浅谈sql执行流程、innodb架构设计、buffer pool缓冲池
一.从服务端到数据库sql执行流程:
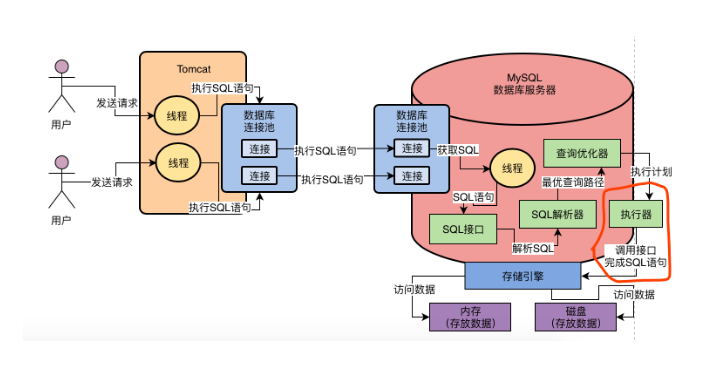
- 1.
SQL接口:负责处理接收到sql的语句 - 2.查询解析器:负责将
sql变成数据库可以看懂的语言 - 3.查询优化器:选择最优的查询路径(针对你编写的复杂
sql语句生成查询路径树,然后从中选择一条最优的查询路径) - 4.执行器:根据执行计划调用存储引擎接口(执行器会根据我们的优化器生成一套执行计划,然后不停的调用存储引擎的各种接口去完成
sql语句的执行计划)。 - 5.存储引擎:存储引擎具体去执行
sql语句计划。(他会按照一定的步骤去查询内存缓存数据,更新磁盘数据,查询磁盘数据等)
二.通过一个简单的更新语句,初步了解Innodb存储引擎架构设计
update user set name = 'xxx' where id = 1
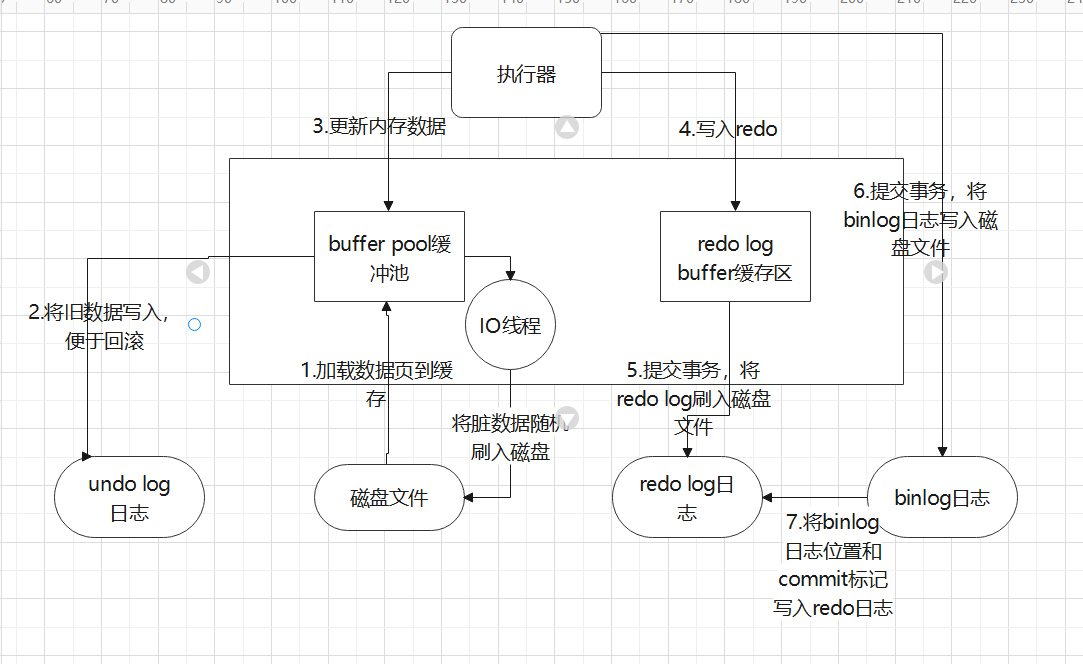
更新流程:
- 1.当我们用
Innodb存储引擎更新语句的时候,他首先会看一下buffer pool里面有没有这条数据,没有这条数据,他会首先从磁盘读取,将这条数据加载到buffer pool,并且为这条数据加上写锁; - 2.紧接着将更新前的值写入
undo日志文件中,用于数据的回滚; - 3.然后修改内存数据(因为此时内存数据和磁盘数据不一致,所以内存数据也叫脏数据);
- 4.将更新后的数据信息写入
redo log buffer缓存区; - 5.提交事务的时候,将
redo log(记录物理日志,记录了对哪个数据页的什么记录,做了什么修改)刷入磁盘文件; - 6.在提交事务的时候,也会将
binlog(逻辑日志,记录了一个对哪个表的那条记录,做了什么修改)写入磁盘文件; - 7.最后,把本次更新对应的
binlog文件名称和这次更新的binlog日志在文件里的位置,以及commit标记写入redo log日志。
- 1.当我们用
1.
undo log日志:用于数据的回滚。把更新前的值,写入undo日志文件中。2.
buffer pool: 内存缓存区。是innodb存储引擎的一个重要组件,这里面会缓存很多数据,以便于以后在查询的时候,内存缓冲池里有数据,就不用再去查磁盘了。3.
redo log buffer: 内存缓存区(用来存放redo日志)4.
redo log日志:提交事务的时候,将redo日志写入磁盘中。(mysql宕机时,数据还没来得及刷入磁盘,重启数据库时,redo log去恢复之前做过的修改,恢复buffer pool池数据)5.
binlog日志:提交事务的时候,会把更新对应的binlog日志写入磁盘文件中。(mysql宕机时,用来恢复磁盘数据;主从复制:主节点开启binlog,从节点接收binlog到relay log,读取内容,生成sql语句执行)redo log日志redo log buffer刷入磁盘文件的策略(innodb_flush_log_at_trx_commit):1.参数设置为
0时,提交事务的时候,不会把redo log buffer里的数据刷入磁盘,数据库突然宕机了,buffer pool缓冲区的数据就丢失。2.参数设置为
1时,提交事务的时候,就必须把redo log buffer里面的数据刷入磁盘文件,事务提交成功了,也就是redo log一定在磁盘中。3.参数设置为
2时,提交事务的时候,不会将内存中的redo日志刷新到磁盘,而是会刷新到操作系统的缓存中,然后可能1s后再刷新到磁盘中。
binlog日志的刷盘策略(sync_binlog):1.为0时(默认值),
binlog不直接进入磁盘文件,而是进入操作系统缓存,由操作系统判断将binlog刷入磁盘的时机。2.设置为1时,提交事务时,
binlog直接写入到磁盘文件中。
redo log和binlog区别:1.
redo log是Innodb存储引擎特有的一个东西;binlog是mysql自己的日志文件。2.
redo log是偏向物理性质的重做日志,“他记录的是对哪个数据页的什么记录,做了什么修改”;binlog是偏向于逻辑性的日志,“他记录的是对哪个表的哪一行做了更新操作,更新以后的值是什么”。
三.Buffer Pool缓冲池:
mysql的数据模型就是表+行+字段的概念,实际上mysql对数据抽象出来一个数据页的概念,他把多行数据放在一个数据页中,也就是说我们的磁盘文件中又很多数据页,每个数据页中放了很多数据。我们实际上更新一条数据的时候,此时数据库会找到这行数据所在的数据页,然后从磁盘文件里把这行数据所在的数据页直接加载到buffer pool缓冲池中。也就是讲buffer pool缓冲池中,放的是一个一个的数据页,数据页加载到缓冲池之后,在缓冲池中叫缓存页。- 1.数据页:数据页默认大小是
16KB。 - 2.缓存页:和数据页的大小是一一对应的,也是
16KB。 - 3.描述数据:每个缓存页都有一个描述数据,记录了这个数据页所属的表空间、数据页号、缓存页在
buffer pool中的地址等信息;描述数据本来也是一块数据;每个描述数据占缓存页大小的5%(800字节)左右;buffer pool(默认128M)实际的大小,会比设置的稍大一下;
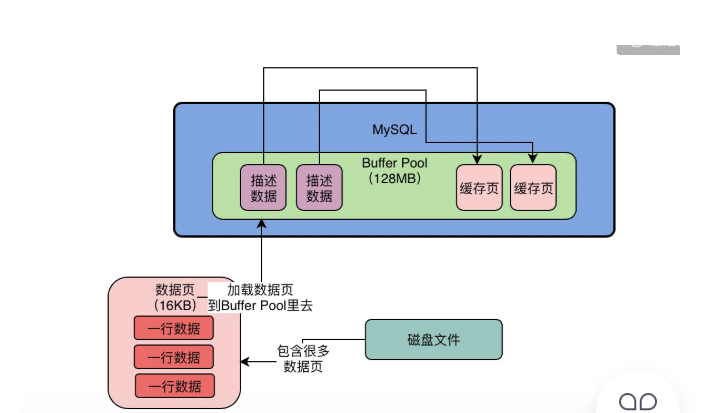
4.当你的数据库启动以后,就会按照你设置的
buffer pool的大小,再稍微加大一点,去操作系统申请一块内存区域,作为buffer pool的内存区域;申请完毕,数据库就会按照默认的缓存页16KB的大小以及对应的800个字节左右的描述数据的大小,在buffer pool中划分一个个缓存页和对应的描述数据。在我们不停的执行增删改的操作的时候,此时就需要不停的从磁盘上对一个个数据页放入buffer pool中对应的缓存页中,把数据缓存起来,应对之后的增删改查;问题:那些缓存页是空闲的?
解决:数据库为buffer pool设计了一个free链表。5.
free链表:由描述数据块地址组成的双向链表(每个节点就是一个空闲缓存页的描述数据的地址);除此之外,free链表还有一个基础节点,是一个40字节大小的节点,里面存放了free链表的头节点地址和尾节点地址,以及当前链表中有多少个节点;
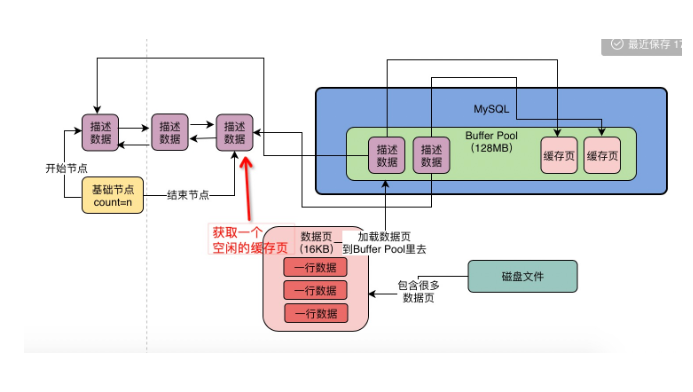
问题:怎么知道那些数据页是已经被缓存过的?
解决:数据库有一个哈希表的数据结构,他会用表空间号+数据页号作为key,缓存页地址作为value;当你要使用一个数据页的时候,通过这个key去哈希表里查一下,如果有value,就说明数据页已经被缓存了。
问题:更新过的数据页叫脏页,这些更新过的脏页数据,最终是要被刷回磁盘文件的;不可能所有的缓存页都刷回磁盘的,因为有些缓存页仅仅是因为查询才被读到buffer pool池的,根本没有修改过,全部刷回,对性能影响很大,如果频繁使用的缓存页,这次刷回,下次还要从磁盘中读取,加载buffer pool池中。
解决:mysql引入了一个flush链表。
6.
flush链表:本质也是通过描述数据地址组成的双向链表;用来记录哪些缓存页是脏页;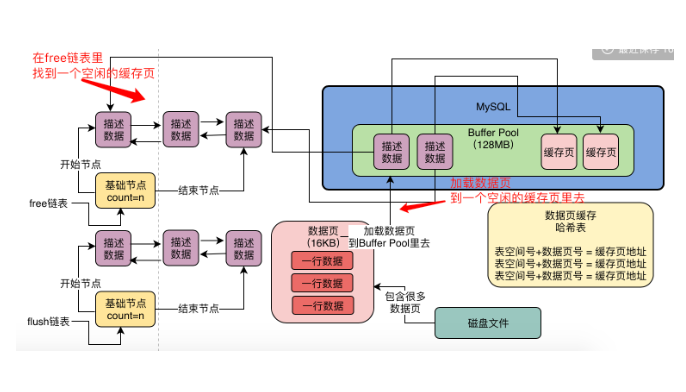
问题:当你不停的把磁盘上的数据页加载到空闲缓存页里,free链表中不停的移除缓存页,当没有空闲缓存页时,此时无法从磁盘上加载新的数据页到缓存页,就必须淘汰一些缓存页
解决:数据库引入LRU链表(least recently used,最近最少使用),他和free链表、flush链表结构一样,都是双向链表;每次磁盘读取数据页放到空闲的缓存页中,并将描述数据块地址添加到LRU链表的表头位置;每次用到某个缓存页都会移到当前缓存页对应的描述数据块到链表头部位置,当缓存页不足的时候,淘汰链表尾部的缓存页,他一定是最近最少使用的缓存页。7.
mysql预读机制:innodb_read_ahead_threshold = 56(默认值),如果顺序的访问一个区里的多个数据页,数量超过了这个阈值,此时就会触发预读机制,把下一个相邻区中的所有数据页都加载在缓存里区;innodb_random_read_ahead = off(默认值),如果开启,如果Buffer Pool里缓存了一个区里的13个连续的数据页,此时也会触发预读机制,把这个区的其他数据页都加载到缓存里;
问题:预读机制的触发,使得这些缓存页一下子都放在LRU链表的前面,其实他们并没有什么人会访问的话,就会导致本来一些频繁被访问的缓存页在LRU链表尾部;一旦要把一些缓存页淘汰的时候,就会把LRU链表尾部一些频繁被访问的缓存页给刷入磁盘和清空掉,这样就不太合理了;(全表扫描也会导致频繁访问的缓存页被淘汰)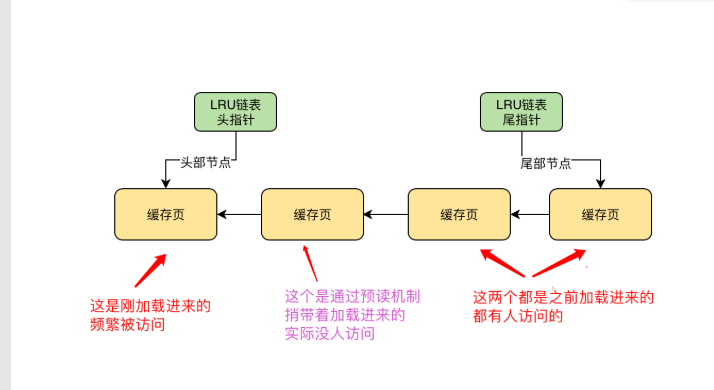
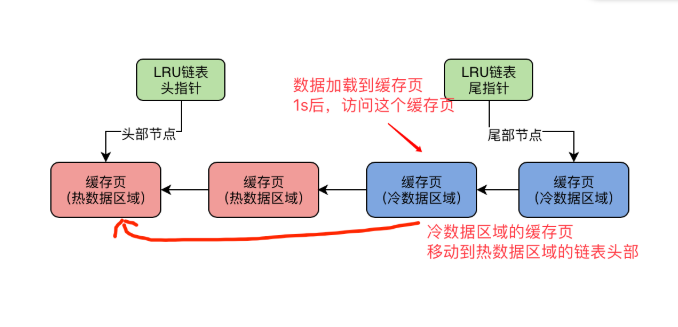
预读问题的解决:
a.基于冷热数据分离的思想设计LRU链表:真正的LRU链表,会被拆成两个部分,一部分是热数据,一部分是冷数据;由参数innodb_old_blocks_pct=37(默认),冷数据占比37%;
b.数据页第一次被加载进来,是放在冷数据区的头部;在1s(由参数innodb_old_blocks_time= 1000(默认值)控制)之后,如果访问这个缓存页,他才会被挪动到热数据区域的链表的头部
8.
mysql对LRU链表热数据区的进一步优化:问题:热数据区的缓存页经常被访问,频繁的移动对性能也不太友好的;
解决:LRU链表的热数据区访问规则被优化了一下,只有在热数据区后3/4部分的缓存页被访问了,才会移动到链表头部,前面1/4的缓存页被访问了,不会移动的;9.
buffer pool的缓存页以及几个链表的配合使用及缓存页刷盘时机:数据页加载到一个缓存页,
free链表里会移除这个缓存页,然后LRU链表的冷数据区的头部会放入这个缓存页;如果修改了一个缓存页,那么flush链表中会记录这个脏页,LRU链表中还可能会把这个缓存页从冷数据区移动到热数据区的头部。定时把
LRU链表尾部的部分缓存页刷入磁盘:mysql后台有一个线程,会运行一个定时任务,每隔一段时间就把LRU链表的冷数据区的尾部的一些缓存页,刷入磁盘,清空这几个缓存页,并把他们加入free链表里;flush链表刷入磁盘:flush链表中的节点都是脏页数据,LRU链表的热数据区的很多缓存页可能会被频繁修改,所以后台线程也会在mysql在不怎么繁忙的时候,把flush链表中的缓存页都刷入磁盘;只要flush链表中的一些缓存页被刷入磁盘,那么这些缓存页就会从flush链表和LRU链表中移除,然后加入到free链表中;
问题:没有空闲缓存页了怎么办?
解决:如果没有空闲缓存页,此时需要从磁盘加载数据页到一个空闲缓存页中,此时就会从LRU链表冷数据区的尾部找到一个缓存页,把数据刷入磁盘并清空,然后把数据页加载到这个腾出来的空闲缓存页中。
浅谈sql执行流程、innodb架构设计、buffer pool缓冲池的更多相关文章
- IOS中 浅谈iOS中MVVM的架构设计与团队协作
今天写这篇文章是想达到抛砖引玉的作用,想与大家交流一下思想,相互学习,博文中有不足之处还望大家批评指正.本篇文章的内容沿袭以往博客的风格,也是以干货为主,偶尔扯扯咸蛋(哈哈~不好好工作又开始发表博客啦 ...
- 浅谈iOS中MVVM的架构设计与团队协作【转载】
今天写这篇文章是想达到抛砖引玉的作用,想与大家交流一下思想,相互学习,博文中有不足之处还望大家批评指正.本篇文章的内容沿袭以往博客的风格,也是以干货为主,偶尔扯扯咸蛋(哈哈~不好好工作又开始发表博客啦 ...
- 浅谈iOS中MVVM的架构设计与团队协作
说到架构设计和团队协作,这个对App的开发还是比较重要的.即使作为一个专业的搬砖者,前提是你这砖搬完放在哪?不只是Code有框架,其他的东西都是有框架的,比如桥梁等等神马的~在这儿就不往外扯了.一个好 ...
- 浅谈 Nginx 的内部核心架构设计
一.前言 Nginx---Ngine X,是一款免费的.自由的.开源的.高性能HTTP服务器和反向代理服务器:也是一个IMAP.POP3.SMTP代理服务器:Nginx以其高性能.稳定性.丰富的功能. ...
- 浅谈iOS中MVVM的架构设计
MVVM就是在MVC的基础上分离出业务处理的逻辑到viewModel层. M: Model层是API请求的原始数据,充当DTO(数据传输对象),当然,用字典也是可以的,编程么,要灵活一些.Model ...
- c#Winform程序调用app.config文件配置数据库连接字符串 SQL Server文章目录 浅谈SQL Server中统计对于查询的影响 有关索引的DMV SQL Server中的执行引擎入门 【译】表变量和临时表的比较 对于表列数据类型选择的一点思考 SQL Server复制入门(一)----复制简介 操作系统中的进程与线程
c#Winform程序调用app.config文件配置数据库连接字符串 你新建winform项目的时候,会有一个app.config的配置文件,写在里面的<connectionStrings n ...
- 浅谈SQL Server 对于内存的管理
简介 理解SQL Server对于内存的管理是对于SQL Server问题处理和性能调优的基本,本篇文章讲述SQL Server对于内存管理的内存原理. 二级存储(secondary storage) ...
- 【SqlServer系列】浅谈SQL Server事务与锁(上篇)
一 概述 在数据库方面,对于非DBA的程序员来说,事务与锁是一大难点,针对该难点,本篇文章视图采用图文的方式来与大家一起探讨. “浅谈SQL Server 事务与锁”这个专题共分两篇,上篇主讲事务及 ...
- 浅谈SQL Server内部运行机制
对于已经很熟悉T-SQL的读者,或者对于较专业的DBA来说,逻辑的增删改查,或者较复杂的SQL语句,都是非常简单的,不存在任何挑战,不值得一提,那么,SQL的哪些方面是他们的挑战 或者软肋呢? 那就是 ...
- 浅谈SQL Server数据内部表现形式
在上篇文章 浅谈SQL Server内部运行机制 中,与大家分享了SQL Server内部运行机制,通过上次的分享,相信大家已经能解决如下几个问题: 1.SQL Server 体系结构由哪几部分组成? ...
随机推荐
- 用原型实现Class的各项语法
本人之前对Class一直不够重视.平时对原型的使用,也仅限于在构造函数的prototype上挂属性.原型尚且用不着,更何况你Class只是原型的一颗语法糖? 直到公司开始了一个webgis项目,使用o ...
- 【luogu题解】T378828 位运算
位运算 题目背景 题目由 daiyulong20120222 创作(me) 并由 QBW1117完善以及数据 . 题目描述 给定两个数\(x,y\) ,在给定一个位运算符号 \(c\). 请你列出 \ ...
- 洛谷P2757 [国家集训队]等差子序列 (hash+线段树)
题目连接 这题只要令 $len=3$看是否符合即可.因为是一个 $1$到 $n$的排列,考虑数列中项,那么对于一个数 $x$,令 $k=\max(n-x, x-1)$,只要存在 $d\in(1,k)$ ...
- Linux下通过AnySetup配置防火墙
软件 AnySetup 主要功能 主要功能是对Linux操作系统下的基本配置进行管理.多种服务配置进行管理.安全配置进行管理等.如:操作系统的升级管理,软件包的安装.更新和卸载管理,软件仓库源的管理, ...
- 吉特日化MES-日化生产相关设备区分
在化妆品生产过程中约到各种各样的设备,对日化生产设备做一些简单的整理汇总,便于学习(其中设备根据其所在的产品以及领域会有一定的不同) 从产品的角度可以将产品划分为: (1) 乳化剂类产品 (2) 分类 ...
- C# 字节数组、各进制字符串数据互转
前言 日常开发过程中,格式转换是必不可少的重要环节,经常是十进制转十六进制.十六进制转byte数组又转换回来来回转换,最然进制转换很基础同时 C# 也提供了很多直接方便进行格式转换的方法,但是封装一个 ...
- 24、Go语言中的OOP思想
1.是什么? OOP:面向对象 Go语言的解构体嵌套 1.模拟集成性:is - a type A struct { field } type B struct { A // 匿名字段 } 这种方式就会 ...
- MD5在文件安全中的应用与重要性
一.MD5简介 MD5(Message-Digest Algorithm 5)是一种广泛应用的密码散列函数,由美国密码学家罗纳德·李维斯特(Ronald Linn Rivest)于1992年提出.它主 ...
- Selenium基本使用、过检测
import time from selenium import webdriver from selenium.webdriver.chrome.service import Service as ...
- eclipse工具使用
eclipse下载 官网下载:https://www.eclipse.org/downloads/packages/ 打开后,找到Eclipse IDE for Java Developers点击进入 ...