技本功|统计信息对SQL执行效率的影响
在一个风和日丽的下午,奋哥哥突然接到业务方线上业务数据库CPU资源告警信息,立马放下手里的枸杞登录业务方阿里云控制台查看具体问题。
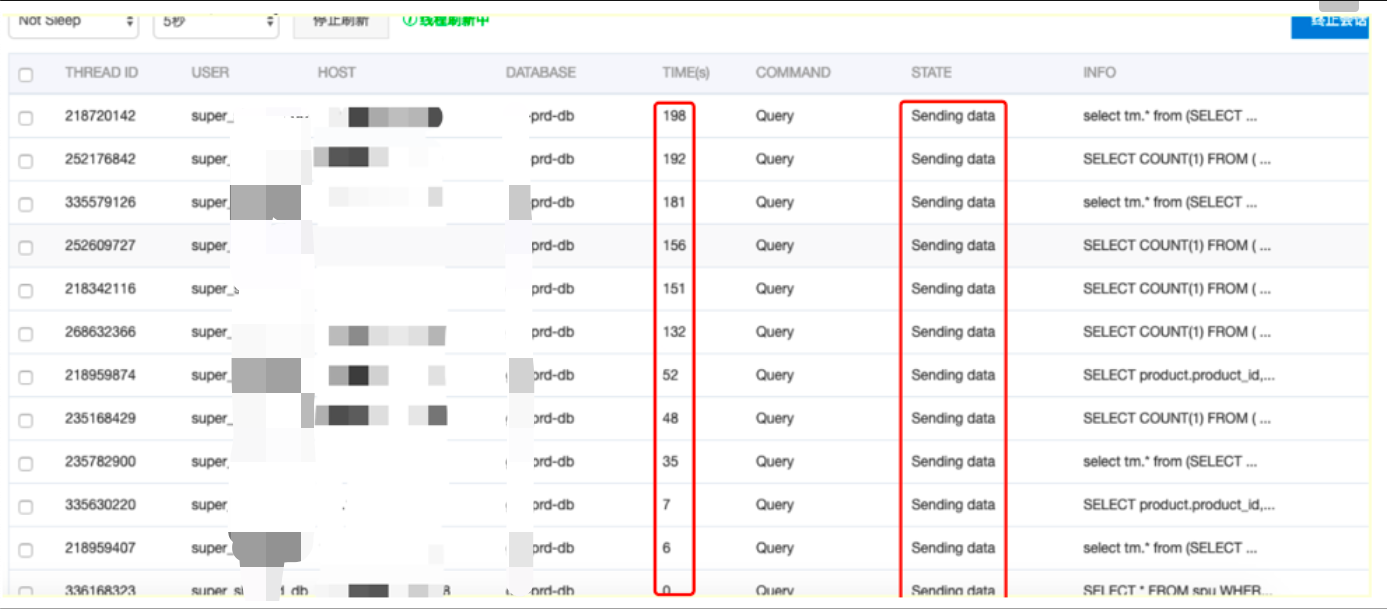
对于数据库当前正在发生中的问题,我们首先从数据库实时会话信息中尝试抓取有效信息,可以看到该告警实例的会话已经出现堆积状态,大量会话处于"Sending data"状态且从TIME字段可以看到这些会话长时间执行未结束。会话长时间执行表示当前会话一直占用的数据库资源未释放,且堆积会话基本为同一类型的业务SQL,这也就是导致我们数据库资源打高的问题SQL。
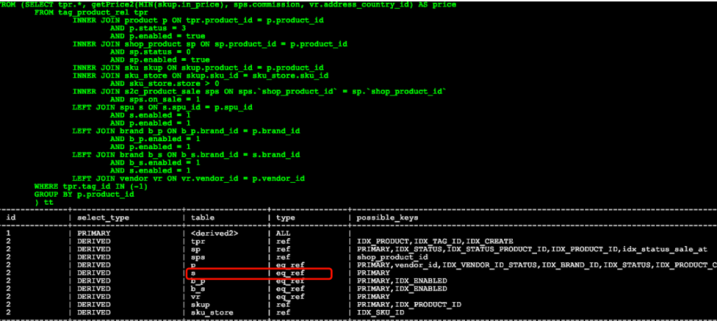
我们拎出这个问题SQL登录数据库查看SQL的执行计划,对问题SQL进行分析,从SQL执行计划中我们很明显发现一个资源消耗比较大的操作"ALL"全表扫描操作,而且比较诡异的一点是,a表进行表关联possible_keys明明是primary但是却没有使用,所以我们下一步的方向就是排查为什么表关联没有有效利用索引。

导致索引失效的问题的原因最常见的就是隐式转换,关于隐式转换我们之前的文章也做过比较详细的讲解,总体概括主要是以下几个场景:
1)传递数据类型和字段类型不一致
2)关联字段类型不一致
3)关联字段字符集不一致
4)校验规则不一致
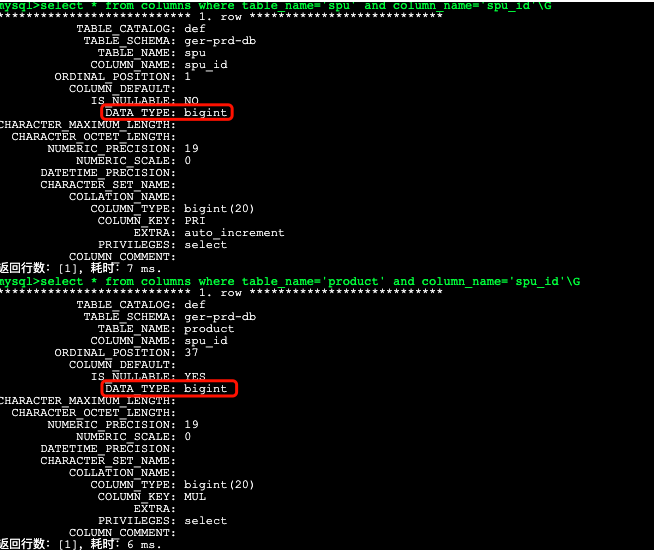
在表关联字段索引失效的情况下,可能导致索引失效的场景主要是2~4,于是我们马上查看表关联字段相关信息进行一一验证。emmmm,查询到的结果却似乎有些不尽人意,表关联字段均是bigint类型,完美的规避掉了以上所有可能。
再次陷入沉思,在没有发生隐式转换的情况下索引一般都是会有效利用的,除非MySQL优化器认为ALL全表扫描的效率并不差。我们知道,MySQL优化器会通过具体表的统计信息基于CBO进行代价计算,帮我们选择最佳执行计划。但是统计信息并不是完全精确的,某些时候可能会出现一定的误差,也正是因为统计信息的误差,就可能导致MySQL优化器错误的选择一个并不是很好的"最佳执行计划"。接下来我们就可以进一步查看表的统计信息以及hint进行验证。
表关联对应的统计信息

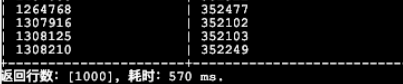
通过hint强制走primary索引观察执行计划、并测试执行效率
问题排查到这里,导致该SQL大量消耗CPU资源的原因也就水落石出了。对于业务方目前的CPU打高的情况,我们可以建议业务方先将目前堆积的会话进行Kill,避免影响其他正常的业务查询,等数据库CPU资源有所回落后,在数据库执行"analyze table"对问题表的统计信息重新采集,统计信息更新后MySQL优化器就可以正确的选择最佳执行计划。
统计信息更新:

执行计划更新:
虽然客户的问题已经处理,对于本案例还是有一些点值得我们思考:
索引失效的场景都有哪些?
隐式转换
统计信息不准确
MySQL统计信息是如何更新采集?
在MySQL中有一些参数设置决定了统计信息采集的行为方式,一般情况下不会做特别设置,我们需要正确的理解这些参数,明白统计信息只是一个统计估计值,并不是绝对精准。
统计信息相关参数
innodb_stats_method 默认nulls_equal,表示统计信息时把所有的null当作等值对待
innodb_stats_auto_recalc 是否打开自动化采集统计数据 ,默认打开,当表数据量更新10%触发重新采集统计信息
innodb_stats_on_metadata 默认关闭,若该参数开启时表示数据库执行"show table status",访问"INFORMATION_SCHEMA.TABLES or
INFORMATION_SCHEMA.STATISTICS"时,都会触发重新采集统计信息的操作
innodb_stats_persistent 统计信息是否持久化到磁盘,默认打开。持久化磁盘当数据库重新启动后可从磁盘读取。
innodb_stats_persistent_sample_pages 默认20,对于持久化存储统计信息的表,每次重新采集信息需要采集20个索引页进行分析
innodb_stats_transient_sample_pages 默认8,对于非持久化的表,其统计信息重新采集需要扫描8个索引页进行分析
MySQL几种重新采集统计信息的时机
新打开一张表时
表数据变更超过10%触发该表的统计信息重新采集
当innodb_stats_on_metadata参数打开,数据库执行"show table status",访问"INFORMATION_SCHEMA.TABLES or INFORMATION_SCHEMA.STATISTICS"时
手动执行analyze tables时
关于analyze table操作
执行该操作需要具有该表的select/insert权限
支持Innodb、Myisam、NDB存储引擎下的表,不支持视图
支持对分区表中某个分区单独执行统计分析:alter table ... analyze partition在执行analyze期间,会对该表加一个读锁。
探寻完技术的真理后,奋哥哥又拿起了曾经放下的枸杞。
技本功|统计信息对SQL执行效率的影响的更多相关文章
- Oracle数据迁移后由列的直方图统计信息引起的执行计划异常
(一)问题背景 在使用impdp进行数据导入的时候,往往在导入表和索引的统计信息的时候,速度非常慢,因此我在使用impdp进行导入时,会使用exclude=table_statistics排除表的统计 ...
- in和exists的区别与SQL执行效率
in和exists的区别与SQL执行效率最近很多论坛又开始讨论in和exists的区别与SQL执行效率的问题,本文特整理一些in和exists的区别与SQL执行效率分析 SQL中in可以分为三类: 1 ...
- in和exists的区别与SQL执行效率分析
可总结为:当子查询表比主查询表大时,用Exists:当子查询表比主查询表小时,用in SQL中in可以分为三类: 1.形如select * from t1 where f1 in ('a','b'), ...
- SQl 执行效率总结
SQL执行效率总结 1.关于SQL查询效率,100w数据,查询只要1秒,与您分享: 机器情况 p4: 2.4 内存: 1 G os: windows 2003 数据库: ms sql server 2 ...
- 收集统计信息让SQL走正确的执行计划
数据库环境:SQL SERVER 2005 今天在生产库里抓到一条跑得慢的SQL,语句不是很复杂,返回的数据才有800多行, 却执行了34分钟,甚至更久. 先看一下执行结果 我贴一下SQL. SELE ...
- 通过手动创建统计信息优化sql查询性能案例
本质原因在于:SQL Server 统计信息只包含复合索引的第一个列的信息,而不包含复合索引数据组合的信息 来源于工作中的一个实际问题, 这里是组合列数据不均匀导致查询无法预估数据行数,从而导致无法选 ...
- SQL执行效率和性能测试方法总结
对于做管理系统和分析系统的程序员,复杂SQL语句是不可避免的,面对海量数据,有时候经过优化的某一条语句,可以提高执行效率和整体运行性能.如何选择SQL语句,本文提供了两种方法,分别对多条SQL进行量化 ...
- SQL执行效率2-执行计划
以下语句可以进行SQL 语句执行时间分析,两个Go之间就是SQL查询语句 use Work--数据库名 go set statistics profile on set statistics io o ...
- [转]SQLServer SQL执行效率和性能测试方法总结
本文转自:http://www.zhixing123.cn/net/27495.html 对于做管理系统和分析系统的程序员,复杂SQL语句是不可避免的,面对海量数据,有时候经过优化的某一条语句,可以提 ...
- SQL执行效率和性能测试方法
对于做管理系统和分析系统的程序员,复杂SQL语句是不可避免的,面对海量数据,有时候经过优化的某一条语句,可以提高执行效率和整体运行性能.如何选择SQL语句,本文提供了两种方法,分别对多条SQL进行量化 ...
随机推荐
- 关于使用uniapp时Android 离线打包的注意事项
Android 离线打包 文档地址: https://nativesupport.dcloud.net.cn/AppDocs/usesdk/android 注意事项: 添加权限,需要将 uniapp ...
- ubuntu22.04 安装nginx 卸载
1.使用apt-get 安装nginx(得机器能联网才行) # 切换到root用户 # 切换到root用户 sudo -i # 更新apt源 apt-get update# 安装nginx apt-g ...
- ArcGIS将遥感影像的0值设置为NoData
本文介绍在ArcMap软件中,将栅格图层中的0值或其他指定数值作为NoData值的方法. 在处理栅格图像时,有时会发现如下图所示的情况--我们对某一个区域的栅格数据进行分类着色后,其周边区域( ...
- maven error
1 [INFO] Assembling webapp [crm9] in [/home/wukongcrm/72crm-java/target/ROOT] 2 [INFO] Processing wa ...
- CF1534C
题目简化和分析: 涉及算法:并查集. 为什么要使用并查集: 因为交换只能是列交换,并且保证不与别的重复 我们通过观察题目发现,某些列之间互为限制关系 即如果某列序列排序方式固定,则被限制的列也为固定的 ...
- 【matplotlib 实战】--气泡图
气泡图是一种多变量的统计图表,可以看作是散点图的变形.与散点图不同的是,每一个气泡都表示三个维度的数据,除了像散点图一样有X,Y轴,气泡的大小可以表示另一个维度的数据.例如,x轴表示产品销量,y轴表示 ...
- 从基础到实践,回顾Elasticsearch 向量检索发展史
本文分享自华为云社区<Elasticsearch向量检索的演进与变革:从基础到应用>,作者: 汀丶. 1.引言 向量检索已经成为现代搜索和推荐系统的核心组件. 通过将复杂的对象(例如文本. ...
- 计算机的数值转化与网络的IP地址分类与地址划分
数值转换 数字系统由来 远古时代是没有数字系统非位置化数字系统: 罗马数字 (I-1.II-2.III-3.IV-4.V-5.VI-6.VII-7.VIII-8.IX-9.X-10) 位置话数字化系统 ...
- Chromium GPU资源共享
资源共享指的是在一个 Context 中的创建的 Texture 资源可以被其他 Context 所使用.一般来讲只有相同 share group Context 创建的 Texture 才可以被共享 ...
- SQL改写案例4(开窗函数取中位数案例)
周总找我问个报表SQL实现逻辑的案例,废话不说给他看看. 原SQL: SELECT d.tname 姓名, d.spname 岗位, d.sum_cnt 报单单量, d.min_cnt 放款单量, d ...