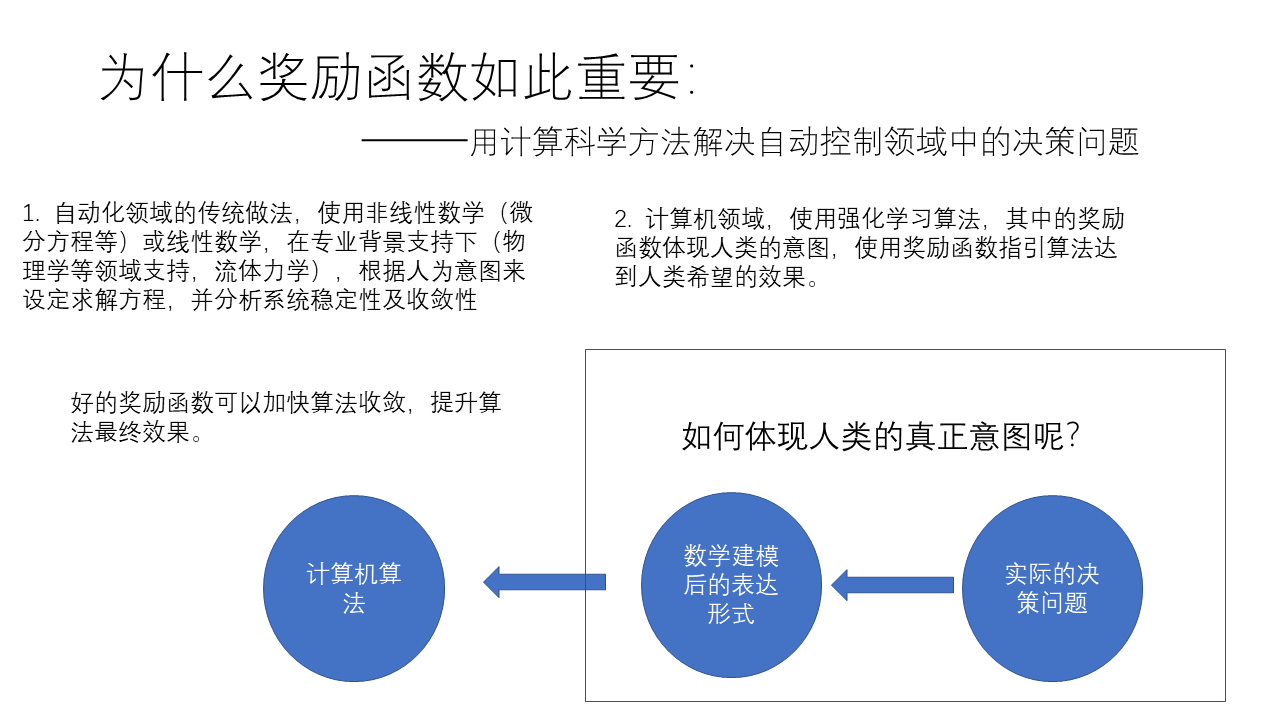
论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》的阅读——强化学习中的策略梯度算法基本形式与部分证明
最近组会汇报,由于前一阵听了中科院的教授讲解过这篇论文,于是想到以这篇论文为题做了学习汇报。论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》虽然发表的时间很早,但是确实很有影响性,属于这个领域很有里程牌的一篇论文,也是属于这个领域的研究者多少应该了解些的文章。以下给出根据自己理解做成的PPT。













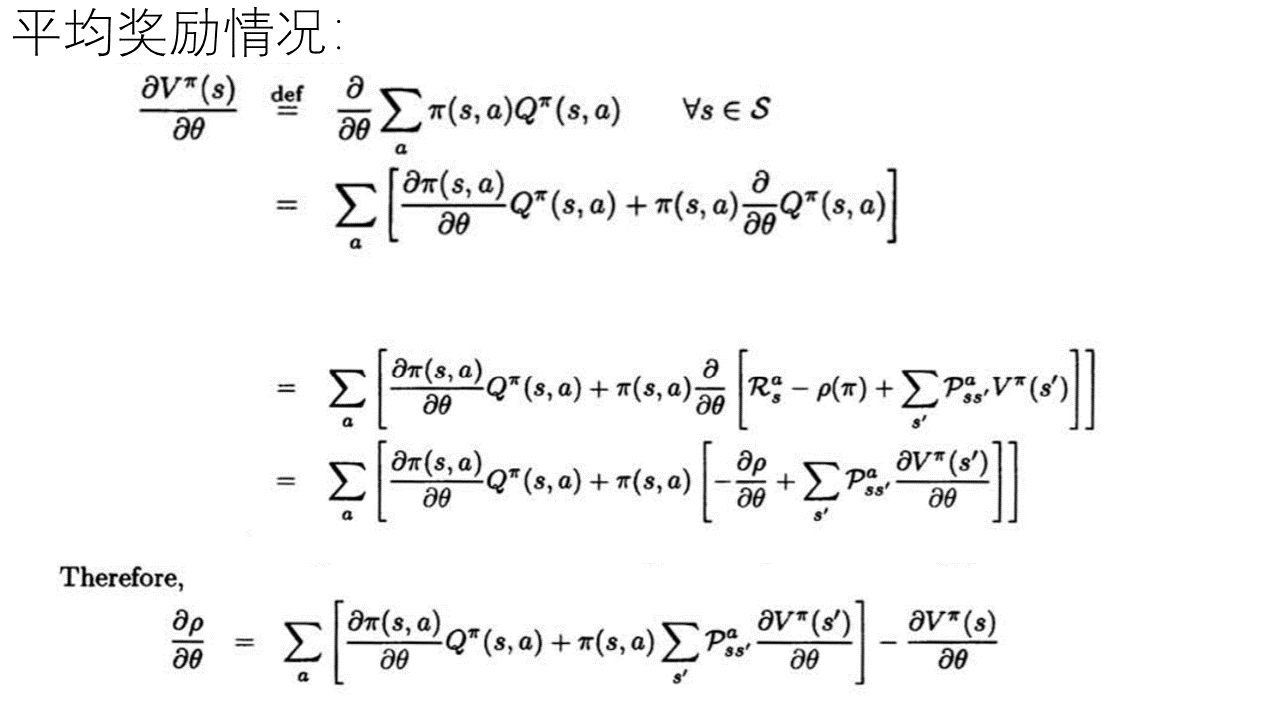









---------------------------------------------------------------------------------
后注:
其实,很多人觉得这个推导就是多此一举,这个公式和证明根本没有必要,因为这个公式本身就是显而易见的,原因如下:
已知(根据MDP及强化学习的定义有):
公式(1):
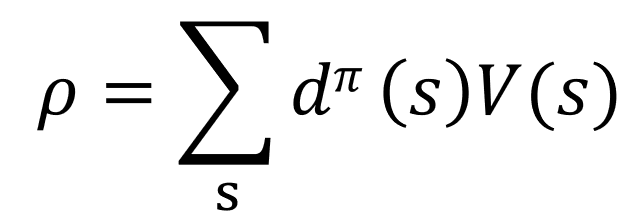
公式(2):

而上面的这篇论文通篇要做的就是下面的公式成立,并且满足逼近函数f为向量且上面的公式(4)及step_size的要求可以收敛到局部最优:
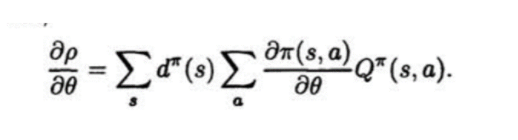
根据后注中的公式(1)和(2),不是直接就可以得到论文中的这个公式嘛,而且而这个公式必然在理想条件下收敛(对整体环境有很好的抽样的情况下),那么把Q换成逼近函数f ,不是也会收敛的嘛,又何必费力去推导最后还得到一个在多个条件下收敛到局部解的结论,这不是显而易见的事情还非得花无用功去为了推导公式而去推导公式和证明收敛的吗?
在此,回答一下 这方面的提问:
首先,要说的就是提出这个问题的人本身就忽略了下面的事情:
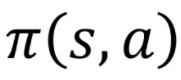 与
与 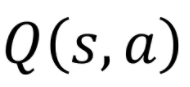 本身都是对策略依赖的,或者说这两个item本身就含有策略参数θ , 所以根本就不存在由后注中的(1),(2)公式可以推导出论文的最终公式的形式。
本身都是对策略依赖的,或者说这两个item本身就含有策略参数θ , 所以根本就不存在由后注中的(1),(2)公式可以推导出论文的最终公式的形式。
换句话说就是策略pi和Q 对策略参数θ来说都不是常数的,由此才有上面论文中的各种情况下的推导。
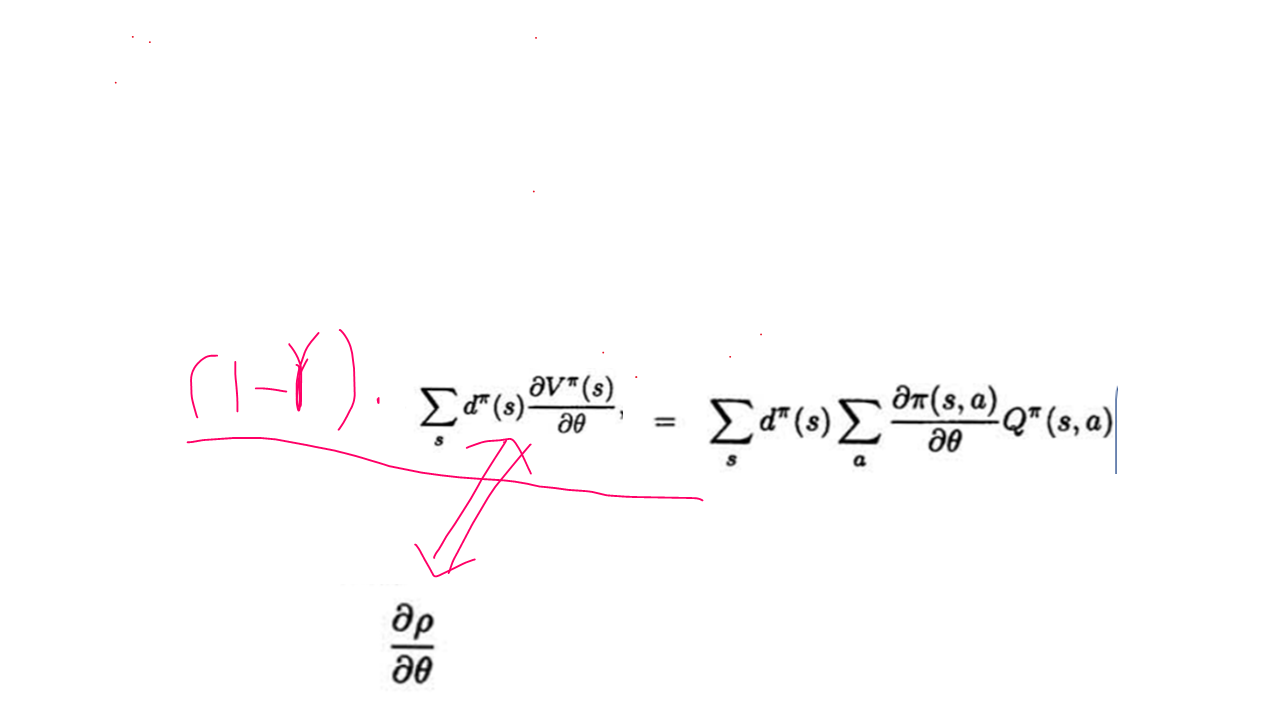
对于收敛的问题:
虽然我们可以知道在完全抽样的情况下策略梯度用策略和Q来表示是收敛的,都是实际Q并不知道,我们需要用函数近似和采样的方法来获得,而在这样的整个动态的学习过程中即要优化策略梯度的参数,又要优化近似函数f的参数,而这样的情况下是否收敛却并不知道的。
如果在某个学习过程中 近似函数f 对 Q值的估计 过程收敛到局部最优,则有论文中的公式 (3), 而在近似值函数f 和 策略函数pi 满足论文中的公式(4),则有论文中的公式(5),(6), 在有对step_size的限制下才有 满足以上条件的值函数近似策略梯度算法收敛都局部最优的结论。
---------------------------------------
论文《policy-gradient-methods-for-reinforcement-learning-with-function-approximation 》的阅读——强化学习中的策略梯度算法基本形式与部分证明的更多相关文章
- 《DRN: A Deep Reinforcement Learning Framework for News Recommendation》强化学习推荐系统
摘要 新闻推荐系统中,新闻具有很强的动态特征(dynamic nature of news features),目前一些模型已经考虑到了动态特征. 一:他们只处理了当前的奖励(ctr);. 二:有一些 ...
- [Reinforcement Learning] Value Function Approximation
为什么需要值函数近似? 之前我们提到过各种计算值函数的方法,比如对于 MDP 已知的问题可以使用 Bellman 期望方程求得值函数:对于 MDP 未知的情况,可以通过 MC 以及 TD 方法来获得值 ...
- Ⅶ. Policy Gradient Methods
Dictum: Life is just a series of trying to make up your mind. -- T. Fuller 不同于近似价值函数并以此计算确定性的策略的基于价 ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- 论文翻译--StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning
(缺少一些公式的图或者效果图,评论区有惊喜) (个人学习这篇论文时进行的翻译[谷歌翻译,你懂的],如有侵权等,请告知) StarCraft Micromanagement with Reinforce ...
- [Reinforcement Learning] Policy Gradient Methods
上一篇博文的内容整理了我们如何去近似价值函数或者是动作价值函数的方法: \[ V_{\theta}(s)\approx V^{\pi}(s) \\ Q_{\theta}(s)\approx Q^{\p ...
- 强化学习七 - Policy Gradient Methods
一.前言 之前我们讨论的所有问题都是先学习action value,再根据action value 来选择action(无论是根据greedy policy选择使得action value 最大的ac ...
- DRL之:策略梯度方法 (Policy Gradient Methods)
DRL 教材 Chpater 11 --- 策略梯度方法(Policy Gradient Methods) 前面介绍了很多关于 state or state-action pairs 方面的知识,为了 ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
- 论文选读一: Towards end-to-end reinforcement learning of dialogue agents for information access
Towards end-to-end reinforcement learning of dialogue agents for information access KB-InfoBot 与知识库交 ...
随机推荐
- redis 远程连接
redis-cli -h host -p port -a password -h 服务器地址 -p 端口号 -a 密码
- 夜莺项目发布 v6.1.0 版本,增强可观测性数据串联
大家好,夜莺项目发布 v6.1.0 版本,这是一个中版本迭代,不止是 bugfix 了,而是引入了既有功能的增强.具体增强了什么功能,下面一一介绍. 1. 增强可观测性数据串联 从 v6.1.0 开始 ...
- javascript class 方法的this指向问题
踩坑记录 JavaScript 的 class 里面有两种定义方法的方式 普通函数(fun1) 箭头函数(fun2) class Obj { func1() { // write some code. ...
- spring mvc GET请求方式及传参
spring mvc GET请求方式及传参 @Api(tags = "管理接口") @Slf4j @RestController @RequestMapping("/my ...
- xxlJob端口号及故障转移设置,解决负载均衡调度任务执行
xxlJob端口号及故障转移设置,解决负载均衡调度任务执行 my.xxljob.executorPort = 1162 my.xxljob.executorAppName = myService-jo ...
- 2024-06-19:用go语言,给定一个起始下标为 0 的整数数组 nums 和一个整数 k, 可以执行一个操作将相邻两个元素按位AND后替换为结果。 要求在最多执行 k 次操作的情况下, 计算数组
2024-06-19:用go语言,给定一个起始下标为 0 的整数数组 nums 和一个整数 k, 可以执行一个操作将相邻两个元素按位AND后替换为结果. 要求在最多执行 k 次操作的情况下, 计算数组 ...
- 从 Docker Hub 拉取镜像受阻?这些解决方案帮你轻松应对
最近一段时间 Docker 镜像一直是 Pull 不下来的状态,感觉除了挂,想直连 Docker Hub 是几乎不可能的.更糟糕的是,很多原本可靠的国内镜像站,例如一些大厂和高校运营的,也陆续关停了, ...
- MySql用户与权限控制
MySql用户与权限控制 -- 刷新权限命令 # -- 刷新mysql权限命令 flush privileges; 用户管理 1.查看用户 #查看用户 USE mysql; SELECT host,u ...
- 微信小程序自动化分析_包含执行设备及对应的微信版本
背景介绍: 微信小程序是基于腾讯自研 X5 内核,不是谷歌原生 webview. 实现方式: 1.小程序自动化sdk,使用自动化sdk,需要有小程序的开发者权限,以及参考的资料较少,2.选择采用app ...
- [ABC347C] Ideal Holidays题解
[ABC347C] Ideal Holidays题解 原题传送门 原题传送门(洛谷) 题意翻译: 在 \(AtCoder\) 王国中,一个周有 \(A+B\) 天.其中在一周中, \([1,A ...