LevelDB学习笔记 (2): 整体概览与读写实现细节
1. leveldb整体介绍
首先leveldb的数据是存储在磁盘上的。采用LSM-Tree实现,LSM-Tree把对于磁盘的随机写操作转换成了顺序写操作。这是得益于此leveldb的写操作非常快,为了做点这一点LSM-Tree的思路是将索引树结构拆成一大一小两棵树,较小的一颗常驻内存,较大的一个持久化到磁盘。而随着内存中的树逐渐增大就会发生树的合并和分裂,大概结构如下图所示。后面还会详细分析

下图是整个leveldb的结构概述图,首先我们会把数据写入memtable(位于内存中),当memtable满了之后。就会变成immutable memtable。也就是所谓的冷却状态,这个时候的memtable无法再被写入数据。在immutable memtable中的数据会准备写入SST(磁盘)中
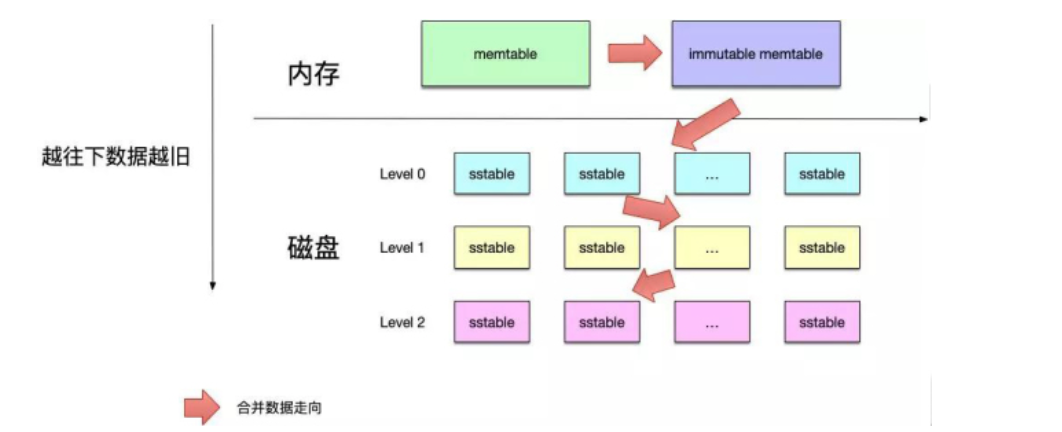
2. leveldb的主要构成
1、Log文件(位于磁盘)
在我们把数据写Memtable前会先写Log文件,Log通过append的方式顺序写入。Log的存在使得机器宕机导致的内存数据丢失得以恢复。
2、 Memtable(位于内存)
Leveldb主要的内存数据结构,采用跳表进行实现。新的数据会首先写入这里。
3、Immutable Memtable(位于内存)
当Memtable内的数据设置的容量上限后,Memtable会变为Immutable为之后向SST文件的归并做准备。Immutable Mumtable不再接受用户写入,同时生成新的Memtable、log文件供新数据写入。
4、SST文件(位于磁盘)
磁盘数据存储文件。SSTable(Sorted String Table)就是由内存中的数据不断导出并进行Compaction操作后形成的,而且SSTable的所有文件是一种层级结构,第一层为Level 0,第二层为Level 1,依次类推,层级逐渐增高,这也是为何称之为LevelDb的原因。除此之外,Compact动作会将多个SSTable合并成少量的几个SSTable,以剔除无效数据,保证数据访问效率并降低磁盘占用。
SSTABLE是由多个segement组成,这样可以减少碎片的产生。整体的结构如下图引用自

5、Manifest文件(位于磁盘)
Manifest文件中记录SST文件在不同Level的分布,单个SST文件的最大最小key,以及其他一些LevelDB需要的元信息。
6、Current文件(位于磁盘)
从上面的介绍可以看出,LevelDB启动时的首要任务就是找到当前的Manifest,而Manifest可能有多个。Current文件简单的记录了当前Manifest的文件名,从而让这个过程变得非常简单。
上述的整体结构就可以利用下图来描述
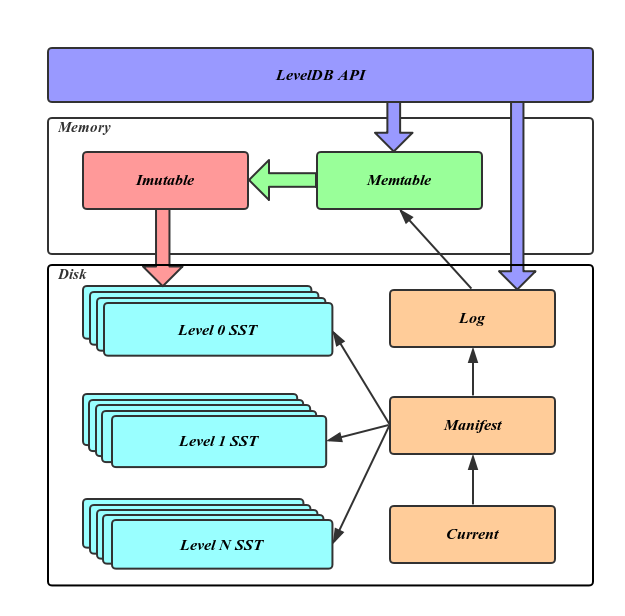
3. leveldb读写实现速看
1. 写操作的实现
首先我们通过之前写过的简单的put操作,利用断点跟踪一下整个put过程。
// Write data.
status = db->Put(leveldb::WriteOptions(), "name", "zxl");
WriteOptions 控制着我们是否需要
sync,也就是刷到磁盘上
根据断点执行,上述的put操作要先进入db/db_impl.cc里面的Put函数。这里可以发现的key和value都是以Slice形式来存储,也就是切片来存储。因此在往下追溯之前我们先来看一下切片
// Convenience methods
Status DBImpl::Put(const WriteOptions& o, const Slice& key, const Slice& val) {
return DB::Put(o, key, val);
}
切片的实现
切片的整体代码位于include/Slice.h。整体由一个类组成。其中含有一个c字符串和一个大小变量
class LEVELDB_EXPORT Slice {
// ......
private:
const char* data_;
size_t size_;
}
整体关于Slice的构造函数有几种不同的重载,下面我们仔细来看一下
// Create an empty slice.
Slice() : data_(""), size_(0) {}
// Create a slice that refers to d[0,n-1].
Slice(const char* d, size_t n) : data_(d), size_(n) {}
// Create a slice that refers to the contents of "s"
Slice(const std::string& s) : data_(s.data()), size_(s.size()) {}
// Create a slice that refers to s[0,strlen(s)-1]
Slice(const char* s) : data_(s), size_(strlen(s)) {}
上面四种分别对应了不同的情况
- 是对于空字符串的初始化
- 对于给定长度的c字符串的初始化
- 对于string的初始化
- 对于不给定长度的c字符串的初始化
对于拷贝构造和拷贝赋值则都采用了c++11的默认方法=default来实现
// Intentionally copyable.
Slice(const Slice&) = default; // 默认浅拷贝
Slice& operator=(const Slice&) = default;
同样关于切片还有一些特殊作用的函数,来分析一下
starts_with函数用来判断x是不是当前Slice的一个前缀。这里用到了memcmp这个c语言库函数。
int memcmp (const void *s1, const void *s2, size_t n); 用来比较s1 和s2 所指的内存区间前n 个字符。
如果返回值为0则表示相同,否则会返回差值,这里是按照ascll的顺序来进行比较的
// Return true iff "x" is a prefix of "*this"
bool starts_with(const Slice& x) const {
return ((size_ >= x.size_) && (memcmp(data_, x.data_, x.size_) == 0));
}
下面还有两个切片的比较函数
- 假如说我们调用a.compare(b)
- 那么比较的逻辑就是先看a和b谁比较长一点。
- 然后取较小的长度去进行比较
- 如果在较小的长度内a和b是相同的,那么就是谁长谁就更大
- 如果在较小的长度内a和b不是想同的,那么就以较小长度内的比较为准
inline int Slice::compare(const Slice& b) const {
const size_t min_len = (size_ < b.size_) ? size_ : b.size_;
int r = memcmp(data_, b.data_, min_len);
if (r == 0) {
if (size_ < b.size_)
r = -1;
else if (size_ > b.size_)
r = +1;
}
return r;
}
写一个测试代码
auto a = new leveldb::Slice("123");
leveldb::Slice b;
b = leveldb::Slice("21");
std:: cout << "a 与 b 的比较结果" << a->compare(b) << std::endl;
上述代码会输出-1表示a < b这符合我们的预期
好了我们上面知道了key和value都是以切片的形式进行存储的。ok下面继续分析写操作
随后进入db/db_imp.cc中的DB::Put函数
// Default implementations of convenience methods that subclasses of DB
// can call if they wish
Status DB::Put(const WriteOptions& opt, const Slice& key, const Slice& value) {
WriteBatch batch;
batch.Put(key, value);
return Write(opt, &batch);
}
这里会定义一个writeBatch来进行写入操作,它会调用batch.put来实现原子写。
不过我们前面有说写操作会先写Log来防止出现意外。而数据则会先写入memtable中
Write Log操作
在调用write(opt, &batch)的时候
Status DBImpl::Write(const WriteOptions& options, WriteBatch* updates) {
Writer w(&mutex_);
w.batch = updates;
w.sync = options.sync;
w.done = false;
MutexLock l(&mutex_);
writers_.push_back(&w);
// 排队写入,直到我们在 front
while (!w.done && &w != writers_.front()) {
w.cv.Wait();
}
if (w.done) {
return w.status;
}
{
mutex_.Unlock();
status = log_->AddRecord(WriteBatchInternal::Contents(write_batch));
上述操作就是写入log的操作。而下面的代码则是写入memTable
if (status.ok()) {
status = WriteBatchInternal::InsertInto(write_batch, mem_); // 这里写入,mem_ 是 MemTable,
}
关于log写入的具体分析后面会在log详解的时候分析
写入memtable
Status WriteBatchInternal::InsertInto(const WriteBatch* b, MemTable* memtable) {
MemTableInserter inserter;
inserter.sequence_ = WriteBatchInternal::Sequence(b);
inserter.mem_ = memtable;
return b->Iterate(&inserter);
}
上面的代码最终会执行到。memtable.cc中
void MemTable::Add(SequenceNumber s, ValueType type, const Slice& key,
const Slice& value) {
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
size_t key_size = key.size();
size_t val_size = value.size();
size_t internal_key_size = key_size + 8;
const size_t encoded_len = VarintLength(internal_key_size) +
internal_key_size + VarintLength(val_size) +
val_size;
// 为要put的key value 创建空间
char* buf = arena_.Allocate(encoded_len);
char* p = EncodeVarint32(buf, internal_key_size);
// copy进去
std::memcpy(p, key.data(), key_size);
p += key_size;
EncodeFixed64(p, (s << 8) | type);
p += 8;
p = EncodeVarint32(p, val_size);
std::memcpy(p, value.data(), val_size);
assert(p + val_size == buf + encoded_len);
// 将索引写入SkipList
table_.Insert(buf);
}
前面说过当memtable满了之后会写入磁盘也就是sstable。对应的代码在MakeRoomForWrite后面再仔细分析了
Status status = MakeRoomForWrite(updates == nullptr);
uint64_t last_sequence = versions_->LastSequence();
2. 读操作的实现
同样的还是通过debug的方式追踪代码
代码位于
db_impl.cc:DBImpl::Get
// Unlock while reading from files and memtables
{
mutex_.Unlock();
// First look in the memtable, then in the immutable memtable (if any).
LookupKey lkey(key, snapshot);
if (mem->Get(lkey, value, &s)) {
// Done
} else if (imm != nullptr && imm->Get(lkey, value, &s)) {
// Done
} else {
s = current->Get(options, lkey, value, &stats);
have_stat_update = true;
}
mutex_.Lock();
}
if (have_stat_update && current->UpdateStats(stats)) {
MaybeScheduleCompaction();
}
mem->Unref();
if (imm != nullptr) imm->Unref();
current->Unref();
return s;
可以发现读操作会先根据key值做一个查找操作loocupKey
随后去memtable中查找。如果memtable没有则会去 immutable中寻找
如果上面两个地方都查不到的话最后则要去sstable中查找。
4. 总结
借鉴了很多大佬们的资料, 分析了一下leveldb的整体结构,以及读和写操作的简单实现,当然后面还会进一步分析。更详细的讲解读和写操作的实现。下一篇就分析一下memtable的实现以及是如何写入memtable和immutable的。
5. 参考资料
https://youjiali1995.github.io/rocksdb/io/
https://github.com/google/leveldb/tree/v1.20/doc
http://catkang.github.io/2017/01/07/leveldb-summary.html
https://www.zhihu.com/column/c_1327581534384230400
https://www.youtube.com/watch?v=PSna05F5fL4&list=PLBokfyNIQPIR2EOXnpemSqzXkkZylAmsD
http://blog.yanick.site/2020/11/08/algorithm/lsm-tree/
https://mp.weixin.qq.com/s/RmyBUUrNVUrmHBJ-7ujM3w
LevelDB学习笔记 (2): 整体概览与读写实现细节的更多相关文章
- LevelDB学习笔记 (3): 长文解析memtable、跳表和内存池Arena
LevelDB学习笔记 (3): 长文解析memtable.跳表和内存池Arena 1. MemTable的基本信息 我们前面说过leveldb的所有数据都会先写入memtable中,在leveldb ...
- LevelDB学习笔记 (1):初识LevelDB
LevelDB学习笔记 (1):初识LevelDB 1. 写在前面 1.1 什么是levelDB LevelDB就是一个由Google开源的高效的单机Key/Value存储系统,该存储系统提供了Key ...
- LevelDB 学习笔记2:合并
LevelDB 学习笔记2:合并 部分图片来自 RocksDB 文档 Minor Compaction 将内存数据库刷到硬盘的过程称为 minor compaction 产出的 L0 层的 sstab ...
- LevelDB 学习笔记1:布隆过滤器
LevelDB 学习笔记1:布隆过滤器 底层是位数组,初始都是 0 插入时,用 k 个哈希函数对插入的数字做哈希,并用位数组长度取余,将对应位置 1 查找时,做同样的哈希操作,查看这些位的值 如果所有 ...
- Dynamic CRM 2013学习笔记(十七)JS读写各种类型字段方法及技巧
我们经常要对表单里各种类型的字段进行读取或赋值,下面列出各种类型的读写方法及注意事项: 1. lookup 类型 清空值 var state = Xrm.Page.getAttribute(" ...
- AntDesign vue学习笔记(七)Form 读写与图片上传
AntDesign Form使用布局相比传统Jquery有点繁琐 (一)先读写一个简单的input为例 <a-form :form="form" layout="v ...
- Bootstrap学习笔记之整体架构
之前有粗略地看过一下Bootstrap的内容,不过那只是走马观花式地看下是怎么用的,以及里面有什么控件,所以就没想着记笔记.现在由于要给部门做分享,所以不得不深入地去学习下,不然仅是简单地说下怎么用, ...
- leveldb学习笔记
LevelDB由 Jeff Dean和Sanjay Ghemawat开发. LevelDb是能够处理十亿级别规模Key-Value型数据持久性存储的C++ 程序库. 特别如下: 1.LevelDb是一 ...
- leveldb 学习笔记之VarInt
在leveldb在查找比较时的key里面保存key长度用的是VarInt,何为VarInt呢,就是变长的整数,每7bit代表一个数,第8bit代表是否还有下一个字节, 1. 比如小于128(一个字节以 ...
随机推荐
- Android面试必问!View 事件分发机制,看这一篇就够了!
在 Android 开发当中,View 的事件分发机制是一块很重要的知识.不仅在开发当中经常需要用到,面试的时候也经常被问到. 如果你在面试的时候,能把这块讲清楚,对于校招生或者实习生来说,算是一块不 ...
- 使用ldap客户端创建zimbra ldap用户的格式
cat << EOF | ldapadd -x -W -H ldap://:389 -D "uid=zimbra,cn=admins,cn=zimbra" dn: ui ...
- 如何访问pod --- service(7)
一.通过service访问pod 我们不应该期望 Kubernetes Pod 是健壮的,而是要假设 Pod 中的容器很可能因为各种原因发生故障而死掉.Deployment 等 controller ...
- Lua的string库函数列表
基本函数 函数 描述 示例 结果 len 计算字符串长度 string.len("abcd") 4 rep 返回字符串s的n个拷贝 string.rep("abcd&qu ...
- 工作流引擎详解!工作流开源框架ACtiviti的详细配置以及安装和使用
创建ProcessEngine Activiti流程引擎的配置文件是名为activiti.cfg.xml的XML文件.注意与使用Spring方式创建流程引擎是不一样的 使用org.activiti.e ...
- SystemVerilog 语言部分(二)
接口interface: 既可以设计,也可以用来验证. 验证环境:interface使得连接变得简单不容易出错. interface可以定义端口,单双向信号,内控部使用initial always t ...
- 痞子衡嵌入式:关于i.MXRT中FlexSPI外设lookupTable里配置Normal read的一个小误区
大家好,我是痞子衡,是正经搞技术的痞子.今天痞子衡给大家介绍的是i.MXRT中FlexSPI外设lookupTable里配置Normal read的一个小误区. 关于串行四线NOR Flash,当其作 ...
- [论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion
[论文阅读笔记] Unsupervised Attributed Network Embedding via Cross Fusion 本文结构 解决问题 主要贡献 算法原理 实验结果 参考文献 (1 ...
- 6, java数据结构和算法: 栈的应用, 逆波兰计算器, 中缀表达式--> 后缀表达式
直接上代码: public class PolandCalculator { //栈的应用:波兰计算器: 即: 输入一个字符串,来计算结果, 比如 1+((2+3)×4)-5 结果为16 public ...
- vulhub-struct2-s2-005
0x00 漏洞原理 s2-005漏洞的起源源于S2-003(受影响版本: 低于Struts 2.0.12),struts2会将http的每个参数名解析为OGNL语句执行(可理解为java代码).O ...