Elasticsearch生态&技术峰会 | 阿里云Elasticsearch云原生内核
简介: 开源最大的特征就是开放性,云生态则让开源技术更具开放性与创造性,Elastic 与阿里云的合作正是开源与云生态共生共荣的典范。值此合作三周年之际,我们邀请业界资深人士相聚云端,共话云上Elasticsearch生态与技术的未来。
开源最大的特征就是开放性,云生态则让开源技术更具开放性与创造性,Elastic 与阿里云的合作正是开源与云生态共生共荣的典范。值此合作三周年之际,我们邀请业界资深人士相聚云端,共话云上Elasticsearch生态与技术的未来。

本篇内容是阿里巴巴集团技术专家魏子珺带来的阿里云Elasticsearch云原生内核
分享人:阿里巴巴集团技术专家魏子珺
视频地址:https://developer.aliyun.com/live/246150
关于阿里云Elasticsearch云原生内核,本文将通过三个部分展开介绍:
- 阿里云Elasticsearch内核概览
- 云原生Elasticsearch定义
- 阿里云原生Elasticsearch实践
一、阿里云Elasticsearch内核概览
(一)阿里云ES的优势
下面这个对比图可以很好地说明阿里云ES相比开源ES 的优势。

先看内圈,开源ES针对通用硬件设施,而阿里云ES内核则是针对阿里云基础设施深度定制的内核,可以最大地发挥阿里云基础设施的性能,以及成本方面的优势。然后,看最外圈,开源ES内核为了适应ES丰富的使用场景包括搜索,可观察性等,无法做到功能和性能兼顾,而阿里云ES内核依托于阿里云ES的服务可以做很多场景化的优化和功能增强,在搜索和观察性等方面会比自建的ES更有优势。内核在中圈,向下运行在阿里云基础设施,向上依托于阿里云ES服务。可以看到,阿里云ES内核相比开源ES自建集群,不论在成本、性能、稳定性和功能上都会更具优势。
(二) 基于用户需求的内核建设
用户对阿里云ES内核的需求,主要是以下三个方面:
1、简单
存储容量能够不断扩充,计算有足够的弹性,用户不需要操心资源的问题。
2、好用
开箱即用,不用进行一系列复杂的部署和配置,直接根据场景提供最优的配置即可,还要有丰富的检索功能可以使用。
3、性价比
阿里云ES做到价格足够低,性能足够好,足够稳定。
结合上述的需求,我们从下面四个方面展开内核建设。

1、成本节约
第一,我们提供计算存储分离的增强版ES,成本上节省了副本的开销,保证足够的弹性,可按需使用。第二,支持冷热分离,成本更低地存储介质。第三,Indexing Service,这是我们全新发布的产品,对写多读少的场景有很大的成本节约。第四,索引数据压缩,我们新增的压缩算法可以比默认的压缩方式提升45%的压缩率。
2、性能优化
第一,我们研发的ElasticBuild相比在线的写入能有三倍的性能提升。第二,我们还研发了物理复制功能,从最早支持计算存储分离到现在的支持通用版的ES,物理复制通过segment同步而不是request同步的方式,减少了副本的写入开销,所以有一个副本的情况下,写入性能能有45%左右的性能提升,副本越多,提升越明显。第三,bulk聚合插件,在协调节点聚合下载的数据,降低分布式的长尾效应,在写入吞吐高、分辨数多的场景写入吞吐能有20%以上的性能提升。第四,时序查询优化,针对range查询,可以直接跳过不在range范围内的segment,结合时序策略可以获得更好的查询性能提升。
3、稳定性提升
第一,我们研发了集群限流插件,能够实现索引,节点,集群级别的读写限流,在关键时刻对指定的索引降级,将流量控制在合适的范围内。第二,慢查询隔离池的特性,它避免了异常查询消耗资源过高导致集群异常的问题。第三,协调节点流控插件,它集成了淘宝搜索核心的流控能力,针对分布式环境中偶发节点异常导致的查询抖动,能够做到秒级切流,最大程度降低业务抖动概率,保证业务平稳地运行。第四,monitor插件,它采集了集群多维度的指标,可以提供全方位的监控。
4、功能增强
第一,向量检索插件,是基于阿里巴巴达摩院Proxima向量检索库实现,能够帮助用户快速地实现图像搜索、视频指纹采样、人脸识别、语音识别等等场景的需求。第二,阿里NLP的分词插件,它是基于阿里巴巴达摩院提供的阿里NLP的分词技术,支持阿里内部包括淘宝搜索、优酷、口碑等业务,提供了近1G的海量词库。 第三,OSS的Snapshot插件,它支持使用阿里云OSS的对象存储来保存ES的Snapshot。 第四,场景化的推荐模板,可以针对不同的业务场景提供成本、性能的优化。
以上的这些特性都能在我们阿里云ES官方文档中看到,欢迎大家使用。
二、云原生ES的定义
(一)云原生Elasticsearch如何定义
首先看一下什么是云原生。阿里巴巴云原生公众号前段时间推出了一篇文章《什么是真正的云原生》,总结了云原生的定义:第一,弹性、API自动化部署和运维;第二,服务化云原生产品;第三,因云而生的软硬一体化架构。

上图是云原生架构的白皮书封面,这是由阿里云二十位云原生技术专家共同编写,已经正式对外发布,欢迎大家阅读。
那么,什么是云原生ES?
- ES的云服务,开箱即用,能用API自动化部署和运维
- 计算存储分离,弹性可伸缩
- 能充分利用云基础设施,网络、存储和算力等
以上三点就能对应最开始提到的三个圈: 服务,内核,和基础设施,这样才是云原生ES。
(二)云原生 Elasticsearch如何设计

第一,它必须是计算存储分离的架构,这样才能提供更加弹性的计算能力和无限的存储空间。第二,可以支持冷热分离,冷热的节点都要是计算存储分离的架构。冷节点使用高性价比的对象存储,相比热节点可以有90%的成本节约。第三,Serverless的用户真正关心的是索引的使用,而不是ES集群的维护。Serverless让用户的关注点从集群的维度可以下沉到索引维度。
(三)云原生Elasticsearch内核挑战
实现这样的云原生内核,挑战是非常大的,主要的挑战分为下面三个方面:
1、热节点的分布式文件系统
第一,分布式文件系统自身的稳定性保证,ES对Latency非常敏感,它提供性能和稳定性与本地盘相当的分布式文件系统,这个挑战本身就非常大。第二,ES在实现一写多读时,如何防止出现多写的情况。ES数据是在内存,读写需要的内存状态数据、数据是如何保持一致性的,这些都是很大的挑战。
2、冷节点的对象存储
对象存储提供的是HTTP接口,所以需要去适配。另外,对象存储的单次IO Latency非常高,所以只有在冷节点相对Latency不敏感的场景才有机会使用。如何解决Latency最高的问题也是很有挑战。最后是对象存储无法使用到操作系统的pagecache和预读能力,所以要用对象存储,这些能力必须在ES侧实现。
3、Serverless
最难解决的就是多租户的共享和隔离的平衡问题,如果不同索引直接产生相互的影响,在云上是不可接受的。如果不共享,就意味着资源无法充分利用。如何平衡共享和隔离的问题,这是Serverless最大的挑战。 第二是体验,基于索引的使用如何提供和云原生ES一样的体验也是需要考虑的问题。 第三是资源监控,如何评估索引的使用资源也是一个挑战。
三、阿里云原生Elasticsearch实践
1、计算存储分离
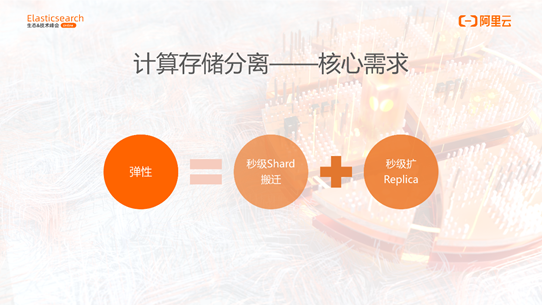
计算存储分离核心的诉求是弹性,它不只是像云原生ES那样支持动态的添加节点、自动Shard搬迁,而是彻底的弹性。对于ES来说,它的核心诉求是两点:Shard秒级搬迁和Replication秒级增加。这样才能解决热点的问题,和高低峰快速的动态扩容的问题。如果扩缩容还要迁移Shard的数据,弹性是不够的。彻底的弹性一定是Shard搬迁,Replication扩充,数据是不动的,只是调整DataNode对Shard的映射。要实现这样的弹性,就必须做到计算存储分离。
阿里云对ES存储分离内核的实现如下:
- 数据存储在分布式文件系统上,由分布式文件系统保证数据的可靠性
- 同一个Shard的多个副本数据只保存一份
- 一写多读的场景,这样就不再依赖于ES自身的replication,可以减少写入的开销。
- 索引扩Shard,无需复制数据,秒级增加只读Shard
- Shard搬迁无需迁移数据,秒级切换DataNode
核心技术之一:内存物理复制,实现replica的近实时访问
Segment同步的实现细节:
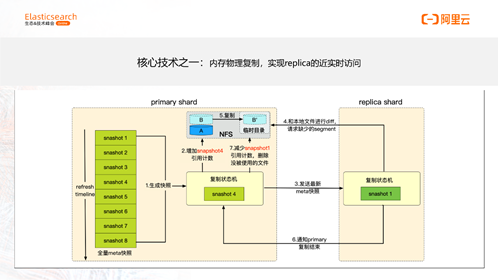
图中描述的是ES物理复制的状态机,核心是为了解决segment同步乱序的问题。通用的物理复制功能也是一样的实现,主要区别在于计算存储分离只需要复制实时生成的segment,对于后续产生的segment,强制提交commit,确保segment落盘,来防止大的segment进行复制。而通用的物理复制,外界的segment也是需要复制的,这种segment往往会比较大。所以这里有一个关键的优化,为了防止大segment复制导致的主从可见性差距过大,主shard在从shard复制完成后才会打开最新的segment。
下图介绍了物理复制保证数据一致性的方式。
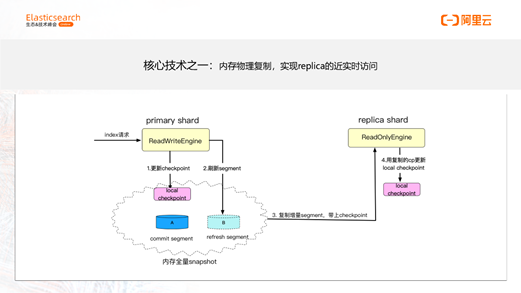
核心是保证checkpoint的一致性,通过将主shard的checkpoint同步到从shard来实现。结合这张图可以看下流程,当数据写进来的时候,主shard会更新checkpoint,在第二步刷新segment时,第三步将segment复制到从shard时,会带上checkpoint,第四步从shard会用这个checkpoint更新自己的local checkpoint来保证主从shard使用了相同的checkpoint,这样就实现了数据一致性的保证。
核心技术之二:两阶段IO fence
核心要解决的问题是防止多写。通过分布式文件系统的管控侧将异常节点加入黑名单,直接从根本上防止了异常节点的显露。
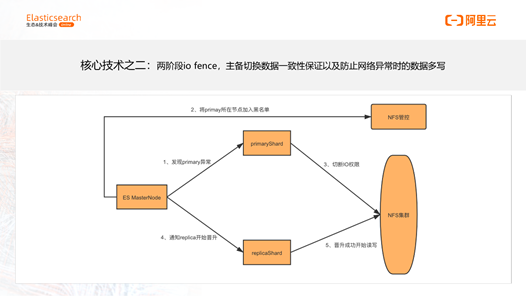
上图展示了整体的流程,在主Shard节点异常的时候,MasterNode 首先发现主Shard的异常,然后将主Shard所在的节点加入黑名单。第三步,这个节点切断了IO的权限,彻底失去了写的能力。第四步,master通知从Shard晋升成主Shard。第五步,从Shard晋升成主Shard后,就开始正常地读写数据。
我们的计算存储分离的架构通过阿里云增强版进行售卖。计算存储分离除了弹性的特点外,由于一写多读的特点,在性能、成本上都有显著的提升。我们测试了线上阿里云增强版ES和原生ES在同样规格配置的性能对比情况,从表格的最右一列红色的标识可以看到,不论在translog同步还是异步的场景,一个副本的情况下,性能都有超过百分之百的提升,副本越多,性能提升越明显。
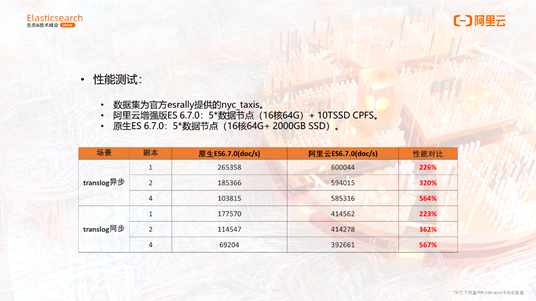
总结一下计算存储分离的特点:首先它是秒级弹性扩缩容;第二,由于不写副本,所以写入性能能有100%的提升;第三,由于多个副本存储一份数据,所以存储成本呈倍数降低。
计算存储分离——热节点
想要使用我们计算存储分离的ES集群,可以选择图中所示的日志增强版,欢迎大家使用。

计算存储分离——冷节点
热节点通过分布式文件系统实现了计算存储的分离,冷节点也需要实现计算存储分离才能实现弹性。冷节点这部分我们还在研发阶段,所以这次分享给大家的是一些思考的内容。

冷节点的成本是第一要素,所以对象存储成了首选。对象存储相比分布式文件系统和块存储等特点非常鲜明。劣势,大都在挑战中提及到,这些劣势相比其他存储,无论从易用性和性能上都无法跟分布式文件系统和块存储相比,所以这些热节点很难直接使用对象存储。但是冷节点不同,冷节点核心考虑的是成本,因此它也有一些优势。它的成本比SSD云盘便宜近90%,可以真正的按需使用,不用预先准备存储空间。另外可以提供12个9的可靠性,所以也可以不用存储副本,这又是一半以上的成本节约。基于这些优势,对象存储成了最好的选择。
如何最大减少它的劣势带来的影响,这要从ES的特点说起。ES在可观察性、安全的方向上,冷热数据明显,日志长期存在SSD上成本过高,所以可以考虑冷热架构。第二,ES在search的时候很消耗CPU,因此可以利用计算时异步地扒取对象存储的数据,减少IO等待的时间。第三点是冷数据基本上无写入,所以对写入性能要求也不高。以上的三点就是ES冷数据使用对象存储的原因。
Indexing Service
Indexing service是我们即将重量级发布的新产品,这是我们在serverless尝试的一个产品,是针对写入方面的性能优化。相比查询的多样性,写入会相对简洁明了。Indexing service,从功能方面,提供了写入托管服务,满足高并发持续数据写入,降低了业务集群的CPU开销,它适用在日志、监控、APM等时序场景,它解决的最大痛点是写多读少,而且很多时序场景下写远多与读,业务需要消耗大量的节点资源来满足写入。Indexing service 可以极大的降低这部分场景的成本开销。
Indexing service 有以下三个方面的特点:
1、完全兼容原生的 API
2、按量付费,按写入吞吐和QPS实际需求付费
3、写入能力可秒级快速弹性扩缩
下图展示了Indexing service是如何实现的:

1、第一,请求转发,请求发到用户ES集群,用户使用云原生API操作ES,ES内核会将开启托管的索引写入请求,转发到Indexing Service。这里可以展开再缩小,对于不再写入的索引,用户就可以取消协助托管,释放存储成本。Indexing service结合Data stream和over功能可以有非常好的用户体验,因为新生成了索引后,老索引就不再写入。我们在内核上做了优化,在生成新索引的时候就会自动取消托管。
2、第二步,在写入 Indexing service 后,内部会经过分布式的 QoS 模块,进行写入的流量控制,来阻止资源的过度消耗。
3、第三步,跨集群的物理复制, Indexing Service 构建的索引是通过物理复制到用户集群的。
4、最后是 Indexing Service 内部会持续地运行原数据同步的 task ,实时地同步用户集群托管的索引 metadata。
Indexing Service将于2021年2月全新上线,实现ES在时序日志场景的降本增效。 Index server 可以解决时序日志数据高并发写入瓶颈,优化集群写入计算资源成本,降低运维的复杂度。Indexing Service 无论从写入性能,成本节约,还是弹性伸缩的能力方面都能带来不一样的体验,大家可以敬请期待。

本文为阿里云原创内容,未经允许不得转载。
Elasticsearch生态&技术峰会 | 阿里云Elasticsearch云原生内核的更多相关文章
- 可能是全网首个支持阿里云Elasticsearch Xapck鉴权的Skywalking
可能是全网首个支持阿里云Elasticsearch Xapck鉴权的Skywalking 对Skywalking有兴趣的同学参见:年轻人的第一个APM-Skywalking 之前在搭建Skywalki ...
- 30分钟全方位了解阿里云Elasticsearch
摘要:阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security.Machine Learning.Graph.APM等商业功能,致力于数据分析.数据搜 ...
- 30分钟全方位了解阿里云Elasticsearch(附公开课完整视频)
摘要: 阿里云Elasticsearch提供100%兼容开源Elasticsearch的功能,以及Security.Machine Learning.Graph.APM等商业功能,致力于数据分析.数据 ...
- 服务质量分析:腾讯会议&腾讯云Elasticsearch玩出了怎样的新操作?
导语 | 腾讯会议于2019年12月底上线,两个月内日活突破1000万,被广泛应用于疫情防控会议.远程办公.师生远程授课等场景,为疫情期间的复工复产提供了重要的远程沟通工具.上线100天内,腾讯会议快 ...
- 上海仪电Azure Stack技术深入浅出系列1:谈Azure Stack在私有云/混合云生态中的定位
2.2 Azure Stack Azure Stack到2017年7月才提供GA版本,但目前还是可以通过技术预览版了解该技术.Azure Stack本质上是核心Azure服务的一个私有实例. Micr ...
- 速石科技携HPC混合云平台亮相AWS技术峰会2019上海站
2019年6月20日,全球云技术盛会——AWS技术峰会2019(上海站)在上海世博中心举行.作为AWS的技术合作伙伴,速石科技携旗下基于混合云的一站式高性能计算(HPC)平台首次公开亮相. 速石科技向 ...
- 腾讯云Elasticsearch集群规划及性能优化实践
一.引言 随着腾讯云 Elasticsearch 云产品功能越来越丰富,ES 用户越来越多,云上的集群规模也越来越大.我们在日常运维工作中也经常会遇到一些由于前期集群规划不到位,导致后期业务增长集群 ...
- 阿里云在云栖大会发布SaaS加速器3.0版最新成果,让天下没有难做的SaaS
2019年杭州·云栖大会顺利落幕,超过6万人次观展,200余位顶尖科学家分享了前沿技术.作为“阿里云不做SaaS”,坚持“被集成”战略的落地体现,阿里云SaaS加速器在云栖大会现场发布了SaaS加速器 ...
- 阿里云视频云正式支持AV1编码格式 为视频编码服务降本提效
今天我们要说的 AV1 可不是我们平时说的 .AVI 文件格式,它是由AOM(Alliance for Open Media,开放媒体联盟)制定的一个开源.免版权费的视频编码格式,可以解决H.265昂 ...
- 【公开课】【阿里在线技术峰会】何登成:AliSQL性能优化与功能突破的演进之路
MySQL的公开课,可能目前用不上这些,但是往往能在以后想解决方案的时候帮助到我.以下是阿里对公开课的整理 摘要: 本文根据阿里高级数据库专家何登成在首届阿里巴巴在线技术峰会上的分享整理而成.他主要介 ...
随机推荐
- Android 开发Day4
我们双击进入activity_main.xml 先将android.support.constraint.ConstraintLayout改为LinerLayout线性的,意思就是水平的的结构 并加入 ...
- 从时间复杂度的角度出发,list和vector之间查找,插入,删除等数据操作的区别
list和vector是STL(标准模板库)中常用的两种序列容器,它们各自在不同类型的操作上有着不同的优势.下面是list和vector在不同操作上的擅长之处: list的擅长操作 插入和删除操作:l ...
- Newtonsoft.Json/Json.NET忽略序列化时的意外错误
在.NET中Newtonsoft.Json(Json.NET)是我们常用来进行Json序列化与反序列化的库. 而在使用中常会遇到反序列化Json时,遇到不规则的Json数据解构而抛出异常. Newto ...
- petalinux创建及工程配置
2023-03-19 21:56:47 下载petalinux安装包 petalinux_2022 下载download用于离线编译 downloads_2022 sstate下载 这个部分不容易在线 ...
- springBoot打war包部署tomcat
1.修改maven的pom.xml文件 <packaging>war</packaging> 2.排除springboot内嵌的tomcat <dependency> ...
- FBNet/FBNetV2/FBNetV3:Facebook在NAS领域的轻量级网络探索 | 轻量级网络
FBNet系列是完全基于NAS方法的轻量级网络系列,分析当前搜索方法的缺点,逐步增加创新性改进,FBNet结合了DNAS和资源约束,FBNetV2加入了channel和输入分辨率的搜索,FBNetV3 ...
- MySQL索引Innodb存储引擎
MySQL索引优化 一.基础理解 MySQL语句的查询效率主要和索引树的高度有关,想要降低查询的次数提高查询的速度,减少直接对磁盘的I/O流的次数,就要让索引树的高度越低越好. 索引的定义:索引是帮助 ...
- Luna likes Love 题解
Problem Link 简要题意 题目很清楚. 分析 定理 两个人中左边的人一直向右运动,和两人向中间走所用的 步数相同 证明 假设有两组人为 \(a_l , a_r , b_l , b_r (a_ ...
- 准备Python环境学习OpenCV的使用
安装venv模块,执行如下命令: sudo apt-get install python3-venv 创建venv环境,命名为images,执行如下命令: python3 -m venv images ...
- 深入探讨Java面试中内存泄漏:如何识别、预防和解决
引言 在编写和维护Java应用程序时,内存泄漏是一个重要的问题,可能导致性能下降和不稳定性.本文将介绍内存泄漏的概念,为什么它在Java应用程序中如此重要,并明确本文的目标,即识别.预防和解决内存泄漏 ...