面试一次问一次,HashMap是该拿下了(一)
文章目录
前言
业精于勤荒于嬉,行成于思毁于随;
在码农的大道上,唯有自己强才是真正的强者,求人不如求己,静下心来,开始思考…
今天一起来聊一聊 HashMap集合,看到这里,笔者懂,大家莫慌,先来宝图镇楼 ~
咳咳… 对于屏幕前帅气的猿友们来说,HashMap… 张口就来,闭眼能写,但是呢,面试一问立马慌,自己阅读源码又隐隐觉得知其然不知其所以然;
那么…此时,笔者帅气的脸庞似有似无洋溢起一抹微笑,毕竟是查看过源码的猿,就是那么的豪横,话不多说,来吧,展示…
一、HashMap类图
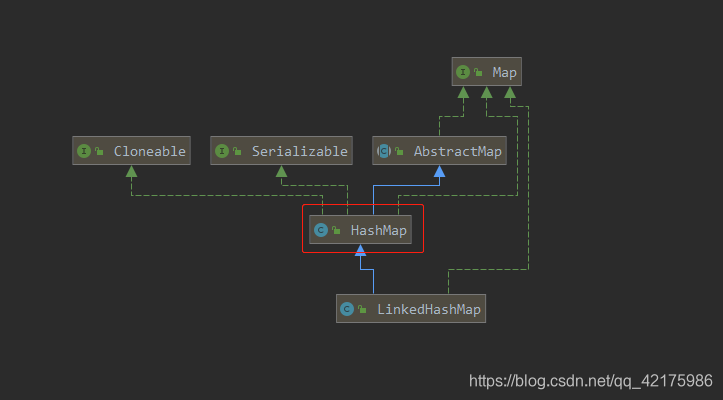
二、源码剖析
1. HashMap(jdk1.7版本) - 此篇详解
大家都知道,jdk1.7版本底层数组+链表(单向链表),结合笔者的经验之谈,我觉得在分析HashMap集合具体操作源码前,有必要先了解下其底层链表结构,上源码…
- 链表结构 - 单向链表
/**
* HashMap1.7中定义- 单向链表
*/
static class Entry<K,V> implements Map.Entry<K,V> {
// key值
final K key;
// value值
V value;
// 下一个节点
Entry<K,V> next;
// hash值
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
// 重写equals方法
public final boolean equals(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry e = (Map.Entry)o;
Object k1 = getKey();
Object k2 = e.getKey();
if (k1 == k2 || (k1 != null && k1.equals(k2))) {
Object v1 = getValue();
Object v2 = e.getValue();
if (v1 == v2 || (v1 != null && v1.equals(v2)))
return true;
}
return false;
}
// 重写hashCode方法
public final int hashCode() { return Objects.hashCode(getKey()) ^ Objects.hashCode(getValue()); }
// 重写toString方法
public final String toString() { return getKey() + "=" + getValue(); }
// value被覆盖调用一次
void recordAccess(HashMap<K,V> m) { }
// todo:此此两方法主要作用于HashMap的子类实现,eg:linkedHashMap
// 每移除一个entry就被调用一次
void recordRemoval(HashMap<K,V> m) { }
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
如此如此,这般这般… 然而…这就是HashMap1.7版本定义的链表结构之单向链表…
每一个Entry节点包含四个属性:key表示当前节点key值;value表示当前节点value值,next节点表示当前节点下一个节点,如当前节点为链表末尾节点,则当前节点的next节点为null;hash表示当前节点key值通过算法计算出来的hash值;
抽象图解如下(其实笔者并不是很认同此图能形象的代表链表结构,但抽象理解还是可以的):
单个Entry节点: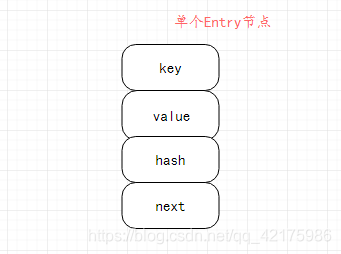
单向链表图解:
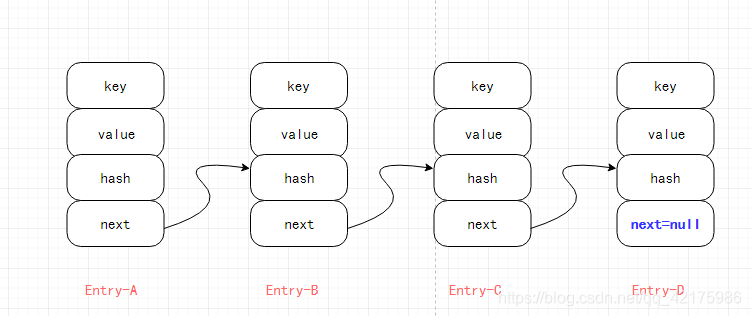
HashMap1.7版本底层 数组 + 单向链表 图解:
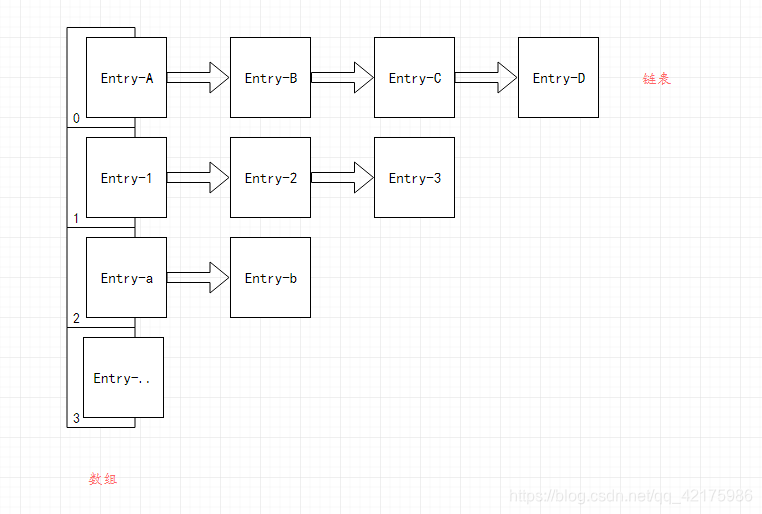
- 构造函数
// 数组默认初始容量 - 16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
// 加载因子 - 默认值
static final float DEFAULT_LOAD_FACTOR = 0.75f;
// 加载因子
final float loadFactor;
// 最大容量
static final int MAXIMUM_CAPACITY = 1 << 30;
// 扩容阈值(也表示hashMap底层数组实际存放元素大小)
int threshold;
/**
* 无参构造
*/
public HashMap() {
this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
}
/**
* 有参构造
* @param initialCapacity:自定义初始容量
* @param loadFactor:自定义
*/
public HashMap(int initialCapacity, float loadFactor) {
// 判断初始容量值有效性
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity);
// 判断最大初始容量
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
// 判断加载因子有效性
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " + loadFactor);
// 设置加载因子-默认0.75
this.loadFactor = loadFactor;
// 设置扩容阈值(构造初始化为16,第一次put为12)
threshold = initialCapacity;
// 模板方法-默认无实现
init();
}
// 模板方法-设计模式:表示继承可拓展
void init() {
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
从源码中可以看出,构造只为相关参数(加载因子、扩容阈值)进行初始化;
其中需注意一点,我们都知道HashMap的扩容阈值为12,但在构造初始化的时候扩容阈值为16(知识点虽小,但却是细节);
那么此篇文章重点要来了,静下心来,开始思考…
- put() - 添加元素方法
// 数组默认值-空数组
static final Entry<?,?>[] EMPTY_TABLE = {};
// 底层数组
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
// HashMap元素个数
transient int size;
// 记录对HashMap操作次数
transient int modCount;
transient int hashSeed = 0;
/**
* 入口
*/
public V put(K key, V value) {
// 1.第一次put元素
// 数组为空进行参数初始化-表示第一次put元素
if (table == EMPTY_TABLE) {
// 数组初始化/参数初始化
// 第一次put时,threshold经过构造方法赋值为16
inflateTable(threshold);
}
// 2.添加key为null的元素
if (key == null)
return putForNullKey(value);
// 3.添加key非null的元素
// 计算hash值
int hash = hash(key);
// 计算数组对应下标值
int i = indexFor(hash, table.length);
// 遍历数组下标为i的链表
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
// hash冲突 && key相同
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 获取遍历节点元素值
V oldValue = e.value;
// 对value进行覆盖
e.value = value;
// value被覆盖时调用
e.recordAccess(this);
// 返回旧元素值
return oldValue;
}
}
// 操作次数++
modCount++;
// 添加Entry节点
addEntry(hash, key, value, i);
return null;
}
// 数组初始化/参数初始化
private void inflateTable(int toSize) {
// 计算初始容量
// 第一次put时,返回值:16
int capacity = roundUpToPowerOf2(toSize);
// 计算扩容阈值:16 * 0.75 = 12
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
// 初始化长度为16的table数组
table = new Entry[capacity];
// 此方法不影响主要功能,咱跳过此方法(有兴趣的猿友们可自行研究哦~)
initHashSeedAsNeeded(capacity);
}
// 用于返回大于等于最接近number的2的整数次幂
private static int roundUpToPowerOf2(int number) {
// 第一次put元素时: 16 >= 数组最大容量(1 << 30) ? (1 << 30) : (16 > 1) ? Integer.highestOneBit((16-1) << 1) : 1
// Integer.highestOneBit((16-1) << 1) = Integer.highestOneBit(30) = 16
return number >= MAXIMUM_CAPACITY ? MAXIMUM_CAPACITY : (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
// 添加key为null的元素 - 可以看出key为null时,存放在数组下标为0的位置
private V putForNullKey(V value) {
// 遍历数组下标为0的链表
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
// 获取遍历节点元素值
V oldValue = e.value;
// 对value进行覆盖
e.value = value;
// value被覆盖时调用
e.recordAccess(this);
// 返回旧值
return oldValue;
}
}
// 操作次数++
modCount++;
// 添加Entry节点
addEntry(0, null, value, 0);
return null;
}
// 添加Entry节点
void addEntry(int hash, K key, V value, int bucketIndex) {
// map元素个数 > 扩容阈值 && 当前数组位置对应链表不为空
if ((size >= threshold) && (null != table[bucketIndex])) {
// 将源数组中的元素值散列至新数组
resize(2 * table.length);
// 计算hash值 - 重新计算
hash = (null != key) ? hash(key) : 0;
// 计算对应新数组下标位置
bucketIndex = indexFor(hash, table.length);
}
// 添加Eentry节点
createEntry(hash, key, value, bucketIndex);
}
// 将源数组中的元素值散列至新数组
void resize(int newCapacity) {
// 获取源数组
Entry[] oldTable = table;
// 获取源数组长度
int oldCapacity = oldTable.length;
// 数组长度最大值设置
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 创建长度为源数组长度2倍的新数组
Entry[] newTable = new Entry[newCapacity];
// 将源数组中的元素值散列至新数组
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 将新数组赋值至源数组
table = newTable;
// 重新计算扩容阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
// 获取当前Key对应hash值
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String)
return sun.misc.Hashing.stringHash32((String) k);
h ^= k.hashCode();
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
// 获取对应数组下标位置
static int indexFor(int h, int length) {
return h & (length-1);
}
// 添加Eentry节点
void createEntry(int hash, K key, V value, int bucketIndex) {
// 获取数组下标对应链表
Entry<K,V> e = table[bucketIndex];
// 向链表中添加节点
table[bucketIndex] = new Entry<>(hash, key, value, e);
// HashMap元素个数++
size++;
}
// 将源数组中元素散列至新数组中
void transfer(Entry[] newTable, boolean rehash) {
// 获取新数组长度
int newCapacity = newTable.length;
// 遍历源数组,将元素按照一定规则散列至新数组
// 外循环:遍历数组
for (Entry<K,V> e : table) {
// 内循环:遍历数组位置对应链表
while(null != e) {
// 获取当前节点下一个节点
Entry<K,V> next = e.next;
if (rehash) {
// true:重新计算hash值
e.hash = null == e.key ? 0 : hash(e.key);
}
// 获取对应新数组的下标值
int i = indexFor(e.hash, newCapacity);
// 下面三步一定要连起来去思考:
// **前提条件,2次循环都作用于新数组同一下标位置的情况:
// 第一次循环时,newTable[i]为空,先赋值给当前遍历节点的下个节点,再将当前遍历节点赋值给对应新下标的新数组,最后继续循环
// 第二次循环时,newTable[i]为上次(存入同一下标位置对应新数组的链表),然后赋值给当前遍历节点的下个节点(此节点实则为上一次遍历节点的下一个节点,
// 从这里可以看出,HashMap1.7这里用的是头插法),再将此链表赋值给同一下标位置的新数组中,最后不为空继续循环;
e.next = newTable[i];
newTable[i] = e;
e = next;
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
果不其然,相信大部分猿友硬着头皮跟一大坨代码硬钢之下,还是放弃了抵抗,来到了这里看笔者结论;
此时,笔者帅气的脸庞似有似无洋溢起一抹微笑,毕竟是查看过源码的猿;
其实呢,看源码也是有其讲究的,相信细心的猿友已从笔者源码注释看出些许问道,正如其所料,其实说白了,put()添加元素方法只做了三件事,下面我们拆解分析下:
- 第一次put元素(当前为第一次添加元素时):
- 计算扩容阈值:
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1); // threshold = 16 * 0.75 = 12
- 1
- 初始化底层数组:
table = new Entry[capacity]; // capacity = 16
- 1
- 添加key为null的元素:
遍历数组下标为0的链表:
⑴ 如判断已存在 key=null 的节点,则覆盖其value值;
if (e.key == null) {
// 获取遍历节点元素值
V oldValue = e.value;
// 对value进行覆盖
e.value = value;
// value被覆盖时调用
e.recordAccess(this);
// 返回旧值
return oldValue;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
⑵ 反之,则添加节点;
// 操作次数++
modCount++;
// 添加Entry节点
addEntry(0, null, value, 0);
- 1
- 2
- 3
- 4
- 5
- 添加key非null的元素:
计算key键对应的hash值:
通过hash值计算对应数组下标存放位置;
遍历数组对应下标的链表(步骤2计算的下标):
⑴ 如判断hash值相等且key值相等,则覆盖其value值;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 获取遍历节点元素值
V oldValue = e.value;
// 对value进行覆盖
e.value = value;
// value被覆盖时调用
e.recordAccess(this);
// 返回旧元素值
return oldValue;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
⑵ 反之,则添加节点;
// 操作次数++
modCount++;
// 添加Entry节点
addEntry(0, null, value, 0);
- 1
- 2
- 3
- 4
- 5
不知过了许久…
此时,笔者嘴角若隐若现一丝弧度微起,源码么,也不过如此…
咳咳… 请原谅笔者,毕竟从小到大无如此之成就感爆棚,猝不及防下狠狠地又装了一把…
我们言归正传,相信屏幕前的猿友经过笔者此分析,或多或少收获些许源码知识,至于其中如何判断key存在,如何进行value值覆盖,如何添加Entry节点,相信对于现在已然拿下put()方法框架思路的猿友来说,只是so easy的事情了,那么…此时…往上翻翻吧,趁着思路清晰,静下心来,参考着笔者源码注释,争取拿下其方法细节…
此时此刻,屏幕前拥有盛世美颜的你,给也同样拥有盛世美颜的暖男笔者,赏脸来个三连吧…笔者已迫不及待准备好么么哒,亲在…
- get() - 获取元素方法
/**
* 入口
*/
public V get(Object key) {
// key为空时获取元素值
if (key == null)
return getForNullKey();
// 获取key对应Entry链表
Entry<K,V> entry = getEntry(key);
// 返回对应元素值
return null == entry ? null : entry.getValue();
}
// key为空获取元素值 - 可以看出key为null时,在下标为0的位置的数组获取
private V getForNullKey() {
// map元素个数为0时返回 null
if (size == 0) {
return null;
}
// 获取下标为0的链表
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
// 遍历key=null,返回对应元素值
if (e.key == null)
return e.value;
}
// 无->返回null
return null;
}
// 获取key对应Entry链表
final Entry<K,V> getEntry(Object key) {
// map元素个数为0时返回 null
if (size == 0) {
return null;
}
// 计算hash
int hash = (key == null) ? 0 : hash(key);
// 1.计算对应数组下标值 2.遍历数组位置对应链表
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
// hash相等 && key相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
// 无->返回null
return null;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
相信对于屏幕前已拿下put()方法的你来说,获取元素方法,简直very so easy;
从源码中可以看出,获取元素时做了2件事:
- 获取 key=null 的元素:
遍历数组下标为0的链表:
⑴ 如判断已存在 key=null 的节点,则返回其value值;
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
// 遍历key=null,返回对应元素值
if (e.key == null)
return e.value;
}
- 1
- 2
- 3
- 4
- 5
⑵ 反之,则返回null;
- 获取 key非null 的元素:
计算key键对应的hash值:
通过hash值计算对应数组下标存放位置;
遍历数组对应下标的链表(步骤2计算的下标):
⑴ 如判断hash值相等且key值相等,则返回其value值;
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
// hash相等 && key相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
- 1
- 2
- 3
- 4
- 5
- 6
⑵ 反之,则返回 null;
笔者:当你翻过代码中最高的的一座山之后,剩下的只是一码平川;
- remove() - 删除元素方法
/**
* 入口
*/
public V remove(Object key) {
// 获取key对应Entry链表
Entry<K,V> e = removeEntryForKey(key);
// 返回删除元素值
return (e == null ? null : e.value);
}
// 获取删除元素对应Entry链表
final Entry<K,V> removeEntryForKey(Object key) {
// map元素个数为0时返回 null
if (size == 0) {
return null;
}
// 计算hash值
int hash = (key == null) ? 0 : hash(key);
// 计算对应数组下标位置
int i = indexFor(hash, table.length);
// 获取数组下标为i对应链表
Entry<K,V> prev = table[i];
// 链表第一次赋值
Entry<K,V> e = prev;
// 遍历此链表
while (e != null) {
// 获取当前节点下一个节点
Entry<K,V> next = e.next;
Object k;
// hash相等 && key相等
if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) {
// 操作次数++
modCount++;
// map元素个数--
size--;
// 当前判断表示:循环此链表第一个节点
if (prev == e)
// 直接将当前遍历(删除)节点的下一个节点赋值即可
table[i] = next;
else
// 表示循环非此链表第一个节点
// 将上个节点的next节点设置为 当前遍历(删除)节点的下一个节点
prev.next = next;
// 移除一个entry调用一次
e.recordRemoval(this);
// 返回删除节点
return e;
}
// 将当前遍历(非删除)节点赋值给prev
prev = e;
// 将当前遍历(非删除)节点的下一个节点赋值给e(下一次遍历的节点)
e = next;
}
// e!=null但无对应key -> 返回此链表最后一个Entry节点
// e==null -> 返回null
return e;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
相信屏幕前的猿友,此时此刻正干劲十足,越挫越勇,那么… 恭黑雷(恭喜你),拿下HashMap近在咫尺;
从源码中可以看出,删除元素实则就做了一件事,修改节点之间的引用;
注意,删除元素中唯一比较绕的就是此代码,结合笔者注释,注意细节即可: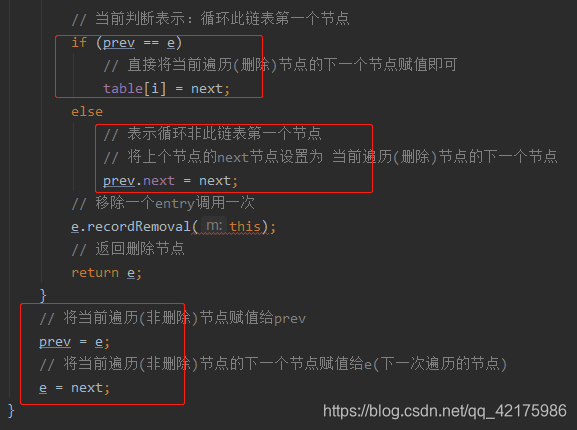
原文章:https://blog.csdn.net/qq_42175986/article/details/111994967
- HashMap(jdk1.7版本)总结:
- 底层为数组 + 链表(单向链表);
- 线程不安全;
- 数组初始容量为16;
- 扩容加载因子为0.75;
- 扩容阈值 a.构造之后为16,第一次put()方法后为12;
- 扩容死循环问题 - 笔者之后会另起一篇详解;
- 有modCount;
2. HashMap(jdk1.8版本)
面试一次问一次,HashMap是该拿下了之 HashMap1.8版本
3. ConcurrentHashMap
面试一次问一次,HashMap是该拿下了之 ConcurrentHashMap
面试一次问一次,HashMap是该拿下了(一)的更多相关文章
- 我说我了解集合类,面试官竟然问我为啥HashMap的负载因子不设置成1!?
在Java基础中,集合类是很关键的一块知识点,也是日常开发的时候经常会用到的.比如List.Map这些在代码中也是很常见的. 个人认为,关于HashMap的实现,JDK的工程师其实是做了很多优化的,要 ...
- 面试官再问你 HashMap 底层原理,就把这篇文章甩给他看
前言 HashMap 源码和底层原理在现在面试中是必问的.因此,我们非常有必要搞清楚它的底层实现和思想,才能在面试中对答如流,跟面试官大战三百回合.文章较长,介绍了很多原理性的问题,希望对你有所帮助~ ...
- 电话面试总结(问的很细).md
String 和其他基本类型有什么区别 Tip 基本类型有几种 为什么要给String创建一个常量池而不给其他类创建常量池 常量池的定义是什么 垃圾回收机制是如何运行的 对新生代和老年代不同的处理机制 ...
- 【搞定 Java 并发面试】面试最常问的 Java 并发进阶常见面试题总结!
本文为 SnailClimb 的原创,目前已经收录自我开源的 JavaGuide 中(61.5 k Star![Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识.觉得内容不错 ...
- 应届生/社招面试最爱问的几道Java基础问题
本文已经收录自笔者开源的 JavaGuide: https://github.com/Snailclimb ([Java学习+面试指南] 一份涵盖大部分Java程序员所需要掌握的核心知识)如果觉得不错 ...
- JVM工作原理和特点(一些二逼的逼神面试官会问的问题)
作为一种阅读的方式了解下jvm的工作原理 ps:(一些二逼的逼神面试官会问的问题) JVM工作原理和特点主要是指操作系统装入JVM是通过jdk中Java.exe来完毕,通过以下4步来完毕JVM环境. ...
- 面试中常问的List去重问题,你都答对了吗?
面试中经常被问到的list如何去重,用来考察你对list数据结构,以及相关方法的掌握,体现你的java基础学的是否牢固. 我们大家都知道,set集合的特点就是没有重复的元素.如果集合中的数据类型是基本 ...
- 面试阿里百分百问的Jvm,别问有没有必要学,真的很有必要朋友
面试阿里百分百问的Jvm,别问有没有必要学,真的很有必要朋友 前言: JVM 的内存模型和 JVM 的垃圾回收机制一直是 Java 业内从业者绕不开的话题(实际调优.面试)JVM是java中很重要的一 ...
- 面试总被问分布式ID怎么办? 滴滴(Tinyid)甩给他
整理了一些Java方面的架构.面试资料(微服务.集群.分布式.中间件等),有需要的小伙伴可以关注公众号[程序员内点事],无套路自行领取 一口气说出 9种 分布式ID生成方式,面试官有点懵了 面试总被问 ...
随机推荐
- 【实用小技巧】spring springmvc集成shiro时报 No bean named 'shiroFilter' available
查了网上的,很多情况,不同的解决办法,总归一点就是配置文件加载的问题. 先看下配置文件中的配置 web.xml中的主要配置(这是修改后不在报错的:仅仅修改了一个位置:[classpath:spring ...
- windows桌面图标及任务管理栏丢失
背景环境: 卸载某些软件,如Auto CAD 2011 之后,会出现桌面图标和任务栏丢失的现象,某些重要文件没有保存或者不能注销及重启的动作 1:按组合键Ctrl+Shift+Esc,键调出任务管理器 ...
- 简单说几个MySQL高频面试题
前言: 在各类技术岗位面试中,似乎 MySQL 相关问题经常被问到.无论你面试开发岗位或运维岗位,总会问几道数据库问题.经常有小伙伴私信我,询问如何应对 MySQL 面试题.其实很多面试题都是大同小异 ...
- 获取CPU频率
#include <stdio.h> #include <string.h> float get_cpu_clock_speed() { FILE *fp; char buff ...
- golang:Channel协程间通信
channel是Go语言中的一个核心数据类型,channel是一个数据类型,主要用来解决协程的同步问题以及协程之间数据共享(数据传递)的问题.在并发核心单元通过它就可以发送或者接收数据进行通讯,这在一 ...
- 【转载】在python的class中的,self到底是什么?
在python的class中的,self到底是什么? 答案:self可以理解为一个字典变量,内部存的就是对象的数据属性.如:{'name':'zhang','age':'18'}就是这些. 注意只 ...
- sed常用
行首添加字符串 # cat a [root@localhost b]# vim a 文件a将每行的第1列添加HEAD [root@localhost b]# sed 's/^/HEAD &/g ...
- Linux_配置认证访问FTP服务
[RHEL8]-FTPserver:[Centos8]-FTPclient !!!测试环境我们首关闭防火墙和selinux(FTPserver和FTPclient都需要) [root@localhos ...
- TEB 系统综合误差
TEB 系统综合误差 和森世籍 聊天得知 该TEB 包括 传感器误差 温度 系统误差等等
- stm32中关于NVIC_SetVectorTable函数使用的疑惑与理解
[转载]2017年12月4日14:48:29 先描述下这几天碰到的一个奇怪的问题: 一个基于stm32的工程中使用到了IAP编程,其中boot空间预留长度为0x6100,实际boot的bin文件大小为 ...