二、mybatis之数据输出
上一篇我们做了一个入门案例,是我们做mybatis的基本步骤,不熟悉的可以回顾一下https://www.cnblogs.com/jasmine-e/p/15330355.html,在这篇文章中只是简单介绍了一下用于select标签时使用resultType属性来指定输出的类型,这只是单行数据的输出方式,今天整理了数据输出的几种方式。
一、数据的输出
数据输出是针对查询数据的方法返回查询结果,也就是让mapper接口的对象返回select的结果集。那么既然是返回结果集,那我们必须得先了解一下结果集的类型有哪几种。
1. select结果集的类型
- 单个数据:以简单类型接收,比如查询总数居的条数。
- 一条数据:以pojo或Map类型接受,比如根据id查询员工信息。
- 多条数据:以List 或者List类型接收,比如查询所有员工。
2. 实例分析
按照入门案例的方法,我们来做个实例分析
(1) 物理建模
创建数据库mybatis-example,表t_emp,添加一行数据。(为了方便,还是入门案例的数据)
CREATE DATABASE `mybatis-example`;
USE `mybatis-example`;
CREATE TABLE `t_emp`(
emp_id INT AUTO_INCREMENT,
emp_name CHAR(100),
emp_salary DOUBLE(10,5),
PRIMARY KEY(emp_id)
);
INSERT INTO `t_emp`(emp_name,emp_salary) VALUES("tom",200.33);
(2)逻辑建模
package pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Employee {
private Integer empId;
private String empName;
private Double empSalary;
}
(3)引入依赖
在pom.xml里加入以下依赖(其中还有打包方式)
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.8</version>
<scope>provided</scope>
</dependency>
<!-- Mybatis核心 -->
<dependency>
<groupId>org.mybatis</groupId>
<artifactId>mybatis</artifactId>
<version>3.5.7</version>
</dependency>
<!-- junit测试 -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.3</version>
<scope>runtime</scope>
</dependency>
<!-- log4j日志 -->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
(4)创建持久层接口
package mappers;
import pojo.Employee;
import java.util.List;
import java.util.Map;
public interface EmployeeMapper {
/*查询单个数据,返回简单类型*/
Long selectCount();
/*查询单行数据,返回实体类对象*/
Employee selectEmployeeByEmpId(Integer empId);
/*查询单行数据,返回map集合*/
Map selectEmployeeMapByEmpId(Integer empId);
/*查询多行数据,返回list<pojo>*/
List<Employee> selectEmployeeList();
/*查询多行数据,返回list<Map>*/
List<Map> selectMapList();
/*添加数据*/
void insertEmployee(Employee e);
}
(5)引入日志框架和依赖
先引入依赖,这一步在引入依赖那里一起引入了,再在类路径下,也就是resources下创建log4j.xml,因为我已经有了,所以直接复制过来。
以上步骤都是和入门案例差不多的,对于接口我们只需要写我们要测试的方法就行,下面的才是重点。
(6)全局配置文件
重点关注驼峰配置,类型别名配置,映射路径配置
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE configuration
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!--驼峰映射-->
<settings>
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
<!--类型别名配置-->
<typeAliases>
<!-- <typeAlias type="pojo.Employee" alias="employee"></typeAlias>-->
<!--
采用包扫描的方式,一次性对某个包中的所有类配置别名,每个类的别名就是它的类名,不区分大小写
-->
<package name="pojo"/>
</typeAliases>
<environments default="dev">
<environment id="dev">
<transactionManager type="JDBC"></transactionManager>
<dataSource type="POOLED">
<property name="username" value="root"></property>
<property name="password" value="888888"></property>
<property name="driver" value="com.mysql.jdbc.Driver"></property>
<property name="url" value="jdbc:mysql://localhost:3306/mybatis-example"></property>
</dataSource>
</environment>
</environments>
<mappers>
<!--resource=映射路径-->
<!-- <mapper resource="mappers/EmployeeMapper.xml"/>-->
<package name="mappers"/>
</mappers>
</configuration>
这些配置的位置是有规定的,可以点configuration进去,可以看到下面的源码

所以先写驼峰<settings>,别名配置<typeAliases>,然后<environments>,<mappers>.
驼峰配置
pojo中属性命名采用驼峰命名规则,而表中字段名一般都是表名_字段名来表示,如果执行查询任务,我们在入门时采用的是取别名的方法,让结果集映射成功,封装到pojo类。但是如果字段名多了,这个方法就不太方便了,所以我们采用了驼峰命名法。直接在全局配置中加入下列代码。
<!-- 使用settings对Mybatis全局进行设置 -->
<settings>
<!-- 将xxx_xxx这样的列名自动映射到xxXxx这样驼峰式命名的属性名 -->
<setting name="mapUnderscoreToCamelCase" value="true"/>
</settings>
类型别名配置
在获取的结果集中,我们需要写全限定名,太长了,所以可以在全局配置中配置<typeAliases>标签,里面就是别名配置,有两种方法:
- 每一个typeAlias标签就表示配置一个别名
- type属性:要进行别名配置的类
- alias属性:取的别名
<typeAliases>
<typeAlias type="pojo.Employee" alias="employee"></typeAlias>
</typeAliases>
- 因为所有的POJO类基本上都是放在同一个包中,所以我们可以采用包扫描进行别名配置
用package标签进行包扫描,别名就是该类的类名(不区分大小写)
我们一般采用第二种(也就是包扫描的方式进行别名配置)
<typeAliases>
<package name="pojo"/>
</typeAliases>
Mapper映射
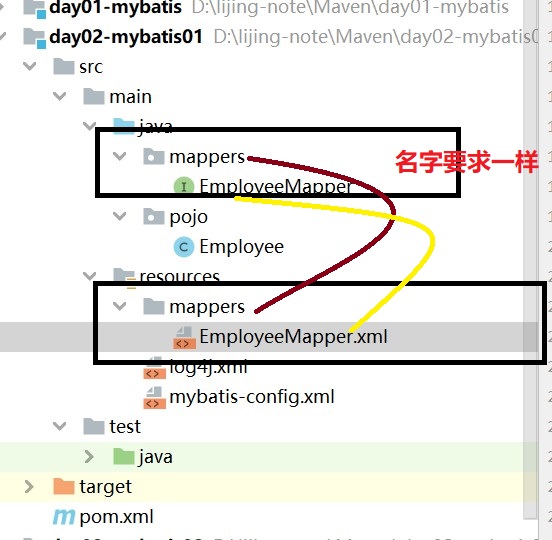
之前的案例都是只有一个接口,一个映射配置文件,如果多个接口多个映射配置文件,我们可以采取打包的方式,此时这个包下的所有Mapper配置文件将被自动加载、注册,比较方便。
但是,要求是:
- Mapper接口和Mapper配置文件名称一致
- Mapper配置文件放在Mapper接口所在的包内
<mappers>
<!--resource=映射路径-->
<!-- <mapper resource="mappers/EmployeeMapper.xml"/>-->
<package name="mappers"/>
</mappers>
模块下的包如图:
(7)映射配置文件
这一步重点是手动映射,为后面的多表查询做铺垫
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mappers.EmployeeMapper">
<!--手动映射,多表查询都会用到手动映射
autoMapping="true"表示能自动映射的就自动映射
驼峰映射在全局配置中配置
-->
<resultMap id="employeeMap" type="Employee" autoMapping="true">
</resultMap>
<select id="selectCount" resultType="long">
select count(emp_id) from t_emp
</select>
<select id="selectEmployeeByEmpId" resultMap="employeeMap" >
select * from t_emp where emp_id=#{emp_id}
</select>
<!--返回值是map类型,就不适用于上面的手动映射了,直接自动驼峰-->
<select id="selectEmployeeMapByEmpId" resultType="map" >
select * from t_emp where emp_id=#{emp_id}
</select>
<select id="selectEmployeeList" resultMap="employeeMap" >
select * from t_emp
</select>
<select id="selectMapList" resultType="map">
select * from t_emp
</select>
<!--
useGeneratedKeys="true"表示获取自增长的主键值
keyProperty="empId"表示将获取到的自增长的主键值赋给传入的POJO的empId属性
-->
<insert id="insertEmployee" useGeneratedKeys="true" keyProperty="empId">
insert into t_emp (emp_name,emp_salary) values (#{empName},#{empSalary})
</insert>
</mapper>
映射
映射一般包括全自动映射,驼峰映射,手动映射
手动映射
完整映射步骤如下:
<!--
手动映射:通过resultMap标签配置映射规则
1. id属性:表示这个手动映射规则的唯一表示
2. type属性: 表示这个手动映射规则是将结果集映射给哪个类的对象,就是JavaBean类的全限定名
resultMap标签中的子标签就是一一指定映射规则:
1. id标签:表示对主键进行手动映射
2. result标签:指定非主键的映射规则
id标签和result标签的属性:
1. column:要进行映射的结果集的字段名
2. property:要进行映射的JavaBean的属性名
-->
<resultMap id="EmployeeMap" type="Employee">
<id column="emp_id" property="id"/>
<result column="emp_name" property="name"/>
<result column="emp_salary" property="salary"/>
</resultMap>
<!--
在select标签中通过resultMap属性来指定使用哪个手动映射规则
-->
<select id="selectEmployeeByEmpId" resultMap="EmployeeMap">
select * from t_emp where emp_id=#{empId}
</select>
对比以下我加在配置文件的代码,
<resultMap id="employeeMap" type="Employee" autoMapping="true">
</resultMap>
加了autoMapping="true"表示我在全局配置的驼峰命名先自动映射,再手动映射,因为后面的id,result标签采用的是驼峰命名的手动映射,所以可以不写了。不过后面的多表关联查询就需要注意。值得注意的是,如果需要用到手动映射的地方,返回值的类型要改为resultMap="employeeMap"
获取自动增长的主键值
在这里加了一个方法,添加一条数据之后再获得添加后的主键值。有两种方法:
第一种(经常)
- useGeneratedKeys="true"表示获取自增长的主键值
- keyProperty="empId"表示将获取到的自增长的主键值赋给传入的POJO的empId属性
<insert id="insertEmployee" useGeneratedKeys="true" keyProperty="empId">
insert into t_emp (emp_name,emp_salary) values (#{empName},#{empSalary})
</insert>
第二种
可以使用在那些不支持主键自增的数据库中,比如Oracle
- selectKey表示查询键:
- keyColumn="emp_id" 表示要查询emp_id字段
- keyProperty="empId" 将查询到的字段赋值给POJO的empId属性
- order="AFTER"表示在执行添加语句之后进行查询
- resultType="int" 表示查询到的主键的类型
<!-- <insert id="insertEmployee" >
<selectKey keyColumn="emp_id" keyProperty="empId" order="AFTER" resultType="int">
select last_insert_id()
</selectKey>
insert into t_emp(emp_name,emp_salary) values(#{empName},#{empSalary})
</insert>-->
(8)测试程序
import mappers.EmployeeMapper;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.junit.After;
import org.junit.Before;
import pojo.Employee;
import java.io.InputStream;
public class Test {
private EmployeeMapper employeeMapper;
private InputStream is;
private SqlSession sqlSession;
@Before
public void init() throws Exception{
//目标:获取EmployeeMapper接口的代理对象,并且使用该对象调用selectEmployee(1)方法,然后返回Employee对象
//1. 将全局配置文件转成字节输入流
is = Resources.getResourceAsStream("mybatis-config.xml");
//2. 创建SqlSessionFactoryBuilder对象
SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder();
//3. 使用构建者模式创建SqlSessionFactory对象
SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(is);
//4. 使用工厂模式创建一个SqlSession对象
sqlSession = sqlSessionFactory.openSession();
//5. 使用动态代理模式,创建EmployeeMapper接口的代理对象
employeeMapper = sqlSession.getMapper(EmployeeMapper.class);
}
@After
public void after() throws Exception{
//提交事务!!!
sqlSession.commit();
//7. 关闭资源
is.close();
sqlSession.close();
}
@org.junit.Test
public void testSelectCount(){
System.out.println(employeeMapper.selectCount());
}
@org.junit.Test
public void testSelectEmployeeByEmpId(){
System.out.println(employeeMapper.selectEmployeeByEmpId(1));
}
@org.junit.Test
public void testSelectEmployeeMapByEmpId(){
System.out.println(employeeMapper.selectEmployeeMapByEmpId(1));
}
@org.junit.Test
public void testSelectEmployeeList(){
System.out.println(employeeMapper.selectEmployeeList());
}
@org.junit.Test
public void testSelectMapList(){
System.out.println(employeeMapper.selectMapList());
}
@org.junit.Test
public void testInsertEmployee(){
Employee e=new Employee(null,"alisa",666d);
employeeMapper.insertEmployee(e);
System.out.println(e.getEmpId());
}
}
总结:

下篇整理多表关联查询
二、mybatis之数据输出的更多相关文章
- Maven 工程下 Spring MVC 站点配置 (二) Mybatis数据操作
详细的Spring MVC框架搭配在这个连接中: Maven 工程下 Spring MVC 站点配置 (一) Maven 工程下 Spring MVC 站点配置 (二) Mybatis数据操作 这篇主 ...
- MyBatis基础入门《十二》删除数据 - @Param参数
MyBatis基础入门<十二>删除数据 - @Param参数 描述: 删除数据,这里使用了@Param这个注解,其实在代码中,不使用这个注解也可以的.只是为了学习这个@Param注解,为此 ...
- (转)MyBatis框架的学习(二)——MyBatis架构与入门
http://blog.csdn.net/yerenyuan_pku/article/details/71699515 MyBatis框架的架构 MyBatis框架的架构如下图: 下面作简要概述: S ...
- 把数据输出到Word (组件形式)
上一篇的文章中我们介绍了在不使用第三方组件的方式,多种数据输出出到 word的方式,最后我们也提到了不使用组件的弊端,就是复杂的word我们要提前设置模板.编码不易控制.循环输出数据更是难以控制.接下 ...
- 把数据输出到Word (非插件形式)
项目开发过程中,我们要把数据以各种各样的形式展现给客户.把数据以文档的形式展现给客户相信是一种比较头疼的问题,如果没有好的方法会 使得我的开发繁琐,而且满足不了客户的需求.接下来我会通过两种开发方式介 ...
- tp5数据输出
法一:系统配置 'default_return_type'=>'json' 法二:输出设置 namespace app\index\controller; class Index { publi ...
- (3)分布式下的爬虫Scrapy应该如何做-递归爬取方式,数据输出方式以及数据库链接
放假这段时间好好的思考了一下关于Scrapy的一些常用操作,主要解决了三个问题: 1.如何连续爬取 2.数据输出方式 3.数据库链接 一,如何连续爬取: 思考:要达到连续爬取,逻辑上无非从以下的方向着 ...
- Mybatis实现数据的增删改查
Mybatis实现数据的增删改查 1.项目结构(使用maven创建项目) 2.App.java package com.GetcharZp.MyBatisStudy; import java.io.I ...
- 计算机二级-C语言-对二维数组数据进行处理。对文件进行数据输入。形参与实参。
//函数fun的功能为:计算x所指数组中N个数的平均值(规定所有数都为正数),平均值通过形参返回给主函数,将小于平均值且最接近平均值的数作为函数值返回,并输出. //重难点:形参与实参之间,是否进行了 ...
随机推荐
- wpf 中 theme 的使用 和 listview 模板的使用.
theme 文件 <ResourceDictionary xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentatio ...
- Socket编程 Tcp和粘包
大多数程序员都要接触网络编程,Web开发天天和http打交道.稍微底层一点的程序员,就是TCP/UDP . 对程序员来说,Tcp/udp的核心是Socket编程. 我的浅薄的观点---------理解 ...
- 处理URLs
问题 你有一个包含相对URLs路径的HTML文档,需要将这些相对路径转换成绝对路径的URLs. 方法 在你解析文档时确保有指定base URI,然后 使用 abs: 属性前缀来取得包含base URI ...
- Spring中Resource(资源)的获取
1.通过Resource接口获取资源 Resource接口的实现类有: Resource接口继承了InputStreamSource 接口,InputStreamSource 接口中有一个方法:get ...
- MySQL案例:一次单核CPU占用过高问题的处理
客户现场反馈,top的检查结果中,一个CPU的占用一直是100%.实际上现场有4个CPU,而且这个服务器是mysql专属服务器. 我的第一反应是io_thread一类的参数设置有问题,检查以后发现re ...
- openresty HTTP status constants nginx api for lua
https://github.com/openresty/lua-nginx-module context: init_by_lua, set_by_lua, rewrite_by_lua, acce ...
- K8s 系列(三) - 如何配置 etcd https 证书?
在 K8s 中,kube-apiserver 使用 etcd 对 REST object 资源进行持久化存储,本文介绍如何配置生成自签 https 证书,搭建 etcd 集群给 apiserver 使 ...
- echo -e 命令详解
echo在php中是输入那么在linux中是不是也是输入呢,当然echo在linux也是输入不过它的用法比php强大多了可以带参数及一些东西,下面我们来看一篇关于linux echo命令介绍及-n.- ...
- Identity用户管理入门三(注册用户)
用户注册主要有2个方法,1.密码加密 2.用户注册 3.ASP.NET Core Identity 使用密码策略.锁定和 cookie 配置等设置的默认值. 可以在类中重写这些设置 Startup(官 ...
- Abp VNext权限定义
在Shop.Application.Contracts项目中Permissions目录下ShopPermissions定义权限名 namespace Shop.Permissions { public ...