Istio最佳实践系列:如何实现方法级调用跟踪?
赵化冰,腾讯云高级工程师,Istio Member,ServiceMesher 管理委员,Istio 项目贡献者,热衷于开源、网络和云计算。目前主要从事服务网格的开源和研发工作。
引言
TCM(Tencent Cloud Mesh)是腾讯云上提供的基于Istio 进行增强,和 Istio API 完全兼容的 Service Mesh 托管服务,可以帮助用户以较小的迁移成本和维护代价快速利用到 Service Mesh 提供的流量管理和服务治理能力。本系列文章将介绍 TCM 上的最佳实践,本文将介绍如何利用 Spring 和 OpenTracing 简化应用程序的Tracing 上下文传递,以及如何在 Istio 提供的进程间调用跟踪基础上实现方法级别的细粒度调用跟踪。
分布式调用跟踪和 OpenTracing 规范
什么是分布式调用跟踪?
相比传统的“巨石”应用,微服务的一个主要变化是将应用中的不同模块拆分为了独立的进程。在微服务架构下,原来进程内的方法调用成为了跨进程的RPC调用。相对于单一进程的方法调用,跨进程调用的调试和故障分析是非常困难的,很难用传统的调试器或者日志打印来对分布式调用进行查看和分析。
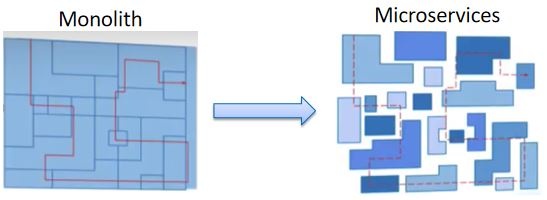
如上图所示,一个来自客户端的请求经过了多个微服务进程。如果要对该请求进行分析,则必须将该请求经过的所有服务的相关信息都收集起来并关联在一起,这就是“分布式调用跟踪”。
什么是OpenTracing?
CNCF OpenTracing项目
OpenTracing是CNCF(云原生计算基金会)下的一个项目,其中包含了一套分布式调用跟踪的标准规范,各种语言的API,编程框架和函数库。OpenTracing的目的是定义一套分布式调用跟踪的标准,以统一各种分布式调用跟踪的实现。目前已有大量支持OpenTracing规范的Tracer实现,包括Jager,Skywalking,LightStep等。在微服务应用中采用OpenTracing API实现分布式调用跟踪,可以避免vendor locking,以最小的代价和任意一个兼容OpenTracing的基础设施进行对接。
OpenTracing概念模型
OpenTracing的概念模型参见下图:
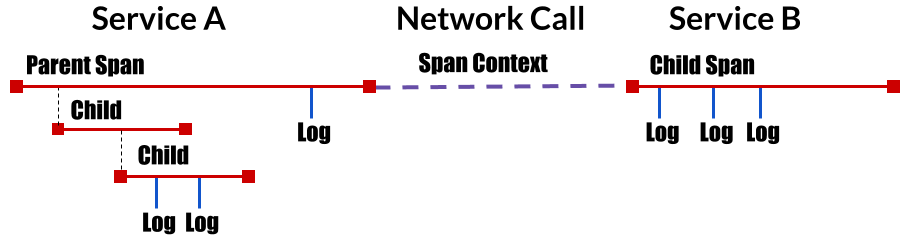
图源自 https://opentracing.io/
如图所示,OpenTracing中主要包含下述几个概念:
- Trace: 描述一个分布式系统中的端到端事务,例如来自客户端的一个请求。
- Span:一个具有名称和时间长度的操作,例如一个REST调用或者数据库操作等。Span是分布式调用跟踪的最小跟踪单位,一个Trace由多段Span组成。
- Span context:分布式调用跟踪的上下文信息,包括Trace id,Span id以及其它需要传递到下游服务的内容。一个OpenTracing的实现需要将Span context通过某种序列化机制(Wire Protocol)在进程边界上进行传递,以将不同进程中的Span关联到同一个Trace上。这些Wire Protocol可以是基于文本的,例如HTTP header,也可以是二进制协议。
OpenTracing数据模型
一个Trace可以看成由多个相互关联的Span组成的有向无环图(DAG图)。下图是一个由8个Span组成的Trace:
[Span A] ←←←(the root span)
|
+------+------+
| |
[Span B] [Span C] ←←←(Span C is a `ChildOf` Span A)
| |
[Span D] +---+-------+
| |
[Span E] [Span F] >>> [Span G] >>> [Span H]
↑
↑
↑
(Span G `FollowsFrom` Span F)
上图的trace也可以按照时间先后顺序表示如下:
––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–––––––|–> time
[Span A···················································]
[Span B··············································]
[Span D··········································]
[Span C········································]
[Span E·······] [Span F··] [Span G··] [Span H··]
Span的数据结构中包含以下内容:
- name: Span所代表的操作名称,例如REST接口对应的资源名称。
- Start timestamp: Span所代表操作的开始时间
- Finish timestamp: Span所代表的操作的的结束时间
- Tags:一系列标签,每个标签由一个key value键值对组成。该标签可以是任何有利于调用分析的信息,例如方法名,URL等。
- SpanContext:用于跨进程边界传递Span相关信息,在进行传递时需要结合一种序列化协议(Wire Protocol)使用。
- References:该Span引用的其它关联Span,主要有两种引用关系,Childof和FollowsFrom。
- Childof: 最常用的一种引用关系,表示Parent Span和Child Span之间存在直接的依赖关系。例RPC服务端Span和RPC客户端Span,或者数据库SQL插入Span和ORM Save动作Span之间的关系。
- FollowsFrom:如果Parent Span并不依赖Child Span的执行结果,则可以用FollowsFrom表示。例如网上商店购物付款后会向用户发一个邮件通知,但无论邮件通知是否发送成功,都不影响付款成功的状态,这种情况则适用于用FollowsFrom表示。
跨进程调用信息传播
SpanContext是OpenTracing中一个让人比较迷惑的概念。在OpenTracing的概念模型中提到SpanContext用于跨进程边界传递分布式调用的上下文。但实际上OpenTracing只定义一个SpanContext的抽象接口,该接口封装了分布式调用中一个Span的相关上下文内容,包括该Span所属的Trace id,Span id以及其它需要传递到downstream服务的信息。SpanContext自身并不能实现跨进程的上下文传递,需要由Tracer(Tracer是一个遵循OpenTracing协议的实现,如Jaeger,Skywalking的Tracer)将SpanContext序列化后通过Wire Protocol传递到下一个进程中,然后在下一个进程将SpanContext反序列化,得到相关的上下文信息,以用于生成Child Span。
为了为各种具体实现提供最大的灵活性,OpenTracing只是提出了跨进程传递SpanContext的要求,并未规定将SpanContext进行序列化并在网络中传递的具体实现方式。各个不同的Tracer可以根据自己的情况使用不同的Wire Protocol来传递SpanContext。
在基于HTTP协议的分布式调用中,通常会使用HTTP Header来传递SpanContext的内容。常见的Wire Protocol包含Zipkin使用的b3 HTTP header,Jaeger使用的uber-trace-id HTTP Header,LightStep使用的"x-ot-span-context" HTTP Header等。Istio/Envoy支持b3 header和x-ot-span-context header,可以和Zipkin,Jaeger及LightStep对接。其中b3 HTTP header的示例如下:
X-B3-TraceId: 80f198ee56343ba864fe8b2a57d3eff7
X-B3-ParentSpanId: 05e3ac9a4f6e3b90
X-B3-SpanId: e457b5a2e4d86bd1
X-B3-Sampled: 1
Istio对分布式调用跟踪的支持
Istio/Envoy为微服务提供了开箱即用的分布式调用跟踪功能。在安装了Istio和Envoy的微服务系统中,Envoy会拦截服务的入向和出向请求,为微服务的每个调用请求自动生成调用跟踪数据。通过在服务网格中接入一个分布式跟踪的后端系统,例如zipkin或者Jaeger,就可以查看一个分布式请求的详细内容,例如该请求经过了哪些服务,调用了哪个REST接口,每个REST接口所花费的时间等。
需要注意的是,Istio/Envoy虽然在此过程中完成了大部分工作,但还是要求对应用代码进行少量修改:应用代码中需要将收到的上游HTTP请求中的b3 header拷贝到其向下游发起的HTTP请求的header中,以将调用跟踪上下文传递到下游服务。这部分代码不能由Envoy代劳,原因是Envoy并不清楚其代理的服务中的业务逻辑,无法将入向请求和出向请求按照业务逻辑进行关联。这部分代码量虽然不大,但需要对每一处发起HTTP请求的代码都进行修改,非常繁琐而且容易遗漏。当然,可以将发起HTTP请求的代码封装为一个代码库来供业务模块使用,来简化该工作。
下面以一个简单的网上商店示例程序来展示Istio如何提供分布式调用跟踪。该示例程序由eshop,inventory,billing,delivery几个微服务组成,结构如下图所示:
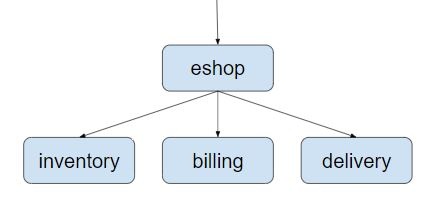
eshop微服务接收来自客户端的请求,然后调用inventory,billing,delivery这几个后端微服务的REST接口来实现用户购买商品的checkout业务逻辑。本例的代码可以从github下载:https://github.com/aeraki-framework/method-level-tracing-with-istio
如下面的代码所示,我们需要在eshop微服务的应用代码中传递b3 HTTP Header。
@RequestMapping(value = "/checkout")
public String checkout(@RequestHeader HttpHeaders headers) {
String result = "";
// Use HTTP GET in this demo. In a real world use case,We should use HTTP POST
// instead.
// The three services are bundled in one jar for simplicity. To make it work,
// define three services in Kubernets.
result += restTemplate.exchange("http://inventory:8080/createOrder", HttpMethod.GET,
new HttpEntity<>(passTracingHeader(headers)), String.class).getBody();
result += "<BR>";
result += restTemplate.exchange("http://billing:8080/payment", HttpMethod.GET,
new HttpEntity<>(passTracingHeader(headers)), String.class).getBody();
result += "<BR>";
result += restTemplate.exchange("http://delivery:8080/arrangeDelivery", HttpMethod.GET,
new HttpEntity<>(passTracingHeader(headers)), String.class).getBody();
return result;
}
private HttpHeaders passTracingHeader(HttpHeaders headers) {
HttpHeaders tracingHeaders = new HttpHeaders();
extractHeader(headers, tracingHeaders, "x-request-id");
extractHeader(headers, tracingHeaders, "x-b3-traceid");
extractHeader(headers, tracingHeaders, "x-b3-spanid");
extractHeader(headers, tracingHeaders, "x-b3-parentspanid");
extractHeader(headers, tracingHeaders, "x-b3-sampled");
extractHeader(headers, tracingHeaders, "x-b3-flags");
extractHeader(headers, tracingHeaders, "x-ot-span-context");
return tracingHeaders;
}
下面我们来测试一下eshop实例程序。我们可以自己搭建一个Kubernetes集群并安装Istio以用于测试。这里为了方便,直接使用腾讯云上提供的全托管的服务网格 TCM,并在创建的 Mesh 中加入了一个容器服务TKE 集群来进行测试。
在 TKE 集群中部署该程序,查看Istio分布式调用跟踪的效果。
git clone git@github.com:aeraki-framework/method-level-tracing-with-istio.git
cd method-level-tracing-with-istio
git checkout without-opentracing
kubectl apply -f k8s/eshop.yaml
- 在浏览器中打开地址:http://${INGRESS_EXTERNAL_IP}/checkout ,以触发调用eshop示例程序的REST接口。
- 在浏览器中打开 TCM 的界面,查看生成的分布式调用跟踪信息。
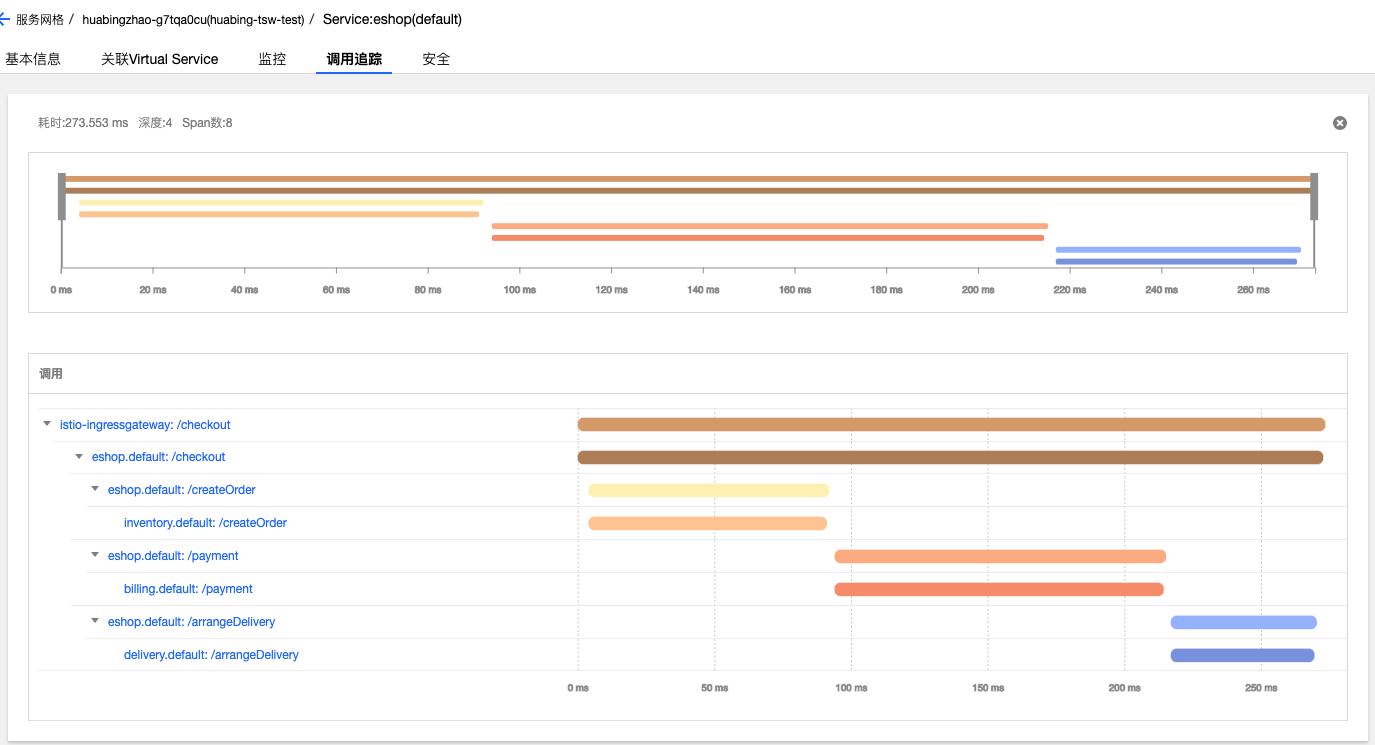
TCM 图形界面直观地展示了这次调用的详细信息,可以看到客户端请求从Ingressgateway进入到系统中,然后调用了eshop微服务的checkout接口,checkout调用有三个child span,分别对应到inventory,billing和delivery三个微服务的REST接口。
使用OpenTracing来传递分布式跟踪上下文
OpenTracing提供了基于Spring的代码埋点,因此我们可以使用OpenTracing Spring框架来提供HTTP header的传递,以避免这部分硬编码工作。在Spring中采用OpenTracing来传递分布式跟踪上下文非常简单,只需要下述两个步骤:
- 在Maven POM文件中声明相关的依赖,一是对OpenTracing SPring Cloud Starter的依赖;另外由于Istio 采用了Zipkin的上报接口,我们也需要引入Zipkin的相关依赖。
- 在Spring Application中声明一个Tracer bean。如下所示,注意我们需要把 Istio 中的zpkin上报地址设置到OKHttpSernder中。
@Bean
public io.opentracing.Tracer zipkinTracer() {
String zipkinEndpoint = System.getenv("ZIPKIN_ENDPOINT");
if (zipkinEndpoint == null || zipkinEndpoint == ""){
zipkinEndpoint = "http://zipkin.istio-system:9411/api/v2/spans";
}
OkHttpSender sender = OkHttpSender.create(zipkinEndpoint);
Reporter spanReporter = AsyncReporter.create(sender);
Tracing braveTracing = Tracing.newBuilder()
.localServiceName("my-service")
.propagationFactory(B3Propagation.FACTORY)
.spanReporter(spanReporter)
.build();
Tracing braveTracer = Tracing.newBuilder()
.localServiceName("spring-boot")
.spanReporter(spanReporter)
.propagationFactory(B3Propagation.FACTORY)
.traceId128Bit(true)
.sampler(Sampler.ALWAYS_SAMPLE)
.build();
return BraveTracer.create(braveTracer);
}
部署采用OpenTracing进行HTTP header传递的程序版本,其调用跟踪信息如下所示:
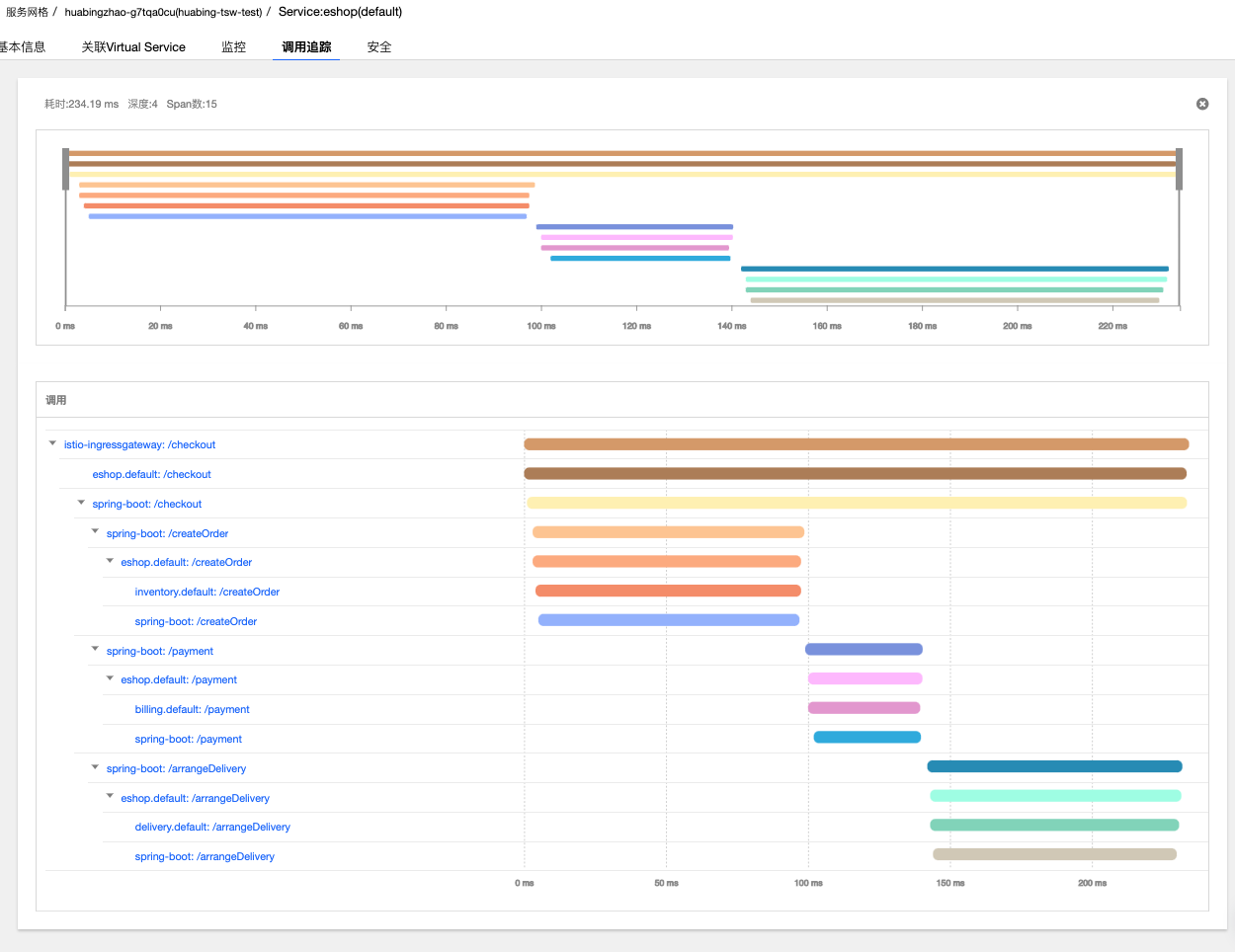
从上图中可以看到,相比在应用代码中直接传递HTTP header的方式,采用OpenTracing进行代码埋点后,相同的调用增加了7个名称前缀为spring-boot的Span,这7个Span是由OpenTracing的tracer生成的。虽然我们并没有在代码中显示创建这些Span,但OpenTracing的代码埋点会自动为每一个REST请求生成一个Span,并根据调用关系关联起来。
OpenTracing生成的这些Span为我们提供了更详细的分布式调用跟踪信息,从这些信息中可以分析出一个HTTP调用从客户端应用代码发起请求,到经过客户端的Envoy,再到服务端的Envoy,最后到服务端接受到请求各个步骤的耗时情况。从图中可以看到,Envoy转发的耗时在1毫秒左右,相对于业务代码的处理时长非常短,对这个应用而言,Envoy的处理和转发对于业务请求的处理效率基本没有影响。
在Istio调用跟踪链中加入方法级的调用跟踪信息
Istio/Envoy提供了跨服务边界的调用链信息,在大部分情况下,服务粒度的调用链信息对于系统性能和故障分析已经足够。但对于某些服务,需要采用更细粒度的调用信息来进行分析,例如一个REST请求内部的业务逻辑和数据库访问分别的耗时情况。在这种情况下,我们需要在服务代码中进行埋点,并将服务代码中上报的调用跟踪数据和Envoy生成的调用跟踪数据进行关联,以统一呈现Envoy和服务代码中生成的调用数据。
在方法中增加调用跟踪的代码是类似的,因此我们用AOP + Annotation的方式实现,以简化代码。
首先定义一个Traced注解和对应的AOP实现逻辑:
@Retention(RetentionPolicy.RUNTIME)
@Target(ElementType.METHOD)
@Documented
public @interface Traced {
}
@Aspect
@Component
public class TracingAspect {
@Autowired
Tracer tracer;
@Around("@annotation(com.zhaohuabing.demo.instrument.Traced)")
public Object aroundAdvice(ProceedingJoinPoint jp) throws Throwable {
String class_name = jp.getTarget().getClass().getName();
String method_name = jp.getSignature().getName();
Span span = tracer.buildSpan(class_name + "." + method_name).withTag("class", class_name)
.withTag("method", method_name).start();
Object result = jp.proceed();
span.finish();
return result;
}
}
然后在需要进行调用跟踪的方法上加上Traced注解:
@Component
public class DBAccess {
@Traced
public void save2db() {
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
@Component
public class BankTransaction {
@Traced
public void transfer() {
try {
Thread.sleep((long) (Math.random() * 100));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
demo程序的master branch已经加入了方法级代码跟踪,可以直接部署。
git checkout master
kubectl apply -f k8s/eshop.yaml
效果如下图所示,可以看到trace中增加了transfer和save2db两个方法级的Span。
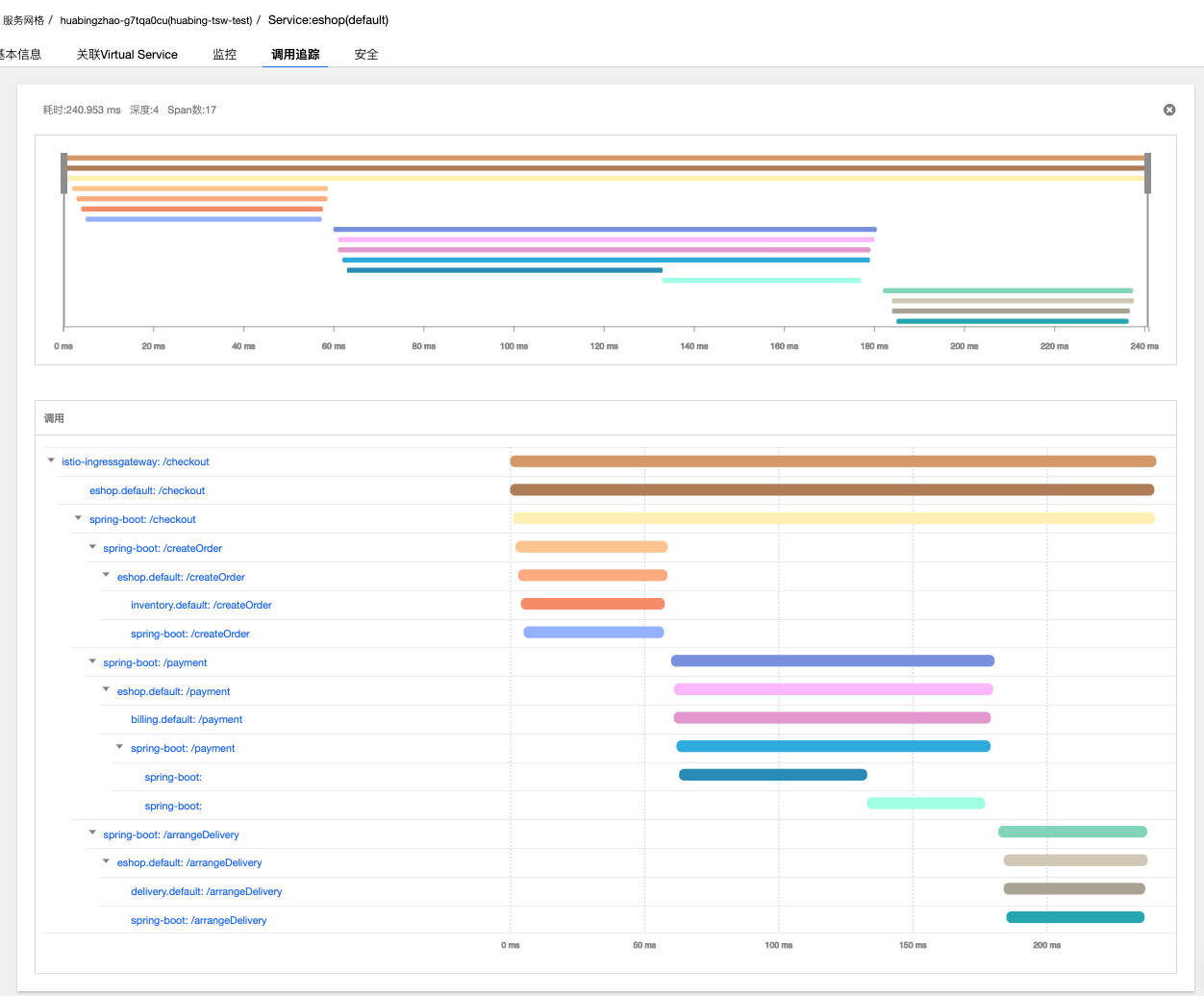
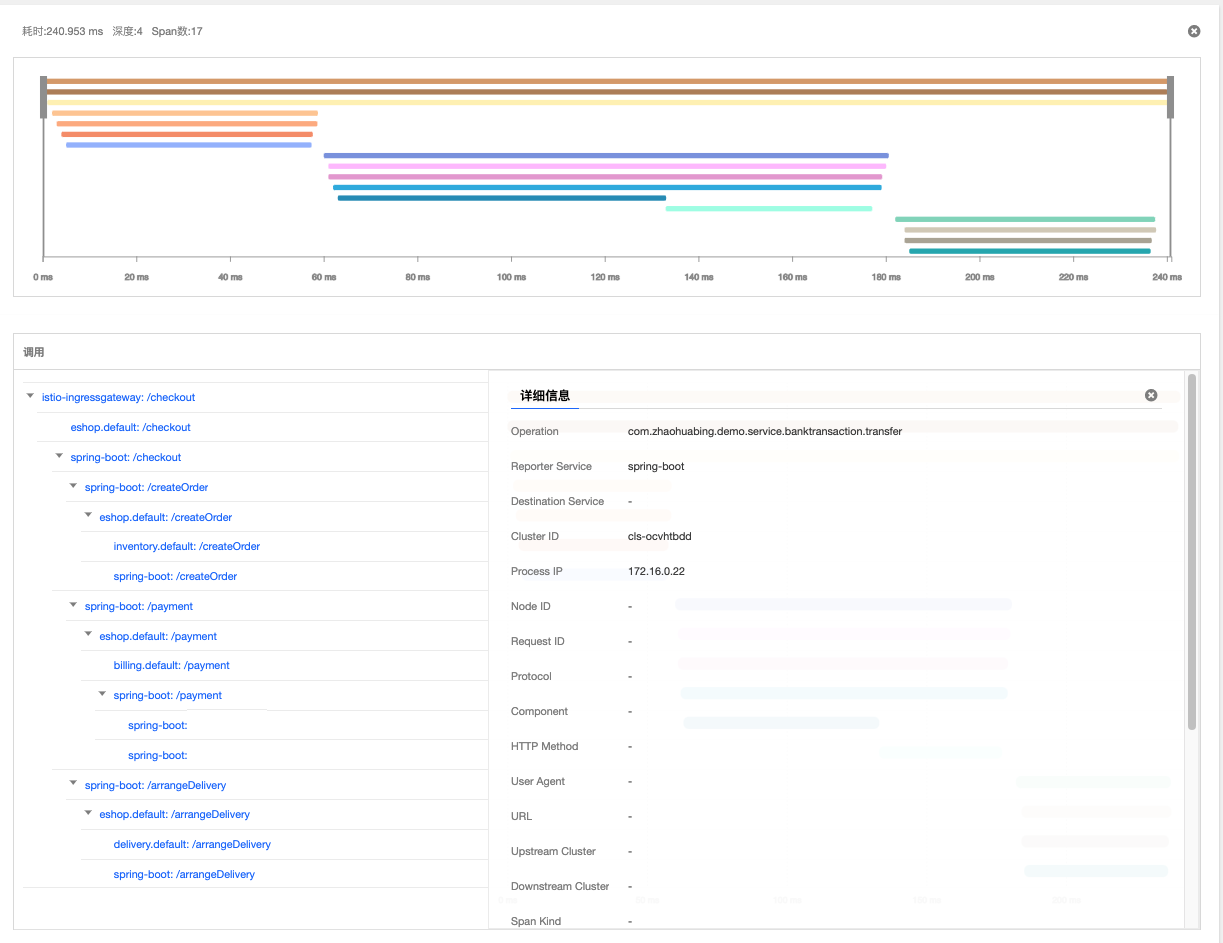
可以打开一个方法的Span,查看详细信息,包括Java类名和调用的方法名等,在AOP代码中还可以根据需要添加出现异常时的异常堆栈等信息。
总结
Istio/Envoy为微服务应用提供了分布式调用跟踪功能,提高了服务调用的可见性。我们可以使用OpenTracing来代替应用硬编码,以传递分布式跟踪的相关http header;还可以通过OpenTracing将方法级的调用信息加入到Istio/Envoy缺省提供的调用链跟踪信息中,以提供更细粒度的调用跟踪信息。
下一步
除了同步调用之外,异步消息也是微服务架构中常见的一种通信方式。在下一篇文章中,我将继续利用eshop demo程序来探讨如何通过OpenTracing将Kafka异步消息也纳入到Istio的分布式调用跟踪中。
参考资料
- 本文中eshop示例程序的源代码
- Opentracing docs
- Opentracing specification
- Opentracing wire protocols
- Istio Trace context propagation
- Zipkin-b3-propagation
- OpenTracing Project Deep Dive
Istio最佳实践系列:如何实现方法级调用跟踪?的更多相关文章
- nodejs 实践:express 最佳实践系列
nodejs 实践:express 最佳实践系列 nodejs 实践:express 最佳实践(一) 项目结构 nodejs 实践:express 最佳实践(二) 中间件 nodejs 实践:expr ...
- iOS应用开发最佳实践系列一:编写高质量的Objective-C代码
本文由海水的味道编译整理,转载请注明译者和出处,请勿用于商业用途! 点标记语法 属性和幂等方法(多次调用和一次调用返回的结果相同)使用点标记语法访问,其他的情况使用方括号标记语法. 良好的 ...
- 【WEB前端开发最佳实践系列】CSS篇
一.有效组织CSS代码 规划组织CSS代码:组织CSS代码文件,所有的CSS都可以分为2类,通用类和业务类.代码的组织应该把通用类和业务类的代码放在不同的目录中. 模块内部的另一样式规则:样式声明的顺 ...
- 基于华为云IOT及无线RFID技术的智慧仓储解决方案最佳实践系列一
[摘要]仓储管理存在四大细分场景:出入库管理.盘点.分拣和货物跟踪.本系列将介绍利用华为云IOT全栈云服务,端侧采用华为收发分离式RFID解决方案,打造端到端到IOT智慧仓储解决方案的最佳实践. 仓储 ...
- 【Web前端开发最佳实践系列】前端代码推荐和建议
一.常用的前端文件的组织结构: 1.js (放置JavaScript代码) lib(放置框架JavaScript文件) custom.js 2.css(放置CSS样式代码) lib(放置框架CSS文件 ...
- Web前端开发最佳实践系列文章汇总
Web前端开发最佳实践(1):前端开发概述 Web前端开发最佳实践(2):前端代码重构 Web前端开发最佳实践(3):前端代码和资源的压缩与合并 Web前端开发最佳实践(4):在页面中添加必要的met ...
- TaintDroid剖析之Native方法级污点跟踪分析
1.Native方法的污点传播 在前两篇文章中我们详细分析了TaintDroid对DVM栈帧的修改,以及它是如何在修改之后的栈帧中实现DVM变量级污点跟踪的.现在我们继续分析其第二个粒度的污点跟踪—— ...
- Istio最佳实践:在K8s上通过Istio服务网格进行灰度发布
Istio是什么? Istio是Google继Kubernetes之后的又一开源力作,主要参与的公司包括Google,IBM,Lyft等公司.它提供了完整的非侵入式的微服务治理解决方案,包含微服务的管 ...
- 【WEB前端开发最佳实践系列】JavaScript篇
一.养成良好的编码习惯,提高可维护性 1.避免定义全局变量和函数,解决全局变量而导致的代码“污染”最简单的额方法就是把变量和方法封装在一个变量对象上,使其变成对象的属性: var myCurrentA ...
随机推荐
- JavaScript中判断对象是否属于Array类型的4种方法及其背后的原理与局限性
前言 毫无疑问,Array.isArray是现如今JavaScript中判断对象是否属于Array类型的首选,但是我认为了解本文其余的方法及其背后的原理与局限性也是很有必要的,因为在JavaScrip ...
- 死磕以太坊源码分析之EVM指令集
死磕以太坊源码分析之EVM指令集 配合以下代码进行阅读:https://github.com/blockchainGuide/ 写文不易,给个小关注,有什么问题可以指出,便于大家交流学习. 以下指令集 ...
- 使用stress进行压力测试
本文转载自使用stress进行压力测试 导语 stress,顾名思义是一款压力测试工具.你可以用它来对系统CPU,内存,以及磁盘IO生成负载. 安装stress 几乎所有主流的linux发行版的软件仓 ...
- epoll 原理
本文转载自epoll 原理 导语 以前经常被人问道 select.poll.epoll 的区别,基本都是靠死记硬背的,最近正好复习 linux 相关的内容,就把这一块做个笔记吧,以后也能方便查阅. e ...
- ASP.NET Core获取请求完整的Url
在ASP.NET项目中获取请求完整的Url: 获取System.Web命名空间下的类名为HttpRequestBase的Url方法: /// <summary>在派生类中替代时,获取有关当 ...
- mysql导入备份.sql文件时报错总结(还有待完善)
错误1:ERROR Unknown character set: 'utf8mb4' utf8mb4编码集支持了表情符号,相信处理过社交网络数据的人都有了解.这个mysql5.5以后支持了utf8mb ...
- Spring Security 整合 微信小程序登录的思路探讨
1. 前言 原本打算把Spring Security中OAuth 2.0的机制讲完后,用小程序登录来实战一下,发现小程序登录流程和Spring Security中OAuth 2.0登录的流程有点不一样 ...
- Redis单机数据库的实现原理
本文主要介绍Redis的数据库结构,Redis两种持久化的原理:RDB持久化.AOF持久化,以及Redis事件分类及执行原理.最后,分别介绍了单机班Redid客户端和Redis服务器的使用和实现原理. ...
- 图解如何在Linux上配置git自动登录验证
记录一下配置git操作远程仓库时的自动验证,效果如下图: 本文介绍的是Linux下的配置.Windows上默认已经启用凭证存储和自动验证(依靠wincred实现,以后会使用GCM-Core). 准备工 ...
- PTA1071 - Speech Patterns - map计算不同单词个数
题意 输出给定字符串出现最多的字符串(小写输出)和出现次数. 所求字符串要求:字符中可以含有A-Z.0-9. 比如说题目给出的Can1,我们可以转换成can1,can1就算一个字符串整体,而不是单独的 ...