3 当某个应用的CPU使用达到100%,该怎么办?
你最常用什么指标来描述系统的 CPU 性能呢?我想你的答案,可能不是平均负载,也不是 CPU 上下文切换,而是另一个更直观的指标—— CPU 使用率。CPU 使用率是单位时间内 CPU 使用情况的统计,以百分比的方式展示。那么,作为最常用也是最熟悉的 CPU 指标,你能说出 CPU 使用率到底是怎么算出来的吗?再有,诸如 top、ps 之类的性能工具展示的 %user、%nice、 %system、%iowait、%steal 等等,你又能弄清楚它们之间的不同吗?
CPU 使用率
Linux 作为一个多任务操作系统,将每个 CPU 的时间划分为很短的时间片,再通过调度器轮流分配给各个任务使用,因此造成多任务同时运行的错觉。为了维护CPU时间,Linux通过事先定义的节拍率(内核中表示为 HZ),触发时间中断,并使用全局变量 Jiffies 记录了开机以来的节拍数。每发生一次时间中断,Jiffies 的值就加 1。节拍率 HZ 是内核的可配选项,可以设置为 100、250、1000 等。不同的系统可能设置不同数值,你可以通过查询 /boot/config 内核选项来查看它的配置值。比如在我的系统中,节拍率设置成了 250,也就是每秒钟触发 250 次时间中断。
[root@web-01 ~]# grep 'CONFIG_HZ=' /boot/config-$(uname -r)
CONFIG_HZ=1000
同时,正因为节拍率 HZ 是内核选项,所以用户空间程序并不能直接访问。为了方便用户空间程序,内核还提供了一个用户空间节拍率 USER_HZ,它总是固定为 100,也就是1/100 秒。这样,用户空间程序并不需要关心内核中 HZ 被设置成了多少,因为它看到的总是固定值 USER_HZ。
Linux 通过 /proc 虚拟文件系统,向用户空间提供了系统内部状态的信息,而 /proc/stat 提供的就是系统的 CPU 和任务统计信息。比方说,如果你只关注 CPU 的话,可以执行下面的命令:
[root@web-01 ~]# cat /proc/stat |grep ^cpu
cpu 1360 5 15836 5940988 4567 0 101 0 0 0
cpu0 743 1 7794 2970951 2458 0 42 0 0 0
cpu1 616 4 8041 2970037 2109 0 58 0 0 0
这里的输出结果是一个表格。其中,第一列表示的是 CPU 编号,如 cpu0、cpu1 ,而第一行没有编号的 cpu ,表示的是所有 CPU 的累加。其他列则表示不同场景下 CPU 的累加节拍数,它的单位是 USER_HZ,也就是 10 ms(1/100 秒),所以这其实就是不同场景下的 CPU 时间。当然,这里每一列的顺序并不需要你背下来。你只要记住,有需要的时候,查询 man proc 就可以。不过,你要清楚 man proc 文档里每一列的涵义,它们都是 CPU 使用率相关的重要指标,你还会在很多其他的性能工具中看到它们。下面,我来依次解读一下。
user(通常缩写为 us),代表用户态 CPU 时间。注意,它不包括下面的 nice 时间,但包括了 guest 时间。
nice(通常缩写为 ni),代表低优先级用户态 CPU 时间,也就是进程的 nice 值被调整为 1-19 之间时的 CPU 时间。这里注意,nice 可取值范围是 -20 到 19,数值越大,优先级反而越低。
system(通常缩写为 sys),代表内核态 CPU 时间。
idle(通常缩写为 id),代表空闲时间。注意,它不包括等待 I/O 的时间(iowait)。iowait(通常缩写为 wa),代表等待 I/O 的 CPU 时间。
irq(通常缩写为 hi),代表处理硬中断的 CPU 时间。softirq(通常缩写为 si),代表处理软中断的 CPU 时间。
steal(通常缩写为 st),代表当系统运行在虚拟机中的时候,被其他虚拟机占用的CPU 时间。
guest(通常缩写为 guest),代表通过虚拟化运行其他操作系统的时间,也就是运行虚拟机的 CPU 时间。
guest_nice(通常缩写为 gnice),代表以低优先级运行虚拟机的时间。
而我们通常所说的 CPU 使用率,就是除了空闲时间外的其他时间占总 CPU 时间的百分比,用公式来表示就是:
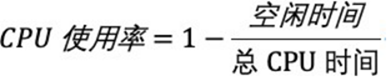
根据这个公式,我们就可以从 /proc/stat 中的数据,很容易地计算出 CPU 使用率。当然,也可以用每一个场景的 CPU 时间,除以总的 CPU 时间,计算出每个场景的 CPU 使用率。
不过先不要着急计算,你能说出,直接用 /proc/stat 的数据,算的是什么时间段的 CPU 使用率吗?
这是开机以来的节拍数累加值,所以直接算出来的,是开机以来的平均 CPU 使用率,一般没啥参考价值。事实上,为了计算 CPU 使用率,性能工具一般都会取间隔一段时间(比如 3 秒)的两次值,作差后,再计算出这段时间内的平均 CPU 使用率,即

这个公式,就是我们用各种性能工具所看到的 CPU 使用率的实际计算方法。现在,我们知道了系统 CPU 使用率的计算方法,那进程的呢?跟系统的指标类似,Linux 也给每个进程提供了运行情况的统计信息,也就是 /proc/[pid]/stat。不过,这个文件包含的数据就比较丰富了,总共有 52 列的数据。当然,不用担心,因为你并不需要掌握每一列的含义。还是那句话,需要的时候,查 man proc 就行。
是不是说要查看 CPU 使用率,就必须先读取 /proc/stat 和 /proc/[pid]/stat 这两个文件,然后再按照上面的公式计算出来呢?当然不是,各种各样的性能分析工具已经帮我们计算好了。不过要注意的是,性能分析工具给出的都是间隔一段时间的平均 CPU 使用率,所以要注意间隔时间的设置,特别是用多个工具对比分析时,你一定要保证它们用的是相同的间隔时间。比如,对比一下 top 和 ps 这两个工具报告的 CPU 使用率,默认的结果很可能不一样,因为 top 默认使用 3 秒时间间隔,而 ps 使用的却是进程的整个生命周期。
怎么查看 CPU 使用率
知道了 CPU 使用率的含义后,我们再来看看要怎么查看 CPU 使用率。说到查看 CPU 使用率的工具,我猜你第一反应肯定是 top 和 ps。的确,top 和 ps 是最常用的性能分析工具:top 显示了系统总体的 CPU 和内存使用情况,以及各个进程的资源使用情况。ps 则只显示了每个进程的资源使用情况。比如,top 的输出格式为:
默认每 3 秒刷新一次
top - 03:49:36 up 10:42, 1 user, load average: 0.00, 0.01, 0.05
Tasks: 92 total, 2 running, 90 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 11.8 sy, 0.0 ni, 88.2 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 2028088 total, 1791704 free, 96856 used, 139528 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1764088 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
1 root 20 0 128004 6508 4132 S 0.0 0.3 0:01.62 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd
3 root 20 0 0 0 0 S 0.0 0.0 0:01.98 ksoftirqd/0
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
6 root 20 0 0 0 0 S 0.0 0.0 0:00.75 kworker/u256:0
7 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0
8 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_bh
9 root 20 0 0 0 0 R 0.0 0.0 0:01.19 rcu_sched
这个输出结果中,第三行 %Cpu 就是系统的 CPU 使用率,具体每一列的含义上一节都讲过,只是把 CPU 时间变换成了 CPU 使用率,我就不再重复讲了。不过需要注意,top 默认显示的是所有 CPU 的平均值,这个时候你只需要按下数字 1 ,就可以切换到每个 CPU 的使用率了。
继续往下看,空白行之后是进程的实时信息,每个进程都有一个 %CPU 列,表示进程的CPU 使用率。它是用户态和内核态 CPU 使用率的总和,包括进程用户空间使用的 CPU、通过系统调用执行的内核空间 CPU 、以及在就绪队列等待运行的 CPU。在虚拟化环境中,它还包括了运行虚拟机占用的 CPU。
所以,到这里我们可以发现,top 并没有细分进程的用户态 CPU 和内核态 CPU。那要怎么查看每个进程的详细情况呢?你应该还记得上一节用到的 pidstat 吧,它正是一个专门分析每个进程 CPU 使用情况的工具。比如,下面的 pidstat 命令,就间隔 1 秒展示了进程的 5 组 CPU 使用率,包括:
用户态 CPU 使用率 (%usr);
内核态 CPU 使用率(%system);
运行虚拟机 CPU 使用率(%guest);
等待 CPU 使用率(%wait);
以及总的 CPU 使用率(%CPU)。
最后的 Average 部分,还计算了 5 组数据的平均值。
每隔 1 秒输出一组数据,共输出 5 组
[root@web-01 ~]# pidstat 1 5
Linux 3.10.0-957.21.2.el7.x86_64 (web-01) 07/12/2019 _x86_64_ (2 CPU) 09:01:48 AM UID PID %usr %system %guest %wait %CPU CPU Command
09:01:49 AM 0 8423 0.99 0.00 0.00 0.00 0.99 0 node
09:01:49 AM 0 9218 0.00 0.99 0.00 0.00 0.99 0 pidstat 09:01:49 AM UID PID %usr %system %guest %wait %CPU CPU Command
09:01:50 AM 27 6908 0.00 1.00 0.00 0.00 1.00 0 mysqld
09:01:50 AM 0 9218 0.00 1.00 0.00 0.00 1.00 0 pidstat 09:01:50 AM UID PID %usr %system %guest %wait %CPU CPU Command 09:01:51 AM UID PID %usr %system %guest %wait %CPU CPU Command
09:01:52 AM 0 9218 0.00 1.00 0.00 0.00 1.00 0 pidstat 09:01:52 AM UID PID %usr %system %guest %wait %CPU CPU Command
09:01:53 AM 0 9218 1.00 0.00 0.00 0.00 1.00 0 pidstat Average: UID PID %usr %system %guest %wait %CPU CPU Command
Average: 27 6908 0.00 0.20 0.00 0.00 0.20 - mysqld
Average: 0 8423 0.20 0.00 0.00 0.00 0.20 - node
Average: 0 9218 0.20 0.60 0.00 0.00 0.80 - pidstat
CPU 使用率过高怎么办?
通过 top、ps、pidstat 等工具,你能够轻松找到 CPU 使用率较高(比如 100% )的进程。接下来,你可能又想知道,占用 CPU 的到底是代码里的哪个函数呢?找到它,你才能更高效、更针对性地进行优化。
我猜你第一个想到的,应该是 GDB(The GNU Project Debugger), 这个功能强大的程序调试利器。的确,GDB 在调试程序错误方面很强大。但是,我又要来“挑刺”了。请你记住,GDB 并不适合在性能分析的早期应用。为什么呢?因为 GDB 调试程序的过程会中断程序运行,这在线上环境往往是不允许的。所以,GDB 只适合用在性能分析的后期,当你找到了出问题的大致函数后,线下再借助它来进一步调试函数内部的问题。
那么哪种工具适合在第一时间分析进程的 CPU 问题呢?我的推荐是 perf。perf 是 Linux 2.6.31以后内置的性能分析工具。它以性能事件采样为基础,不仅可以分析系统的各种事件和内核性能,还可以用来分析指定应用程序的性能问题。使用 perf 分析 CPU 性能问题,我来说两种最常见、也是我最喜欢的用法。第一种常见用法是 perf top,类似于 top,它能够实时显示占用 CPU 时钟最多的函数或者指令,因此可以用来查找热点函数,使用界面如下所示:
yum install -y perf
perf top
Samples: 591 of event 'cpu-clock', Event count (approx.): 24787480
Overhead Shared Object Symbol
29.40% [kernel] [k] _raw_spin_unlock_irqrestore
21.50% [kernel] [k] generic_exec_single
15.81% [kernel] [k] mpt_put_msg_frame
8.49% [kernel] [k] e1000_xmit_frame
7.05% [kernel] [k] __do_softirq
2.56% [kernel] [k] ata_sff_pio_task
2.03% [kernel] [k] tick_nohz_idle_enter
1.57% [kernel] [k] __x2apic_send_IPI_mask
1.29% libslang.so.2.2.4 [.] SLtt_smart_puts
0.77% libpthread-2.17.so [.] 0x000000000000e6a1
......
输出结果中,第一行包含三个数据,分别是采样数(Samples)、事件类型(event)和事件总数量(Event count)。
采样数需要我们特别注意。如果采样数过少(比如只有十几个),那下面的排序和百分比就没什么实际参考价值了。
再往下看是一个表格式样的数据,每一行包含四列,分别是:
第一列 Overhead ,是该符号的性能事件在所有采样中的比例,用百分比来表示。
第二列 Shared ,是该函数或指令所在的动态共享对象(Dynamic Shared Object), 如内核、进程名、动态链接库名、内核模块名等。
第三列 Object ,是动态共享对象的类型。比如 [.] 表示用户空间的可执行程序、或者动态链接库,而 [k] 则表示内核空间。
最后一列 Symbol 是符号名,也就是函数名。当函数名未知时,用十六进制的地址来表示。
接着再来看第二种常见用法,也就是 perf record 和 perf report。 perf top 虽然实时展示了系统的性能信息,但它的缺点是并不保存数据,也就无法用于离线或者后续的分析。而 perf record 则提供了保存数据的功能,保存后的数据,需要你用 perf report 解析展示。
[root@web-01 ~]# perf record # 按 Ctrl+C 终止采样
^C[ perf record: Woken up 21 times to write data ]
[ perf record: Captured and wrote 5.271 MB perf.data (109799 samples) ] [root@web-01 ~]# perf report # 展示类似于 perf top 的报告 Samples: 109K of event 'cpu-clock', Event count (approx.): 27449750000
Overhead Command Shared Object Symbol
99.88% swapper [kernel.kallsyms] [k] native_safe_halt
0.03% swapper [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.02% kworker/0:2 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.02% kworker/1:1 [kernel.kallsyms] [k] _raw_spin_unlock_irqrestore
0.01% swapper [kernel.kallsyms] [k] __do_softirq
0.01% kworker/u256:0 [kernel.kallsyms] [k] mpt_put_msg_frame
0.01% sshd [kernel.kallsyms] [k] e1000_xmit_frame
0.00% kworker/0:3 [kernel.kallsyms] [k] ata_sff_pio_task
0.00% node [kernel.kallsyms] [k] generic_exec_single
0.00% swapper [kernel.kallsyms] [k] e1000_xmit_frame
0.00% swapper [kernel.kallsyms] [k] mpt_put_msg_frame
0.00% irqbalance [kernel.kallsyms] [k] seq_put_decimal_ull
.......
在实际使用中,我们还经常为 perf top 和 perf record 加上 -g 参数,开启调用关系的采样,方便我们根据调用链来分析性能问题。
操作和分析
接下来,我们正式进入操作环节。首先,在第一个终端执行下面的命令来运行 Nginx 和 PHP 应用:
docker run --name nginx -p 10000:80 -itd feisky/nginx
docker run --name phpfpm -itd --network container:nginx feisky/php-fpm
然后,在第二个终端使用 curl 访问 http://[VM1 的 IP]:10000,确认 Nginx 已正常启动。你应该可以看到 It works! 的响应。
[root@web-02 ~]# curl http://10.0.0.6:10000
It works!
接着,我们来测试一下这个 Nginx 服务的性能。在第二个终端运行下面的 ab 命令:
# 并发 10 个请求测试 Nginx 性能,总共测试 100 个请求
[root@web-02 ~]# ab -c 10 -n 100 http://10.0.0.6:10000/
. . .
Complete requests: 100
Failed requests: 0
Write errors: 0
Total transferred: 17200 bytes
HTML transferred: 900 bytes
Requests per second: 20.29 [#/sec] (mean)
Time per request: 492.739 [ms] (mean)
Time per request: 49.274 [ms] (mean, across all concurrent requests)
Transfer rate: 3.41 [Kbytes/sec] received
. . .
从 ab 的输出结果我们可以看到,Nginx 能承受的每秒平均请求数只有 20.29。你一定在吐槽,这也太差了吧。那到底是哪里出了问题呢?我们用 top 和 pidstat 再来观察下。
这次,我们在第二个终端,将测试的请求总数增加到 10000。这样当你在第一个终端使用性能分析工具时, Nginx 的压力还是继续。继续在第二个终端,运行 ab 命令:
ab -c 10 -n 10000 http://10.240.0.5:10000/
接着,回到第一个终端运行 top 命令,并按下数字 1 ,切换到每个 CPU 的使用率:
top - 12:37:16 up 13:07, 1 user, load average: 1.31, 0.33, 0.14
Tasks: 148 total, 6 running, 142 sleeping, 0 stopped, 0 zombie
%Cpu0 : 99.0 us, 0.3 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu1 : 99.7 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 2028112 total, 177024 free, 455488 used, 1395600 buff/cache
KiB Swap: 2097148 total, 2097148 free, 0 used. 1258424 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10463 bin 20 0 336684 9364 1692 R 43.9 0.5 0:05.84 php-fpm
10460 bin 20 0 336684 9368 1696 R 39.5 0.5 0:06.13 php-fpm
10461 bin 20 0 336684 9364 1692 R 39.5 0.5 0:05.75 php-fpm
10462 bin 20 0 336684 9364 1692 R 38.2 0.5 0:07.14 php-fpm
10459 bin 20 0 336684 9372 1700 R 36.9 0.5 0:05.99 php-fpm
9900 101 20 0 33092 2152 776 S 1.0 0.1 0:01.70 nginx
3 root 20 0 0 0 0 S 0.3 0.0 0:00.68 ksoftirqd/0
9538 root 20 0 520300 62624 25208 S 0.3 3.1 0:22.93 dockerd
10348 root 20 0 0 0 0 S 0.3 0.0 0:00.17 kworker/0:0
10464 root 20 0 162012 2280 1592 R 0.3 0.1 0:00.05 top
1 root 20 0 128040 6600 4144 S 0.0 0.3 0:03.05 systemd
2 root 20 0 0 0 0 S 0.0 0.0 0:00.02 kthreadd
5 root 0 -20 0 0 0 S 0.0 0.0 0:00.00 kworker/0:0H
7 root rt 0 0 0 0 S 0.0 0.0 0:00.05 migration/0
这里可以看到,系统中有几个 php-fpm 进程的 CPU 使用率加起来接近 200%;而每个CPU 的用户使用率(us)也已经超过了 98%,接近饱和。这样,我们就可以确认,正是用户空间的 php-fpm 进程,导致 CPU 使用率骤升。
# -g 开启调用关系分析,-p 指定 php-fpm 的进程号 21515
$ perf top -g -p 21515
按方向键切换到 php-fpm,再按下回车键展开 php-fpm 的调用关系,你会发现,调用关系最终到了 sqrt 和 add_function。看来,我们需要从这两个函数入手了。
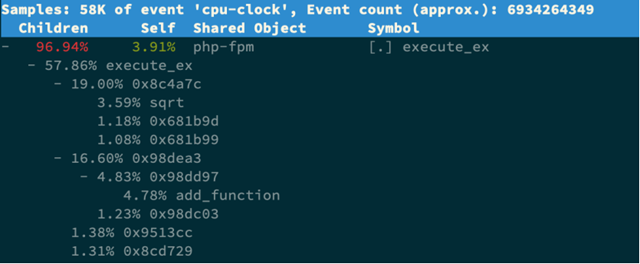
我们拷贝出 Nginx 应用的源码,看看是不是调用了这两个函数:
# 从容器 phpfpm 中将 PHP 源码拷贝出来
$ docker cp phpfpm:/app . # 使用 grep 查找函数调用
$ grep sqrt -r app/ # 找到了 sqrt 调用
app/index.php: $x += sqrt($x);
$ grep add_function -r app/ # 没找到 add_function 调用,这其实是 PHP 内置函数
OK,原来只有 sqrt 函数在 app/index.php 文件中调用了。那最后一步,我们就该看看这个文件的源码了:
[root@web-01 ~]# cat app/index.php
<?php
// test only.
$x = 0.0001;
for ($i = 0; $i <= 1000000; $i++) {
$x += sqrt($x);
} echo "It works!"
呀,有没有发现问题在哪里呢?我想你要笑话我了,居然犯了一个这么傻的错误,测试代码没删就直接发布应用了。为了方便你验证优化后的效果,我把修复后的应用也打包成了
一个 Docker 镜像,你可以在第一个终端中执行下面的命令来运行它:
docker run --name nginx -p 10000:80 -itd feisky/nginx:cpu-fix
docker run --name phpfpm -itd --network container:nginx feisky/php-fpm:cpu-fix
接着,到第二个终端来验证一下修复后的效果。首先 Ctrl+C 停止之前的 ab 命令后,再运行下面的命令:
[root@web-02 ~]# ab -c 10 -n 10000 http://10.0.0.6:10000/ ......
Complete requests: 10000
Failed requests: 0
Write errors: 0
Total transferred: 1720000 bytes
HTML transferred: 90000 bytes
Requests per second: 1638.15 [#/sec] (mean)
Time per request: 6.104 [ms] (mean)
Time per request: 0.610 [ms] (mean, across all concurrent requests)
Transfer rate: 275.16 [Kbytes/sec] received ......
从这里你可以发现,现在每秒的平均请求数,已经从原来的 11 变成了 1638。你看,就是这么很傻的一个小问题,却会极大的影响性能,并且查找起来也并不容易吧。当然,找到问题后,解决方法就简单多了,删除测试代码就可以了。
小结
CPU 使用率是最直观和最常用的系统性能指标,更是我们在排查性能问题时,通常会关注的第一个指标。所以我们更要熟悉它的含义,尤其要弄清楚用户(%user)、Nice(%nice)、系统(%system) 、等待 I/O(%iowait) 、中断(%irq)以及软中断(%softirq)这几种不同 CPU 的使用率。比如说:
用户 CPU 和 Nice CPU 高,说明用户态进程占用了较多的 CPU,所以应该着重排查进程的性能问题。
系统 CPU 高,说明内核态占用了较多的 CPU,所以应该着重排查内核线程或者系统调用的性能问题。
I/O 等待 CPU 高,说明等待 I/O 的时间比较长,所以应该着重排查系统存储是不是出现了 I/O 问题。
软中断和硬中断高,说明软中断或硬中断的处理程序占用了较多的 CPU,所以应该着重排查内核中的中断服务程序。
碰到 CPU 使用率升高的问题,你可以借助 top、pidstat 等工具,确认引发 CPU 性能问题的来源;再使用 perf 等工具,排查出引起性能问题的具体函数。
----
执行perf top -g -p (php-fpm进程号),发现不了sqrt函数
回复: 只看到地址而不是函数名是由于应用程序运行在容器中,它的依赖也都在容器内部, 故而perf无法找到PHP符号表。一个简单的解决方法是使用perf record生成perf.data拷贝到容器内部 perf report。
请问iowait time算在idle time里面吗?cpu的利用率计算公式中空闲时间指的是idle time,还是idle+iowait time。
回复: iowait不算在idle里面
使用perf 只能分析到16进制的地址,无法显示函数名称
回复: 只看到地址而不是函数名是由于应用程序运行在容器中,它的依赖也都在容器内部, 故而perf无法找到PHP符号表。
3 当某个应用的CPU使用达到100%,该怎么办?的更多相关文章
- ixgbe 82599 固定源与目标, UDP, 64字节小包, 1488w pps 单核CPU软中断sirq 100%
ixgbe 82599 固定源与目标, UDP, 64字节小包, 1488w pps 单核CPU软中断sirq 100% 注: 测试使用, 正常应用不要开启 五元组不同, 开启ntupleethtoo ...
- linux下用top命令查看cpu利用率超过100%
今天跑了一个非常耗时的批量插入操作..通过top命令查看cpu以及内存的使用的时候,cpu的时候查过了120%..以前没注意..通过在top的情况下按大键盘的1,查看的cpu的核数为4核. 通过网上查 ...
- SqlServer优化:当数据量查询不是特别多,但数据库服务器的CPU资源一直100%时,如何优化?
最近和同事处理一个小程序,数据量不是特别大,某表的的数据记录:7000W条记录左右,但是从改别执行一次查询时,却发现查询速度也不快,而且最明显的问题就是CPU100%. sql语句: select g ...
- win 系统设置weblogic 进行定时自动重启并删除其日志和缓存文件,定时监控cpu是否达到100%并重启weblogic服务
一:如何在win系统设置 任务管理:请百度查询 win系统设置 任务管理 二:设置 webogic 重启并删除垃圾文件的bat脚本 sqlplus /nolog @C:\Users\Administr ...
- ASP.NET Core奇遇记:无用户访问,CPU却一直100%
这是5月11日遇到的一个问题,1台1核1G阿里云Linux服务器运行着生产环境中的ASP.NET Core站点,出现CPU 100%问题. 开始以为是这台服务器负载高引起的,于是将这台服务器从负载均衡 ...
- MyEclipse 优化:之占用CPU过高100%
原因是 jsp文件代码有4000行左右,MyEclipse打开jsp的时候会越来越慢.CPU占用会越来越高,因此,需要用别的编辑器打开jsp文件,不用在MyEclipse中编辑jsp文件. 我用的是 ...
- 让cpu跑到100%的bat文件
请你新建一个叫“virus.bat”的批处理文件,里面填写上如下三段命令: Echo "welcom to the aqjava's world"Tree /fCall virus ...
- 阿里云被挖矿使用,导致cpu长期处于100%,ddgs进程,xWx3T进程,关于redis密码
1.使用top命令,查看到一个叫xWx3T的进程cpu占用99.8%,由于我的阿里云是单核的,所以最高只能100%. 把它用kill命令杀死后,过一会儿又启动了,又占用100%. 使用ps -ef可以 ...
- top command-linux下用top命令查看cpu利用率超过100%
1. 这里显示的所有的cpu加起来的使用率,说明你的CPU是多核,你运行top后按大键盘1看看,可以显示每个cpu的使用率,top里显示的是把所有使用率加起来; 2.查看CPU信息; cat ...
- [译] 用win7自带工具找出svchost.exe的CPU使用率达到100%的元凶
本文是我对自己上一篇转载的博客 <Figuring out why my SVCHOST.EXE is at 100% CPU without complicated tools in Wind ...
随机推荐
- (二十)VMware Harbor - API
可以用swagger在线解析 http://editor.swagger.io/将swagger.yaml中的内容拷贝到里面即可. 官方文档说明链接如下:https://github.com/vmwa ...
- 网络编程Netty入门:EventLoopGroup分析
目录 Netty线程模型 代码示例 NioEventLoopGroup初始化过程 NioEventLoopGroup启动过程 channel的初始化过程 Netty线程模型 Netty实现了React ...
- C语言-内存函数的实现(二)之memmove
C语言中的内存函数有如下这些 memcpy memmove memcmp memset 下面看看memmove函数 memmove 为什么会需要memmove函数? int main() { int ...
- 用Taro写一个微信小程序(一)——开始一个项目
一.Taro简介 1.名字由来 Taro['tɑ:roʊ],泰罗·奥特曼,宇宙警备队总教官,实力最强的奥特曼. 2.taro是什么 Taro 是一个开放式跨端跨框架解决方案,支持使用 React/Vu ...
- 022- Java算数运算符
算数运算符有哪些: 输入以下代码: public class Operator01 { public static void main(String[]args){ int a = 10; int b ...
- 缓冲区溢出分析第06课:W32Dasm缓冲区溢出分析
漏洞报告分析 学习过破解的朋友一定听说过W32Dasm这款逆向分析工具.它是一个静态反汇编工具,在IDA Pro流行之前,是破解界人士必然要学会使用的工具之一,它也被比作破解界的"屠龙刀&q ...
- Redis笔记整理
Redis 遵守BSD协议.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库.数据结构服务器. 特点: 1.Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时 ...
- 【Android开发高手笔记】Dagger2和它在SystemUI上的应用
和人类需要群居一样,程序界的进程.线程也需要通信往来.它们的交流则依赖模块之间.文件之间产生的关系.如何快速地搞清和构建这种关系,同时还能减轻彼此的依赖,需要开发者们认真思考. 我们将这种需求称之为依 ...
- Ubuntu20.04安装和配置JDK
首先在官网下载Linux系统的jdk到本地 创建/java目录 sudo mkdir /java 这是直接创建在根目录下的. 3. 将下载的jdk压缩包移动到java文件夹 sudo mv 你的安装包 ...
- springboot添加操作
更多精彩关注微信公众号 Mybaits技术连接数据库 resources #update tomcat port server.port=8888 #config datasource(mysql) ...