Linux中的IDR机制
背景
最近在学习 Linux的i2c子系统,看到代码中有关于IDR的调用。了解了一下有关的文档,发现是用来管理指针(对象实例)。
//based on linux V3.14 source code
reference:
- https://blog.csdn.net/morphad/article/details/9051261
- https://blog.csdn.net/midion9/article/details/50923095
概述
系统许多资源都用整数ID来标识,如进程ID、文件描述符ID、IPC ID等;资源信息通常存放在对应的数据结构中(如进程信息存放在task_struct中、ipc信息存放在ipc_perm中),id与数据结构的关联机制有不同的实现,idr机制是其中的一种。
idr,id radix的缩写。idr主要用于建立id与指针(指向对应的数据结构)之间的对应关系。idr用类基数树结构来构造一个稀疏数组,以id为索引找到对应数组元素,进而找到对应的数据结构指针。
IDR机制在Linux内核中指的是整数ID管理机制。实质上来讲,这就是一种将一个整数ID号和一个指针关联在一起的机制。这个机制最早在03年2月加入内核,当时作为POSIX定时器的一个补丁。现在,内核中很多地方都可以找到它的身影。
用到idr机制的主要有:IPC id(消息队列id、信号量id、共享内存id等),磁盘分区id(sda中数字部分)等。
IDR机制产生的背景原理:
IDR机制适用在那些需要把某个整数和特定指针关联在一起的地方。例如,在IIC总线中,每个设备都有自己的地址,要想在总线上找到特定的设备,就必须要先发送设备的地址。当适配器要访问总线上的IIC设备时,首先要知道它们的ID号,同时要在内核中建立一个用于描述该设备的结构体,和驱动程序。将ID号和设备结构体结合起来,如果使用数组进行索引,一旦ID号很大,则用数组索引会占据大量内存空间。这显然不可能。或者用链表,但是,如果总线中实际存在的设备很多,则链表的查询效率会很低。此时,IDR机制应运而生,可以很方便的将整数和指针关联起来,并且具有很高的搜索效率(内部采用radix树实现)。
相关结构体
struct idr {
struct idr_layer __rcu *hint; //最近一个存储指针数据的的idr_layer结构
struct idr_layer __rcu *top; //idr的idr_layer树顶层,树的根
struct idr_layer *id_free; //指向idr_layer的空闲链表
int layers; //idr树中的idr_layer层数量
int id_free_cnt; //idr_layer空闲链表中剩余的idr_layer个数
int cur; //current pos for cyclic allocation
spinlock_t lock;
};
struct idr_layer {
int prefix; //the ID prefix of this idr_layer
DECLARE_BITMAP(bitmap, IDR_SIZE); //标记位图,标记该idr_layer的ary数组使用情况
//该数组用于保存具体的指针数据或者指向子idr_layer结构,大小为1<<8=256项
struct idr_layer __rcu *ary[1<<IDR_BITS];
int count; //ary数组使用计数
int layer; //层号
struct rcu_head rcu_head;
};
idr初始化
在start_kernel函数中调用idr_init_cache()对idr进行相应的初始化。创建一个slab cache,为后边分配idr_layer结构。
static struct kmem_cache *idr_layer_cache;
void __init idr_init_cache(void)
{
idr_layer_cache = kmem_cache_create("idr_layer_cache",sizeof(struct idr_layer), 0, SLAB_PANIC, NULL);
}
idr的使用
1.idr的初始化
(1)宏定义并且初始化一个名为name的idr:
#define DEFINE_IDR(name) struct idr name = IDR_INIT(name)
#define IDR_INIT(name) \
{ \
.lock = __SPIN_LOCK_UNLOCKED(name.lock), \
}
(2)动态初始化idr:
void idr_init(struct idr *idp)
{
memset(idp, 0, sizeof(struct idr));
spin_lock_init(&idp->lock);
}
2.分配idr的空闲idr_layer链表
static inline int __deprecated idr_pre_get(struct idr *idp, gfp_t gfp_mask)
{
return __idr_pre_get(idp, gfp_mask);
}
//注意该函数会导致睡眠,因此不应该用锁保护,函数实现如下
#define MAX_IDR_SHIFT (sizeof(int) * 8 - 1)
#define MAX_IDR_LEVEL ((MAX_IDR_SHIFT + IDR_BITS - 1) / IDR_BITS)
#define MAX_IDR_FREE (MAX_IDR_LEVEL * 2)
//32位系统下,MAX_IDR_SHIFT=31,则MAX_IDR_LEVEL=(31+8-1)/8=4,则MAX_IDR_FREE=4*2=8
int __idr_pre_get(struct idr *idp, gfp_t gfp_mask)
{
//32位系统下,MAX_IDR_FREE=8,所以idr有最多8个处于free状态的idr_layer内存空间
while (idp->id_free_cnt < MAX_IDR_FREE) {
struct idr_layer *new;
//通过slab高速缓存分配idr_layer内存空间
new = kmem_cache_zalloc(idr_layer_cache, gfp_mask);
if (new == NULL)
return (0);
//将idr_layer结构链入idr空闲可用链表中
move_to_free_list(idp, new);
}
return 1;
}
static void move_to_free_list(struct idr *idp, struct idr_layer *p)
{
unsigned long flags;
spin_lock_irqsave(&idp->lock, flags);
__move_to_free_list(idp, p);
spin_unlock_irqrestore(&idp->lock, flags);
}
static void __move_to_free_list(struct idr *idp, struct idr_layer *p)
{
//p代指新创建的id_free成员idr_layer结构。
//当idp->id_free = NULL时(刚初始化),p->ary[0] = idp->id_free = NULL。
//当idp->id_free不为NULL的时候,就表示新创建的idr_layer的ary[0]指向之前的idp->id_free指向的成员,然后再将idp->id_free指向新的成员。最终8个idr_layer都链入链表,结构如下:
/*
idp->id_free -> p8
p8->ary[0] -> p7
p7->ary[0] -> p6
...
...
p1->ary[0] -> NULL
*/
p->ary[0] = idp->id_free;
idp->id_free = p;
idp->id_free_cnt++;
}
3.分配id号并将id号和指针关联
idr有一种比较简单的理解方式,因为之前的IDR_BITS=5,现在在3.14内核中IDR_BITS=8,所以现在它就是一种256进制的数,满256,向前进一位。
假设当前我们是两层结构,top指向256叉树的根,top下面管理256个叶子层的idr_layer。叶子层idr_layer的ary数组元素是用来指向目标obj的。那么两层总共可以管理256256=65536个obj。同样道理三层可以最多管理256256*256=16M个obj。
static inline int idr_get_new(struct idr *idp, void *ptr, int *id)
{
return __idr_get_new_above(idp, ptr, 0, id);
}
//参数idp是之前通过idr_init()初始化的idr指针,或者DEFINE_IDR宏定义的指针。
//参数ptr是和ID号相关联的指针。
//参数id由内核自动分配的ID号,输出参数。
//参数start_id是起始ID号。
int __idr_get_new_above(struct idr *idp, void *ptr, int starting_id, int *id)
{
struct idr_layer *pa[MAX_IDR_LEVEL + 1];
int rv;
//在该idr的idr_layer树中分配一个合适的id,并且分配的idr_layer路径记录在pa数组中
rv = idr_get_empty_slot(idp, starting_id, pa, 0, idp);
if (rv < 0)
return rv == -ENOMEM ? -EAGAIN : rv;
//关联ptr和id
idr_fill_slot(idp, ptr, rv, pa);
*id = rv;
return 0;
}
static int idr_get_empty_slot(struct idr *idp, int starting_id,
struct idr_layer **pa, gfp_t gfp_mask,
struct idr *layer_idr)
{
struct idr_layer *p, *new;
int layers, v, id;
unsigned long flags;
id = starting_id;//starting_id=0
build_up:
//第一次申请id号时,根top指向的idr_layer为NULL
p = idp->top;
//第一次申请id号时,layers层数量idp->layers为0
layers = idp->layers;
//若top指针为NULL,则先设置top指针
if (unlikely(!p)) {
//从idr空闲idr_layer链表中获取最后一个链入链表的idr_layer结构,一般为idr_layer8
//没有的话,则重新分配一个idr_layer结构
if (!(p = idr_layer_alloc(gfp_mask, layer_idr)))
return -ENOMEM;
p->layer = 0;//指定该idr_layer层号为0
layers = 1; //layers层数量设为1,此时只有根idr_layer,即idr_layer8
}
//如果起始的id号超过该idr中设定的idr_layer层数所能设置的id号最大值,则增加idr中的idr_layer树
while (id > idr_max(layers)) {
layers++;//idr层数加1
//count为0,表示该idr_layer结构没有子节点???
if (!p->count) {
/* special case: if the tree is currently empty,
* then we grow the tree by moving the top node upwards.
*/
p->layer++;
WARN_ON_ONCE(p->prefix);
continue;
}
//从layer_idr的空闲链表中分配一个idr_layer结构,或者从内存中分配一个idr_layer结构
if (!(new = idr_layer_alloc(gfp_mask, layer_idr))) {
//若分配失败,top指针指向的idr_layer结构全部要重新初始化,并移到idr的free链表中,返回错误码
spin_lock_irqsave(&idp->lock, flags);
for (new = p; p && p != idp->top; new = p) {
p = p->ary[0];
new->ary[0] = NULL;
new->count = 0;
bitmap_clear(new->bitmap, 0, IDR_SIZE);
__move_to_free_list(idp, new);
}
spin_unlock_irqrestore(&idp->lock, flags);
return -ENOMEM;
}
//新分配的new节点链入top所指向的idr_layer链表中,变成p的父节点
new->ary[0] = p;
//count设为1表示有一个子节点,即ary数组的使用计数
new->count = 1;
//设置层号
new->layer = layers-1;
new->prefix = id & idr_layer_prefix_mask(new->layer);
//如果p的位图满,则设置p的父节点new的位图第0位为1,因为new的ary数组0项指向p
if (bitmap_full(p->bitmap, IDR_SIZE))
__set_bit(0, new->bitmap);
//设置p指向新加入的idr_layer节点
p = new;
}
//设置根top指针
rcu_assign_pointer(idp->top, p);
//设置更新idr->layers层数量
idp->layers = layers;
//从idr的top指针指向的idr_layer树中获得id号,分配路径记录在pa数组中
v = sub_alloc(idp, &id, pa, gfp_mask, layer_idr);
if (v == -EAGAIN)
goto build_up;
return(v);
}
static struct idr_layer *idr_layer_alloc(gfp_t gfp_mask, struct idr *layer_idr)
{
struct idr_layer *new;
//从idr空闲idr_layer链表中获取第一个idr_layer
if (layer_idr)
return get_from_free_list(layer_idr);
//如果idr空闲idr_layer链表中已经没有idr_layer结构,则通过slab高速缓存分配一个idr_layer结构返回
new = kmem_cache_zalloc(idr_layer_cache, gfp_mask | __GFP_NOWARN);
if (new)
return new;
//如果上边内存分配失败,则从idr_preload_head数组中分配一个可用的idr_layer结构,参考idr_preload()
if (!in_interrupt()) {//不能在中断上下文中,要在进程上下文中
//禁止内核强占
preempt_disable();
//从idr_preload_head数组分配一个idr_layer结构
new = __this_cpu_read(idr_preload_head);
if (new) {
//将idr_preload_head指向下一个idr_layer结构
__this_cpu_write(idr_preload_head, new->ary[0]);
//递减计数
__this_cpu_dec(idr_preload_cnt);
//将new从链表中删除
new->ary[0] = NULL;
}
//使能内核抢占
preempt_enable();
if (new)
return new;
}
//若上边分配均失败,则再次尝试从slab高速缓存分配idr_layer结构
return kmem_cache_zalloc(idr_layer_cache, gfp_mask);
}
static struct idr_layer *get_from_free_list(struct idr *idp)
{
struct idr_layer *p;
unsigned long flags;
spin_lock_irqsave(&idp->lock, flags);
//从idr的free链表获取一个空闲idr_layer
if ((p = idp->id_free)) {
idp->id_free = p->ary[0];//idr空闲链表指针指向第二个idr_layer
idp->id_free_cnt--;//idr的空闲idr_layer个数减1
p->ary[0] = NULL;//将该idr_layer从id_free链表中删除
}
spin_unlock_irqrestore(&idp->lock, flags);
return(p);
}
static int idr_max(int layers)
{
//取layers*8和31的小值
//layers小于4层时,id取值可达到2^(layers*8)-1
//layers大于等于4层时,id取值最大取值设置为2^31-1
int bits = min_t(int, layers * IDR_BITS, MAX_IDR_SHIFT);
return (1 << bits) - 1;
}
static int sub_alloc(struct idr *idp, int *starting_id, struct idr_layer **pa,
gfp_t gfp_mask, struct idr *layer_idr)
{
int n, m, sh;
struct idr_layer *p, *new;
int l, id, oid;
id = *starting_id;//起始id号为0
restart:
//找到idr的根top指向的idr_layer
p = idp->top;
//idr中的layers层数量
l = idp->layers;
pa[l--] = NULL;
while (1) {
//n=(id>>8*l) & 0xFF,计算对应的n值,为该layer中的哪个位置。
//若idr中只有1层idr_layer的话,则n值范围为0~255
n = (id >> (IDR_BITS*l)) & IDR_MASK;
//从位图中的第n位开始,查找第一个不为0的位,表示该位可用,为1的位表示已经被使用
m = find_next_zero_bit(p->bitmap, IDR_SIZE, n);
//如果找到的空闲位置m等于IDR_SIZE(即256),表示该idr_layer的位图已经满了,
//如果该idr_layer有子节点,并且对应该子节点的bit也为1了,表示该子节点的位图也满了,
//则需要为该idr增加idr_layer结构
if (m == IDR_SIZE) {
l++;//层数递加
oid = id;
//重新计算id,该id为被增长之后的新值,即新值根据层数右移8*l位
id = (id | ((1 << (IDR_BITS * l)) - 1)) + 1;
//如果重新计算过的id值,大于目前idr中的idr_layer层数所能设置的最大id值
//则说明该idr不能分配id值了,需要增加idr中的idr_layer层数,出错返回
if (id >= 1 << (idp->layers * IDR_BITS)) {
*starting_id = id;
return -EAGAIN;
}
p = pa[l];
BUG_ON(!p);
//If we need to go up one layer, continue the loop; otherwise, restart from the top.
sh = IDR_BITS * (l + 1);
if (oid >> sh == id >> sh)
continue;
else
goto restart;
}
//期望的n值被占用,但可找到可用的m值,重新计算id值
//示例:如果id=0x0A01,则0x0A=10代表第一级的idr_layer的ary数组的索引,0x01代表下一级的ary数组索引,最终ptr数据指针就保存在下一级的ary[0x01]处。
if (m != n) {
sh = IDR_BITS*l;
id = ((id >> sh) ^ n ^ m) << sh;
}
//id超过所能分配的最大值(1 << 31)或者小于0,则出错返回
if ((id >= MAX_IDR_BIT) || (id < 0))
return -ENOSPC;
//一层层循环计算直到到达叶子节点处l才为0,然后才跳出循环
if (l == 0)
break;
//p的叶子节点m为空
if (!p->ary[m]) {
//从idr空闲链表取出一个idr_layer结构,没有则重新分配一个idr_layer结构
new = idr_layer_alloc(gfp_mask, layer_idr);
if (!new)
return -ENOMEM;
new->layer = l-1;//设置新节点的所在层数
new->prefix = id & idr_layer_prefix_mask(new->layer);
rcu_assign_pointer(p->ary[m], new);//父节点p的叶子m指向new
p->count++;//父节点p的使用计数加1,即表示有多少个字节点
}
pa[l--] = p;//将中间的节点存入pa对应的数组中
p = p->ary[m];//p指向下一个叶子节点
}
//执行到这里,l=0。p指向最终的叶子节点。pa数组记录id存放在idr的idr_layer树路径,最终要存放id的idr_layer叶子节点存放在pa[0]中。
//p为最终要存放数据指针ptr的idr_layer,存入pa[0]数组中,后边会在该idr_layer的[id & IDR_MASK]处存放数据指针ptr
pa[l] = p;
return id;
}
static void idr_fill_slot(struct idr *idr, void *ptr, int id,struct idr_layer **pa)
{
//pa数组记录id存放在idr的idr_layer树路径,最终要存放id的idr_layer叶子节点存放在pa[0]中。
//将pa[0]存储的idr_layer结构存入hint域,用于下次快速查找,相当与cache。
rcu_assign_pointer(idr->hint, pa[0]);
//将数据指针地址存入查找到的idr_layer叶子节点的ary数组的[id&IDR_MASK]处
rcu_assign_pointer(pa[0]->ary[id & IDR_MASK], (struct idr_layer *)ptr);
//该idr_layer结构的使用计数加1
pa[0]->count++;
//标志该节点已被使用的bitmap位
idr_mark_full(pa, id);
}
static void idr_mark_full(struct idr_layer **pa, int id)
{
struct idr_layer *p = pa[0];
int l = 0;
//根据id设置该idr_layer的位图,在该位图的第id位设为1
__set_bit(id & IDR_MASK, p->bitmap);
//若该idr_layer的整个位图为满,则标志该idr_layer的父节点对应的位为1
while (bitmap_full(p->bitmap, IDR_SIZE)) {
//找到该idr_layer的父节点
if (!(p = pa[++l]))
break;
//因为是该idr_layer的父节点,所以id对应的父节点应该右移8位,设置位图
id = id >> IDR_BITS;
__set_bit((id & IDR_MASK), p->bitmap);
}
}
4.查找id对应的指针
要想找到obj的指针,必须根据id,一路寻找到叶子层。这里假设为2层的话,若id=266,则266/256 = 1,所以从top---->top->ary[1],我们就找到了叶子节点C。266&IDR_MASK = 10,所以C的ary[10]指向管理的obj。
(1)用前面的256进制方法理解就是266 = 1*256+10,所以,top->ary[1]->ary[10]指向obj。
(2)同样我们可以求id=27对应的obj,27=0*256+27,所以top->ary[0]->ary[27]指向obj。
static inline void *idr_find(struct idr *idr, int id)
{
//hint保留上次操作过的idr_layer指针
struct idr_layer *hint = rcu_dereference_raw(idr->hint);
//比较检查是否为当前id对应的idr_layer,是的话直接从该idr_layer的ary数组返回数据
if (hint && (id & ~IDR_MASK) == hint->prefix)
return rcu_dereference_raw(hint->ary[id & IDR_MASK]);
//否则从idr树中查找
return idr_find_slowpath(idr, id);
}
void *idr_find_slowpath(struct idr *idp, int id)
{
int n;
struct idr_layer *p;
if (id < 0)
return NULL;
//找到该idr的top指针
p = rcu_dereference_raw(idp->top);
if (!p)
return NULL;
//top指向的idr_layer的层号加1,就是整个idr的idr_layer树的层数
n = (p->layer+1) * IDR_BITS;
//如果id号超过该idr中设定的idr_layer层数所能设置的id号最大值,则返回NULL
if (id > idr_max(p->layer + 1))
return NULL;
BUG_ON(n == 0);
//从树顶部top,往树叶查找,取出id对应的数组中的数据指针
//假设为两层,则id值高8位保存上一级的idr_layer的ary数组索引,低8位保存下一级的idr_layer的ary数组索引
while (n > 0 && p) {
n -= IDR_BITS;
BUG_ON(n != p->layer*IDR_BITS);
p = rcu_dereference_raw(p->ary[(id >> n) & IDR_MASK]);
}
return((void *)p);
}
5.idr_replace替换id
void *idr_replace(struct idr *idp, void *ptr, int id)
{
int n;
struct idr_layer *p, *old_p;
if (id < 0)
return ERR_PTR(-EINVAL);
//找到该idr的top指针
p = idp->top;
if (!p)
return ERR_PTR(-EINVAL);
//根据idr层数,设置对应的位数
n = (p->layer+1) * IDR_BITS;
if (id >= (1 << n))
return ERR_PTR(-EINVAL);
//从树顶部top,往树叶查找,取出id对应的数组中的数据指针
n -= IDR_BITS;
while ((n > 0) && p) {
p = p->ary[(id >> n) & IDR_MASK];
n -= IDR_BITS;
}
n = id & IDR_MASK;
if (unlikely(p == NULL || !test_bit(n, p->bitmap)))
return ERR_PTR(-ENOENT);
//对应id的ary数组,指针替换
old_p = p->ary[n];
rcu_assign_pointer(p->ary[n], ptr);
return old_p;
}
6.idr_remove/idr_remove_all移除分配的id
void idr_remove(struct idr *idp, int id)
{
struct idr_layer *p;
struct idr_layer *to_free;
if (id < 0)
return;
//释放id对应的idr_layer路径的空间
sub_remove(idp, (idp->layers - 1) * IDR_BITS, id);
if (idp->top && idp->top->count == 1 && (idp->layers > 1) && idp->top->ary[0]) {
/*
* Single child at leftmost slot: we can shrink the tree.
* This level is not needed anymore since when layers are
* inserted, they are inserted at the top of the existing
* tree.
*/
to_free = idp->top;
p = idp->top->ary[0];
rcu_assign_pointer(idp->top, p);
--idp->layers;
to_free->count = 0;
bitmap_clear(to_free->bitmap, 0, IDR_SIZE);
free_layer(idp, to_free);
}
while (idp->id_free_cnt >= MAX_IDR_FREE) {
p = get_from_free_list(idp);
/*
* Note: we don't call the rcu callback here, since the only
* layers that fall into the freelist are those that have been
* preallocated.
*/
kmem_cache_free(idr_layer_cache, p);
}
return;
}
static void sub_remove(struct idr *idp, int shift, int id)
{
struct idr_layer *p = idp->top;
struct idr_layer **pa[MAX_IDR_LEVEL + 1];
struct idr_layer ***paa = &pa[0];
struct idr_layer *to_free;
int n;
*paa = NULL;
*++paa = &idp->top;
//循环将存储id的idr_layer树路径保存在数组paa中
while ((shift > 0) && p) {
n = (id >> shift) & IDR_MASK;
__clear_bit(n, p->bitmap);
*++paa = &p->ary[n];
p = p->ary[n];
shift -= IDR_BITS;
}
//遍历paa数组,将数组中的idr_layer结构都释放掉
n = id & IDR_MASK;
if (likely(p != NULL && test_bit(n, p->bitmap))) {
__clear_bit(n, p->bitmap);
rcu_assign_pointer(p->ary[n], NULL);
to_free = NULL;
while(*paa && ! --((**paa)->count)){
if (to_free)
free_layer(idp, to_free);
to_free = **paa;
**paa-- = NULL;
}
if (!*paa)
idp->layers = 0;
if (to_free)
free_layer(idp, to_free);
} else
idr_remove_warning(id);
}
7.idr_destroy销毁空闲idr_layer链表
void idr_destroy(struct idr *idp)
{
__idr_remove_all(idp);
//遍历idr的free链表中的idr_layer结构,依次取出并释放内存空间
while (idp->id_free_cnt) {
struct idr_layer *p = get_from_free_list(idp);
kmem_cache_free(idr_layer_cache, p);
}
}
void __idr_remove_all(struct idr *idp)
{
int n, id, max;
int bt_mask;
struct idr_layer *p;
struct idr_layer *pa[MAX_IDR_LEVEL + 1];
struct idr_layer **paa = &pa[0];
n = idp->layers * IDR_BITS;
//取出idr的top指针
p = idp->top;
//top指针置为NULL
rcu_assign_pointer(idp->top, NULL);
//计算该idr中设定的idr_layer层数所能设置的id号最大值
max = idr_max(idp->layers);
id = 0;
while (id >= 0 && id <= max) {
while (n > IDR_BITS && p) {
n -= IDR_BITS;
*paa++ = p;
p = p->ary[(id >> n) & IDR_MASK];
}
bt_mask = id;
id += 1 << n;
/* Get the highest bit that the above add changed from 0->1. */
while (n < fls(id ^ bt_mask)) {
if (p)
free_layer(idp, p);
n += IDR_BITS;
p = *--paa;
}
}
idp->layers = 0;
}
结构图如下:
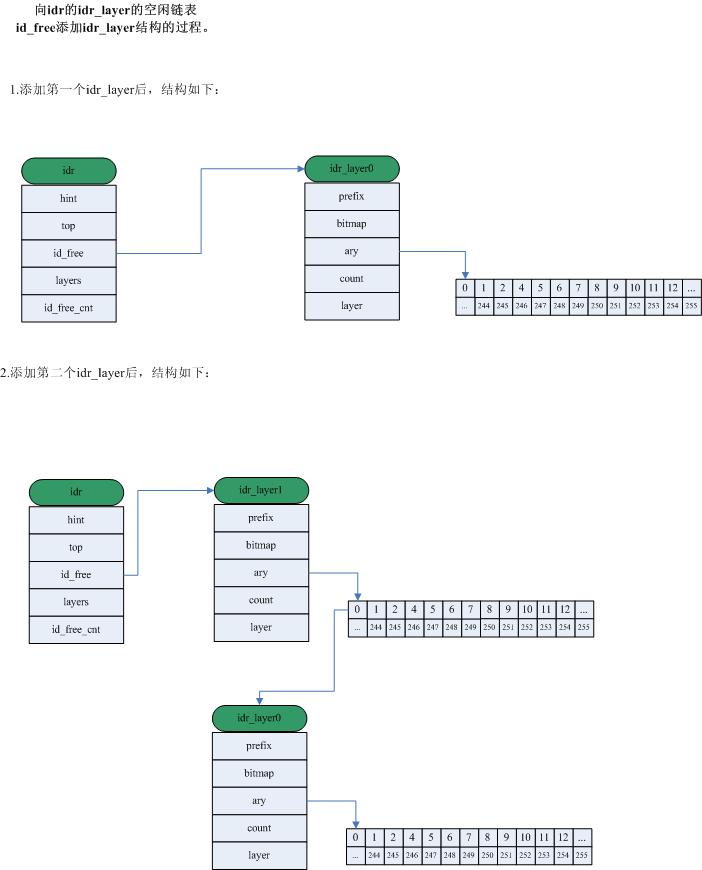
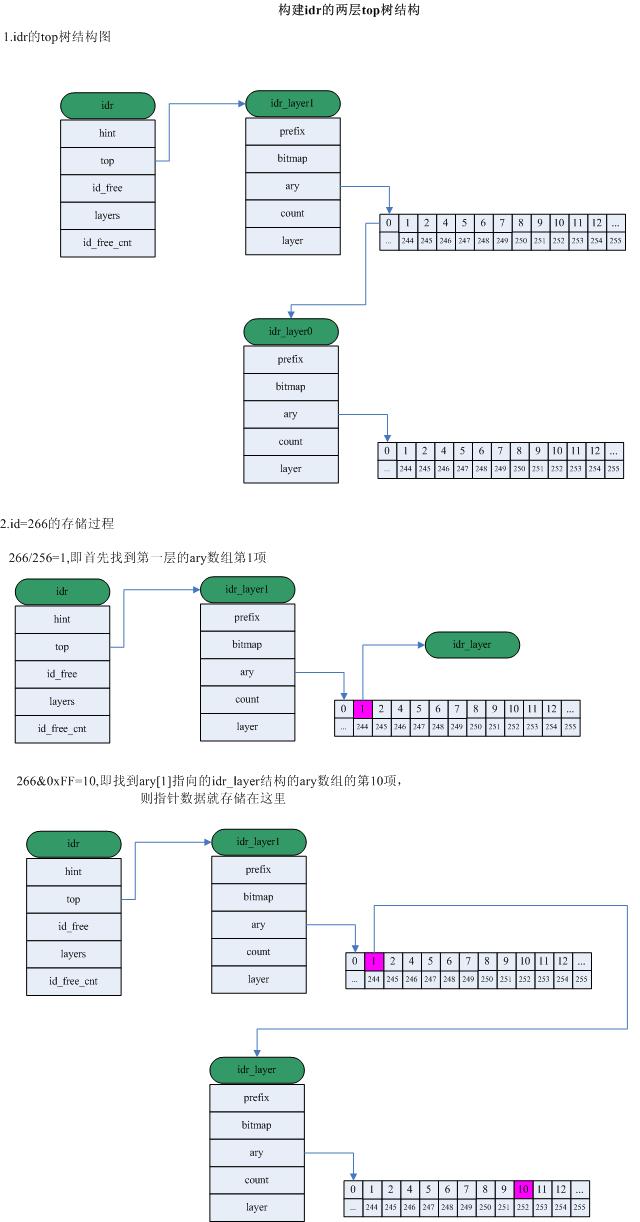
Linux中的IDR机制的更多相关文章
- 浅谈Linux中的信号处理机制(二)
首先谢谢 @小尧弟 这位朋友对我昨天夜里写的一篇<浅谈Linux中的信号处理机制(一)>的指正,之前的题目我用的“浅析”一词,给人一种要剖析内核的感觉.本人自知功力不够,尚且不能对着Lin ...
- Linux中的保护机制
Linux中的保护机制 在编写漏洞利用代码的时候,需要特别注意目标进程是否开启了NX.PIE等机制,例如存在NX的话就不能直接执行栈上的数据,存在PIE 的话各个系统调用的地址就是随机化的. 一:ca ...
- 浅析linux内核中的idr机制
idr在linux内核中指的就是整数ID管理机制,从本质上来说,这就是一种将整数ID号和特定指针关联在一起的机制.这个机制最早是在2003年2月加入内核的,当时是作为POSIX定时器的一个补丁.现在, ...
- 总结一下linux中的分段机制
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 这篇文章主要说一下linux对于分段机制的处理,虽然都说linux不使用分段机制,但是分段机制属于CPU的一个功 ...
- LINUX中的RCU机制的分析
RCU机制是Linux2.6之后提供的一种数据一致性访问的机制,从RCU(read-copy-update)的名称上看,我们就能对他的实现机制有一个大概的了解,在修改数据的时候,首先需要读取数据,然后 ...
- linux中的tasklet机制【转】
转自:http://blog.csdn.net/yasin_lee/article/details/12999099 转自: http://www.kerneltravel.net/?p=143 中断 ...
- linux中的阻塞机制及等待队列
阻塞与非阻塞是设备访问的两种方式.驱动程序需要提供阻塞(等待队列,中断)和非阻塞方式(轮询,异步通知)访问设备.在写阻塞与非阻塞的驱动程序时,经常用到等待队列. 一.阻塞与非阻塞 阻塞调用是没有获得资 ...
- linux中的阻塞机制及等待队列【转】
转自:http://www.cnblogs.com/gdk-0078/p/5172941.html 阻塞与非阻塞是设备访问的两种方式.驱动程序需要提供阻塞(等待队列,中断)和非阻塞方式(轮询,异步通知 ...
- Linux中同步互斥机制研究之原子操作
操作系统中,对共享资源的访问需要有同步互斥机制来保证其逻辑的正确性,而这一切的基础便是原子操作. | 原子操作(Atomic Operations): 原子操作从定义上理解,应当是类似原子的,不 ...
- 浅谈Linux中的信号处理机制(一)
有好些日子没有写博客了,自己想想还是不要荒废了时间,写点儿东西记录自己的成长还是百利无一害的.今天是9月17号,暑假在某家游戏公司实习了一段时间,做的事情是在Windows上用c++写一些游戏英雄技能 ...
随机推荐
- SpringBoot获取Bean的工具类
1.beanName 默认是类名首字母小写 下面的类:beanName = bean1 @Component public class Bean1 { public String getBean1() ...
- Codeforces Round 927 (Div. 3) EFG
E:Link 题意:给定长度小于 \(4 \times 10^5\) 的整数 \(n\),求从 \(0\) 到 \(n\) 各数位变化次数之和. 如:\(n = 12345\) 个位变化 \(1234 ...
- SQL——连续出现的数字
SQL三个排序函数 ROW_NUMBER().RANK().DENSE_RANK() ROW_NUMBER()不并列 连续的 RANK()分组不连续排序(跳跃排序) DENSE_RANK()并列连续 ...
- C数据结构:KMP算法详解(呕心沥血)
KMP算法 作者心声 了解暴力求解(必需会) KMP算法详解 记住我这段话(你会爱上它的)← : ①前后缀及其用处 ②求出前后缀的next数组 求出next数组的代码 开始实现KMP算法 结尾 附上源 ...
- saltstack web 平台开发
运维平台参考: https://wrapbootstrap.com/
- C 语言中的 sscanf 详解
一.函数介绍 函数原型:int sscanf(const char *str, const char *format, ...); 返 回 值:成功返回匹配成功的模式个数,失败返回 -1. RETUR ...
- MySQL慢查询及优化
最近做一个CRM系统,发现了慢查询日志里记载了许多的慢sql,于是就对其进行了sql优化.在优化的过程中,自己也归纳整理了一些sql优化的方案.今天就来和大家聊聊. **1.慢查询的分析** 常见的分 ...
- N 年前,为了学习分库分表,我把 Cobar 源码抄了一遍
10 几年前,互联网产业蓬勃发展,相比传统 IT 企业,互联网应用每天会产生海量的数据. 如何存储和分析这些数据成为了当时技术圈的痛点,彼时,分库分表解决方案应运而生. 当时最流行的 Java 技术论 ...
- objectarx acedInitGet的使用
int rc;TCHAR keyword[20]; acedInitGet(NULL, TEXT("U Y O"));rc = acedGetPoint(ptPre, L" ...
- Swoole 源码分析之 epoll 多路复用模块
首发原文链接:Swoole 源码分析之 Http Server 模块 大家好,我是码农先森. 引言 在传统的IO模型中,每个IO操作都需要创建一个单独的线程或进程来处理,这样的操作会导致系统资源的大量 ...