JAVA并发(7)-并发队列PriorityBlockingQueue的源码分析
本文讲PriorityBlockingQueue(优先阻塞队列)
1. 介绍
一个无界的具有优先级的阻塞队列,使用跟PriorityQueue相同的顺序规则,默认顺序是自然顺序(从小到大)。若传入的对象,不支持比较将报错( ClassCastException)。不允许null。
底层使用的是基于数组的平衡二叉树堆实现(它的优先级的实现)。
公共方法使用单锁ReetrantLock保证线程的安全性。
1.1 类结构
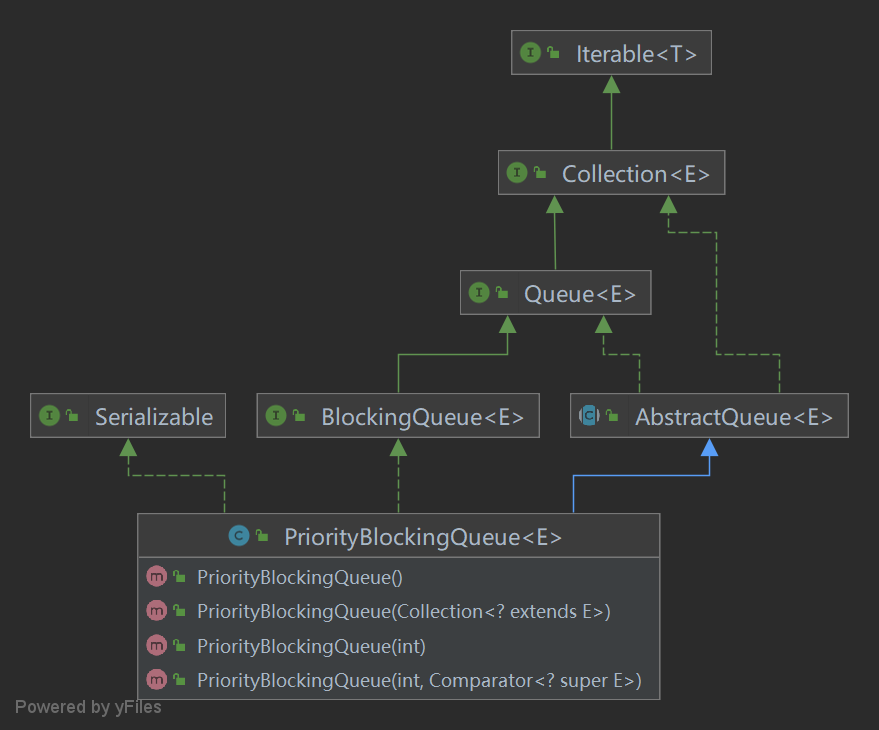
- PriorityBlockingQueue类图
重要的参数
// 数组的默认大小,会自动扩容的private static final int DEFAULT_INITIAL_CAPACITY = 11;/*** The maximum size of array to allocate.* Some VMs reserve some header words in an array.* Attempts to allocate larger arrays may result in* OutOfMemoryError: Requested array size exceeds VM limit*/// 为啥是减8,一些虚拟机会在数组中保留一些header words(头字), 应该学到jvm时,就知道了private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;private transient Object[] queue;...// 如果是空的话,优先级队列就使用元素的自然顺序(从小到大)private transient Comparator<? super E> comparator;
保证线程安全的措施
/*** Lock used for all public operations*/private final ReentrantLock lock;/*** Condition for blocking when empty*/// 为啥没有notFull,因为该队列是无界的private final Condition notEmpty;/*** Spinlock for allocation, acquired via CAS.*/// 为啥用CAS,而不是锁,来控制线程安全在扩容时,后面讲private transient volatile int allocationSpinLock;
2. 源码剖析
我们知道PriorityBlockingQueue实现了BlockingQueue,这篇博客有提到过BlockingQueue可以看一下,它定义了四种方式,对不能立即满足条件的不同的方法,有不同的处理方式。
我们一起去看看下面几种类型的方法的具体实现
- 入队
- 出队
2.1 入队
public boolean add(E e) {return offer(e);}public void put(E e) {offer(e); // never need to block}// 忽略时间public boolean offer(E e, long timeout, TimeUnit unit) {return offer(e); // never need to block}
上面几个入队方法都是去调用的offer(e),所以主要来看看这个方法的实现吧
public boolean offer(E e) {if (e == null)throw new NullPointerException();final ReentrantLock lock = this.lock;lock.lock();int n, cap;Object[] array;// 直到扩容成功或溢出为止while ((n = size) >= (cap = (array = queue).length))tryGrow(array, cap);try {Comparator<? super E> cmp = comparator;if (cmp == null)// 二叉堆的插入算法,在后面讲siftUpComparable(n, e, array);elsesiftUpUsingComparator(n, e, array, cmp);size = n + 1;notEmpty.signal();} finally {lock.unlock();}return true;}
总体步骤很简单,查看是否需要扩容,然后再插入元素到二叉堆里。我们看看扩容的实现
- 扩容
容量小于64,oldCap + (oldCap + 2); 否则oldCap + (oldCap * 0.5)
private void tryGrow(Object[] array, int oldCap) {lock.unlock(); // must release and then re-acquire main lockObject[] newArray = null;// allocationSpinLock默认是0,表示此时没有线程在扩容if (allocationSpinLock == 0 &&UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,0, 1)) {try {int newCap = oldCap + ((oldCap < 64) ?(oldCap + 2) : // grow faster if small(oldCap >> 1));// 检查是否溢出if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflowint minCap = oldCap + 1;if (minCap < 0 || minCap > MAX_ARRAY_SIZE)throw new OutOfMemoryError();newCap = MAX_ARRAY_SIZE;}if (newCap > oldCap && queue == array)newArray = new Object[newCap];} finally {allocationSpinLock = 0;}}// 此时,另一个线程正在扩容;让出自己的CPU时间片,下次再去抢占CPU时间片if (newArray == null) // back off if another thread is allocatingThread.yield();// 重新获取锁lock.lock();// newArray已经被初始化了// 如果queue != array, queue已经被改变了;有两种可能:// 1. 已经有元素被出队了// 2. 已经有元素入队了,此时入队的线程肯定扩容成功了(在没有其他元素出队的情况下)if (newArray != null && queue == array) {queue = newArray;System.arraycopy(array, 0, newArray, 0, oldCap);}}
为什么扩容时,会解锁,并通过CAS去进行新容量的计算?
However, allocation during resizing uses a simple spinlock (used only while not holding main lock) in order to allow takes to operate concurrently with allocation.This avoids repeated postponement of waiting consumers and consequent element build-up.
上面的话,大致意思就是,扩容时使用自旋锁而不是lock,为了在扩容时,也可以执行出队操作(上面的代码中,扩容比较耗费时间)。避免让阻塞的消费者被反复阻塞(被唤醒后,不满足条件,又被阻塞,反复)。
Doug Lea
2.2 出队
只讲poll()的实现;take()与poll(long timeout, TimeUnit unit)的实现都差不多
public E poll() {final ReentrantLock lock = this.lock;lock.lock();try {return dequeue();} finally {lock.unlock();}}
我们先看二叉堆的插入方法siftUpComparable,再看dequeue。
// k = size x为插入的元素private static <T> void siftUpComparable(int k, T x, Object[] array) {Comparable<? super T> key = (Comparable<? super T>) x;while (k > 0) {int parent = (k - 1) >>> 1; // (k -1) / 2Object e = array[parent];if (key.compareTo((T) e) >= 0)break;array[k] = e;k = parent;}array[k] = key;}
这个二叉堆是小根堆(任何一个结点的左右子节点的值都大于自己)
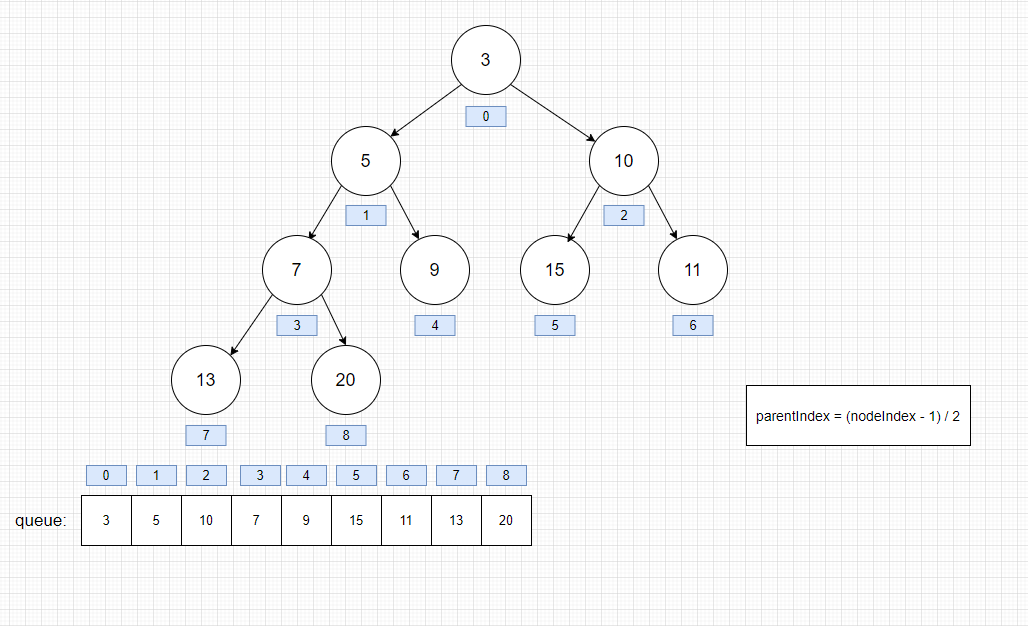
- 堆初始化
此时,我们执行offer(4)。按照上面的源码,我们最后得到
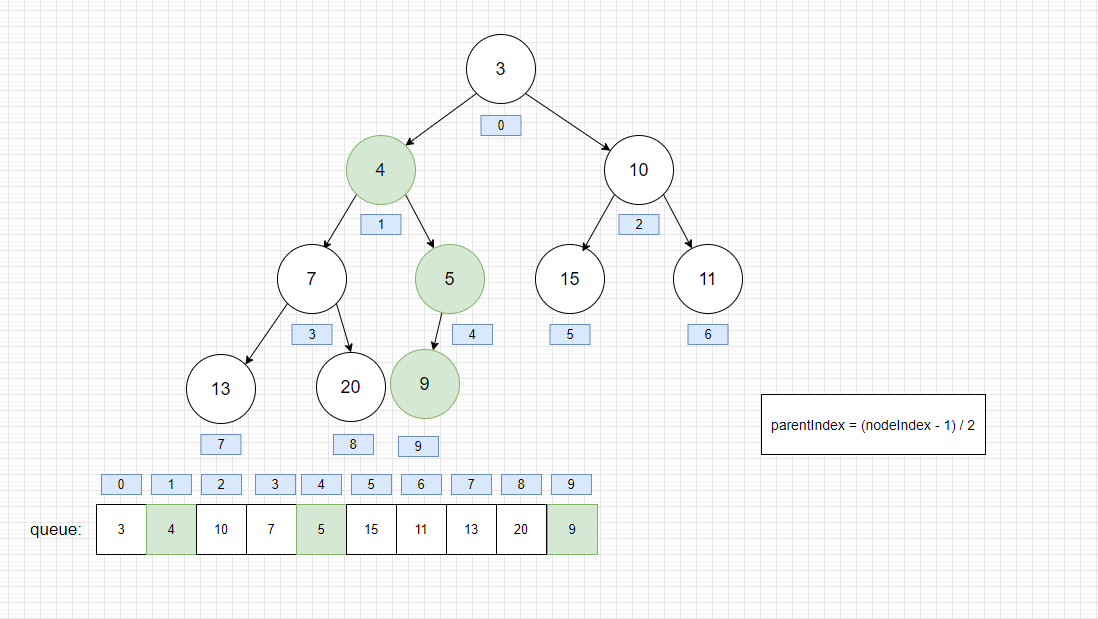
- offer(4)
整个堆插入的思路: 欲插入的元素是否比其父结点小,则与父结点互相交换(小根堆)
我们再执行poll() -> dequeue()
返回头部元素,然后重新调整堆元素位置
/*** Mechanics for poll(). Call only while holding lock.*/private E dequeue() {int n = size - 1;if (n < 0)return null;else {Object[] array = queue;// 获取第一个值E result = (E) array[0];// 保存末尾的值,并置空E x = (E) array[n];array[n] = null;Comparator<? super E> cmp = comparator;if (cmp == null)// 调整堆的位置siftDownComparable(0, x, array, n);elsesiftDownUsingComparator(0, x, array, n, cmp);size = n;return result;}}
将 x元素插入到k位置,为了维持二叉堆的平衡,一直降级x直到它小于或等于它的子节点
private static <T> void siftDownComparable(int k, T x, Object[] array,int n) {if (n > 0) {Comparable<? super T> key = (Comparable<? super T>)x;int half = n >>> 1; // half = n / 2 // loop while a non-leafwhile (k < half) {int child = (k << 1) + 1; // assume left child is least child = k * 2 + 1Object c = array[child];int right = child + 1;if (right < n &&((Comparable<? super T>) c).compareTo((T) array[right]) > 0)// 左右节点谁小,谁就当父结点c = array[child = right];if (key.compareTo((T) c) <= 0)break;array[k] = c;k = child;}array[k] = key;}}
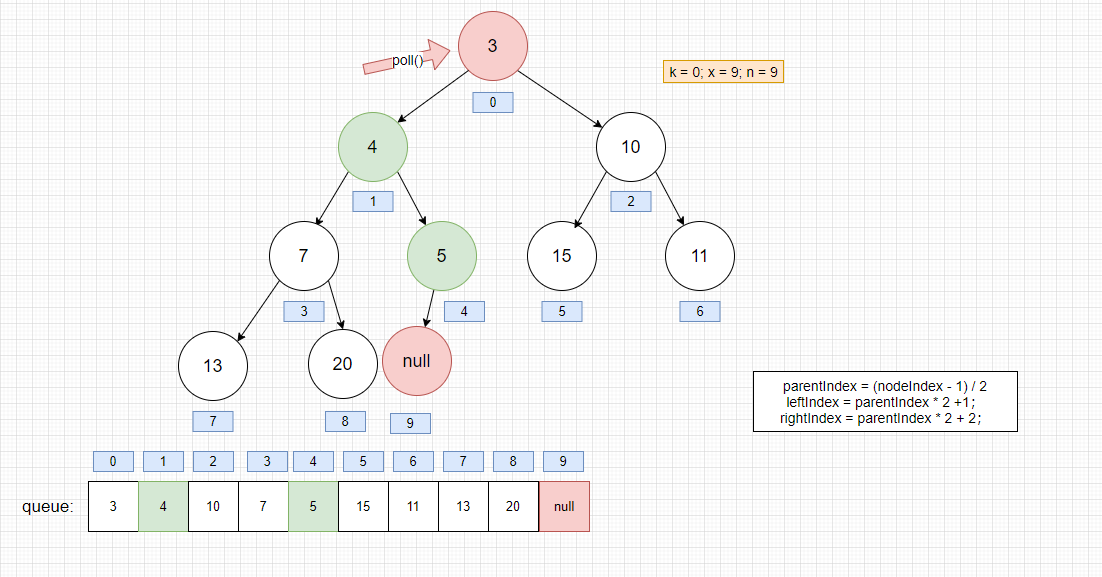
- 进入siftDownComparable的状态
执行完毕
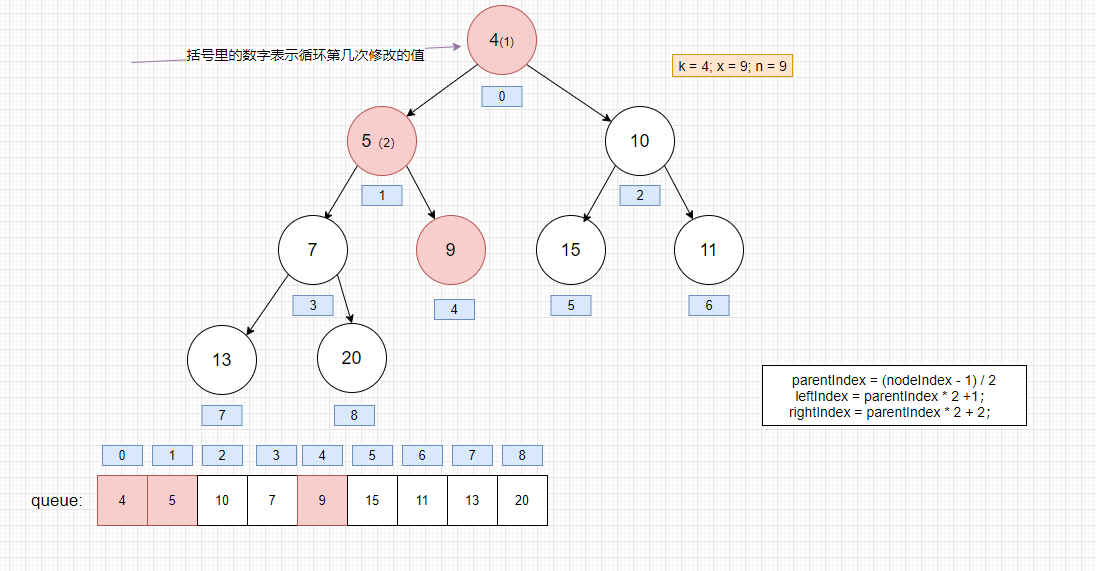
堆获取头结点后的思路: 将最后一个节点保存起来并置空,将它插入到第一个节点,若不满足就执行下面的流程.
- 比较第一个节点的左右节点是否小于该节点,是的话,就交换左右节点的最小的一个值的位置,周而复始。直到满足最小堆的性质为止
3. 总结
- PriorityBlockingQueue入队后的元素的顺序是按照元素的自然顺序(Comparator为null时)进行维护的。
- 使用ReetrantLock单锁,保证线程的安全性;在扩容时,通过CAS来保证只有一个线程可以成功扩容,同时扩容时,还可以进行出队操作
- 顺序通过二叉堆维护的,默认是最小堆
4. 参考
- 深入理解Java PriorityQueue -- 对堆的算法讲的很细致
JAVA并发(7)-并发队列PriorityBlockingQueue的源码分析的更多相关文章
- java并发包——阻塞队列BlockingQueue及源码分析
一.摘要 BlockingQueue通常用于一个线程在生产对象,而另外一个线程在消费这些对象的场景,例如在线程池中,当运行的线程数目大于核心的线程数目时候,经常就会把新来的线程对象放到Blocking ...
- Java的三种代理模式&完整源码分析
Java的三种代理模式&完整源码分析 参考资料: 博客园-Java的三种代理模式 简书-JDK动态代理-超详细源码分析 [博客园-WeakCache缓存的实现机制](https://www.c ...
- java 日志体系(四)log4j 源码分析
java 日志体系(四)log4j 源码分析 logback.log4j2.jul 都是在 log4j 的基础上扩展的,其实现的逻辑都差不多,下面以 log4j 为例剖析一下日志框架的基本组件. 一. ...
- java中的==、equals()、hashCode()源码分析(转载)
在java编程或者面试中经常会遇到 == .equals()的比较.自己看了看源码,结合实际的编程总结一下. 1. == java中的==是比较两个对象在JVM中的地址.比较好理解.看下面的代码: ...
- 延迟队列DelayQueue take() 源码分析
延迟队列DelayQueue take() 源码分析 在工作中使用了延迟队列,对其内部的实现很好奇,于是就研究了一下其运行原理,在这里就介绍一下take()方法的源码 1 take()源码 如下所示 ...
- Java SPI机制实战详解及源码分析
背景介绍 提起SPI机制,可能很多人不太熟悉,它是由JDK直接提供的,全称为:Service Provider Interface.而在平时的使用过程中也很少遇到,但如果你阅读一些框架的源码时,会发现 ...
- 【Java并发编程】16、ReentrantReadWriteLock源码分析
一.前言 在分析了锁框架的其他类之后,下面进入锁框架中最后一个类ReentrantReadWriteLock的分析,它表示可重入读写锁,ReentrantReadWriteLock中包含了两种锁,读锁 ...
- 并发编程(四)—— ThreadLocal源码分析及内存泄露预防
今天我们一起探讨下ThreadLocal的实现原理和源码分析.首先,本文先谈一下对ThreadLocal的理解,然后根据ThreadLocal类的源码分析了其实现原理和使用需要注意的地方,最后给出了两 ...
- HashMap在JDK1.8中并发操作,代码测试以及源码分析
HashMap在JDK1.8中并发操作不会出现死循环,只会出现缺数据.测试如下: package JDKSource; import java.util.HashMap; import java.ut ...
随机推荐
- POJ1149 PIGS(最大流)
题意: 有一个人,他有m个猪圈,每个猪圈里面有一定数量的猪,但是每个猪圈的门都是锁着的,他自己没有钥匙,只有顾客有钥匙,一天依次来了n个顾客,(记住是依次来的)他们每个人都有一些钥匙,和他 ...
- Mybatis 遍历 List<Map<String,Object>>
在上一篇博客中总结了MyBatis Plus 实现多表分页模糊查询(链接在最后).返回类型是编写一个专门的vo类.这次是返回List < Map > 前言 编写一个专门的vo返回类,主 ...
- @ResponseBody、@RequestBody
@ResponseBody 我们在刚刚接触Springboot的第一个hello工程的时候,我们就接触了一个RestController,而通过进入它的源码,我们会发现@ResponseBody @R ...
- 【maven】Failed to execute goal org.apache.maven.plugins:maven-site-plugin:3.3:site (default-site)
问题描述 site一点击就报错,如下 Failed to execute goal org.apache.maven.plugins:maven-site-plugin:3.3:site (defau ...
- 【Matlab】BFSK的调制与解调仿真
写在前面 本篇是[Matlab]BASK的调制与解调仿真的下篇,考虑到阅读体验,故另开一篇分享将BFSK的调制与解调仿真. 索引 写在前面 一.BFSK的调制 1.1 异频载波生成 1.2 信号合并 ...
- 拿到列表的长度len(列表名)
拿到列表的长度len(列表名),即元素个数 列表要放在括号里面
- Qt事件与常用事件处理、过滤
转载: https://blog.csdn.net/apollon_krj/article/category/6939539 https://blog.csdn.net/qq_41072190/art ...
- linux操作系统故障处理-ext4文件系统超级块损坏修复
linux操作系统故障处理-ext4文件系统超级块损坏修复 背景 前天外面出差大数据测试环境平台有7台服务器挂了,同事重启好了五台服务器,但是还有两台服务器启动不起来,第二天回来后我和同事再次去机 ...
- && echo suss! || echo failed
### && echo suss! || echo failed 加在bash后 ########ls /proc && echo suss! || echo fail ...
- 【IBM】netperf 与网络性能测量
netperf 与网络性能测量 汤凯2004 年 7 月 01 日发布 WeiboGoogle+用电子邮件发送本页面 2 在构建或管理一个网络系统时,我们更多的是关心网络的可用性,即网络是否连通,而对 ...