360 数科实践:JanusGraph 到 NebulaGraph 迁移
摘要:在本文中 360 数科的周鹏详细讲解了业务从 JanusGraph 迁移到 Nebula Graph 带来的性能提升,在机器资源不到之前 JanusGraph 配置三分之一的情况下,业务性能提升至少 20 倍。

本文作者系 360 数科开发工程师:周鹏
迁移背景
我们之前图数据用的是单机版的 AgensGraph, 后面因为单机带来的性能限制问题,迁移到了分布式数据库 JanusGraph,详细的迁移信息可以看我之前的一篇文章《百亿级图数据JanusGraph迁移之旅》。但是随着数据量和业务调用量的增加,新的问题又出现了——单次查询的耗时很高个别业务场景已经到了 10s,数据量稍微多点,逻辑复杂点的查询耗时也在 2~3s 左右,这严重影响了整个业务流程的性能和相关业务的发展。
JanusGraph 的架构决定了单次耗时高,核心的原因在于它的存储依赖外部,自身不能很好地控制外部存储,我们生产环境用的便是 HBase 集群,这导致所有的查询没法下推到存储层进行处理,只能把数据从 HBase 查询到 JanusGraph Server 内存再做相应的过滤。
举个例子,查询一层关联关系年龄大于 50 岁的用户,如果一层关联有 1,000 人,年龄大于 50 岁的只有 2 个人。介于 JanusGraph 查询请求发送到 HBase 时做不了一层关联顶点属性的过滤,我们不得不通过并发请求去查询 HBase 获取这 1,000 人的顶点属性,再在 JanusGraph Server 的内存做过滤,最后返回给客户端满足条件的 2 个用户。
这样做的问题就是磁盘 IO、网络 IO 浪费很大,而且查询返回的大多数据在而后查的查询并未用到。我们生产环境用的 HBase 为 19 台高配 SSD 服务器的,具体的网络 IO、磁盘 IO 使用情况如下图:
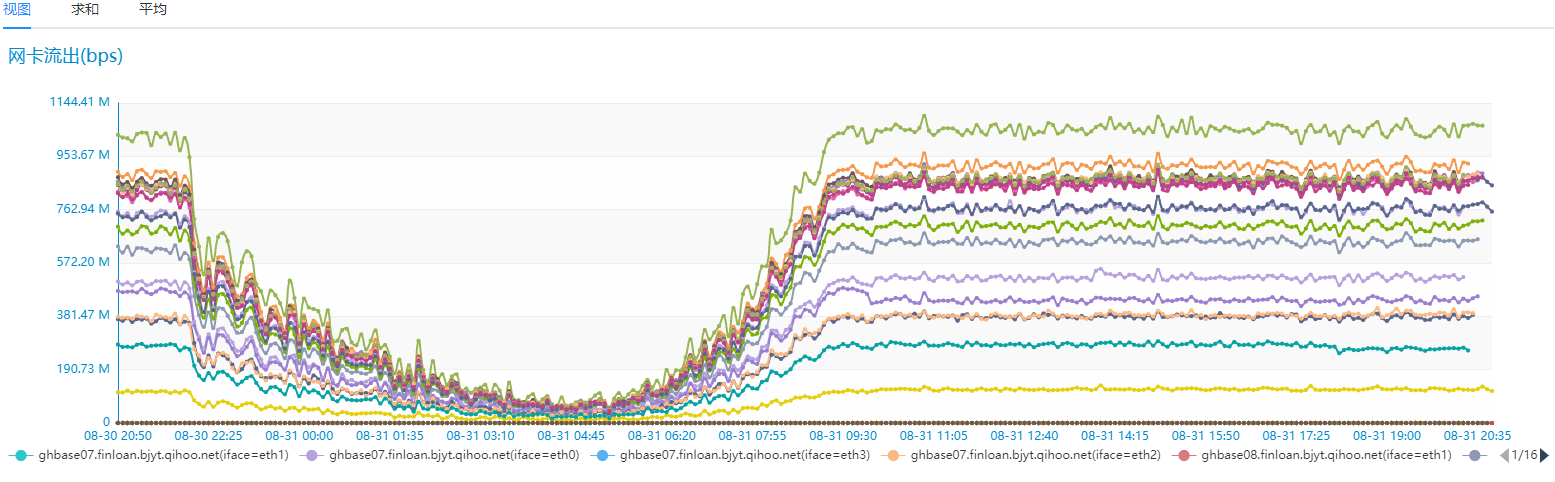
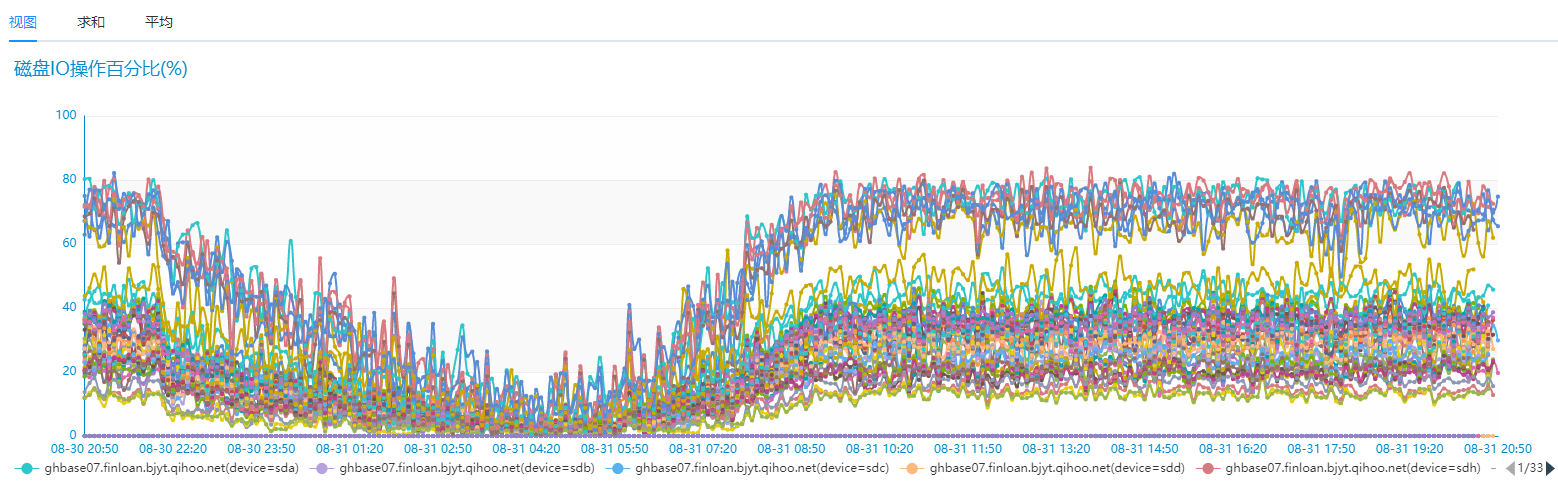
我们对比相同的业务场景,但是只有 6 台相同配置的 SSD 服务器 Nebua Graph 的磁盘 IO 和网络 IO 情况如下:
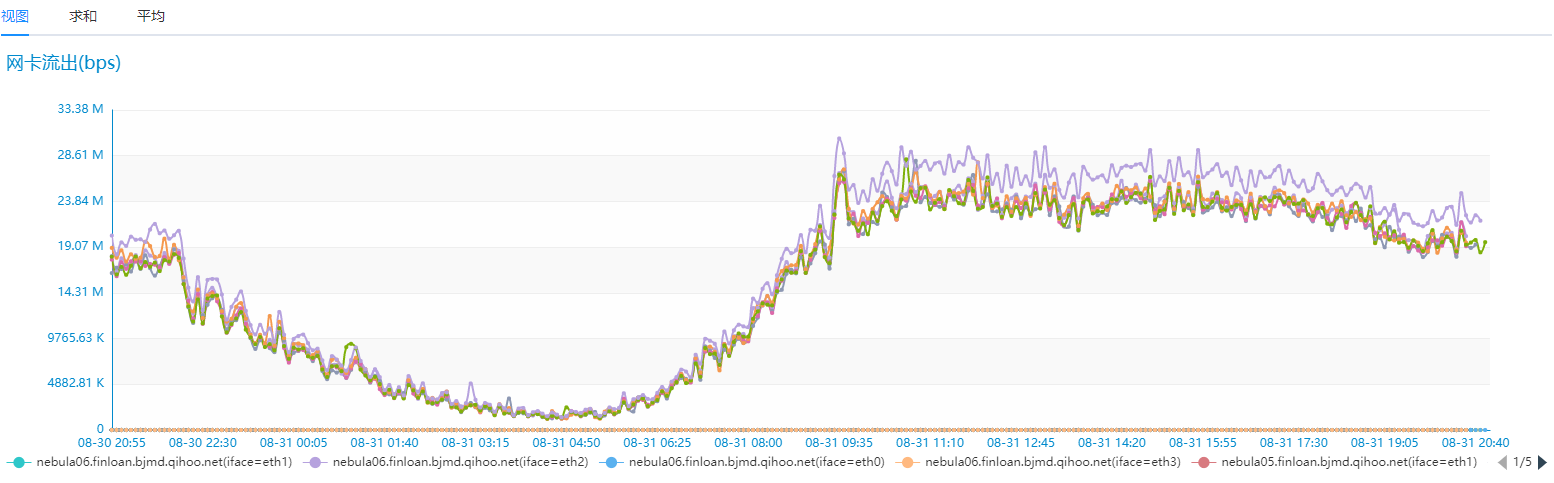
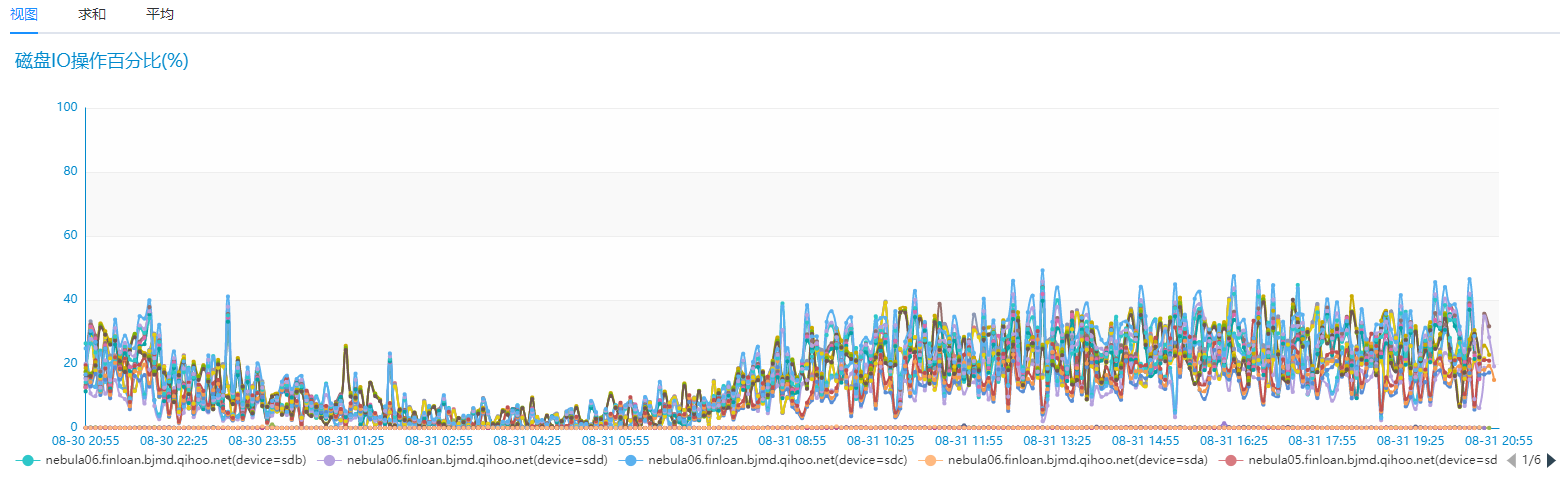
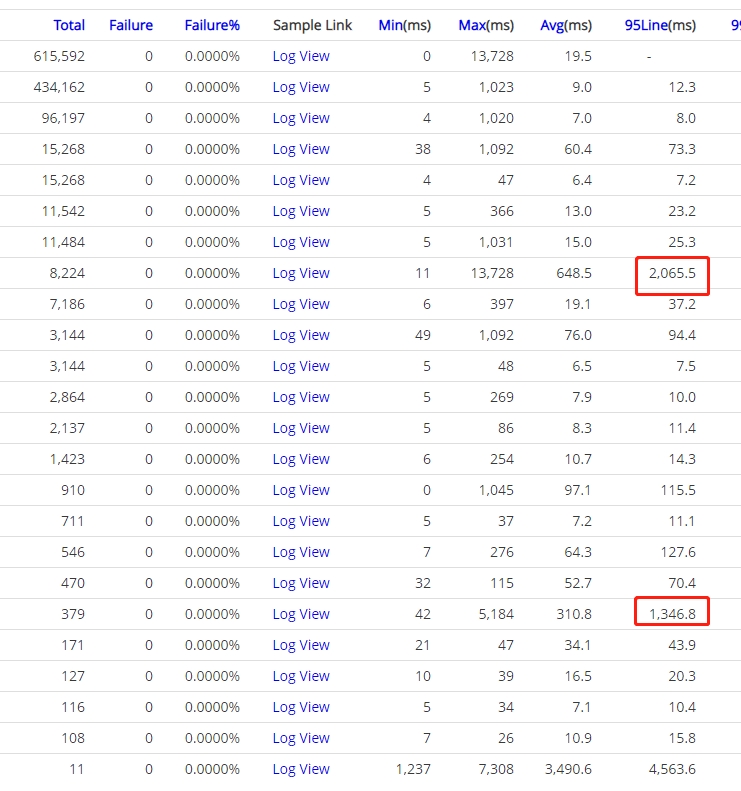
Nebula Graph 性能确实优秀太多,而且是在机器资源只有之前 Hbase 集群 30% 的情况下。我们再来看下业务场景下的耗时情况,之前业务场景中查询耗时需要 2~3s 情况的在 Nebula Graph 这边 100ms 左右返回了,之前需要 10~20s 情况的业务场景现在也基本在 2s 就能返回,并且平均耗时也基本在 500ms 左右就能搞定,性能提升至少 20 倍以上
就冲上面的这些数据,如果你还在用 JanusGraph,就应该立马把这篇文章转发给你的领导,并立个项开始迁移到 Nebua Graph
历史数据迁移
数据迁移这块,因为我们的数据量比较大,20 亿左右的顶点,200 亿左右的边,好在 Nebula Graph 提供 Spark 导入工具——Spark Writer,整个数据导入过程还算比较流畅。这里有个可分享经验,当时使用 Spark 导入工具采用异步方式导入导致了不少 error,稍微改下导入方式换成同步写入就没问题了。另外一个经验是关于 Spark 的,如果导入的数据量比较大,对应的 partitions 需要设置大一点,我们就设置过 8w 个 patitions。如果你设置的 partitions 比较小,单个 partition 的数据量便会比较大,容易导致 Spark 任务 OOM Fail。
查询调优
我们现在生产环境 Nebula Graph 用的是 1.0 的版本,生产环境上 ID 生产我们用的是 hash 函数, uuid 导入数据会很慢,后面官方也不会再支持 uuid。
在我们的生产环境主要参数调优配置如下,主要是 nebula-storage 需要调优
# The default reserved bytes for one batch operation
--rocksdb_batch_size=4096
# The default block cache size used in BlockBasedTable.
# The unit is MB. 我们生产服务器内存为128G
--rocksdb_block_cache=44024
############## rocksdb Options ##############
--rocksdb_disable_wal=true
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={"max_subcompactions":"3","max_background_jobs":"3"}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"disable_auto_compactions":"false","write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"8192"}
--max_handlers_per_req=10
--heartbeat_interval_secs=10
# 新添加参数
--raft_rpc_timeout_ms=5000
--raft_heartbeat_interval_secs=10
--wal_ttl=14400
--max_batch_size=512
# 参数配置减小内存使用
--enable_partitioned_index_filter=true
--max_edge_returned_per_vertex=10000
Linux 机器的调优主要就是把服务的 swap 关闭掉,开启后会因为磁盘 IO 影响查询性能。另外关于 minor compact 和 major compact 调优,我们生产环境是开启 minor compact 关闭 major compact。关闭 major compact 主要是因为这个操作很占磁盘 IO,并且很难通过线程数(--rocksdb_db_options={"max_subcompactions":"3","max_background_jobs":"3"})控制,后续 Nebula Graph 官方有计划优化这块。
最后,来重点提下 max_edge_returned_per_vertex 这个参数,能想到这个参数 Nebula Graph 不愧是图数据行业的老司机——我们之前的图查询一直受到超级节点的困扰,线上环境如果查询遇到这种关联几百万数据的超级节点能直接把 JanusGraph 的 HBase 集群查崩掉(我们生产环境出现过几次)。之前在查询 JanusGraph 的 Gremlin 语句上加各种 limit 限制都没能很好的解决这个问题,在 Nebula Graph 有了这个 max_edge_returned_per_vertex 参数,数据在最底层存储层直接做了过滤,生产环境就不会再有这种超级节点的困扰,就这一点就应该给 NebulaGraph 一个 FIVE STAR !
本文首发于 Nebula Graph 论坛,阅读本文的你有任何疑问,欢迎前往论坛和作者进行讨论,原帖传送门:https://discuss.nebula-graph.com.cn/t/topic/1172
360 数科实践:JanusGraph 到 NebulaGraph 迁移的更多相关文章
- Qihoo 360 altas 实践
Qihoo 360 altas 实践 简介 Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目.它在MySQL官方推出的MySQL-Prox ...
- Cassandra 在 360 的实践与改进
分享嘉宾:王锋 奇虎360 技术总监 文章整理:王彦 内容来源:Cassandra Meetup 出品平台:DataFunTalk 注:欢迎转载,转载请留言. 导读:2010年,Dropbox 在线云 ...
- Laravel 实践之路: 数据库迁移与数据填充
数据库迁移实际上就是对数据库库表的结构变化做版本控制,之前对数据库库表结构做修改的方式比较原始,比如说对某张库表新增了一个字段,都是直接在库表中执行alter table xxx add .. 的方式 ...
- 数据库实践丨使用MTK迁移Mysql源库后主键自增列导致数据无法插入问题
摘要:用户使用Mogdb 2.0.1版本进行业务上线测试,发现在插入数据时,应用日志中提示primary key冲突,用户自查业务SQL没有问题,接到通知后,招手处理故障. 本文分享自华为云社区< ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- Nebula Graph 的 Ansible 实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow & 看大厂图数据库技术实践 背景 在 Nebula-Graph 的日常测试中,我们会经常在 ...
- PB级大规模Elasticsearch集群运维与调优实践
导语 | 腾讯云Elasticsearch 被广泛应用于日志实时分析.结构化数据分析.全文检索等场景中,本文将以情景植入的方式,向大家介绍与腾讯云客户合作过程中遇到的各种典型问题,以及相应的解决思路与 ...
- PB级大规模Elasticsearch集群运维与调优实践【>>戳文章免费体验Elasticsearch服务30天】
[活动]Elasticsearch Service免费体验馆>> Elasticsearch Service自建迁移特惠政策>>Elasticsearch Service新用户 ...
- PB 级大规模 Elasticsearch 集群运维与调优实践
PB 级大规模 Elasticsearch 集群运维与调优实践 https://mp.weixin.qq.com/s/PDyHT9IuRij20JBgbPTjFA | 导语 腾讯云 Elasticse ...
- 用POLARDB构建客到智能餐饮系统实践
在新零售成为大趋势的今天,餐饮行业也加入到这一浪潮之中.智能餐饮系统将帮助餐饮行业从多个维度提升自己的运营能力和收益,而打造智能餐饮系统SaaS化能力也成为了目前的一个热点.本文中果仁软件联合创始人& ...
随机推荐
- 【实践篇】最全的【DDD领域建模】小白学习手册(文末附资料)
导读 DDD领域建模被各个大小厂商提起并应用,而每个人都有自己的理解,本文就是针对小白,系统地讲解DDD到底是什么,解决了什么问题,及一些建议和实践.本文主要是思想的一种碰撞和分享,希望能对朋友们有所 ...
- js中toFixed 并不是你想的那样进行四舍五入
toFixed 的简单介绍 toFixed() 方法可把 Number 类型的数字通过四舍五入为指定小数位的字符串.(将数字类型转化为字符串类型) 也就是说toFixed只能够处理数字类型的. 字符串 ...
- 使用Ant Design Vue的select搜索框出现的问题
Select 选择器进行搜索 <template> <div> <a-form-item label="分类:"> <a-select p ...
- echarts在左下角添加单位
配置单位 option = { xAxis: { type: 'category', data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'], ...
- [LeetCode刷题记录]113 路径总和 II
题目描述 给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径. 说明: 叶子节点是指没有子节点的节点. 难度 中等 题解 采用深度搜索优先,遍历每条从根节点到叶子节点的 ...
- 修改windows电脑键盘按键映射
改键的需求 买了一把61键的小键盘,有些按钮没有,比如Home.End.四个方向键,这些键需要按Fn+XX来实现,所以上网查了一下键盘按键修改的方法,即把按键给改了,比如把右边的Ctrl改成方向键. ...
- PostFix+Dovecot 部署邮件系统
Postfix 是一种电子邮件服务器是一个开放源代码的软件. Postfix 是MTA邮件传输代理软件.是sendmail提供替代品的一个尝试,在Internet世界中,大部分的电子邮件都是通过sen ...
- Metasploit 生成带SSL加密载荷
1.下载证书.Impersonate_SSL模块,下载指定网站的证书. msf6> use auxiliary/gather/impersonate_ssl msf6 auxiliary(gat ...
- 23.2 SEH之异常处理--《Windows核心编程》结构化异常处理
(structured exception handing)SEH 包含终止处理和异常处理.本章讨论异常处理. 当一个硬件或者软件异常被抛出的时候,操作系统会给我们程序一个查看异常类型的机会,并允 ...
- golang 中 取切片元素 与 切片再生成切片的区别
func main() { //定义一个切片 a := []byte{1, 2, 3} fmt.Printf("a的类型%T\n", a) //a的类型[]uint8 fmt.Pr ...