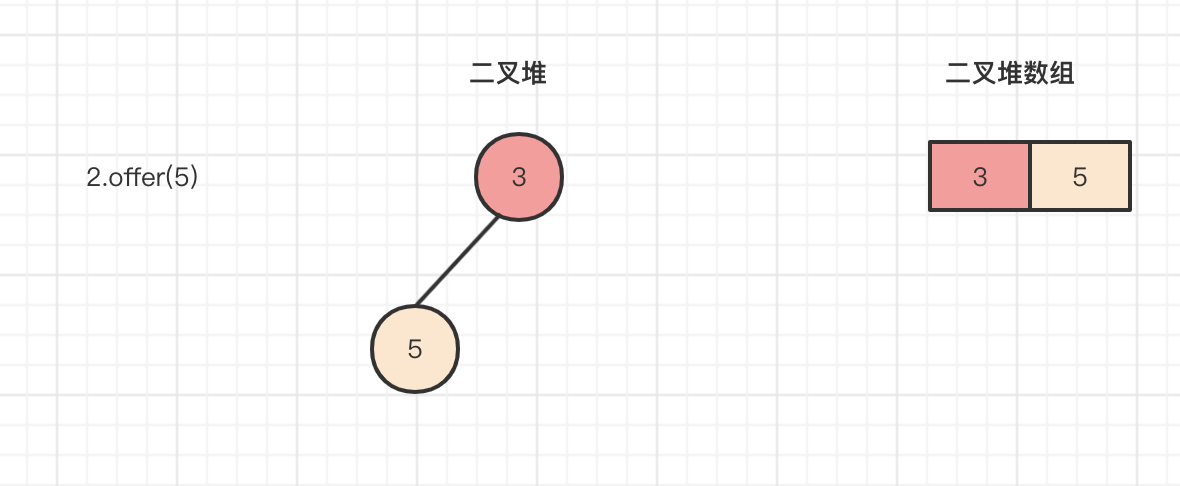
第二次调用offer(5),此时k=n=size=1实际存储长度为1,运行(k-1)>>>1寻找父节点,k-1=0,无符号向右侧移动一位,就相当于是$(k-1)/2$,和开始介绍二叉堆特点的时候寻找父节点是一样的,此时要插入的节点5的父节点是3,需要进行比较3和5的大小,发现父节点小于要插入的节点,所以执行break退出循环,执行array[k] = key操作,将节点5插入到父节点3下面,并且size进行增加1,此时size=2,如下所示:
当第三次调用offer(9)时,此时k=n=size=2,发现
(n = size) >= (cap = (array = queue).length)实际长度与数组的长度相等,此时进行扩容操作,通过上述源码分析得到,oldCap+(oldCap+2)=2+(2+2)=6,数组的长度从长度为2扩容到长度为6,将原有数组内容赋值到新的数组中,扩容之后进入到上浮操作进行入队操作,其实怎么理解呢?可以理解为我们将元素9插入到数组最后一个位置,也就是队列的最后一个位置。
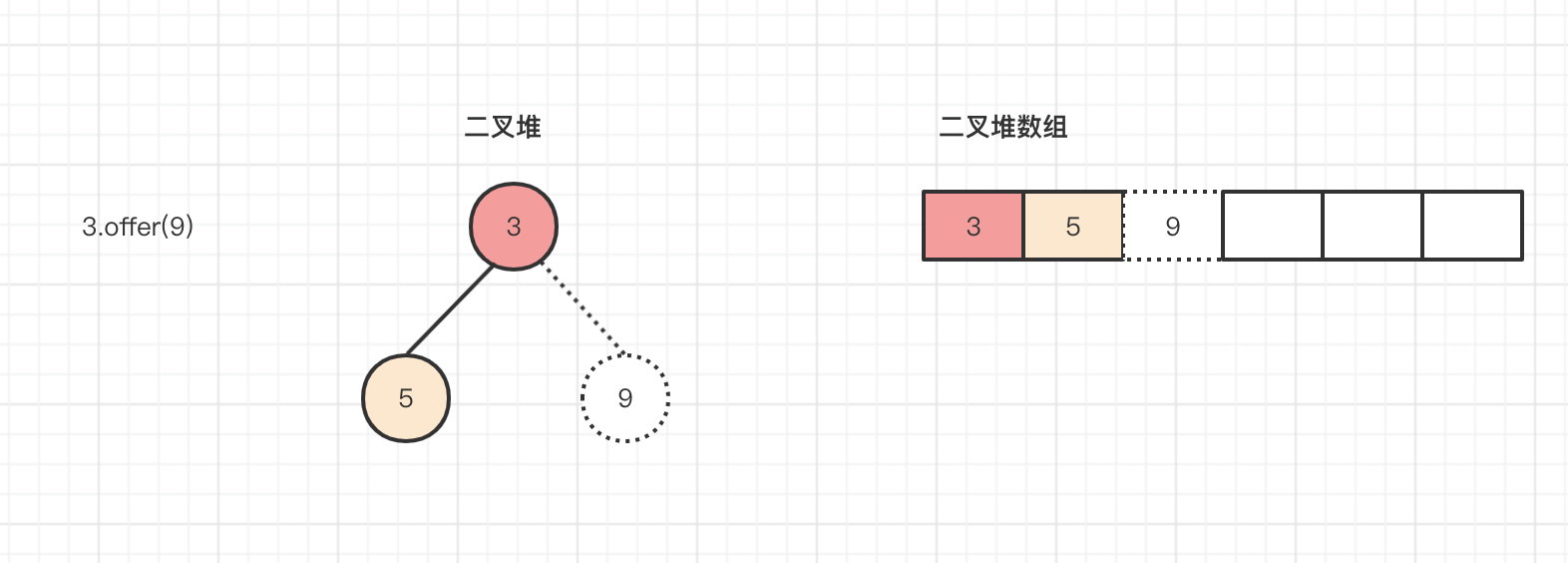
然后9这个元素需要找到它的父节点,那就是3,也即是(k-1)>>>1=(2-1)>>>1得到下标为0,array[0]=3,元素9的父节点是3,比较父节点和子节点大小,发现3<9位置不需要进行变动,则二叉堆就变成如下内容,size进行加1,size=3。
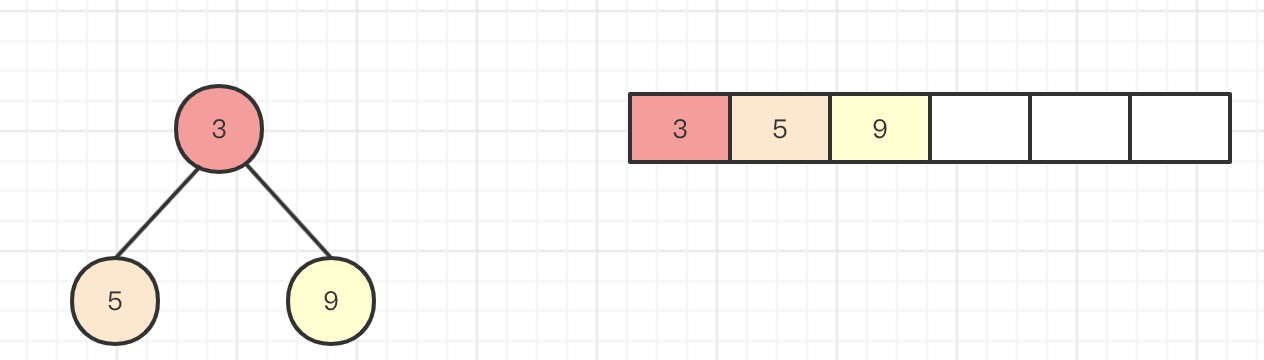
第四次调用offer(2)时,此时k=n=size=3,还是按照上面意思将元素2暂时插入到数组的末尾,然后进行上浮操作,虚线的意思就是告诉你我现在还不一定在不在这里,我要和我的父亲比较下到底谁大,如果父节点大那我只能乖乖在这里喽,如果父节点小,不好意思我得往上浮动了,接下来看一上浮动的过程。
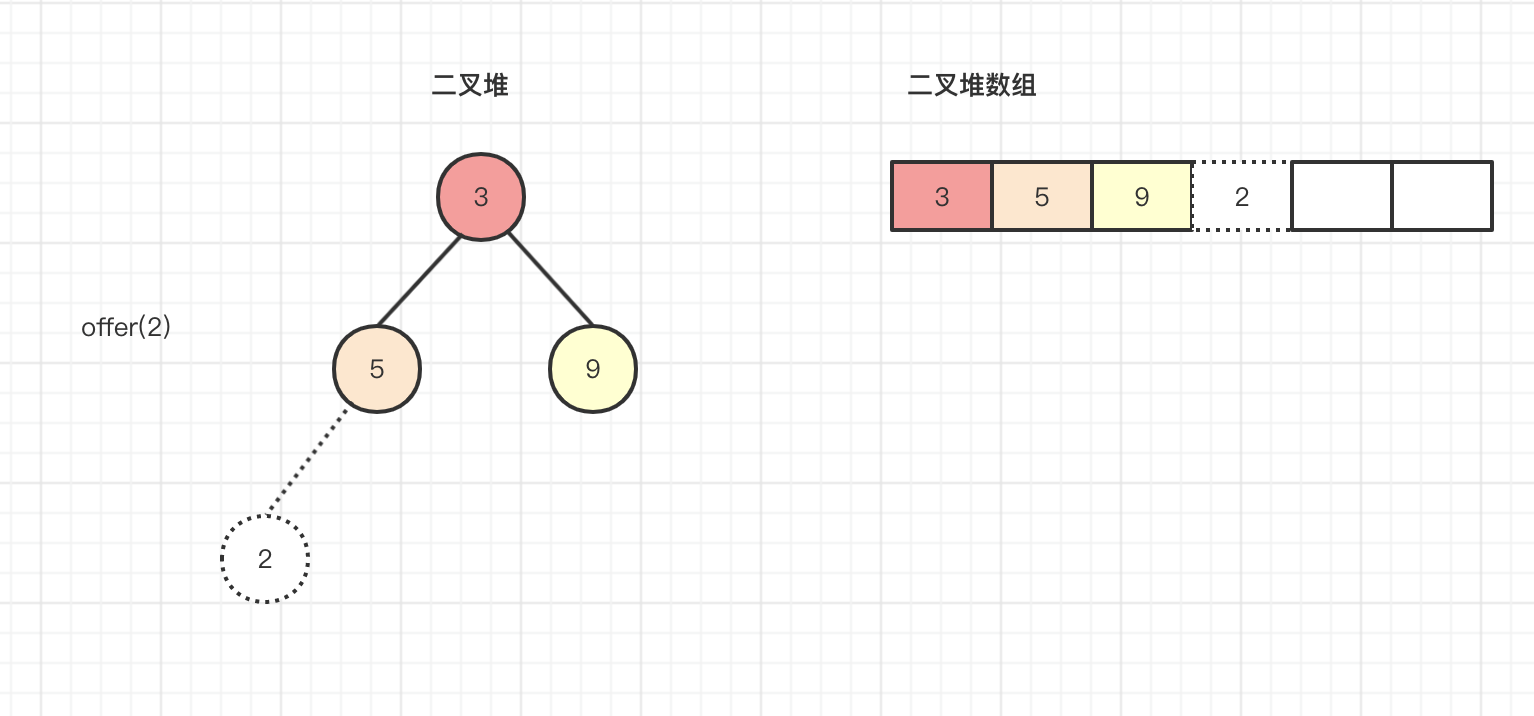
k=3,元素2的父节点=(k-1)>>>1=2>>>1等于1,也就是array[1]的元素5是元素2的父节点,通过上面的二叉图也能够清晰看到元素5是父节点,比较发现2<5,执行array[k] = e,array[3]=5,也就是说将5的位置进行下沉操作,这里源代码并没发现2上浮操作,但是在下一次比较中又用到了我们的元素2进行比较,其实现在树的结构相当于如下所示:

发现刚开始元素2在最后节点,现在被替换成了元素5,这就意味着元素2的位置变到了之前元素5的位置,源码中的k = parent,此时元素2的下标已经变到k=1,但是数组里面的内容并没有变,只是元素下标上浮操作,上浮到父节点,相当于元素2就在元素5的位置,只是下标1的位置元素内容并没有直接替换成元素2仅此而已。接下来还会进行循环,数组下标1的元素的父节点是元素3,这里就不计算了,因为上面第二步计算过,此时发现2<3,需要将元素3的内容进行下沉操作,元素2的下标进行上浮操作。
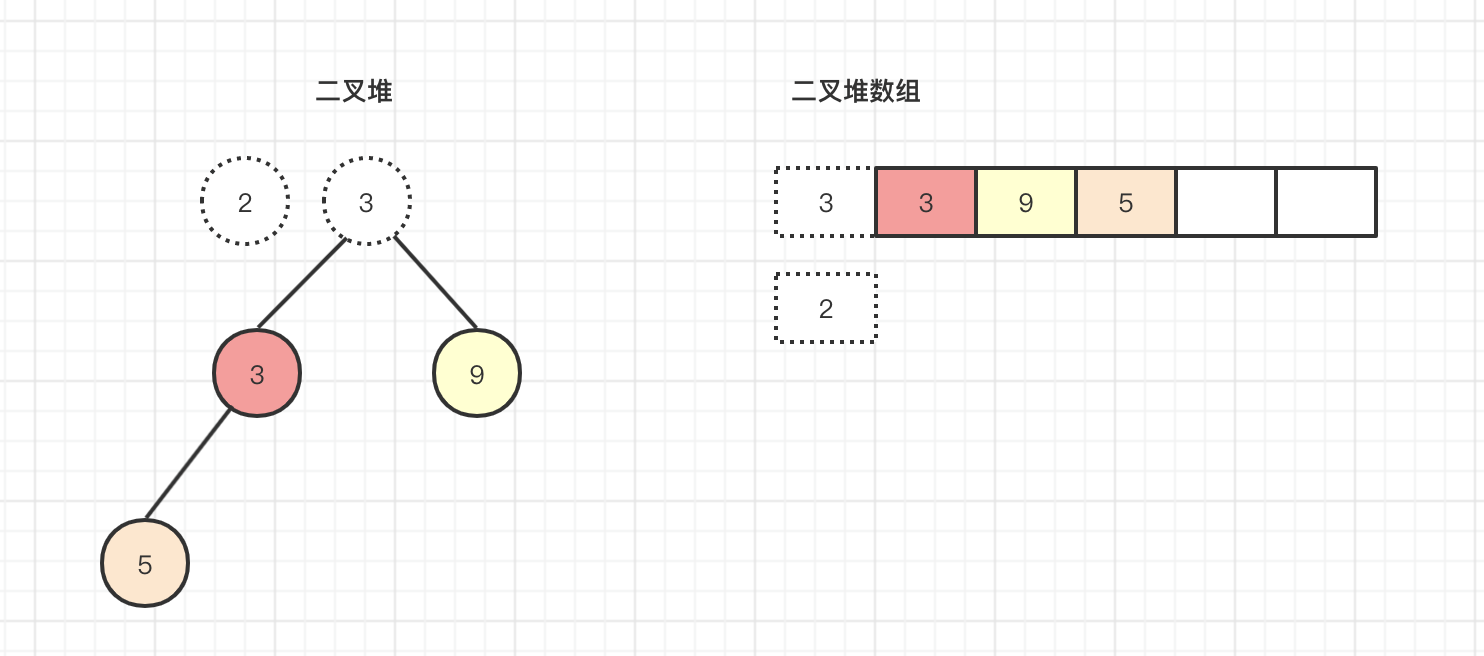
此时下标2的元素移动到父节点下标0的位置,发现k<0,则本次循环结束,将array[0]替换成元素2,本次上浮操作结束。
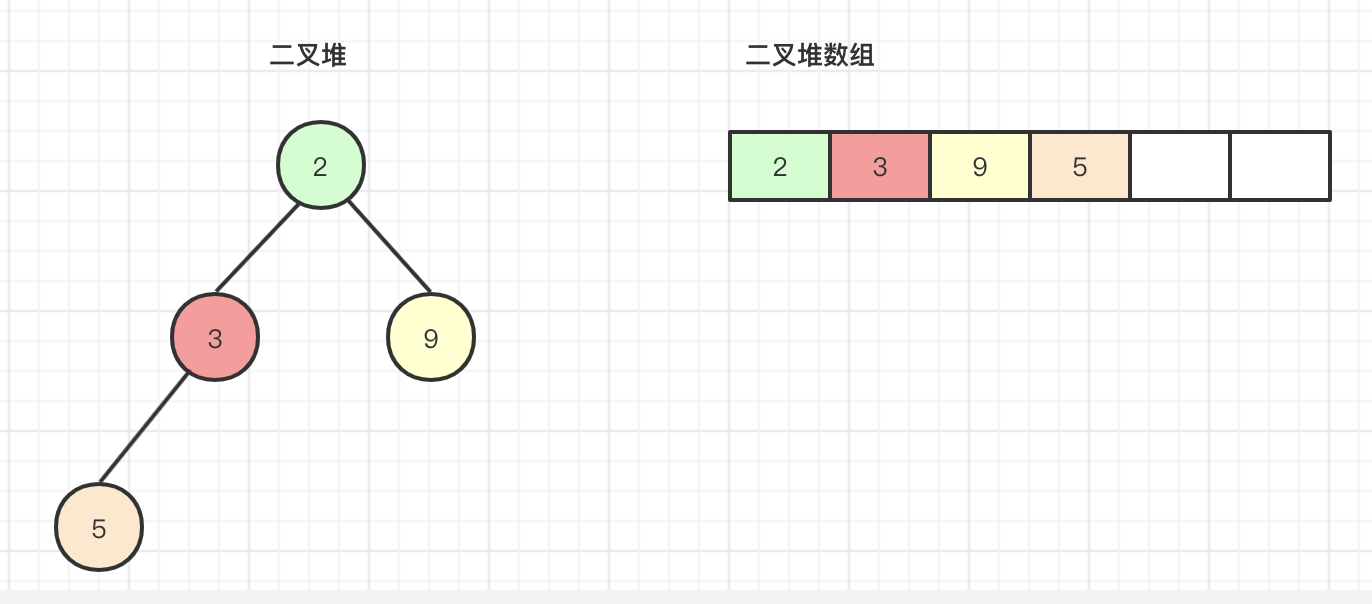
由此可见,次堆为最小二叉堆,当出队操作时弹出的是最小的元素。
poll操作
poll操作就是将队列内部二叉堆的堆顶元素出队操作,如果队列为空则返回null。如下是poll的源码:
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return dequeue();
} finally {
lock.unlock();
}
}
- 首先获取锁对象,进行上锁操作,有且仅有一个线程出队和入队操作
- 获得到锁对象之后进行出队操作,调用
dequeue方法 - 最后释放锁对象
接下来看一下出队操作是如何进行的,
/**
* Mechanics for poll(). Call only while holding lock.
*/
private E dequeue() {
// 数组的元素的个数。
int n = size - 1;
// 如果数组中不存在元素则直接返回null。
if (n < 0)
return null;
else {
// 获取队列数组。
Object[] array = queue;
// 将第一个元素也就是二叉堆的根结点堆顶元素作为返回结果。
E result = (E) array[0];
// 获取数组中最后一个元素。
E x = (E) array[n];
// 将最后一个元素设置为null。
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 进行下沉操作。
siftDownComparable(0, x, array, n);
else
// 进行下沉操作。
siftDownUsingComparator(0, x, array, n, cmp);
// 实际元素大小减少1.
size = n;
// 返回结果。
return result;
}
}
通过源码可以看到,出队的内容就是二叉堆的堆顶元素arrra[0],而后面它有取到的完全二叉树的最后一个节点,将最后一个节点设置为null,然后在调用了siftDownComparable对堆进行了调整动作,看一下这个方法的具体实现内容,然后再结合上面入队的内容进行讲解出队是如何保证二叉堆平衡的。
private static <T> void siftDownComparable(int k, T x, Object[] array, int n) { if (n > 0) { Comparable<? super T> key = (Comparable<? super T>)x; // 最后一个节点的父节点,也就是代表到这里之后就结束了。 int half = n >>> 1; // loop while a non-leaf while (k < half) { // child=2n+1代表leftChild左节点。 int child = (k << 1) + 1; // assume left child is least // 获取左节点的值。 Object c = array[child]; // 获取右节点=2n+1+1=2n+2的坐标 int right = child + 1; // 如果右侧节点坐标小于数组中最有一个元素,并且右节点值小于左侧节点值,则将c设置为右侧节点值。 if (right < n && ((Comparable<? super T>) c).compareTo((T) array[right]) > 0) c = array[child = right]; // 对比c和当前最后一个元素的大小。 if (key.compareTo((T) c) <= 0) break; // 将坐标k位置设置为比较的后的值。 array[k] = c; // 将光标移动到替换的节点上。 k = child; } // 最后将元素最后一个值赋值到k的位置。 array[k] = key; }}private static <T> void siftDownUsingComparator(int k, T x, Object[] array, int n, Comparator<? super T> cmp) { if (n > 0) { int half = n >>> 1; while (k < half) { int child = (k << 1) + 1; Object c = array[child]; int right = child + 1; if (right < n && cmp.compare((T) c, (T) array[right]) > 0) c = array[child = right]; if (cmp.compare(x, (T) c) <= 0) break; array[k] = c; k = child; } array[k] = x; }}
看了源码其实还是有点蒙的,因为根本没有办法想象到是如何实现的,接下来跟着思路一步一步的分析,上面offer时最后二叉堆的情况如下图所示:
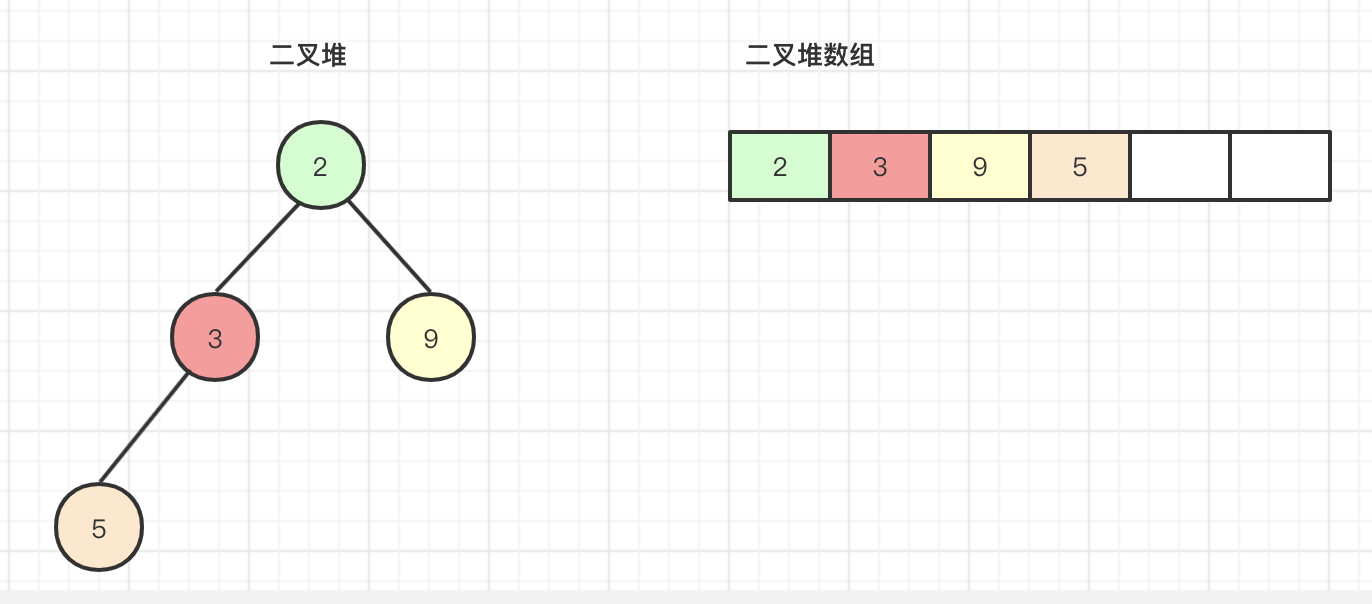
先调用一次poll操作,此时size=4,result=array[0]=2,n=size-1=3,x=array[n]=array[3]=5,将array[3]位置设置为null,就变成如下的二叉堆
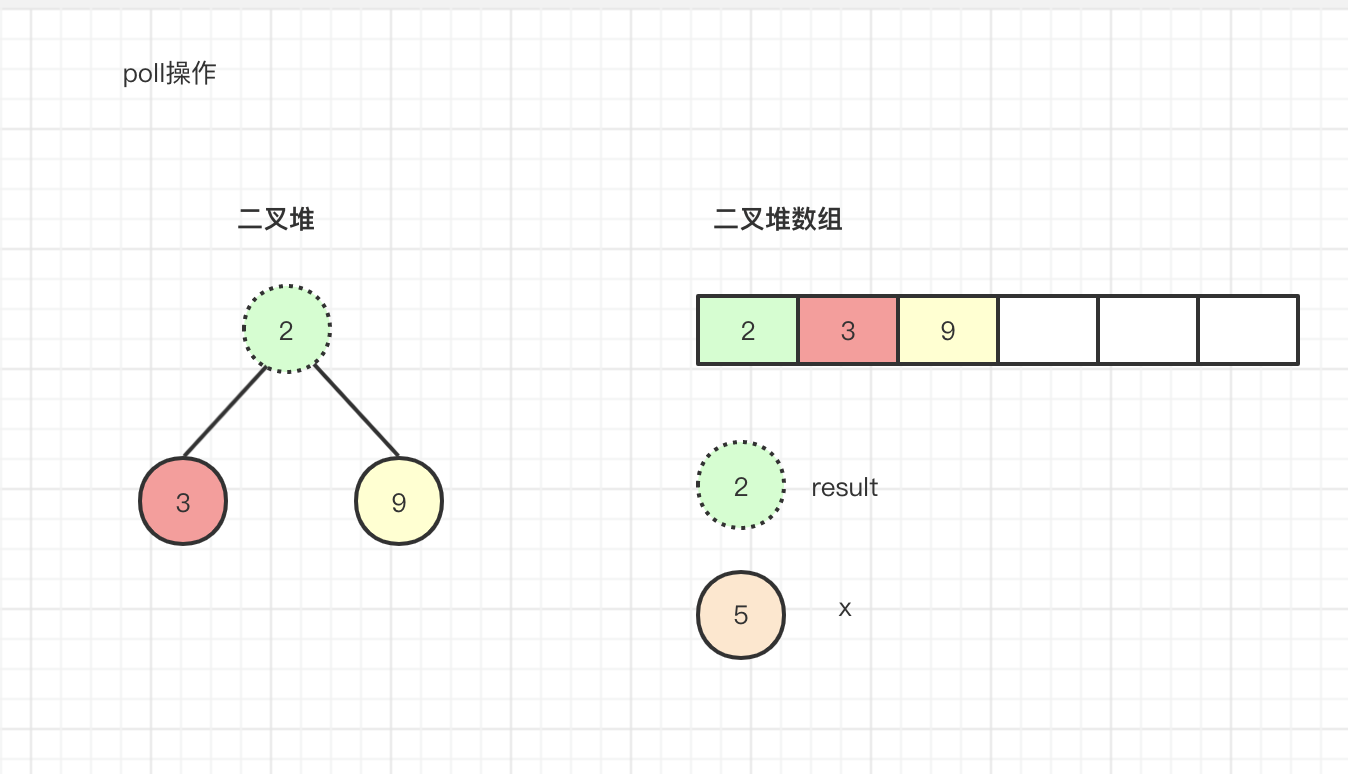
数组中最后一个元素相当于直接被设置为空了,从二叉堆中移除掉了,移除掉了放在那里呢?其实这里大家可以理解为放在堆顶,原因是什么呢?我们想一下,堆顶元素相当于是要被出队操作,元素2已经出队了,但是没有堆顶元素了,此时需要怎么操作呢?直接从数组中找到完全二叉树叶子节点最后一个节点,将最后一个节点设置到堆顶,然后将堆顶元素进行下沉操作,但这里源码中并没有实际设置元素5到堆顶,而是经过比较的过程将元素5从堆顶进行下沉的操作,接下来一步一步分析,目前可以将堆看做如下:

然后通过源码可以看到它是现将堆顶也就是元素2的左右节点相比较,比较3<9所以最小节点c=3,然后再跟元素5(可以看做现在是在堆顶)进行比较3<5,发现元素5大于元素3,将元素3的位置替换原堆顶的元素2(此时我们可以完全可以看成元素5的位置也再堆顶,其实就是替换元素5的位置内容),然后元素5的下标从0调整到原来元素3下标1的位置,这个动作我们称之为下沉操作,下沉过程中并没有进行内容交换,只是坐标进行下沉操作了,此时二叉堆内容如下所示:
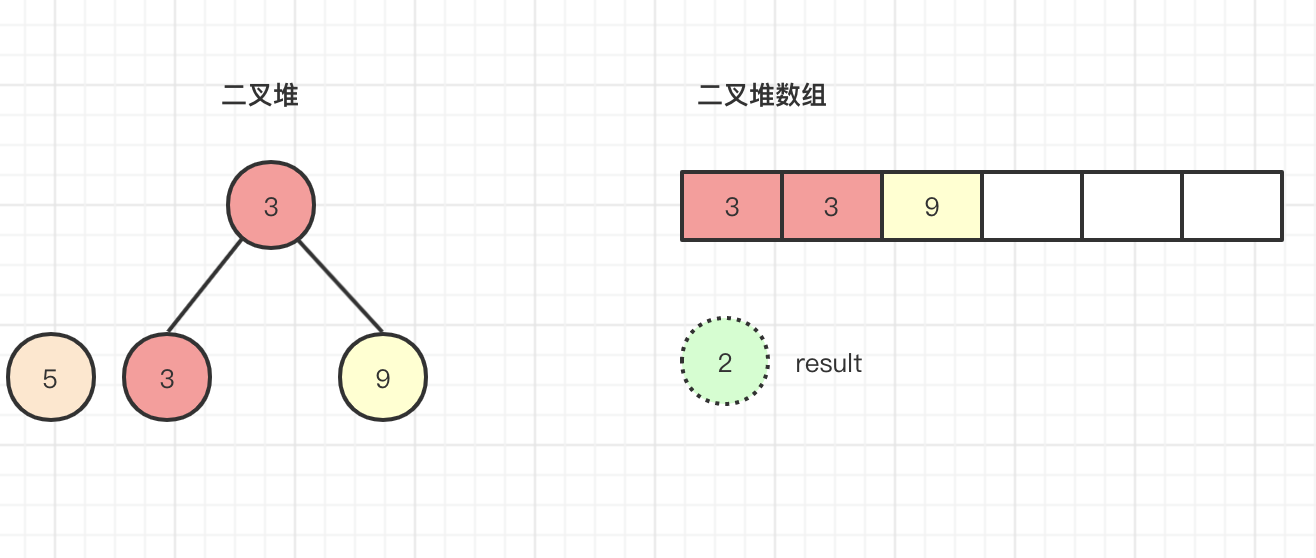
half=3>>>1=1,k的下标在这个时候已经变为1,进行k<half时发现等于false,本次循环结束,将下标1位置替换真实下沉的内容 array[k] = key=array[1]=5,此时二叉堆内容如下所示:
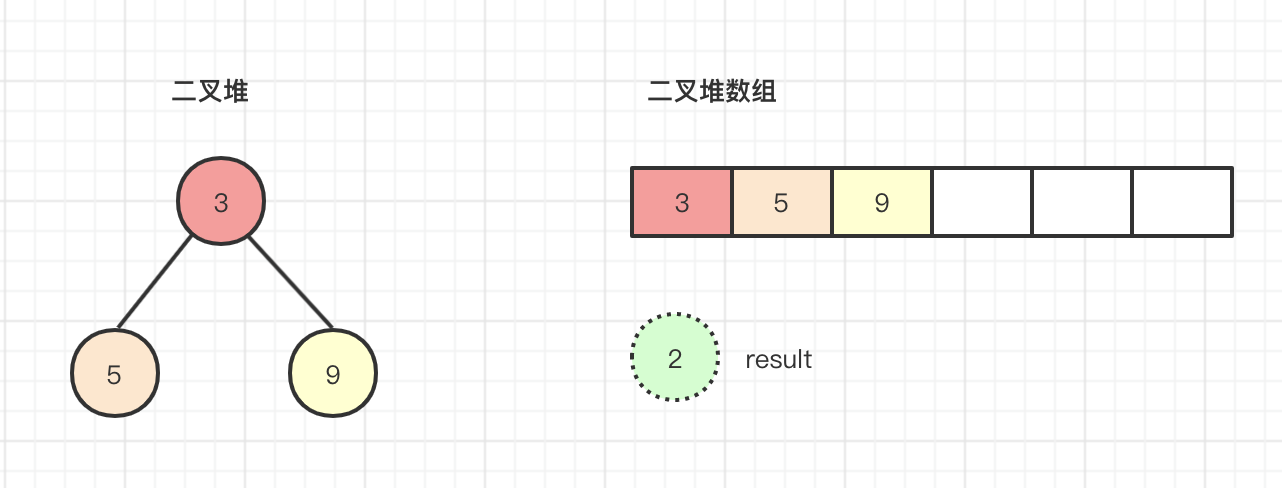
最后将原调整前的result返回。
put操作
put的操作内部其实就是调用了offer操作,由于是无界数组可以进行扩充,所以不需要进行阻塞操作。
public void put(E e) {
offer(e); // never need to block
}
take操作
take操作当队列为空时进行阻塞操作,当队列不为空调用offer操作时会调用notEmpty.signal();通知等待的线程,队列中已经有数据了,可以继续获取数据了,源码如下:
public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
// 调用的事可以相应中断。
lock.lockInterruptibly();
E result;
try {
while ( (result = dequeue()) == null)
// 如果队列为空时等待。
notEmpty.await();
} finally {
lock.unlock();
}
return result;
}
总结
- PriorityBlockingQueue是一个阻塞队列,继承自BlockingQueue。
- PriorityBlockingQueue的元素必须实现Comparable接口。
- PriorityBlockingQueue内部实现原理是基于二叉堆来实现的,二叉堆的实现是基于数组来实现的。
- PriorityBlockingQueue是一个无界数组,插入值时不需要进行阻塞操作,获取值如果队列为空时阻塞线程获取值。
浅析PriorityBlockingQueue优先级队列原理的更多相关文章
- java PriorityBlockingQueue 基于优先级队列,的读出操作可以阻止.
java PriorityBlockingQueue 基于优先级队列.的读出操作可以阻止. package org.rui.thread.newc; import java.util.ArrayLis ...
- 什么是Java优先级队列?
PriorityQueue是基于无界优先级队列和优先级堆构建的重要Java API之一.本文通过适当的代码示例深入了解了有关此API及其用法的一些复杂信息.另在上篇文章中我们简单地谈了下Java编译器 ...
- RHCA学习笔记:RH442-Unit5 队列原理
NIT 5 Queuing Theory 队列原理 目标: 1.明白性能调优的关键术语 2. 应用队列技术解决性能问题 3.明白性能调优的复杂性 5.1 Introd ...
- Java笔记(十)堆与优先级队列
优先级队列 一.PriorityQueue PriorityQueue是优先级队列,它实现了Queue接口,它的队列长度 没有限制,与一般队列的区别是,它有优先级概念,每个元素都有优先 级,队头的元素 ...
- STL中的优先级队列priority_queue
priority_queue(queue类似)完全以底部容器为根据,再加上二叉堆(大根堆或者小根堆)的实现原理,所以其实现非常简单,缺省情况下priority_queue以vector作为底部容器.另 ...
- java数据结构和算法03(队列和优先级队列)
什么是队列呢?其实队列跟栈很像,我们可以把栈的底部给弄开,这样数据就可以从下面漏出来了,我们就从下面拿就好了. 可以看到队列是新进先出,就跟我们显示生活中的排队一样,买火车票,飞机票等一样,先去的肯定 ...
- DelayQueue延迟队列原理剖析
DelayQueue延迟队列原理剖析 介绍 DelayQueue队列是一个延迟队列,DelayQueue中存放的元素必须实现Delayed接口的元素,实现接口后相当于是每个元素都有个过期时间,当队列进 ...
- 体验Rabbitmq强大的【优先级队列】之轻松面对现实业务场景
说到队列的话,大家一定不会陌生,但是扯到优先级队列的话,还是有一部分同学是不清楚的,可能是不知道怎么去实现吧,其实呢,,,这东西已 经烂大街了...很简单,用“堆”去实现的,在我们系统中有一个订单催付 ...
- Java中的队列Queue,优先级队列PriorityQueue
队列Queue 在java5中新增加了java.util.Queue接口,用以支持队列的常见操作.该接口扩展了java.util.Collection接口. Queue使用时要尽量避免Collecti ...
随机推荐
- Jsoup-基于Java实现网络爬虫-爬取笔趣阁小说
注意!仅供学习交流使用,请勿用在歪门邪道的地方!技术只是工具!关键在于用途! 今天接触了一款有意思的框架,作用是网络爬虫,他可以像操作JS一样对网页内容进行提取 初体验Jsoup <!-- Ma ...
- php的call_user_func_array()使用场景
1..动态调用普通函数时,比如参数和调用方法名称不确定的时候很好用 function sayEnglish($fName, $content) { echo 'I am ' . $content; } ...
- 【Java注解】@PostConstruct 注解相关
不多逼逼,直接看注解上面的文档, @PostConsturct PostConstruct注释用于需要执行的方法在依赖注入完成后执行任何初始化.这个方法必须在类投入服务之前调用. 这个所有支持依赖关系 ...
- POJ 2752 同一个串的前后串
题解东北赛回来再补 #include<stdio.h> #include<string.h> int next[500000]; int ans[500000]; char s ...
- android调用号和libc
调用号(以arm平台为例)在/bionic/libc/kernel/uapi/asm-arm/asm/unistd.h: /* WARNING: DO NOT EDIT, AUTO-GENERATED ...
- Markdown修改字体颜色
在写blog时,想高亮某些字,但是发现markdown更改字体颜色不像word里那么方便,于是查了一下,要用一下代码进行更改字体颜色,还可以更改字体大小,还有字体格式 <font 更改语法> ...
- TortoiseGit:拉代码密码错误remote: Coding 提示: Authentication failed! 认证失败,请确认您输入了正确的账号密码
问题 在控制面板里找到凭据管理器 修改密码之后拉取密码
- layui图片上传
<!DOCTYPE html><html><head> <meta charset="utf-8"> <title>up ...
- ppt技巧一四步法调整段落排版
声明:本文所有截图来源于网易云课堂--<和秋叶一起学PPT>,仅作为个人复习之用,特此声明!
- 手把手教你掌握——性能工具Jmeter之参数化(含安装教程 )
本节大纲 Jmeter 发送get/post请求 Jmeter 之文件参数化-TXT/Csv Jmeter之文件参数化-断言 JMeter简介 Apache JMeter是一款基于JAVA的压力测试T ...