Redis 内存优化在 vivo 的探索与实践
作者:vivo 互联网服务器团队- Tang Wenjian
一、 背景
使用过 Redis 的同学应该都知道,它基于键值对(key-value)的内存数据库,所有数据存放在内存中,内存在 Redis 中扮演一个核心角色,所有的操作都是围绕它进行。
我们在实际维护过程中经常会被问到如下问题,比如数据怎么存储在 Redis 里面能节约成本、提升性能?Redis内存告警是什么原因导致?
本文主要是通过分析 Redis内存结构、介绍内存优化手段,同时结合生产案例,帮助大家在优化内存使用,快速定位 Redis 相关内存异常问题。
二、 Redis 内存管理
本章详细介绍 Redis 是怎么管理各内存结构的,然后主要介绍几个占用内存可能比较多的内存结构。首先我们看下Redis 的内存模型。
内存模型如图:
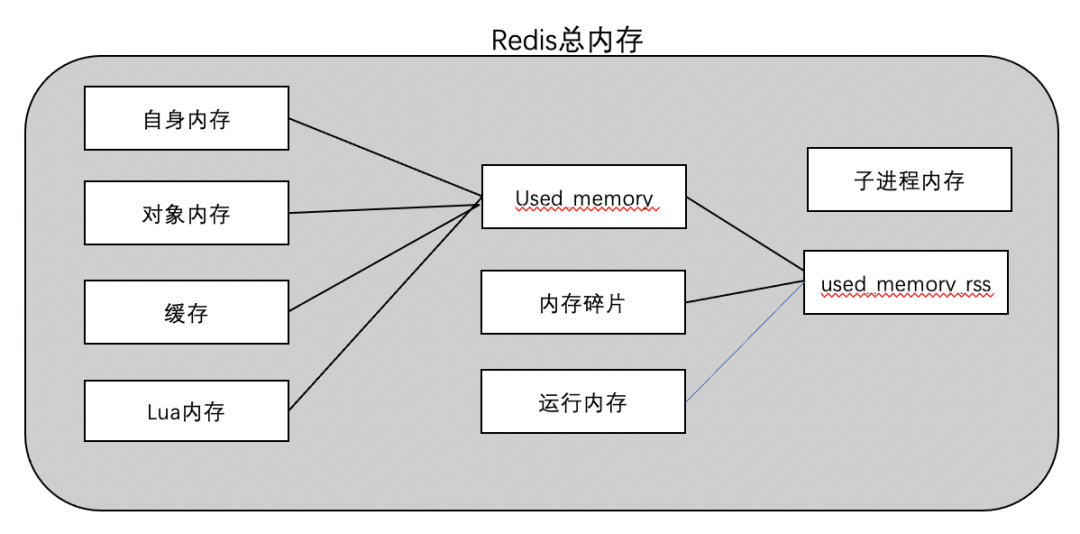
【used_memory】:Redis内存占用中最主要的部分,Redis分配器分配的内存总量(单位是KB)(在编译时指定编译器,默认是jemalloc),主要包含自身内存(字典、元数据)、对象内存、缓存,lua内存。
【自身内存】:自身维护的一些数据字典及元数据,一般占用内存很低。
【对象内存】:所有对象都是Key-Value型,Key对象都是字符串,Value对象则包括5种类(String,List,Hash,Set,Zset),5.0还支持stream类型。
【缓存】:客户端缓冲区(普通 + 主从复制 + pubsub)以及aof缓冲区。
【Lua内存】:主要是存储加载的 Lua 脚本,内存使用量和加载的 Lua 脚本数量有关。
【used_memory_rss】:Redis 主进程占据操作系统的内存(单位是KB),是从操作系统角度得到的值,如top、ps等命令。
【内存碎片】:如果对数据的更改频繁,可能导致redis释放的空间在物理内存中并没有释放,但redis又无法有效利用,这就形成了内存碎片。
【运行内存】:运行时消耗的内存,一般占用内存较低,在10M内。
【子进程内存】:主要是在持久化的时候,aof rewrite或者rdb产生的子进程消耗的内存,一般也是比较小。
2.1 对象内存
对象内存存储 Redis 所有的key-value型数据类型,key对象都是 string 类型,value对象主要有五种数据类型String、List、Hash、Set、Zset,不同类型的对象通过对应的编码各种封装,对外定义为RedisObject结构体,RedisObject都是由字典(Dict)保存的,而字典底层是通过哈希表来实现的。通过哈希表中的节点保存字典中的键值对,结构如下:
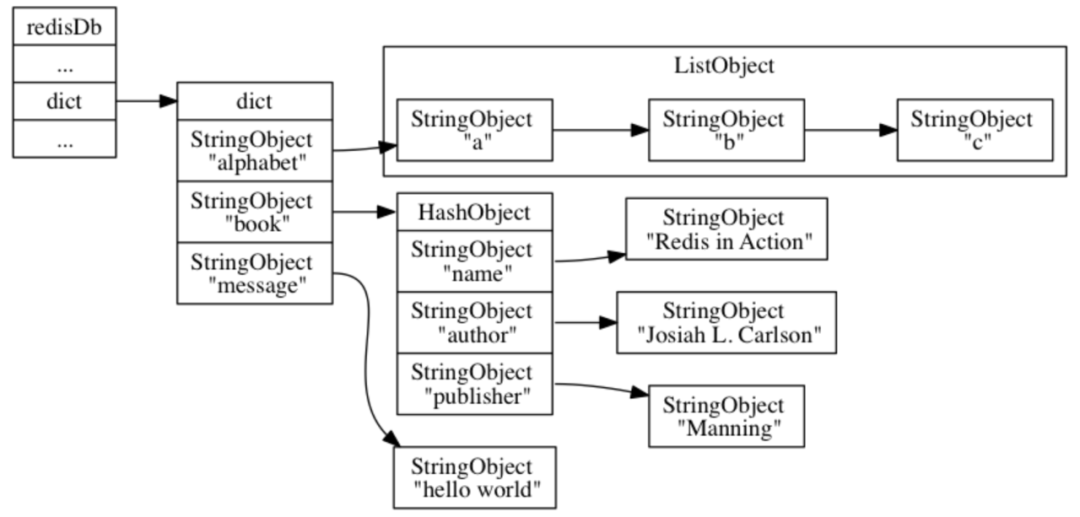
(来源:书籍《Redis设计与实现》)
为了达到极大的提高 Redis 的灵活性和效率,Redis 根据不同的使用场景来对一个对象设置不同的编码,从而优化某一场景下的效率。
各类对象选择编码的规则如下:
string (字符串)
【int】:(整数且数字长度小于20,直接记录在ptr*里面)
【embstr】: (连续分配的内存(字符串长度小于等于44字节的字符串))
【raw】: 动态字符串(大于44个字节的字符串,同时字符长度小于 512M(512M是字符串的大小限制))
list (列表)
【ziplist】:(元素个数小于hash-max-ziplist-entries配置(默认512个),同时所有值都小于hash-max-ziplist-value配置(默认64个字节))
【linkedlist】:(当列表类型无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现)
【quicklist】:(Redis 3.2 版本引入了 quicklist 作为 list 的底层实现,不再使用 linkedlist 和 ziplist 实现)
set (集合)
【intset 】:(元素都是整数且元素个数小于set-max-intset-entries配置(默认512个))
【hashtable】:(集合类型无法满足intset的条件时就会使用hashtable)
hash (hash列表)
【ziplist】:(元素个数小于hash-max-ziplist-entries配置(默认512个),同时任意一个value的长度都小于hash-max-ziplist-value配置(默认64个字节))
【hashtable】:(hash类型无法满足intset的条件时就会使用hashtable
zset(有序集合)
【ziplist】:(元素个数小于zset-max-ziplist-entries配置(默认128个)同时每个元素的value小于zset-max-ziplist-value配置(默认64个字节))
【skiplist】:(当ziplist条件不满足时,有序集合会使用skiplist作为内部实现)
2.2 缓冲内存
2.2 1 客户端缓存
客户端缓冲指的是所有接入 Redis 服务的 TCP 连接的输入输出缓冲。有普通客户端缓冲、主从复制缓冲、订阅缓冲,这些都由对应的参数缓冲控制大小(输入缓冲无参数控制,最大空间为1G),若达到设定的最大值,客户端将断开。
【client-output-buffer-limit】: 限制客户端输出缓存的大小,后面接客户端种类(normal、slave、pubsub)及限制大小,默认是0,不做限制,如果做了限制,达到阈值之后,会断开链接,释放内存。
【repl-backlog-size】:默认是1M,backlog是一个主从复制的缓冲区,是一个环形buffer,假设达到设置的阈值,不存在溢出的问题,会循环覆盖,比如slave中断过程中同步数据没有被覆盖,执行增量同步就可以。backlog设置的越大,slave可以失连的时间就越长,受参数maxmemory限制,正常不要设置太大。
2.2 2 AOF 缓冲
当我们开启了 AOF 的时候,先将客户端传来的命令存放在AOF缓冲区,再去根据具体的策略(always、everysec、no)去写入磁盘中的 AOF 文件中,同时记录刷盘时间。
AOF 缓冲没法限制,也不需要限制,因为主线程每次进行 AOF会对比上次刷盘成功的时间;如果超过2s,则主线程阻塞直到fsync同步完成,主线程被阻塞的时候,aof_delayed_fsync状态变量记录会增加。因此 AOF 缓存只会存几秒时间的数据,消耗内存比较小。
2.3 内存碎片
程序出现内存碎片是个很常见的问题,Redis的默认分配器是jemalloc ,它的策略是按照一系列固定的大小划分内存空间,例如 8 字节、16 字节、32 字节、…, 4KB、8KB 等。当程序申请的内存最接近某个固定值时,jemalloc 会给它分配比它大一点的固定大小的空间,所以会产生一些碎片,另外在删除数据的时候,释放的内存不会立刻返回给操作系统,但redis自己又无法有效利用,就形成碎片。
内存碎片不会被统计在used_memory中,内存碎片比率在redis info里面记录了一个动态值mem_fragmentation_ratio,该值是used_memory_rss / used_memory的比值,mem_fragmentation_ratio越接近1,碎片率越低,正常值在1~1.5内,超过了说明碎片很多。
2.4 子进程内存
前面提到子进程主要是为了生成 RDB 和 AOF rewrite产生的子进程,也会占用一定的内存,但是在这个过程中写操作不频繁的情况下内存占用较少,写操作很频繁会导致占用内存较多。
三、Redis 内存优化
内存优化的对象主要是对象内存、客户端缓冲、内存碎片、子进程内存等几个方面,因为这几个内存消耗比较大或者有的时候不稳定,我们优化内存的方向分为如:减少内存使用、提高性能、减少内存异常发生。
3.1 对象内存优化
对象内存的优化可以降低内存使用率,提高性能,优化点主要针对不同对象不同编码的选择上做优化。
在优化前,我们可以了解下如下的一些知识点:
(1)首先是字符串类型的3种编码,int编码除了自身object无需分配内存,object 的指针不需要指向其他内存空间,无论是从性能还是内存使用都是最优的,embstr是会分配一块连续的内存空间,但是假设这个value有任何变化,那么value对象会变成raw编码,而且是不可逆的。
(2)ziplist 存储 list 时每个元素会作为一个 entry; 存储 hash 时 key 和 value 会作为相邻的两个 entry; 存储 zset 时 member 和 score 会作为相邻的两个entry,当不满足上述条件时,ziplist 会升级为 linkedlist, hashtable 或 skiplist 编码。
(3)在任何情况下大内存的编码都不会降级为 ziplist。
(4)linkedlist 、hashtable 便于进行增删改操作但是内存占用较大。
(5)ziplist 内存占用较少,但是因为每次修改都可能触发 realloc 和 memcopy, 可能导致连锁更新(数据可能需要挪动)。因此修改操作的效率较低,在 ziplist 的条目很多时这个问题更加突出。
(6)由于目前大部分redis运行的版本都是在3.2以上,所以 List 类型的编码都是quicklist,它是 ziplist 组成的双向链表linkedlist ,它的每个节点都是一个ziplist,考虑了综合平衡空间碎片和读写性能两个维度所以使用了个新编码quicklist,quicklist有个比较重要的参数list-max-ziplist-size,当它取正数的时候,正数表示限制每个节点ziplist中的entry数量,如果是负数则只能为-1-5,限制ziplist大小,从-1-5的限制分别为4kb、8kb、16kb、32kb、64kb,默认是-2,也就是限制不超过8kb。
(7)【rehash】: redis存储底层很多是hashtable,客户端可以根据key计算的hash值找到对应的对象,但是当数据量越来越大的时候,可能就会存在多个key计算的hash值相同,这个时候这些相同的hash值就会以链表的形式存放,如果这个链表过大,那么遍历的时候性能就会下降,所以Redis定义了一个阈值(负载因子 loader_factor = 哈希表中键值对数量 / 哈希表长度),会触发渐进式的rehash,过程是新建一个更大的新hashtable,然后把数据逐步移动到新hashtable中。
(8)【bigkey】:bigkey一般指的是value的值占用内存空间很大,但是这个大小其实没有一个固定的标准,我们自己定义超过10M就可以称之为bigkey。
优化建议:
key尽量控制在44个字节数内,走embstr编码,embstr比raw编码减少一次内存分配,同时因为是连续内存存储,性能会更好。
多个string类型可以合并成小段hash类型去维护,小的hash类型走ziplist是有很好的压缩效果,节约内存。
非string的类型的value对象的元素个数尽量不要太多,避免产生大key。
在value的元素较多且频繁变动,不要使用ziplist编码,因为ziplist是连续的内存分配,对频繁更新的对象并不友好,性能损耗反而大。
hash类型对象包含的元素不要太多,避免在rehash的时候消耗过多内存。
尽量不要修改ziplist限制的参数值,因为ziplist编码虽然可以对内存有很好的压缩,但是如果元素太多使用ziplist的话,性能可能会有所下降。
3.2 客户端缓冲优化
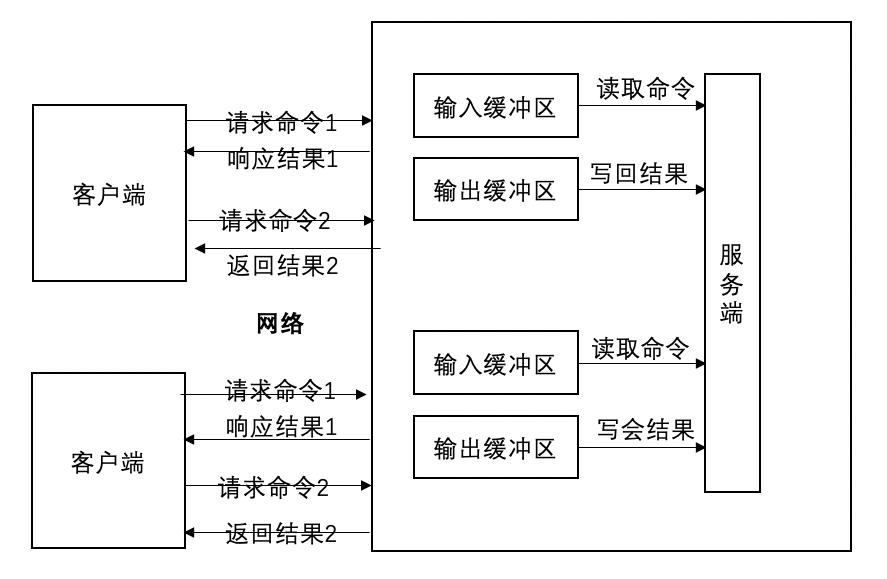
客户端缓存是很多内存异常增长的罪魁祸首,大部分都是普通客户端输出缓冲区异常增长导致,我们先了解下执行命令的过程,客户端发送一个或者通过piplie发送一组请求命令给服务端,然后等待服务端的响应,一般客户端使用阻塞模式来等待服务端响应,数据在被客户端读取前,数据是存放在客户端缓存区,命令执行的简易流程图如下:
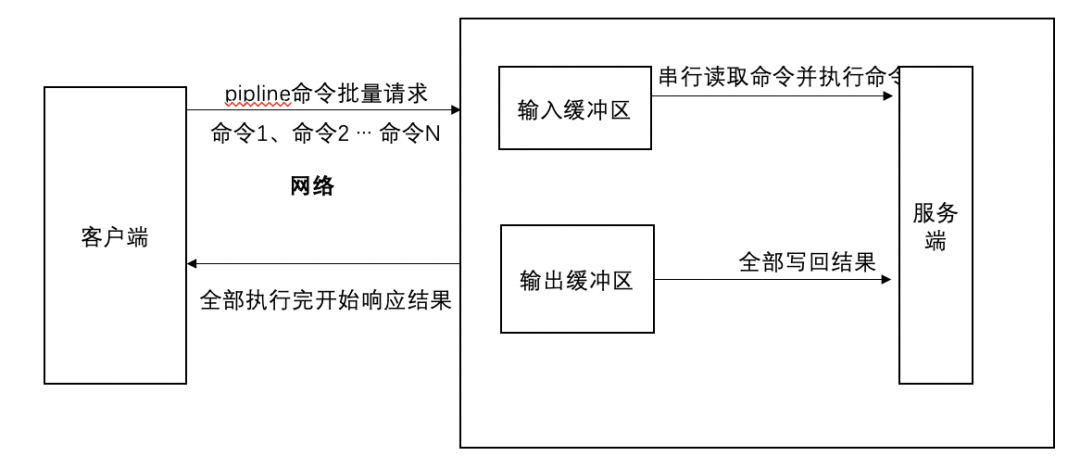
异常增长原因可能如下几种:
客户端访问大key 导致客户端输出缓存异常增长。
客户端使用monitor命令访问Redis,monitor命令会把所有访问redis的命令持续存放到输出缓冲区,导致输出缓冲区异常增长。
客户端为了加快访问效率,使用pipline封装了大量命令,导致返回的结果集异常大(pipline的特性是等所有命令全部执行完才返回,返回前都是暂存在输出缓存区)。
从节点应用数据较慢,导致输出主从复制输出缓存有很多数据积压,最后导致缓冲区异常增长。
异常表现:
在Redis的info命令返回的结果里面,client部分client_recent_max_output_buffer的值很大。
在执行client list命令返回的结果集里面,omem不为0且很大,omem代表该客户端的输出代表缓存使用的字节数。
在集群中,可能少部分used_memory在监控显示存在异常增长,因为不管是monitor或者pipeline都是针对单个实例的下发的命令。
优化建议:
应用不要设计大key,大key尽量拆分。
服务端的普通客户端输出缓存区通过参数设置,因为内存告警的阈值大部分是使用率80%开始,实际建议参数可以设置为实例内存的5%~15%左右,最好不要超过20%,避免OOM。
非特殊情况下避免使用monitor命令或者rename该命令。
在使用pipline的时候,pipeline不能封装过多的命令,特别是一些返回结果集较多的命令更应该少封装。
主从复制输出缓冲区大小设置参考: 缓冲区大小=(主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小)* 2。
3.3 碎片优化
碎片优化可以降低内存使用率,提高访问效率,在4.0以下版本,我们只能使用重启恢复,重启加载rdb或者重启通过高可用主从切换实现数据的重新加载可以减少碎片,在4.0以上版本,Redis提供了自动和手动的碎片整理功能,原理大致是把数据拷贝到新的内存空间,然后把老的空间释放掉,这个是有一定的性能损耗的。
【a. redis手动整理碎片】:执行memory purge命令即可。
【b.redis自动整理碎片】:通过如下几个参数控制
【activedefrag yes 】:启用自动碎片清理开关
【active-defrag-ignore-bytes 100mb】:内存碎片空间达到多少才开启碎片整理
【active-defrag-threshold-lower 10】:碎片率达到百分之多少才开启碎片整理
【active-defrag-threshold-upper 100 】:内存碎片率超过多少,则尽最大努力整理(占用最大资源去做碎片整理)
【active-defrag-cycle-min 25 】:内存自动整理占用资源最小百分比
【active-defrag-cycle-max 75】:内存自动整理占用资源最大百分比
3.4 子进程内存优化
前面谈到 AOF rewrite和 RDB 生成动作会产生子进程,正常在两个动作执行的过程中,Redis 写操作没有那么频繁的情况下fork出来的子进程是不会消耗很多内存的,这个主要是因为 Redis 子进程使用了 Linux 的 copy on write 机制,简称COW。
COW的核心是在fork出子进程后,与父进程共享内存空间,只有在父进程发生写操作修改内存数据时,才会真正去分配内存空间,并复制内存数据。
但是有一点需要注意,不要开启操作系统的大页THP(Transparent Huge Pages),开启 THP 机制后,本来页的大小由4KB变为 2MB了。它虽然可以加快 fork 完成的速度( 因为要拷贝的页的数量减少 ),但是会导致 copy-on-write 复制内存页的单位从 4KB 增大为 2MB,如果父进程有大量写命令,会加重内存拷贝量,从而造成过度内存消耗。
四、内存优化案例
4.1 缓冲区异常优化案例
线上业务 Redis 集群出现内存告警,内存使用率增长很快达到100%,值班人员先进行了紧急扩容,同时反馈至业务群是否有大量新数据写入,业务反馈并无大量新数据写入,且同时扩容后的内存还在涨,很快又要触发告警了,业务 DBA 去查监控看看具体原因。
首先我们看used_memory增长只是集群的少数几个实例,同时内存异常的实例的key的数量并没有异常增长,说明没有写入大批量数据导致。
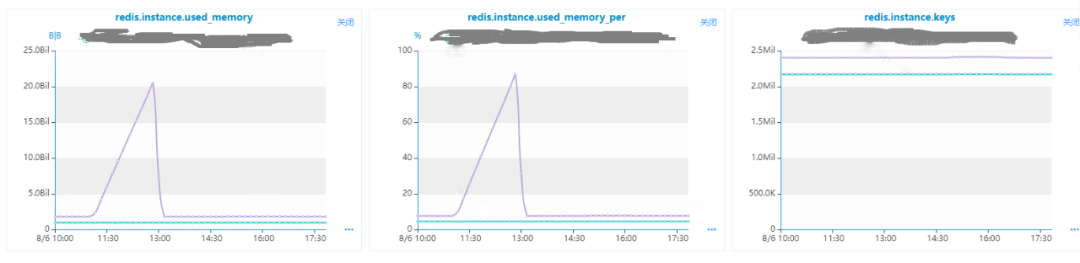
我们再往下分析,可能是客户端的内存占用异常比较大,查看实例 info 里面的客户端相关指标,观察发现output_list的增长曲线和used_memory一致,可以判定是客户端的输出缓冲异常导致。
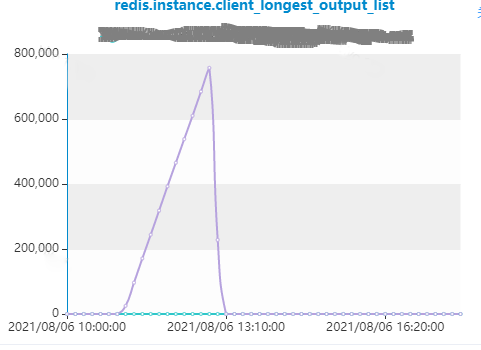
接下来我们再去通过client list查看是什么客户端导致output增长,客户端在执行什么命令,同时去分析是否访问大key。
执行 client list |grep -i omem=0 发现如下:
id=12593807 addr=192.168.101.1:52086 fd=10767 name= age=15301 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=16173 oll=341101 omem=5259227504 events=rw cmd=get
说明下相关的几个重点的字段的含义:
【id】:就是客户端的唯一标识,经常用于我们kill客户端用到id;
【addr】:客户端信息;
【obl】:固定缓冲区大小(字节),默认是16K;
【oll】:动态缓冲区大小(对象个数),客户端如果每条命令的响应结果超过16k或者固定缓冲区写满了会写动态缓冲区;
【omem】: 指缓冲区的总字节数;
【cmd】: 最近一次的操作命令。
可以看到缓冲区内存占用很大,最近的操作命令也是get,所以我们先看看是否大key导致(我们是直接分析RDB发现并没有大key),但是发现并没有大key,而且get对应的肯定是string类型,string类型的value最大是512M,所以单个key也不太可能产生这么大的缓存,所以断定是客户端缓存了多个key。
这个时候为了尽快恢复,和业务沟通临时kill该连接,内存释放,然后为了避免防止后面还产生异常,和业务方沟通设置普通客户端缓存限制,因为最大内存是25G,我们把缓存设置了2G-4G, 动态设置参数如下:
config set client-output-buffer-limit normal 4096mb 2048mb 120
因为参数限制也只是针对单个client的输出缓冲这么大,所以还需要检查客户端使用使用 pipline 这种管道命令或者类似实现了封装大批量命令导致结果统一返回之前被阻塞,后面确定确实会有这个操作,业务层就需要去逐步优化,不然我们限制了输出缓冲,达到了上限,会话会被kill, 所以业务不改的话还是会有抛错。
业务方反馈用的是 C++ 语言 brpc 自带的 Redis客户端,第一次直接搜索没有pipline的关键字,但是现象又指向使用的管道,所以继续仔细看了下代码,发现其内部是实现了pipline类似的功能,也是会对多个命令进行封装去请求redis,然后统一返回结果,客户端GitHub链接如下:
https://github.com/apache/incubator-brpc/blob/master/docs/cn/redis_client.md
总结:
pipline 在 Redis 客户端中使用的挺多的,因为确实可以提供访问效率,但是使用不当反而会影响访问,应该控制好访问,生产环境也尽量加这些内存限制,避免部分客户端的异常访问影响全局使用。
4.2 从节点内存异常增长案例
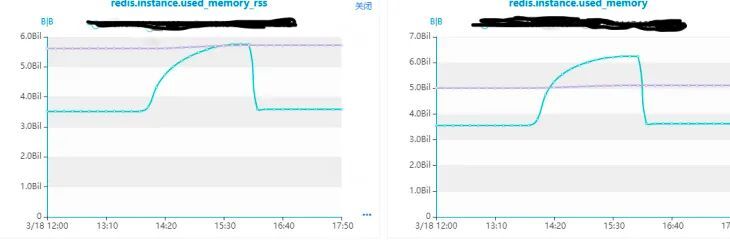
线上 Redis 集群出现内存使用率超过 95% 的灾难告警,但是该集群是有190个节点的集群触发异常内存告警的只有3个节点。所以查看集群对应信息以及监控指标发现如下有用信息:
3个从节点对应的主节点内存没有变化,从节点的内存是逐步增长的。
发现集群整体ops比较低,说明业务变化并不大,没有发现有效命令突增。
主从节点的最大内存不一致,主节点是6G,从节点是5G,这个是导致灾难告警的重要原因。
在出问题前,主节点比从节点的内存大概多出1.3G,后面从节点used_memory逐步增长到超过主节点内存,但是rss内存是最后保持了一样。
主从复制出现延迟也内存增长的那个时间段。
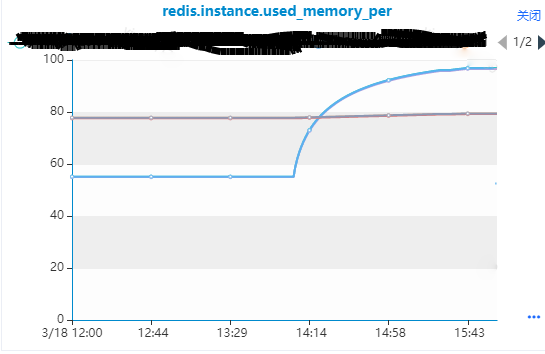
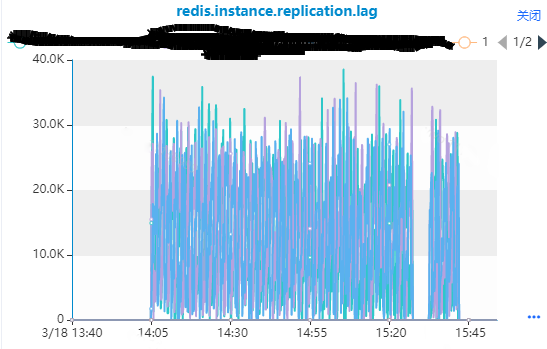
处理过程:
首先想到的应该是保持主从节点最大内存一致,但是因为主机内存使用率比较高暂时没法扩容,因为想到的是从节点可能什么原因阻塞,所以和业务方沟通是重启下2从节点缓解下,重启后从节点内存释放,降到发生问题前的水平,如上图,后面主机空出了内存资源,所以优先把内存调整一致。
内存调整好了一周后,这3个从节点内存又告警了,因为现在主从内存是一致的,所以触发的是严重告警(>85%),查看监控发现情况是和之前一样,猜测这个是某些操作触发的,所以还是决定问问业务方这 两个时间段都有哪些操作,业务反馈这段时间就是在写业务,那2个时间段都是在写入,也看了写redis的那段代码,用了一个比较少见的命令append,append是对string类型的value进行追加。
这里就得提下string类型在 Redis 里面是怎么分配内存的:string类型都是都是sds存储,当前分配的sds内存空间不足存储且小于1M时候,Redis会重新分配一个2倍之前内存大小的内存空间。
根据上面到知识点,所以可以大致可以解析上述一系列的问题,大概是当时做 append 操作,从节点需要分配空间从而发生内存膨胀,而主节点不需要分配空间,因为内存重新分配设计malloc和free操作,所以当时有lag也是正常的。
Redis的主从本身是一个逻辑复制,加载 RDB 的过程其实也是拿到kv不断的写入到从节点,所以主从到内存大小也经常存在不相同的情况,特别是这种values大小经常改变的场景,主从存储的kv所用的空间很多可能是不一样的。
为了证明这一猜测,我们可以通过获取一个key(value大小要比较大)在主从节点占用空间的大小,因为是4.0以上版本,所以我们可以使用memory USAGE 去获取大小,看看差异有多少,我们随机找了几个稍微大点的key去查看,发现在有些key从库占用空间是主库的近2倍,有的差不多,有的也是1倍多,rdb解析出来的这个key空间更小,说明从节点重启后加载rdb进行存放是最小的,然后因为某段时间大批量key操作,导致从节点的大批量的key分配的空间不足,需要扩容1倍空间,导致内存出现增长。
到这就分析的其实差不多了,因为append的特性,为了避免内存再次出现内存告警,决定把该集群的内存进行扩容,控制内存使用率在70%以下(避免可能发生的大量key使用内存翻倍的情况)。
最后还有1个问题:上面的used_memory为什么会比memory_rss的值还大呢?(swap是关闭的)。
这是因为jemalloc内存分配一开始其实分配的是虚拟内存,只有往分配的page页里面写数据的时候才会真正分配内存,memory_rss是实际内存占用,used_memory其实是一个计数器,在 Redis做内存的malloc/free的时候,对这个used_memory做加减法。
关于used_memory大于memory_rss的问题,redis作者也做了回答:
https://github.com/redis/redis/issues/946#issuecomment-13599772
总结:
在知晓 Redis内存分配原理的情况下,数据库的内存异常问题进行分析会比较快速定位,另外可能某个问题看起来和业务没什么关联,但是我们还是应该多和业务方沟通获取一些线索排查问题,最后主从内存一定按照规范保持一致。
五、总结
Redis在数据存储、缓存都是做了很巧妙的设计和优化,我们在了解了它的内部结构、存储方式之后,我们可以提前在key的设计上做优化。我们在遇到内存异常或者性能优化的时候,可以不再局限于表面的一些分析如:资源消耗、命令的复杂度、key的大小,还可以结合根据Redis的一些内部运行机制和内存管理方式去深入发现是否还有可能哪些方面导致异常或者性能下降。
参考资料
- 书籍《Redis设计与实现》
Redis 内存优化在 vivo 的探索与实践的更多相关文章
- 如何用分布式缓存服务实现Redis内存优化
Redis是一种支持Key-Value等多种数据结构的存储系统,其数据特性是“ALL IN MEMORY”,因此优化内存十分重要.在对Redis进行内存优化时,先要掌握Redis内存存储的特性比如字符 ...
- Redis内存优化memory-optimization
https://redis.io/topics/memory-optimization 官方文档 一.特殊编码: 自从Redis 2.2之后,很多数据类型都可以通过特殊编码的方式来进行存储空间的优化 ...
- redis内存优化方法
先来认识2个redis配置参数 hash-max-ziplist-entries : hash内部编码压缩列表的最大值,默认512 hash-max-zipmap-value : hash内部编码压缩 ...
- redis的内存优化【转】
Redis所有的数据都在内存中,而内存又是非常宝贵的资源.对于如何优化内存使用一直是Redis用户非常关注的问题.本文让我们深入到Redis细节中,学习内存优化的技巧.分为如下几个部分: 一.redi ...
- Redis系列--内存淘汰机制(含单机版内存优化建议)
https://blog.csdn.net/Jack__Frost/article/details/72478400?locationNum=13&fps=1 每台redis的服务器的内存都是 ...
- Redis之内存优化
Redis所有的数据都存在内存中,当前内存虽然越来越便宜,但跟廉价的硬盘相比成本还是比较昂贵,因此如何高效利用Redis内存变得非常重要.高效利用Redis内存首先需要理解Redis内存消耗在哪里,如 ...
- Redis内存使用优化与存储
抄自http://www.infoq.com/cn/articles/tq-redis-memory-usage-optimization-storage 本文将对Redis的常见数据类型的使用场景以 ...
- Redis内存使用优化与存储(转)
Redis常用数据类型 Redis最为常用的数据类型主要有以下五种: String Hash List Set Sorted set 在具体描述这几种数据类型之前,我们先通过一张图了解下Redis内部 ...
- Redis 内存使用优化与存储
Redis 常用数据类型 Redis 最为常用的数据类型主要有以下五种: • String • Hash • List • Set • Sorted set 在具体描述这几种数据类型之前,我们先通过一 ...
- Redis学习-内存优化
以下为个人学习Redis的备忘录--内存优化 1.随时查看info memory,了解内存使用状况:127.0.0.1:6379> info memory# Memoryused_memory: ...
随机推荐
- 湖南省网络攻防邀请赛 RE 题解
ez_apkk 解题过程: 将apk拖入jadx,查看MainActivity,发现是简单RC4加密,密钥是"55667788",最后再将加密结果+1 public String ...
- mac电脑升级后wifi报感叹号连不上WiFi的问题
我的mac电脑是2015款的makebook pro,13英寸,之前一直用的是10.14系统,后来看到系统更新一直在推10.15系统,我就升级了10.15系统,但是升级后就坑爹了,wifi标志直接就不 ...
- [scrapy]一个简单的scrapy爬虫demo
一个简单的scrapy爬虫demo 爬取豆瓣top250的电影名称+电影口号 使用到持久化流程: 爬虫文件爬取到数据后,需要将数据封装到items对象中. 使用yield关键字将items对象提交给p ...
- [ABC246A] Four Points
Problem Statement There is a rectangle in the $xy$-plane. Each edge of this rectangle is parallel to ...
- ubuntu 20.04安装mysql5.7
ubuntu 22.04系统安装mysql5.7 一.查看系统默认安装的数据库版本 apt-get update apt-cache policy mysql-server ubuntu 20.04自 ...
- CH395实现主动ping对端功能(代码及说明)
目录 1.PING原理 1.1简介 1.2协议 1.3通信流程 2.代码解释 3.工程链接 PING原理 1.简介 PING是基于ICMP(Internet Control Message Proto ...
- AVL树和红黑树的Python代码实现
AVL树 AVL树是一种自平衡二叉搜索树.在这种树中,任何节点的两个子树的高度差被严格控制在1以内.这确保了树的平衡,从而保证了搜索.插入和删除操作的高效性.AVL树是由Georgy Adelson- ...
- 华企盾DSC控制台升级提示不能连接服务器
由于服务器Apache没有启动导致无法升级,查看版本说明看看是否是版本问题,尝试手动启动Apache服务
- Python 中 key 参数的含义及用法
哈喽大家好,我是咸鱼 我们在使用 sorted() 或 map() 函数的时候,都会看到里面有一个 key 参数 其实这个 key 参数也存在于其他内置函数中(例如 min().max() 等),那么 ...
- python tkinter使用(五)
python tkinter使用(五) 本篇文章讲述tkinter 中treeview的使用 Treeview是一个多列列表框,可以显示层次数据. #!/usr/bin/python3 # -*- c ...