如何快速准备高质量的AI数据?
摘要:随着AI的快速发展,如何快速准备大量高质量的数据已经成为AI开发过程中一个极具挑战性的问题!
本文分享自华为云社区《如何快速准备高质量的AI数据?》,原文作者:徐波。
一、背景
通常来讲,AI人工智能的三要素是数据、算法和算力。这三要素缺一不可,都是人工智能快速发展的必备条件。这一轮AI热潮得以快速发展,也正是得益于这三个要素已经准备就绪。数据的质量会影响模型的精度,一般来说,大量高质量的数据更有可能训练出高精度AI模型。现在很多算法使用常规数据能将准确率做到85%或者90%,而商业化应用往往要求更高,如果将要模型精度提升至96%甚至99%,则需要大量高质量的数据,这个时候也会要求数据更加精细化、场景化、专业化,这往往也成为了AI模型突破瓶颈的关键性条件。
而在大多数人工智能和机器学习项目中,数据准备和工程任务占了80%以上的时间,其中数据清洗和数据标注占了整个项目的50%左右。而数据准备非常消耗人力,如何快速准备大量高质量的数据已经成为AI开发过程中一个极具挑战性的问题。

ModelArts是面向AI开发者的一站式开发平台,能够支撑开发者从数据到AI应用的全流程开发过程,包含数据处理、算法开发、模型训练、模型部署等操作。并且提供AI Gallery功能,能够在市场内与其他开发者分享数据、算法、模型等。为了能帮用户快速准备大量高质量的数据,ModelArts数据管理提供了以下主要能力:
- 提供了数据预览和多维筛选等功能方便AI开发者快速识别数据;
- 提供了数据校验、自动分组等数据处理功能加速数据清洗;
- 提供了12种以上的标注工具来帮助用户标注各个场景的数据;
- 提供了智能标注、团队标注等功能加速标注、保障标注质量。
更多功能请见ModelArts数据管理:

ModelArts数据管理为准备高质量的AI数据提供的能力
本案例将以交通标志识别原始数据集为基础,将使用ModelArts为您演示:
- 如何使用数据校验功能快速对数据进行清洗;
- 如何使用自动分组功能从众多数据中选出想要的数据;
- 如何使用标注工具快速完成标注;
- 如何使用智能标注等功能加速数据标注。
用户只需要进行确认或者稍作调整即可完成标注,可以大大提高数据标注效率,节省用户标注时间。
当您完成这个案例,您将掌握如何使用ModelArts快速准备大量高质量的数据。
二、准备
在开始之前,您需要进行相关的准备工作,包括注册华为云账号、实名认证、ModelArts全局配置和OBS相关操作,详细请参考此文档。
三、操作
本次案例主要分为以下几个步骤:①从AI Gallery下载数据集到ModelArts数据管理,② 数据校验:处理非法数据, ③自动分组:删除不想要的数据,④数据标注:对数据打标注,⑤智能标注:使用AI技术加速数据标注,⑥发布数据集:共享数据。
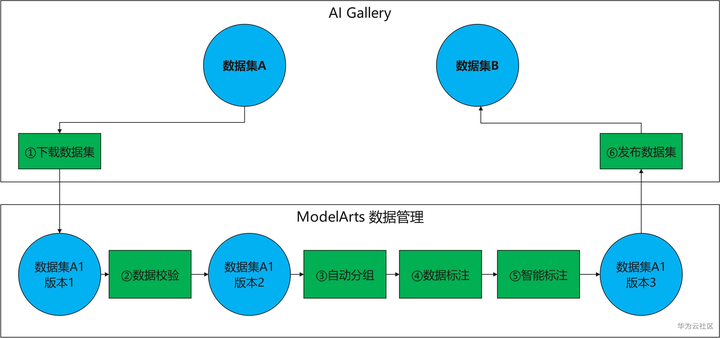
操作流程图
1. 下载数据集
该案例的数据集名称为“交通标志识别原始数据集”,已经上传到AI Gallery,AI Gallery地址为https://marketplace.huaweicloud.com/markets/aihub/datasets/list/。进入AI Gallery后需要选择数据栏,然后在AI Gallery搜索数据集名称“交通标志识别原始数据集”,或者点击数据集链接下载。
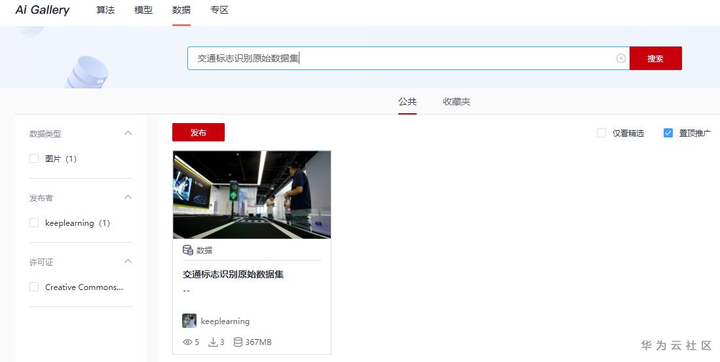
搜索数据集名称“交通标志识别原始数据集”
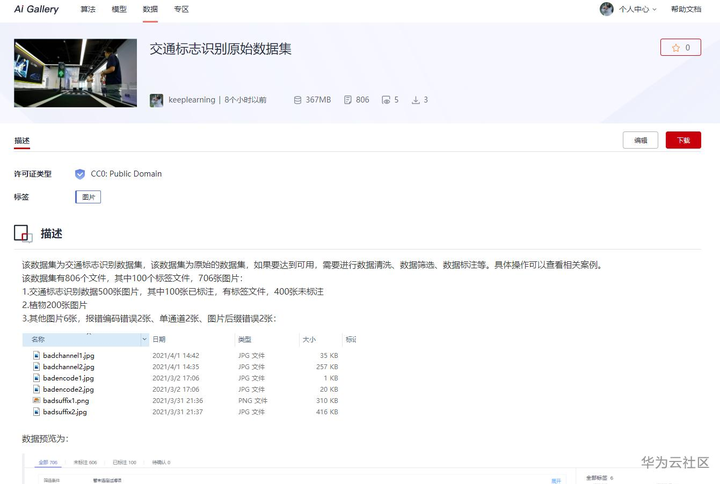
“交通标志识别原始数据集” 详情
选择该数据集进行下载,配置数据集的目标位置(需要现在OBS创建桶和目录),修改名称为“交通标志识别”,可以根据自己的情况加上描述。点击确认下载后,页面会跳转到“我的数据”页面,这个时候可以点击“我的下载”页面查看下载进度。
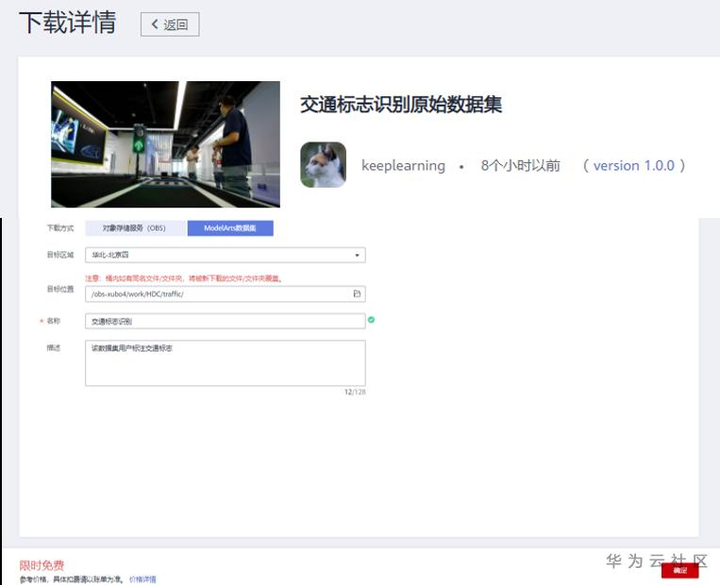
下载“交通标志识别原始数据集”
下载进度

数据集详情
2. 数据清洗
1)数据识别
当完成数据下载后,一般需要先进行数据识别,查看数据的大致情况,比如有多少数据、数据是什么样的、是否需要清洗等。这个时候可以点击“开始标注”,可以对数据进行预览,可以看到数据集样本列表。总共706张图片:交通标志识别数据500张,其中100张已标注,400张未标注;植物200张;其他数据6张。样本列表中的图片也会展示标签信息,右侧有该数据集的全部标签信息。目前已有的标签为:
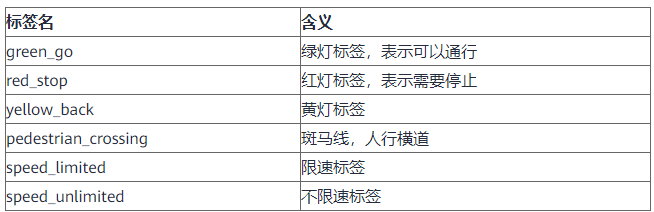
标签信息
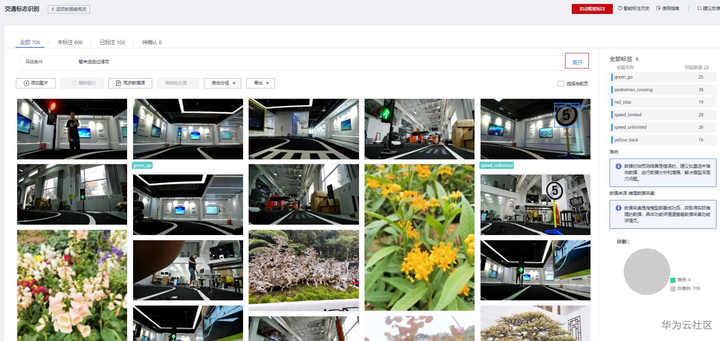
数据集样本列表
2) 数据筛选
进行数据查看时往往数据对数据进行筛选,选择自己想看的数据。这个时候可以点击筛选条件右侧的展开,选择相关条件进行筛选。ModelArts数据管理支持对标签名称、文件名称、标注人、样本属性、难例信息等进行筛选。也可以选择多个筛选条件同时进行筛选。
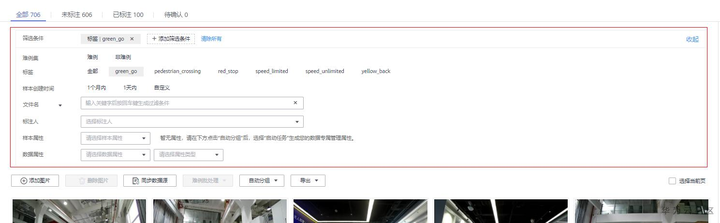
数据筛选
比如想查看标签名为“green_go”的样本列表信息,则可以直接选择标签名进行查看。
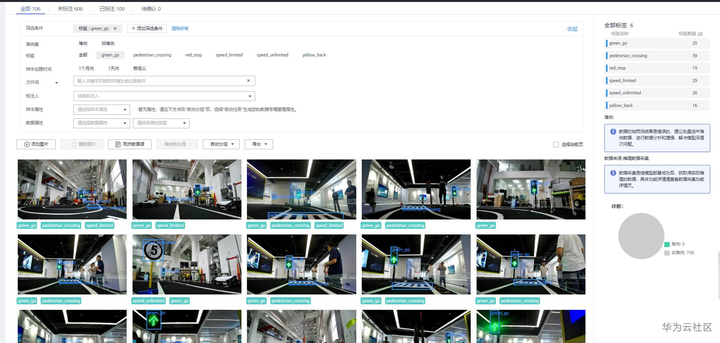
标签名为“green_go”的样本列表。
实际应用场景中数据往往夹杂着非法数据,需要对数据进行清洗。该数据集也有相关非法数据:编码错误2张(badencode1.jpg,badencode2.jpg)、图片后缀错误2张(badsuffix1.png,badsuffix2.png)、单通道2张(badchannel1.jpg,badchannel2.jpg)。比如根据文件名“badencode1.jpg”查看非法数据,可以看到图片加载异常,因为图片编码有问题。
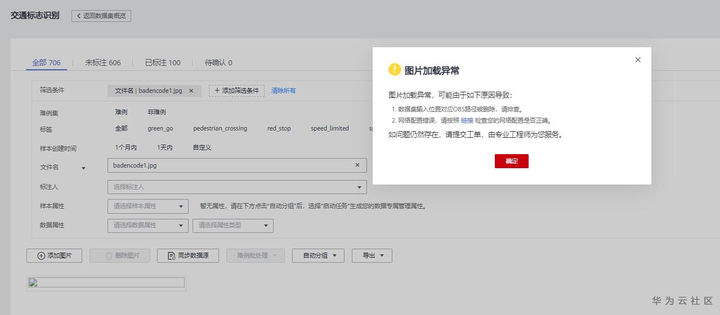
根据文件名“badencode1.jpg”查看非法数据
3) 创建“数据校验”类型的数据处理作业
ModelArts数据处理提供了“数据校验”功能,可以对数据进行检查。可以去ModelArts主页下的数据处理页面创建数据处理作业。
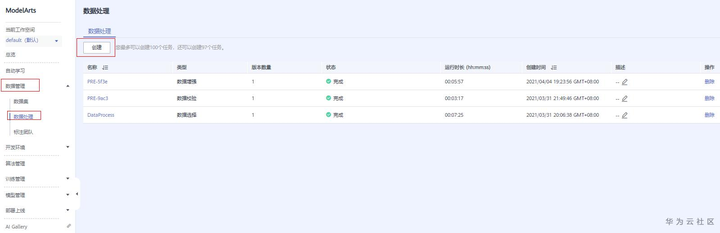
数据处理页面
创建数据处理作业时可以修改作业名称为“datavalidate”,选择场景类别“物体检测”,数据处理类型为“数据校验”,输入为数据集“交通标志识别”的V001版本,数据为数据集“交通标志识别”V002版本。
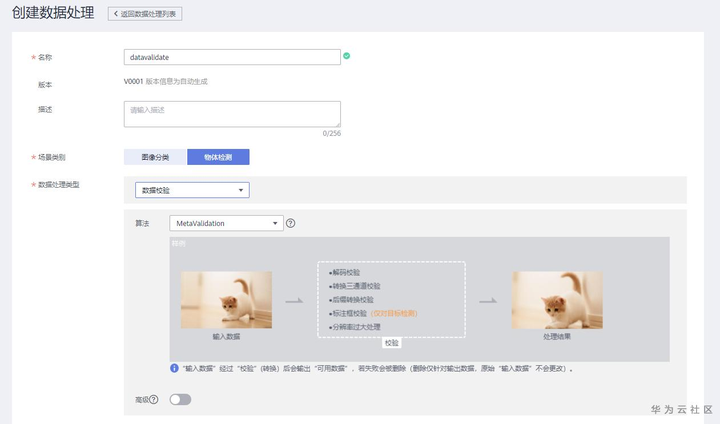

创建“数据校验”类型的数据处理作业
4)查看数据校验作业结果
数据校验结果确认:等待数据处理作业完成,预计需要几分钟。等待作业“datavalidate”完成后可以查看数据,选择输出数据集为“交通标志识别”V002版本,这个时候会提示是否切换版本,点击是,会切换版本,并且跳转到数据集页面,展示数据集详情。如果不切换版本,数据集展示的还是数据校验前的数据,可能会导致后面的步骤失败。查看结果,可以看到只有704张图片,2张编码格式有问题的已删除,后缀不对的2张和单通道的2张图片已修改。即已经对数据集完成数据清洗。
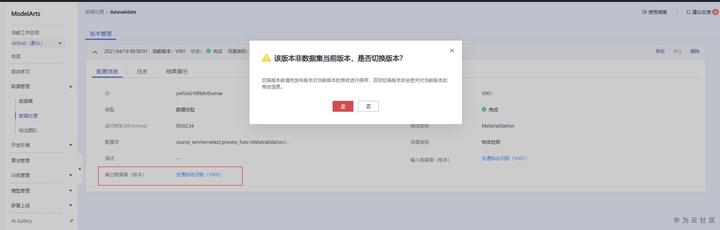
选择查看输出数据集版本
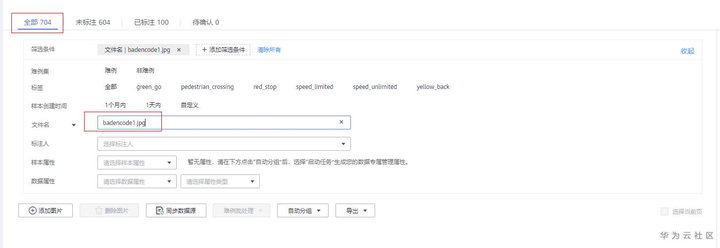
根据文件名“badencode1.jpg”查看,非法数据已被清洗
3. 自动分组
1) 启动任务
在对数据校验之后,发现数据中有500张交通标志的图片,200张植物的图片,4张其他的图片。如果前面数据未顺利获取到,可以直接选择从AI Gallery下载已进行数据校验的数据集:交通标志识别已校验数据集 。可参考下图下载对应阶段已处理好的数据:
对应阶段已处理好的数据
这个时候如果一张一张去挑自己想标注的数据,或者删除不想要的数据,会很慢很耗时。 这个时候可以选择启动自动分组功能,对交通标注数据和植物数据进行分组。进入页面为全部,然后点击自动分组就可以启动任务。
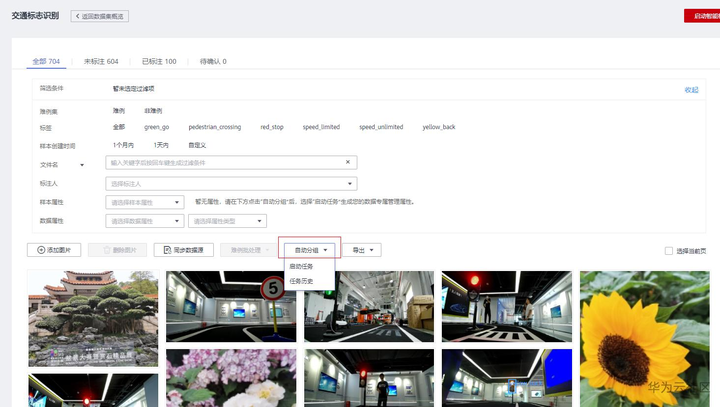
启动自动分组任务进行数据选择
启动自动分组任务时填入分组数为3,属性名称为group(也可以自定义),点击确认,等待任务执行。自动分组任务会在右上角展示。

启动自动分组任务,填入参数

自动分组进展查看
2) 任务结果查看
自动分组运行完后,可以在全部页签展开筛选条件,选择样本属性“group”,再选择属性值来查看结果:样本属性为“group”,值为0和1的基本为交通标志识别数据,区分在于两个拍摄场景不一样。样本属性为“group”,值为2的基本为植物数据。
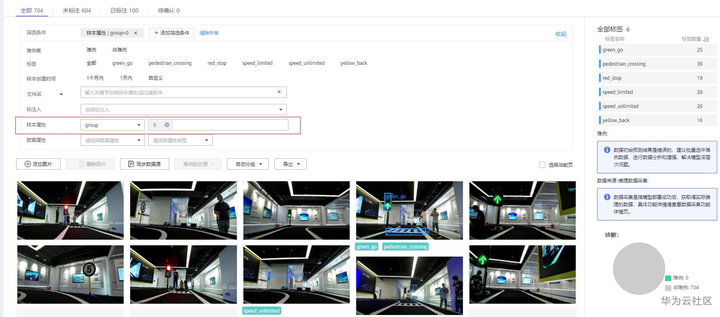
样本属性为“group”,值为0的筛选结果
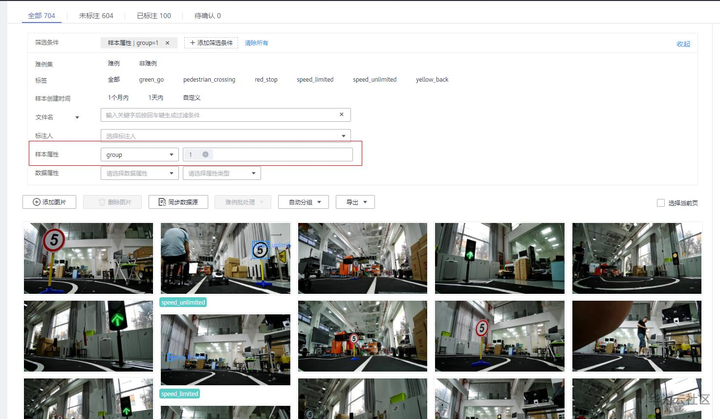
样本属性为“group”,值为1的筛选结果
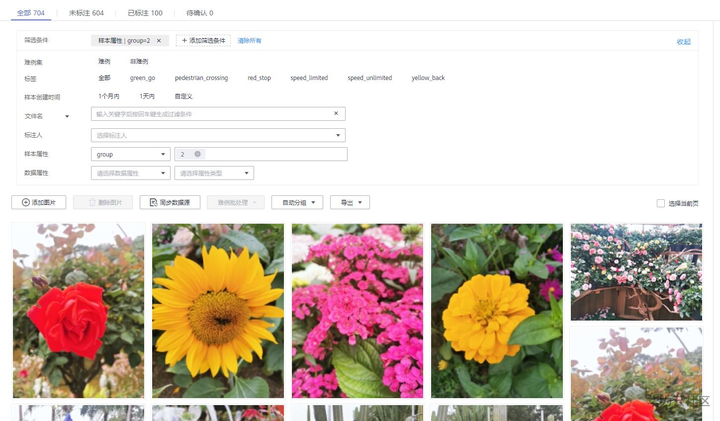
样本属性为“group”,值为2的筛选结果
3) 删除数据
这样数据就已经完成分组,而且分组结果比较准确。我们可以根据结果,将植物数据进行批量删除。点击图片列表右上角的“选择当前页”,选择所有数据,然后浏览一遍数据,如果发现已选的数据中有想要的数据,可以取消选择该图片,处理完后再点击“删除图片”,即可完成批量图片删除。删除完成后,基本只剩交通标志识别的数据了。
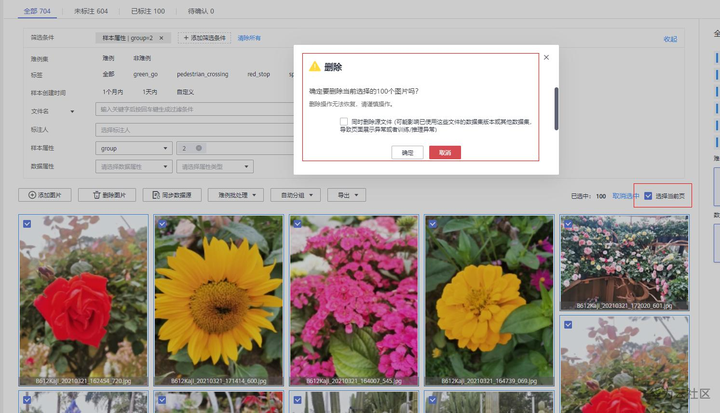
批量删除不想要的图片
4. 数据标注
在完成数据清洗,删除不想要的数据后,需要对数据进行标注。此时数据还剩大概500张图片。如果前面数据未顺利获取到,可以直接选择从AI Gallery下载已进行数据清洗的数据集:交通标志识别已清洗数据集
在数据集样本列表页面,点击“未标注”页签,筛选条件中样本属性为“group”,值为0,即可看到交通标志数据数据集中第一个场景的数据。更多使用信息可以查看用户指南。
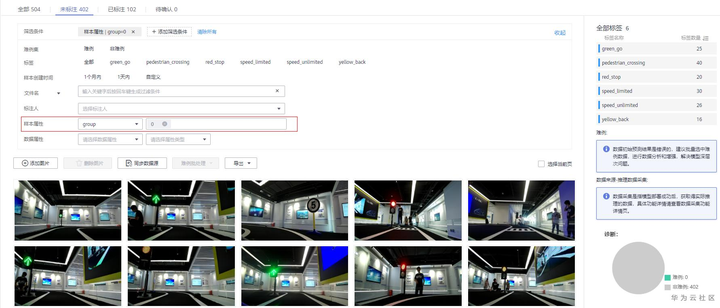
“未标注”页签样本属性为“group”,值为0的样本列表

标注工具说明
点击任意一张图片即可进入样本详情页面进行标注,标注页面会有标注工具栏、图片详情展示、图片列表、标签列表、图片切换等功能,如下图所示。
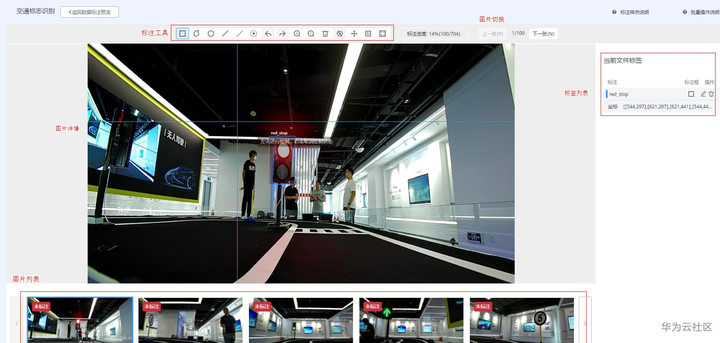
图片标注页面
选择矩形框,左击绘制选择标注位置,然后选择标签,即可完成标注,点击下一张会自动保存标注结果。也可以使用快捷键N切换到下一张。
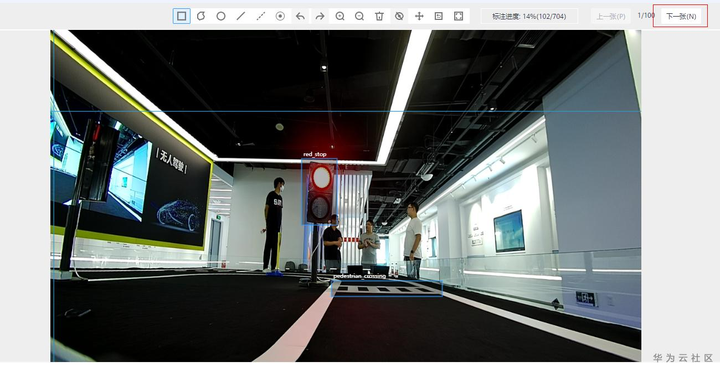
进行数据标注
5. 智能标注
使用过程中可以感觉到物体检测任务的标注工作量很大,而且手动标注效率不高,这个时候就可以使用智能标注功能来加速。
智能标注会对用户未标注的数据进行自动标注,用户只需要进行确认或者稍作调整即可完成标注。
智能标注主动学习的原理是使用已有的部分数据和ModelArts内置算法来训练一个模型,然后使用模型对剩下未标注的图片进行预测。其中快速型是监督算法,使用的是已标注数据进行训练,精准型为半监督算法,使用的是已标注和未标注的数据进行训练。用户也可以选择自己的模型进行智能标注,这个时候可以选择智能标注的预标注功能,同样能得到自动标注的预测结果。预测完成后,人只需要对预测结果进行准确性的检查,预测准确的图片就直接使用算法标注的结果,预测不准确的就人工修正一下标注,这种人机协作的方式,就能大幅度提升标注效率,节省用户标注时间。
1) 启动智能标注
启动智能标注前,建议每个标签标15张以上,这样进度会更高。点击样本列表的右上角“启动智能标注”,使用默认选项即可,点击提交即可开始智能标注。
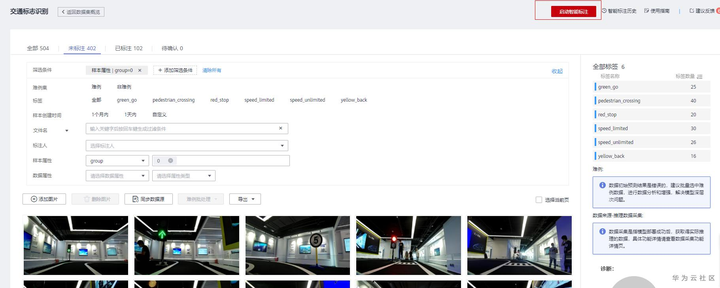
启动智能标注入口
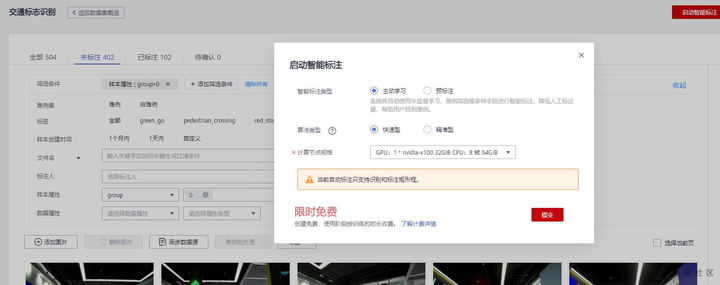
确定启动智能标注
2) 查看智能标注进展
提交智能标注任务之后即会跳转到智能标注进展页面,也可以点击“待确认”页签查看任务进度。
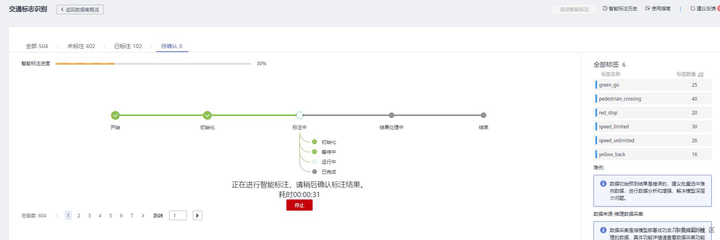
智能标注任务进展
3) 确认智能标注结果
智能标注运行完成后,可以在“待确认”页签看到智能标注结果。
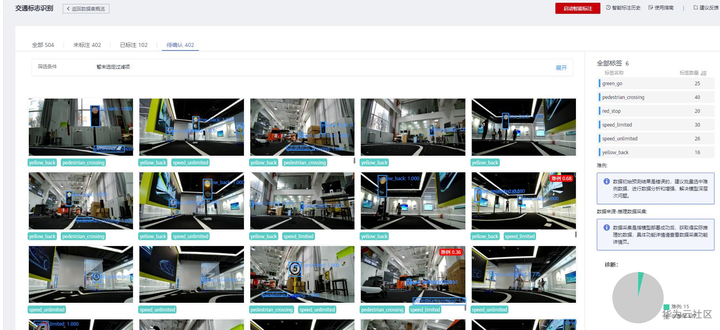
智能标注结果列表
未标注402张,智能标注结果也是402张。点击具体的图片进入详情页面确认。确认标签准确性,如果准确,直接可以点击“确认标注”,如果发现不对,可以调整标注结果再点击“确认标注”。
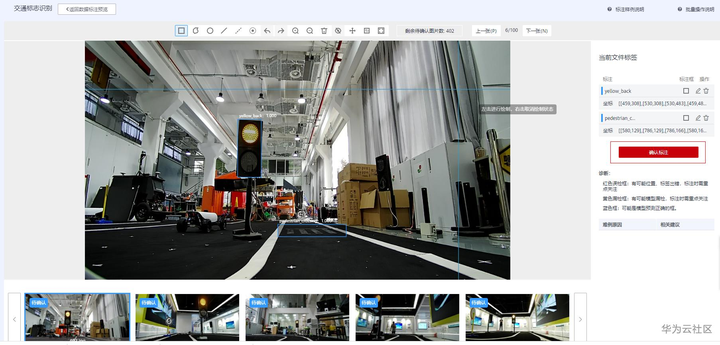
确认智能标注结果
6. 发布数据集
1) 发布数据集版本
完成数据标注之后可以发布数据集版本,可以选择数据切分和写入描述,也可以不选。
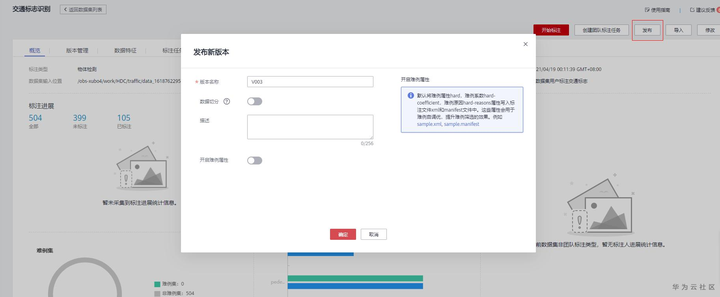
发布数据集版本
发布完成之后会生产固定化的版本,记录总共多少样本,已标注多少样本。也会生成manifest文件。Manifest里面会记录所有样本信息及其标注文件存储信息,对于物体检测,标注未见为Pascal VOC形式的XML文件,详细描述请见官方文档。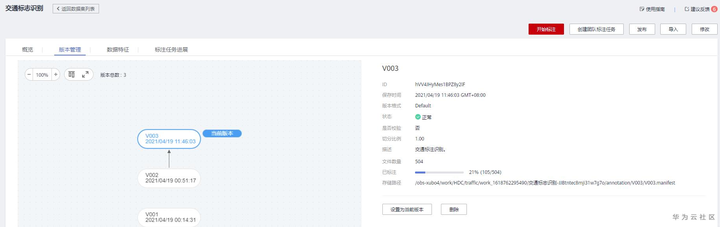
版本详情
2) 发布数据集版本到AI Gallery
在发布完数据集版本后,可以在ModelArts训练中选择该版本进行训练,也可以将该数据集发布到AI Gallery,共享给其他用户。进入AI Gallery下的数据页面,点击“发布”按钮,填写发布数据集的名称,比如“HDC2021--交通标志识别数据集”,选择数据集名称“交通标志识”和版本“V003”,选择数据类型为图片,选择许可类型。点击发布即可。

AI Gallery发布数据集
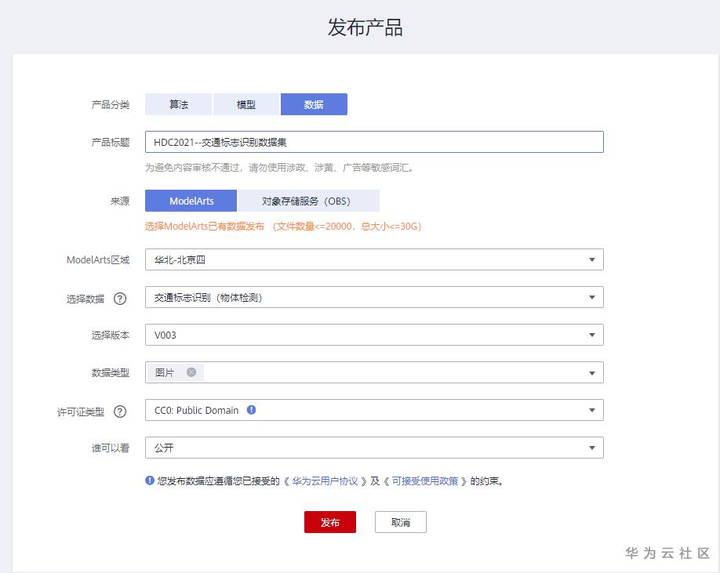
发布数据集到AI Gallery
发布完数据集之后可以点击编辑按钮,完善数据集信息,包括数据集首页
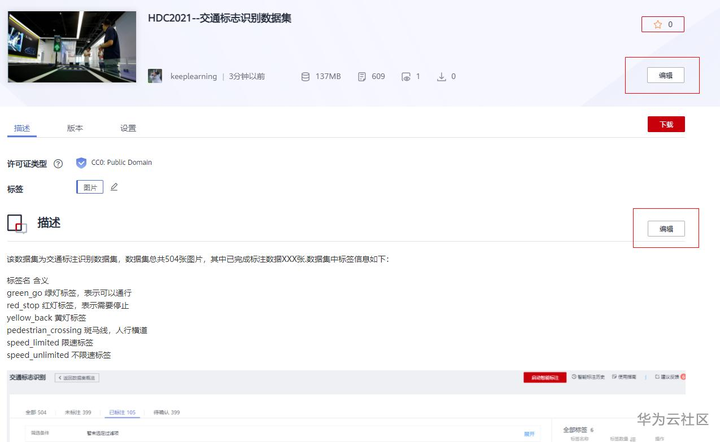
点击编辑完善数据集信息
至此,本案例完成。
如何快速准备高质量的AI数据?的更多相关文章
- react 高效高质量搭建后台系统 系列 —— 请求数据
其他章节请看: react 高效高质量搭建后台系统 系列 请求数据 后续要做登录模块(主页),需要先和后端约定JSON数据格式,将 axios 进行封装,实现本地的数据模拟 mockjs. Tip:s ...
- 法律AI数据及应用
本文简单列举了法律AI目前的应用,数据集,研究方向. 历史 1970年,Buchanan和Headrick发表文章"关于人工智能和法律推理的一些猜测",讨论了对法律研究和推理进行建 ...
- 通过优化在UE4中实现良好性能和高质量视觉效果
转自:http://gad.qq.com/program/translateview/7160166 译者:赵菁菁(轩语轩缘) 审校:李笑达(DDBC4747) 对于任何追求UE4性能最佳.同时又想 ...
- 编写高质量代码:Web前端开发修炼之道(一)
最近老大给我们买来一些技术方面的书籍,其实很少搬着一本书好好的完整的看完过,每每看电子档的,也是打游击式的看看这章,瞅瞅那章,在那5本书中挑了一本比较单薄的<编写高质量代码web前端开发修炼之道 ...
- 如何写出高质量的技术博客 这边文章出自http://www.jianshu.com/p/ae9ab21a5730 觉得不错直接拿过来了 好东西要大家分享嘛
如何写出高质量的技术博客?答案是:如果你想,就一定能写出高质量的技术博客.看起来很唯心,但这就是事实.有足够愿力去做一件目标明确,有良好反馈系统的事情往往很简单.就是不停地训练,慢慢地,你自己 ...
- 高质量C++/C编程指南(林锐)
推荐-高质量C++/C编程指南(林锐) 版本/状态 作者 参与者 起止日期 备注 V 0.9 草稿文件 林锐 2001-7-1至 2001-7-18 林锐起草 V 1.0 正式文件 林锐 20 ...
- 每周一书-编写高质量代码:改善C程序代码的125个建议
首先说明,本周活动有效时间为2016年8月28日到2016年9月4日.本周为大家送出的书是由机械工业出版社出版,马伟编著的<编写高质量代码:改善C程序代码的125个建议>. 编辑推荐 10 ...
- HTML Inspector – 帮助你编写高质量的 HTML 代码
HTML Inspector 是一款代码质量检测工具,帮助你编写更优秀的 HTML 代码.HTML Inspector 使用 JavaScript 编写,运行在浏览器中,是最好的 HTML 代码检测工 ...
- 深入理解JavaScript系列(1):编写高质量JavaScript代码的基本要点
深入理解JavaScript系列(1):编写高质量JavaScript代码的基本要点 2011-12-28 23:00 by 汤姆大叔, 139489 阅读, 119 评论, 收藏, 编辑 才华横溢的 ...
- 高质量C++[转]
高质量C++/C编程指南 文件状态 [ ] 草稿文件 [√] 正式文件 [ ] 更改正式文件 文件标识: 当前版本: 1.0 作 者: 林锐 博士 完成日期: 2001年7月24日 版 本 ...
随机推荐
- 2023-10-25:用go语言,假如某公司目前推出了N个在售的金融产品(1<=N<=100) 对于张三,用ai表示他购买了ai(0<=ai<=10^4)份额的第i个产品(1<=i<=N) 现给出K(
2023-10-25:用go语言,假如某公司目前推出了N个在售的金融产品(1<=N<=100) 对于张三,用ai表示他购买了ai(0<=ai<=10^4)份额的第i个产品(1& ...
- 文心一言 VS 讯飞星火 VS chatgpt (121)-- 算法导论10.4 2题
二.用go语言,给定一个n结点的二叉树,写出一个 O(n)时间的递归过程,将该树每个结点的关键字输出. 文心一言: 在Go语言中,你可以使用递归函数来遍历二叉树的所有节点,并输出每个节点的关键字.以下 ...
- Unity - Windows获取屏幕分辨率、可用区域
直接搜索最多的就是使用System.Windows.Form.Screen类,但因为unity用的是mono,不能正常使用这个方法 可使用win32api获取,这里只尝试了获取主要屏幕的分辨率,而且没 ...
- influxdb报错:cache-max-memory-size exceeded
转载请注明出处: influxdb报错日志: 该错误信息表示 InfluxDB 引擎超过了缓存最大内存大小.这意味着 InfluxDB 的缓存使用量超出了配置的限制. 要解决此问题,可以采取以下步骤来 ...
- sql server 截断和收缩所有用户数据库日志--用游标循环所有正常状态的用户数据库
在服务器运维活动中,我们经常需要做一项工具就是将好多年的用户数据库日志文件截断并收缩为最小,以节省大量的磁盘空间.当数据库只有一两个时可以手动操作,但数据库数量众多时,就需要采用sql脚本,批量化执行 ...
- 基于springboot+vue开发的教师工作量管理系
教师工作量管理系 springboot31 摘要 随着信息技术在管理上越来越深入而广泛的应用,管理信息系统的实施在技术上已逐步成熟.本文介绍了教师工作量管理系统的开发全过程.通过分析教师工作量管理系统 ...
- Node.js如何处理多个请求?
Node.js如何处理多个请求? 前言 在计算机科学领域,关于并发和并行的概念经常被提及.然而,这两个术语常常被混为一谈,导致很多人对它们的理解存在着很多混淆.本文小编将通过对并发和并行的深入解析,帮 ...
- .NET 8 IEndpointRouteBuilder详解
Map 经过对 WebApplication 的初步剖析,我们已经大致对Web应用的骨架有了一定了解,现在我们来看一下Hello World案例中仅剩的一条代码: app.MapGet(" ...
- 《实现领域驱动设计》笔记——DDD入门
设计不只是感观,设计就是产品的工作方式. 我们的目标应该是创造一个可观测的.可伸缩的.组织良好的软件模型. DDD同时提供了战略上的战术上的建模工具. 我能DDD吗? DDD首先并不是关于技术的,而是 ...
- 栈与队列应用:逆波兰计算器(逆波兰表达式;后缀表达式)把运算符放到运算量后边 && 中缀表达式转化为后缀表达式
1 //1.实现对逆波兰输入的表达式进行计算如(2-1)*(2+3)= 5 就输入2 1 - 2 3 + * //先把2 1 压栈 遇到-弹栈 再把2 3压进去 遇到+弹栈 最后遇到*弹栈 2 //2 ...