聚合查询 分组查询 F与Q查询 添加新字段
聚合查询
聚合函数:Max Min Sum Count Avg
在ORM中支持单独使用聚合函数 aggregate
from django.db.models import Max, Min, Sum, Count, Avg
res = models.Book.objects.aggregate(Max('price'), Count('pk'), 最小价格=Min('price'), allPrice=Sum('price'),平均价格=Avg('price'))
print(res)
聚合函数的概念我们之前在mysql数据库中有所接触。
在mysql中是先使用group by分组,再使用聚合函数处理。聚合函数专门用于分组之后的数据统计。或者说当不进行分组时,会默认将当前表自己分为一组。
而在ORM中,聚合函数支持单独使用(把当前表作为一组),通过aggregate方法即可实现。
与聚合函数相关的功能,通常在django.db、django.db.model两个模块中。
aggregate 聚合函数
书籍表展示:

需求:求书里面价格最大的。
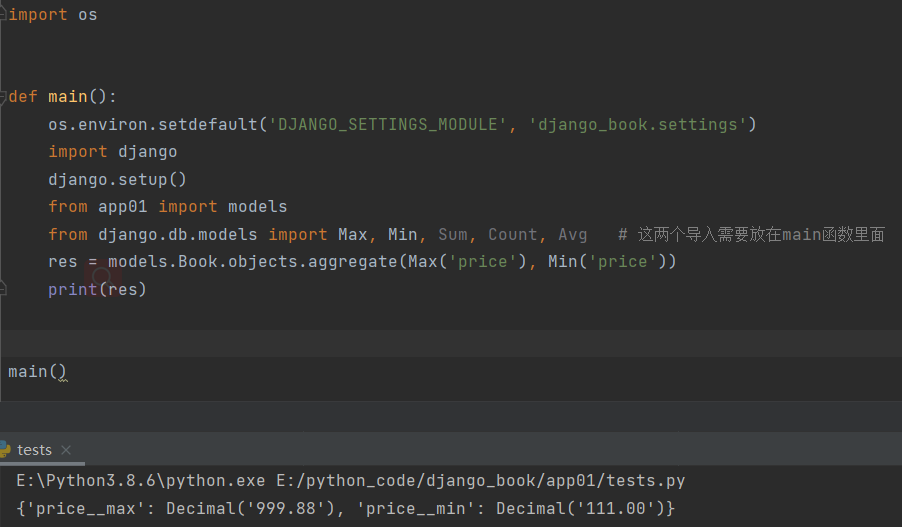
起别名
起别名:可以使用中文,但是不建议。
注意这里使用了等号,实际上是传入了关键字实参。这里关键字实参需要放在位置实参的后面,不然会报错。

分组查询
annotate 注释函数
需求:统计每一本书的作者个数。
所以应该按书分组,再对每个组的作者进行统计。
这里的意思是annotate前面是哪个表就按哪个分组:

比如上面这个例子,就是按照书分组,有8本书,就会分为8组。我们想统计每个书有几个作者。书到作者,外键(authors)在书,是一个正向查询。正向查询按类中外键字段。我们通过authors跳转到作者表,再加上一个固定的双下划线。这里每一个组都去作者表,查找有几个作者。最后使用Count函数对作者数进行统计。
但是如上操作,只能得到书籍对象,我们的查询结果也在书籍对象中:

起别名
这时候又需要取别名,然后我们使用自己取的别名,就可以拿到数据了:

分组查询报错
执行orm分组查询是有可能报错的 并且有关键字sql_mode_strict_model。
如下示例:

此时把only_full_group_by配置给取消就行了。

这里的session是当前会话有效,就是这个mysql账号退出登录后就无效了。想要长期生效可以修改配置文件。
分组查询练习
需求:统计出每个出版社的最便宜的书的价格。
思路:按照出版社分组,对书的价格使用聚合函数。
由于从出版社查书是反向查询,反向查询按照表名小写。

需求:统计不只一个作者的图书。
思路:先统计每一本书的作者个数(按照书分组),再筛选(filter)出作者个数大于1的数据。

这里筛选的时候使用了双下划线查询。
需求:查询每个作者出的书的总价格
思路:先按照作者分组,在组内求书的总价格,再将这个总价格的数据存放在书籍对象,最后通过values获取总价格。

总结
首先按照表中的某个字段分组:
"""
models.表名.objects.annotate() 按照表分组
models.表名.objects.values('字段名').annotate() 按照values括号内指定的字段分组
"""
添加新字段
当数据库中表已经生成,且里面已经存有数据时,如果我们想添加新的字段,此时该怎么做?
直接在模型层的类中新增字段:

这样你迁移数据库的时候,django会提示你:
1.你需要给新字段提供默认值
2.现在回去改模型层
这是为什么呢?

因为你添加新字段了,django不知道如何处理这些新生成的空格。
两种解决方法:

第一种是设置默认值,第二种是允许该空格为NULL,也就是允许为空。
F与Q查询
首先这两种查询都是对查询的再细化。
F查询是对双下划线查询的不足之处进行补充。
Q循环是对filter查询的不足之处进行补充。
F查询
需求1:查询库存数大于卖出数的书籍
这时候我们或许会想到这样写:

但是不行,双下划线gt 后面只支持数字。
当查询条件不是明确的,也需要从数据库中获取时 就需要使用F查询。

需求2:将所有书的价格涨800块
这样不行:

update方法是直接覆盖,而不是在原有的基础上涨价。

所以这里也要用F查询:

字符串拼接 concat方法
需求3:将所有书的名称后面追加爆款二字

也是需要用F查询获取每本书原有的名字,在这个基础进行字符串的拼接,最后使用update更新数据库。
但是很可惜,orm中数字相加可以用加号,而字符串拼接是要用特定的方法的:

Q查询
还记得我们之前学过的filter方法吗?里面的查询条件,默认情况下都是and的关系。
如:

这里的意思是查询主键为1且价格大于2000的书籍。
而我们的需求:查询主键是1或者价格大于2000的数据
也就是想要查询条件变成or的关系:

必须要用Q查询:
Q查询之and关系

将查询条件用Q函数包起来,注意这个逗号隔开。逗号隔开表示这两个查询条件是and关系。
Q查询之or关系
想要使用or关系就用|将两个条件隔开。

Q查询之取反
Q查询还支持取反操作,使用~符号:

这里表示:查询主键不是1 或者 价格大于2000的书。
聚合查询 分组查询 F与Q查询 添加新字段的更多相关文章
- Django 08 Django模型基础3(关系表的数据操作、表关联对象的访问、多表查询、聚合、分组、F、Q查询)
Django 08 Django模型基础3(关系表的数据操作.表关联对象的访问.多表查询.聚合.分组.F.Q查询) 一.关系表的数据操作 #为了能方便学习,我们进入项目的idle中去执行我们的操作,通 ...
- Django模型系统——ORM中跨表、聚合、分组、F、Q
核心知识点: 1.明白表之间的关系 2.根据关联字段确定正反向,选择一种方式 在Django的ORM种,查询既可以通过查询的方向分为正向查询和反向查询,也可以通过不同的对象分为对象查询和Queryse ...
- Django orm进阶查询(聚合、分组、F查询、Q查询)、常见字段、查询优化及事务操作
Django orm进阶查询(聚合.分组.F查询.Q查询).常见字段.查询优化及事务操作 聚合查询 记住用到关键字aggregate然后还有几个常用的聚合函数就好了 from django.db.mo ...
- Django 聚合查询 分组查询 F与Q查询
一.聚合查询 需要导入模块:from django.db.models import Max, Min, Sum, Count, Avg 关键语法:aggregate(聚合结果别名 = 聚合函数(参数 ...
- Django 聚合分组F与Q查询及choices
一.聚合查询 需要导入模块:from django.db.models import Max, Min, Sum, Count, Avg 关键语法:aggregate(聚合结果别名 = 聚合函数(参数 ...
- 图书管理系统、聚合函数、分组查询、F与Q查询
目录 图书管理系统 1.表设计 2.首页搭建.展示 书籍的添加 书籍编辑 书籍删除 聚合函数 Max Min Sum Count Avg 分组查询 按照表分组 按照字段分组 F与Q查询 F查询 Q查询 ...
- 聚合查询、分组查询、ORM中如何给表再次添加新的字段、F与Q查询、ORM查询优化、ORM事务操作、ORM常用字段类型、ORM常用字段参数、Ajax、数据编码格式(Content-Type)、ajax携带文件数据
今日内容 聚合查询 在ORM中支持单独使用聚合函数,需要使用aggregate方法. 聚合函数:Max最大.Min最小.Sum总和.Avg平均.count统计 from django.db.model ...
- 12月16日内容总结——图书管理系统、聚合与分组查询、F与Q查询
目录 一.图书管理系统讲解 二.聚合查询 三.分组查询 四.ORM中如何给表再次添加新的字段 五.F与Q查询 六.作业 一.图书管理系统讲解 1.表设计 先考虑普通字段再考虑外键字段 数据库迁移.测试 ...
- django----聚合查询 分组 F与Q查询 字段 及其 参数
目录 一.orm补充查询 聚合查询 1-1 分组查询 1-2 F与Q查询 1-3 二. 字段及其参数 常用字段 AutoField IntegerField CharField DateField D ...
- Django中多表的增删改查操作及聚合查询、F、Q查询
一.创建表 创建四个表:书籍,出版社,作者,作者详细信息 四个表之间关系:书籍和作者多对多,作者和作者详细信息一对一,出版社和书籍一对多 创建一对一的关系:OneToOne("要绑定关系的表 ...
随机推荐
- java固定窗口大小
this.setResizable(false);//////frame.setResizable(false)
- Ubuntu 20.04 查看内存信息
输入命令 dmidecode -t memory 输出如下: # dmidecode 3.2 Getting SMBIOS data from sysfs. SMBIOS 2.8 present. H ...
- Python 潮流周刊#27:应该如何处理程序的错误?
你好,我是猫哥.这里每周分享优质的 Python.AI 及通用技术内容,大部分为英文.本周刊开源,欢迎投稿.另有电报频道作为副刊,补充发布更加丰富的资讯. 产品推荐 Walles.AI 是一款适用于所 ...
- 1. Linux 软件介绍
重点: rpm -i -e -qi -ql -qf -qa --scripts. yum install remove info list repolist provides. 配置系统源. 搭建私有 ...
- 2分钟,快速认识什么是SQL
结构化查询语言,简称SQL,它是与关系数据库管理系统通信的黄金标准语言.今天就来一起快速认识一下什么是SQL,您可以通过以下的文字内容学习,也可以通过文末的视频学习,希望本文对您有所帮助. 您可能听说 ...
- .net下优秀的日志框架Serilog,你用上了吗?强烈推荐
在 .NET 开发中,Serilog 是一款广受欢迎的日志库,它提供了强大的日志记录功能,具有丰富的特性和高度的可扩展性.Serilog 的优秀之处包括: 可扩展性: Serilog 可以轻松扩展以满 ...
- 【Postman&JMeter】使用Postman和JMeter进行signature签名
使用Postman和JMeter进行signature签名 目录 使用Postman和JMeter进行signature签名 一.前言 二.v0接口 1.Postman 2.JMeter 三.v1接口 ...
- 【2016】CloneCD和IsoBuster配合使用以提取VCD中的文件
**笔记记录于:2016-11-24 ** 本文章仅供用于技术研究用途,请勿利用文章内容操作用于违反法律的事情. 起因: 公司老总让我提取下VCD中的文件以备份下,但是把光碟放进DVD光驱中发现只有几 ...
- 【笔记整理】请求携带cookie的两种方法
""" 方法一:在请求头header中携带Cookie请求头信息(因为本身Cookie就是用请求头传递的....) 方法二:使用cookie参数传递cookie字典 &q ...
- 一篇可供参考的 K8S 落地实践经验
前言 k8s 即 Kubernetes,是一个开源的容器编排引擎,用来对容器化应用进行自动化部署. 扩缩和管理 本篇文章将分享 k8s v1.18.8 的安装,以及其面板,监控,部署服务,使用Ingr ...