Transformer应用于时序任务:综述《Transformers in Time Series: A Survey》
摸鱼了一天,看看综述。
论文:Transformers in Time Series: A Survey
GitHub:
阿里达摩院 2022的论文。
摘要
从两个角度研究了时间序列transformers的发展。
(i)从网络结构的角度,总结了为适应时间序列分析中的挑战而对transformer进行的调整和修改。
(ii)从应用的角度,根据常见任务对时间序列transformers进行分类,包括预测、异常检测和分类。
根据经验,进行稳健分析、模型规模分析和季节趋势分解分析,以研究transformers在时间序列中的表现。
最后,讨论并建议未来的方向,以提供有益的研究指导。
1 介绍
Transformer在序列数据中显示了强大的远程依赖性和交互建模能力,因此与时间序列建模相关。
季节性或周期性是时间序列的一个重要特征,如何有效地建模长期和短期时间依赖性并同时捕获季节性仍然是一个挑战。
由于时间序列Transformer是深度学习中的一个新兴学科,对时间序列中Transformers进行系统和全面的调查将大大有利于时间序列社区。
2022年9月14日 10:42
(1)对于网络修改,讨论了对Transformers的低级(即模块)和高级(即架构)所做的改进,目的是优化时间序列建模的性能。
(2)对于应用,分析和总结了用于流行的时间序列任务的Transformers,包括预测、异常检测和分类。
2 Transformer的前期工作
2.1 普通的Transformer
普通的Transformer【Vaswani等人,2017年】采用编码器-解码器结构,遵循最具竞争力的神经序列模型。编码器和解码器都由多个相同的块组成。每个编码器块由多头自关注模块和位置方向前馈网络(FFN)组成,而每个解码器块在多头自注意模块与位置方向前馈网(FFN),插入交叉关注模型。
2.2 输入编码和位置编码
与LSTM或RNN不同,Transformer没有递归和卷积。相反,它利用在输入embeddings中添加的位置编码来建模序列信息。
下面总结一些位置编码。
绝对位置编码
相对位置编码
相对位置编码方法。例如,其中一种方法是将可学习的相对位置嵌入添加到注意力机制的keys(键值)[Shaw等人,2018]。
除了绝对和相对位置编码之外,还有使用混合位置编码的方法,将它们结合在一起[Ke等人,2020]。通常,位置编码被添加到token embedding中,并被馈送到Transformer。
2.3 多头注意力
2.4 前馈和残差网络
点式前馈网络是一个完全连接的模块。
在较深的模块中,在每个模块周围插入残差连接模块,然后是层归一化模块。
3 时间序列中Transformers的分类
为了总结现有的时间序列Transformers,从网络修改和应用领域的角度提出了一种分类法,如图1所示。
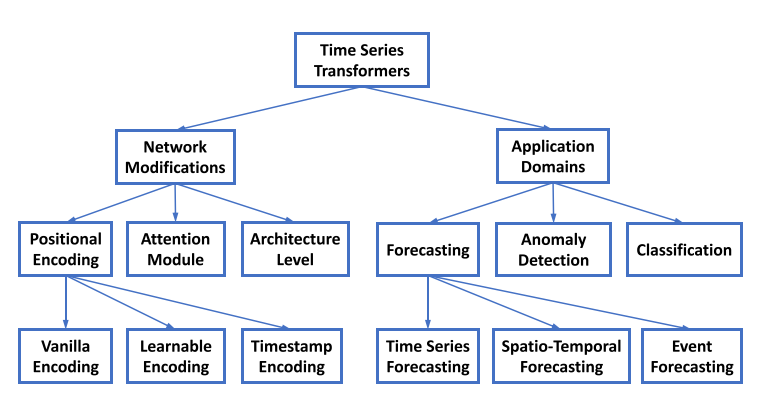
图1:从网络修改和应用领域的角度对时间序列建模的Transformers分类
从网络修改的角度,总结了Transformer在模块级和架构级所做的更改,以适应时间序列建模中的特殊挑战。从应用的角度,根据时间序列Transformers的应用任务对其进行分类,包括预测、异常检测、分类和聚类。
4 时间序列的网络修改
4.1 位置编码
由于Transformers是等效的,而且时间序列的排序很重要,因此将输入时间序列的位置编码到Transformers中是非常重要的。一个常见的设计是首先将位置信息编码为向量,然后将它们与输入的时间序列一起作为附加输入注入模型。在用Transformers对时间序列进行建模时,如何获得这些向量可以分为三个主要类别。
普通位置编码
虽然这种普通的应用可以从时间序列中提取一些位置信息,但无法充分地利用时间序列数据的重要特征。
可学习位置编码
一些研究发现,从时间序列数据中学习适当的位置嵌入可能更有效。与固定的普通位置编码相比,学习嵌入更灵活,可以适应特定任务。[Zerveas等人,2021]在Transformer中引入embedding层,该嵌入层与其他模型参数一起学习每个位置索引的嵌入向量。[Lim等人,2019]使用LSTM网络对位置嵌入进行编码,目的是更好地利用时间序列中的顺序排序信息。
时间戳编码
在真实场景中建模时间序列时,时间戳信息通常是可访问的,包括日历时间戳(例如,秒、分钟、小时、周、月和年)和特殊时间戳(如,节假日和事件)。这些时间戳在实际应用程序中非常有用,但在普通Transformers中几乎没有使用。为了缓解这个问题,Informer[Zhou等人,2021]提出通过使用可学习的嵌入层将时间戳编码为额外的位置编码。在Autoformer[Wu等人,2021]和FEDformer[Zhou等人,2022]中使用了类似的时间戳编码方案。
4.2 注意力模块
Transformer的核心是自我注意模块。它可以被看作是一个全连接层,其权重是根据输入模式的成对相似度动态生成的。因此,它与全连接层具有相同的最大路径长度,但参数数量要少得多,使其适合于建立长期依赖关系的模型。
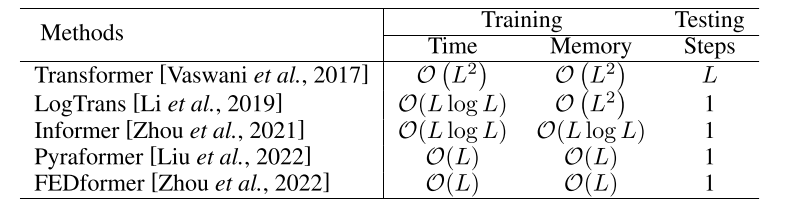
正如在上一节中所展示的,普通Transformer中的自我注意模块的时间和内存复杂度为O(L2)(L为输入时间序列的长度),在处理长序列时,它成为计算的瓶颈。许多高效的Transformer被提出来以降低二次复杂度,可以分为两个主要类别:(1) 明确地在注意力机制中引入稀疏偏差,如LogTrans [Li et al., 2019] 和 Pyraformer [Liu et al., 2022];(2) 探索自我注意力矩阵的低秩属性以加快计算速度,如Informer [Zhou et al., 2021] 和 FEDformer [Zhou et al., 2022]。在表1中,总结了应用于时间序列建模的流行Transformers的时间和内存复杂性。
表1:具有不同注意力模块的流行时间序列transformers的复杂性比较。
4.3 架构层面的创新
除了在Transformers中容纳单个模块用于时间序列建模外,一些工作[Zhou等人, 2021; Liu等人, 2022]试图在结构层面上对Transformers进行改造。最近的工作在Transformer中引入了分层结构,以考虑到时间序列的多分辨率方面。Informer [Zhou et al., 2021]在注意力块之间插入跨度为2的最大池化层,将序列向下取样到其半片。Pyraformer [Liu et al., 2022]设计了一个基于C-ary树的关注机制,其中最细尺度的节点对应原始时间序列,而较粗尺度的节点代表低分辨率的序列。Pyraformer同时开发了尺度内和尺度间的关注,以便更好地捕捉不同分辨率的时间依赖性。除了整合不同多分辨率信息的能力,分层结构还享有高效计算的好处,特别是对于长时间序列。
5 时间序列Transformers的应用
5.1 预测中的Transformers
研究了三种类型的预测任务,即时间序列预测、时空预测和事件预测。
时间序列预测
预测是时间序列最常见和最重要的应用。LogTrans [Li et al., 2019]提出了卷积自注意力,通过采用因果卷积来生成自注意力层中的queries和keys。它在自我注意模型中引入了稀疏偏置,即Logsparse掩码,将计算复杂度从O(L2)降低到O(L log L)。
Informer[Zhou等人,2021]没有明确地引入稀疏偏差,而是根据queries和key的相似性选择O(log L)的主导查询,从而在计算复杂度上实现与LogTrans类似的改进。它还设计了一个生成式解码器,直接产生长期预测,从而避免了使用一个正向步骤预测进行长期预测的累积误差。
AST[Wu et al., 2020]使用生成式对抗编码器-解码器框架来训练用于时间序列预测的稀疏Transformer模型。它表明,对抗性训练可以通过直接塑造网络的输出分布来改善时间序列预测,以避免通过一步超前推理而产生的误差积累。
Autoformer[Wu et al., 2021]设计了一个简单的季节趋势分解架构,其中的自相关机制作为一个注意力模块。自相关块不是传统的注意力块。它测量输入信号之间的时延相似性,并聚合前k个相似子序列,以产生复杂度降低为O(L log L)的输出。
FEDformer [Zhou et al., 2022] 在频域中应用了傅里叶变换和小波变换的注意力操作。它通过随机选择一个固定大小的频率子集实现了线性复杂度。值得注意的是,由于Autoformer和FEDformer的成功,在频域中探索时间序列建模的自注意力机制已经引起了社区的更多关注。
TFT[Lim等人,2021]设计了一个具有静态协变量编码器、门控特征选择和时间自注意力解码器的多跨度预测模型。它从各种协变量中编码和选择有用的信息来进行预测。它还保留了可解释性,包括全局、时间依赖性和事件。
SSDNet [Lin et al., 2021] 和ProTran [Tang and Matteson, 2021] 将Transformer与状态空间模型相结合,以提供概率预测。SSDNet首先使用Transformer学习时间模式并估计SSM的参数,然后应用SSM进行季节趋势分解并保持可解释能力。ProTran设计了一个基于变分推理的生成式建模和推理过程。
Pyraformer [Liu et al., 2022] 设计了一个具有二叉树跟踪路径的分层金字塔注意力模块,以线性时间和内存复杂度捕捉不同范围的时间依赖。
Aliformer [Qi et al., 2021]通过使用知识引导的注意力,用一个分支来修正和去噪注意力图,对时间序列数据进行顺序预测。
时空预测
在时空预测中,我们需要同时考虑时间和时空相关性,以便进行准确预测。Traffic Transformer [Cai et al., 2020]设计了一个编码器-解码器结构,使用自注意力模块来捕捉时间-时间依赖性,使用图形神经网络模块来捕捉空间依赖性。用于交通流预测的时空变换器[Xu等人, 2020]更进一步。除了引入一个时间变换器模块来捕获时间依赖性之外,它还设计了一个空间变换器模块,连同一个图卷积网络,以更好地捕获空间-空间依赖性。时空图变换器[Yu等人, 2020]设计了一个基于注意力的图卷积机制,能够学习复杂的时空注意力模式,以改善行人轨迹预测。
事件预测
在许多现实生活的应用中,自然会观察到具有不规则和异步时间戳的事件序列数据,这与具有相等采样间隔的规则时间序列数据形成对比。事件预测或预报的目的是根据过去事件的历史来预测未来事件的时间和标志,它通常由时间点过程(TPP)建模[Shchur等人,2021]。
最近,一些神经TPP模型开始结合Transformers,以提高事件预测的性能。自注意力霍克斯过程 (SAHP) [Zhang et al., 2020] 和Transformer霍克斯过程 (THP) [Zuo et al., 2020] 采用Transformer编码器架构来总结历史事件的影响并计算事件预测的强度函数。它们通过将时间间隔转化为正弦函数来修改位置编码,从而使事件之间的间隔得到利用。后来,一个更灵活的名为注意力神经数据记录时间 (A-NDTT) [Mei et al., 2022]被提出来,通过将所有可能的事件和时间嵌入注意力来扩展SAHP/THP方案。实验表明,与现有方法相比,它能更好地捕捉复杂的事件依赖关系。
5.2 异常检测中的Transformers
深度学习也引发了异常检测的新发展[Ruff等人,2021]。由于深度学习是一种表征学习,重建模型在异常检测任务中发挥着重要作用。重构模型的目的是学习一个神经网络,将简单的预定义源分布Q的向量映射到实际的输入分布P+。Q通常是一个高斯分布或均匀分布。异常分数是由重建误差定义的。直观地说,重建误差越高,意味着不太可能来自输入分布,异常得分越高。设置一个阈值来区分异常和正常。
最近,[Meng等人,2019]揭示了使用Transformer进行异常检测比其他传统的时间依赖性模型(如LSTM)的优势。除了更高的检测质量(以F1衡量),基于transformer的异常检测明显比基于LSTM的方法更有效率,这主要是由于Transformer架构的并行计算。在多项研究中,包括TranAD[Tuli等人,2022],MT-RVAE[Wang等人,2022]和TransAnomaly[Zhang等人,2021],研究人员提出将Transformer与神经生成模型相结合,例如VAEs[Kingma和Welling,2013]和GANs[Goodfellow等人,2014],以便在异常检测中建立更好的重建模型。
TranAD提出了一种对抗性训练过程,以放大重建误差,因为基于Transformer的简单网络往往会错过小的异常偏差。GAN风格的对抗性训练程序是由两个Transformer编码器和两个Transformer解码器设计的,以获得稳定性。消融研究表明,如果更换基于Transformer的编码器-解码器,F1评分性能将下降近11%,表明Transformer架构对异常检测的重要性。
2022年9月16日 15:11
虽然MT-RVAE和TransAnomaly都将VAE与Transformer结合起来,但它们有着不同的目的。TransAnomaly将VAE与Transformer结合起来,允许更多的并行化,并将训练成本降低近80%。在MT-RVAE中,多尺度的Transformer被设计用来提取和整合不同尺度的时间序列信息。它克服了传统Transformer只提取局部信息进行序列分析的缺点。
一些时间序列Transformer是为多变量时间序列设计的,它们将Transformer与基于图的学习架构相结合,如GTA[Chen等人,2021d]。请注意,MT-RVAE也适用于多变量时间序列,但在维度较少或序列间关系不够紧密时,图神经网络模型效果并不好。为了应对这种挑战,MT-RVAE修改了位置编码模块并引入了特征学习模块。GTA包含图卷积结构来模拟影响传播过程。与MT-RVAE类似,GTA也考虑了 "全局 "信息,但它用多分支注意力机制取代了普通的多头注意力,也就是全局学习注意力、普通的多头注意力和邻域卷积的组合。
AnomalyTrans [Xu et al., 2022]将Transformer和高斯先验关联结合起来,,使罕见的异常现象更容易被区分。尽管与TranAD的动机相似,但AnomalyTrans以非常不同的方式实现了这一目标。洞察力在于,与常态相比,异常现象更难与整个系列建立强大的关联,而与相邻的时间点则更容易。在AnomalyTrans中,先验关联和系列关联是同时建模的。除了重建损失外,异常模型还通过极小极大策略进行优化,以约束先验关联和系列关联,从而获得更多可区分的关联差异。
5.3 分类中的Transformers
Transformer被证明在各种时间序列分类任务中是有效的,因为它在捕捉长期依赖性方面具有突出能力。分类Transformers通常采用一个简单的编码器结构,其中自注意力层进行表征学习,前馈层产生每个类别的概率。
2022年9月18日 14:25
GTN [Liu et al., 2021]使用了一个双塔Transformer,每个塔分别致力于时间步长的注意和通道长的注意。为了合并两个塔的特征,使用了一个可学习的加权协concat(也称为 "门控")。提出的Transformer的扩展在13个多变量时间序列分类上取得了最先进的结果。[Rußwurm和K¨orner, 2020]研究了基于自我注意的Transformer用于原始光学卫星时间序列分类,与递归和卷积神经网络相比,获得了最佳结果。
在分类任务中也研究了预训练Transformers。[Yuan and Lin, 2020]研究了用于原始光学卫星图像时间序列分类的Transformer。由于标注的数据有限,作者使用了自监督的预训练模式。[Zerveas等人,2021]引入了一个无监督的预训练框架,模型是用按比例屏蔽的数据进行预训练。然后在下游任务(如分类)中对预训练的模型进行微调。[Yang等人,2021]提出将大规模预训练的语音处理模型用于下游的时间序列分类问题,并在30个流行的时间序列分类数据集上产生了19个有竞争力的结果。
6 试验评估和讨论
鲁棒性分析
2022年9月19日 10:19
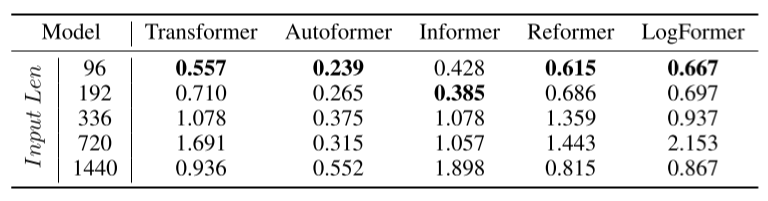
上述工作,虽然使用了短的固定大小输入,在实验中获得了最佳结果。但作者质疑实际使用的效果。所以通过延长输入长度来做鲁棒性实验来证明这些模型在处理长期输入序列时的预测能力和鲁棒性。
如表2,将预测结果与延长输入长度进行比较,各种基于Transformers的模型迅速恶化。这说明这些模型在长期预测任务中不能有效地利用长输入信息。需要更多的工作来充分利用长序列输入,而不是简单的运行。
表2:在延长输入长度的情况下,ETTm2数据集的96步预测稳健性实验的MSE比较
模型规模大小分析
在被引入时间序列预测领域之前,Transformer已经在NLP和CV社区表现出了优势性能[Vaswani等人,2017;Kenton和Toutanova,2019;Qiu等人,2020;Han等人,2021;Khan等人,2021;Selva等人,2022] 。Transformer在这些领域拥有的一个关键优势是能够通过增加模型容量来提高预测能力。通常情况下,模型容量由Transformer的层数控制,在CV和NLP中,层数通常设置在12到128之间。
提出了一个问题,即如何设计具有深层的Transformer架构,以增加模型的容量并实现更好的预测性能。
季节-趋势分解分析
在最新的研究中,研究人员[Wu et al., 2021; Zhou et al., 2022; Lin et al., 2021; Liu et al., 2022]开始意识到,季节-趋势分解是Transformer在时间序列预测中表现的关键部分。作为表4所示的一个简单实验,我们使用[Wu et al., 2021]中提出的移动平均趋势分解架构来测试各种注意模块。季节性趋势分解模型可以大大提升模型的性能,达到50%到80%。这是一个独特的区块,这种通过分解提升性能的现象似乎是Transformer应用中时间序列预测的一致现象,值得进一步研究。
7 未来的研究机遇
在这里,我们强调了在时间序列中研究Transformers的几个潜在方向。
7.1 时间序列Transformers的电感偏置
普通的Transformer不对数据模式和特征做任何假设。虽然它是一个用于建模长距离依赖关系的通用网络,但它也是有代价的,即需要大量的数据来训练Transformer以避免数据过拟合。时间序列数据的关键特征之一是它的季节性/周期性和趋势模式[Wen等人,2019;Cleveland等人,1990] 。最近的一些研究表明,将序列周期性[Wu et al., 2021]或频率处理[Zhou et al., 2022]纳入时间序列Transformer可以显著提高性能。因此,未来的一个方向是,根据对时间序列数据的理解和特定任务的特点,考虑更有效的方法,将归纳的偏差引入到Transformer中。
7.2 时间序列的Transformers和GNN
多变量和时空时间序列在应用中越来越普遍,需要更多的技术来处理高维度,特别是捕捉维度之间的潜在关系的能力。引入图神经网络(GNN)是一种自然的方式来模拟空间依赖性或维度之间的关系。最近,一些研究表明,GNN和transformers/attentions的结合不仅可以带来像交通预测[Cai等人,2020;Xu等人,2020]和多模式预测[Li等人,2021]的显著性能改进,而且可以更好地理解时空动态和潜在的偶然性。将Transformers和GNNs结合起来,有效地在时间序列中进行时空建模,是未来的一个重要方向。
7.3 时间序列预训练Transformers
大规模的预训练Transformer模型大大提升了NLP[Kenton and Toutanova, 2019; Brown et al., 2020]和CV[Chen et al., 2021a]中各种任务的性能。然而,针对时间序列的预训练Transformers的工作有限,现有的研究主要集中在时间序列分类上[Zerveas等人, 2021; Yang等人, 2021]。因此,如何为时间序列中的不同任务开发合适的预训练Transformer模型,还有待今后的研究。
7.4 带NAS的时间序列Transformers
超参数,如嵌入尺寸、头数和层数,可以在很大程度上影响Transformer的性能。手动配置这些超参数是很耗时的,而且往往会导致次优的性能。神经架构搜索(NAS)[Elsken等,2019;Wang等,2020]一直是发现有效的深度神经架构的流行技术,在最近的研究中可以发现在NLP和CV中使用NAS自动设计Transformer[So等,2019;陈等,2021c]。对于工业规模的时间序列数据,其维度和长度都很高,自动发现内存和计算效率高的Transformer架构具有重要的现实意义,这使得它成为时间序列Transformer的重要未来方向。
8 总结
在本文中,我们对各种任务中的时间序列Transformers进行了全面调查。使用由网络修改和应用领域组成这两种新的分类法进行组织调查。我们总结了每个类别中的代表性方法,通过实验评估讨论它们的优势和局限性,并强调了未来的研究方向。
个人:有用有用,感觉可以从季节-趋势分解特征和层次上进行时序预测,然后使用NAS进行参数调整,有戏有戏。
11:03告辞.
Transformer应用于时序任务:综述《Transformers in Time Series: A Survey》的更多相关文章
- 知识图谱顶刊综述 - (2021年4月) A Survey on Knowledge Graphs: Representation, Acquisition, and Applications
知识图谱综述(2021.4) 论文地址:A Survey on Knowledge Graphs: Representation, Acquisition, and Applications 目录 知 ...
- 第五课第四周笔记1:Transformer Network Intuition 变压器网络直觉
目录 Transformer Network Intuition 变压器网络直觉 Transformer Network Intuition 变压器网络直觉 深度学习中最令人兴奋的发展之一是 Tran ...
- TimescaleDB比拼InfluxDB:如何选择合适的时序数据库?
https://www.itcodemonkey.com/article/9339.html 时序数据已用于越来越多的应用中,包括物联网.DevOps.金融.零售.物流.石油天然气.制造业.汽车.太空 ...
- MS-TCT: Multi-Scale Temporal ConvTransformer for Action Detection概述
1.针对的问题 为了在未修剪视频中建模时间关系,以前的多种方法使用一维时间卷积.然而,受核大小的限制,基于卷积的方法只能直接获取视频的局部信息,不能学习视频中时间距离较远的片段之间的直接关系.因此,这 ...
- Java反序列化漏洞详解
Java反序列化漏洞从爆出到现在快2个月了,已有白帽子实现了jenkins,weblogic,jboss等的代码执行利用工具.本文对于Java反序列化的漏洞简述后,并对于Java反序列化的Poc进 ...
- Ysoserial Commons Collections3分析
Ysoserial Commons Collections3分析 写在前面 CommonsCollections Gadget Chains CommonsCollection Version JDK ...
- OpenCV学习(14) 细化算法(2)
前面一篇教程中,我们实现了Zhang的快速并行细化算法,从算法原理上,我们可以知道,算法是基于像素8邻域的形状来决定是否删除当前像素.还有很多与此算法相似的细化算法,只是判断的条件不一样. ...
- 大规模 Transformer 模型 8 比特矩阵乘简介 - 基于 Hugging Face Transformers、Accelerate 以及 bitsandbytes
引言 语言模型一直在变大.截至撰写本文时,PaLM 有 5400 亿参数,OPT.GPT-3 和 BLOOM 有大约 1760 亿参数,而且我们仍在继续朝着更大的模型发展.下图总结了最近的一些语言模型 ...
- ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
前言 人脸表情识别(FER)在计算机视觉领域受到越来越多的关注.本文介绍了一篇在人脸表情识别方向上使用Transformer来学习关系感知的ICCV2021论文,论文提出了一个TransFER ...
- ICCV2021 | Vision Transformer中相对位置编码的反思与改进
前言 在计算机视觉中,相对位置编码的有效性还没有得到很好的研究,甚至仍然存在争议,本文分析了相对位置编码中的几个关键因素,提出了一种新的针对2D图像的相对位置编码方法,称为图像RPE(IRPE). ...
随机推荐
- 12 二次打开pdf失败
h5 安卓 iOS均出现pdf二次打开失败
- oeasy教您玩转vim - 27 - 文件类型
文件类型 回忆上节课内容 上次了解了缩进的各种方式 正常模式下用 << 缩进 插入模式下用 tab 缩进 显示缩进情况 :set listchars=eol:$,tab:>-,s ...
- Microsoft Azure AI 机器学习笔记-1
机器学习基础: 数据与建模: 数据统计和数学建模是处理数据和描述现实情况的关键工具. 观测值是记录的数据实例,而特征是描述观测对象的属性. 标签则代表监督式学习中的已知输出值. 学习类型: 监督式学习 ...
- Bond4配置
Bongding聚合链路工作模式 > bond聚合链路模式共7种:0-6Mode > bond 0 负载均衡 轮询方式往每条链路发送报文,增加带宽和容错能力.容易出现数据包无序到达的问题, ...
- windows生成苹果私钥证书p12证书和profile文件的方法
hbuilderx出现已经有差不多10年时间了,现在越来越多的企业,开始使用跨平台性更优秀的uniapp来开发ios app. 开发ios app的时候,打包需要苹果的私钥证书和证书profile文件 ...
- 【Mybatis】Bonus01 笔记资料
对原生JDBC程序的问题总结 public void jdbc() { // 声明Connection对象 Connection con; // 驱动程序名 String driver = " ...
- 【Web】实现页面自动刷新的功能
技术发现自: https://www.bilibili.com/video/BV14v411b7JS?p=8 摘要自CSDN帖子: https://blog.csdn.net/senbar/artic ...
- 【Tutorial C】03 数据类型、变量
在程序的世界中,可以让计算机按照指令做很多事情, 如进行数值计算.图像显示.语音对话.视频播放.天文计算.发送邮件.游戏绘图以及任何我们可以想象到的事情. 要完成这些任务,程序需要使用数据,即承载信息 ...
- 【Hibernate】05 缓存与MySQL事务隔离
Cache 什么是缓存? 数据存储到数据库,是从内存中以流的方式写进[输出]到数据库,其效率并不是很高 - 所以在内存中暂存一部分数据,可以不以流的方式读取,效率是非常高的[相对于流来说] Hiber ...
- pycuda学习过程中的一些发现,cuda函数的初始化要在cuda内存空间初始化之后,否则会报错
参考: https://www.cnblogs.com/devilmaycry812839668/p/15348610.html 最近在看WarpDrive的代码,其中cuda上运行的代码是使用pyc ...