FasterViT:英伟达提出分层注意力,构造高吞吐CNN-ViT混合网络 | ICLR 2024
论文设计了新的
CNN-ViT混合神经网络FasterViT,重点关注计算机视觉应用的图像吞吐能力。FasterViT结合CNN的局部特征学习的特性和ViT的全局建模特性,引入分层注意力(HAT)方法在降低计算成本的同时增加窗口间的交互。在包括分类、对象检测和分割各种CV任务上,FasterViT在精度与图像吞吐量方面实现了SOTA,HAT可用作即插即用的增强模块来源:晓飞的算法工程笔记 公众号
论文: FasterViT: Fast Vision Transformers with Hierarchical Attention

Introduction
ViT最近在计算机视觉领域变得流行,并在图像分类、目标检测和语义分割等各种应用中取得了卓越的性能。尽管如此,纯ViT模型由于缺乏归纳偏置,导致需要更多的训练数据并可能影响性能。而由CNN和ViT组成的混合架构则可以解决这个问题并达到有竞争力的性能,无需大规模训练数据集或知识蒸馏等其他技术。
ViT的一个组成部分是自注意力机制,可以对短距离和长距离的空间关系进行建模。但由于自注意力的二次计算复杂度会显着影响效率,阻碍其在高分辨率图像应用中的使用。此外,与原始ViT模型的架构(即固定分辨率,无下采样)相反,以多尺度的方式学习特征通常会产生更好的性能,特别是对于下游应用(如检测、分割)。
为了解决这些问题,Swin Transformer提出了一种多尺度架构,其中自注意力在局部窗口内计算,通过窗口移动保证不同区域之间的交互。但由于局部区域的感受域有限且窗口移动的覆盖范围较小,跨窗口交互和长距离空间关系的建模在高分辨率输入的任务中依然具有挑战性。此外,在早期分辨率较大阶段也可能会由于局部窗口数量的增加而影响图像吞吐量。最近,Swin Transformer V2通过改进自注意力机制来解决高分辨率图像训练的不稳定问题。但与Swin Transformer相比,除了较低的图像吞吐量之外,Swin Transformer V2仍然依赖原始的窗口移动机制来进行不同窗口的交互,这在处理大图像时依然不高效。
于是,论文提出一种专为高分辨率图像输入量身定制的FasterViT混合架构,能保持较大的图像吞吐。FasterViT由四个不同的阶段组成,在高分辨率阶段(即阶段 1、2)使用残差卷积块,在后续阶段(即阶段 3、4)使用Transformer块,阶段之间通过步长卷积层来降低输入图像分辨率以及加倍通道数。这样的架构可以快速生成高质量token,然后基于Transformer块来进一步处理这些token。对于每个Transformer块,论文使用分层注意力块来提取长短距离空间关系,进行有效的跨窗口交互。
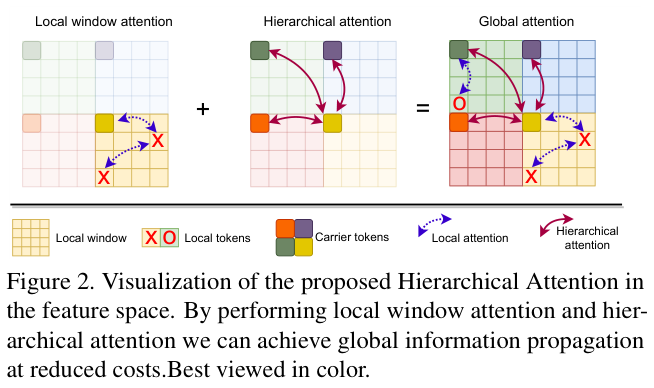
如图2所示,分层注意力机制为每个局部窗口学习一个carrier token作为总结,然后基于carrier token对窗口之间的交互模式进行建模。由于有基于局部窗口的注意力作为计算约束,随着区域数量的增加,分层注意力的计算复杂度几乎随输入图像分辨率线性增长。因此,它是捕获高分辨率特征的远距离关系的高效且有效的方法。
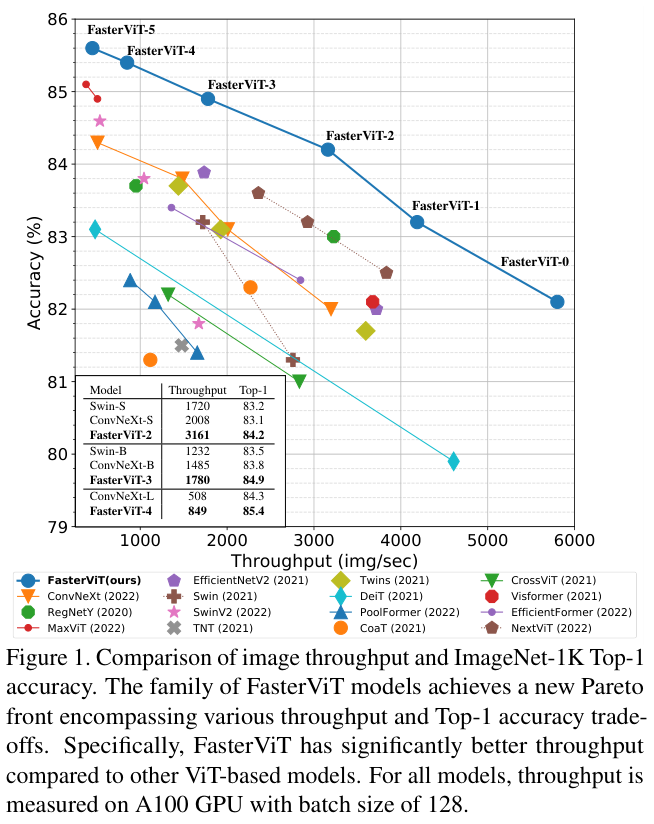
论文在各种图像任务和数据集上广泛地验证了所提出的FasterViT模型的有效性,考虑性能和图像吞吐量之间的权衡,FasterViT在ImageNet-1K top-1实现了最先进的性能。为了展示FasterViT对于更大数据集的可扩展性,论文还在ImageNet-21K数据集上对FasterViT进行了预训练,并在更大规模和更大分辨率的任务上进行微调和评估,实现了最先进的性能。
论文的贡献总结如下:
- 推出新颖的
FasterViT混合视觉架构,旨在实现性能和图像吞吐之间的最佳平衡,可以针对不同的数据集和模型大小有效地缩放到更高分辨率的输入图像。 - 提出了分层注意力模块,可以有效地捕获局部区域的跨窗口交互,并对长距离空间关系进行建模。
FasterViT在图像吞吐和准确性之间的权衡上实现了新的SOTA,比基于ViT的同类架构和最新的SOTA模型要快得多。同时,在MS COCO数据集上的检测和实例分割以及ADE20K数据集上的语义分割达到了具有竞争力的性能。
FasterViT
Design Principals
论文专注于在主流硬件上实现计算机视觉任务的最高吞吐量,需要在数据传输和计算之间进行仔细的平衡,以最大限度地提高吞吐量。
在分层视觉模型中,中间特征的空间维度随着推理的进行而缩小。初始网络层具有较大的空间维度和较少的通道(例如 \(112\times 112 \times 64\)),导致可选操作受内存传输限制,应该多使用如密集卷积的计算密集型操作。此外,无法以矩阵形式表示的操作(例如非线性、池化、批量归一化)也是受内存限制的,应尽量减少使用。相反,后面的层则往往受到运算量限制。比如分层CNN具有大小为 \(14\times 14\) 的高维特征,为使用提取能力更强的操作(例如层归一化、SE或注意力)留下了空间,而且对吞吐量的影响相当小。
Architecture
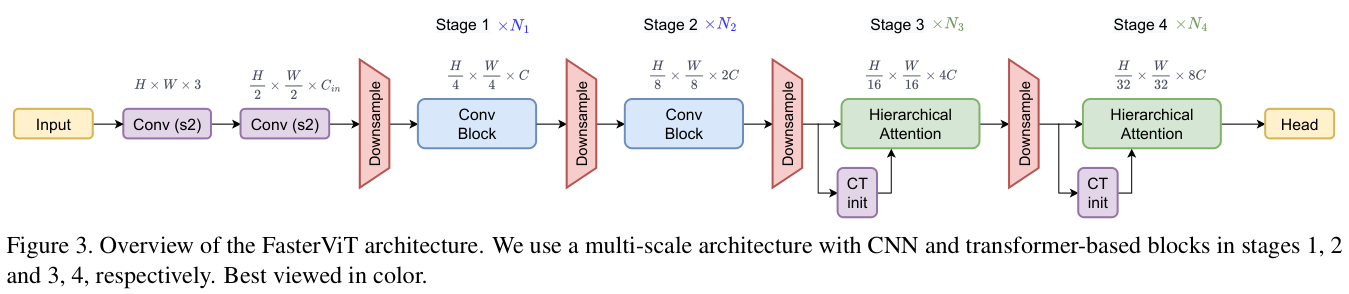
整体设计如图 3 所示,在早期阶段使用卷积层处理高分辨率特征,后半部分依赖于新颖的分层注意力层来对整个特征图进行空间推理。在此设计中,论文根据计算量和吞吐量优化了架构。前半部分和下采样块使用了密集卷积,避免使用SE算子。同时,需要最小化高分辨率阶段(即 1、2)的层归一化使用,因为这些层往往受到内存传输限制。而后期阶段(即 3、4)通常会受到计算量限制,与内存传输成本相比,GPU硬件在计算上花费更多时间,应用多头注意力也不会成为瓶颈。
FasterViT Components
Stem
输入图像 \({\textbf{x}}\in{\mathrm{R}^{H\times W\times3}}\) 通过连续的两个 \(3\times3\) 卷积层投影为 \(D\) 维embedding,每个卷积层的步长为2。embedding会进一步批归一化,每次卷积后都会使用ReLU激活函数。
Downsampler Blocks
FasterViT的下采样块先对空间特征应用2D层归一化,然后使用内核为 \(3\times3\) 且步长为 2 的卷积层,将空间分辨率降低2倍。
Conv Blocks
阶段 1 和阶段 2 由残差卷积块组成,定义为
\quad\quad (1)
\]
其中BN表示批归一化。遵循设计原则,这些卷积是密集的。
Hierarchical Attention
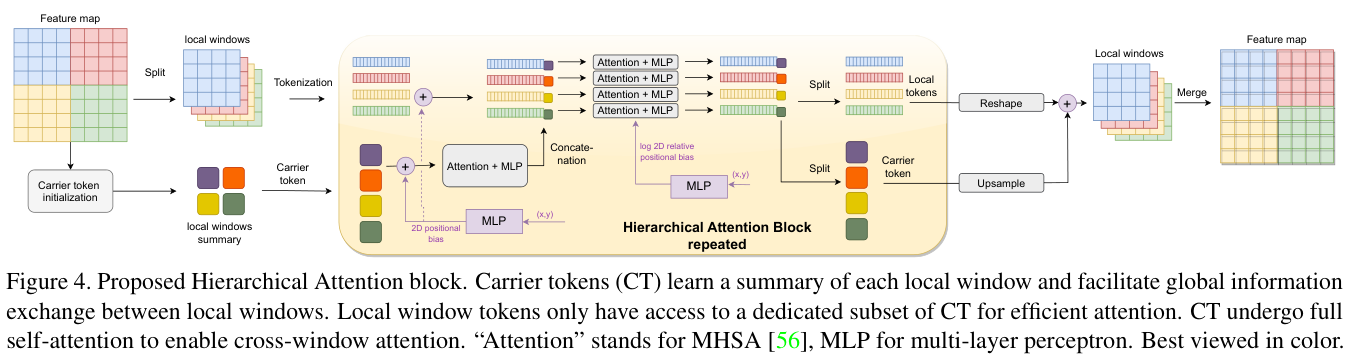
在这项工作中,论文提出了一种新颖的窗口注意力模块,整体如图 2 所示,详细介绍如图 4 所示。核心是在Swin Transformer的局部窗口上引入carrier tokens(CT)用于汇总局部窗口的信息,随后基于CT进行局部窗口之间的信息交互。
假设论文给出一个输入特征图 \(\mathbf{x}\in\mathbb{R}^{{H}\times W\times d}\),其中 \(\textstyle H\)、\(\dot{W}\) 和 \(d\) 表示特征图的高度、宽度和维度。为了简单起见,设置\(H=W\)。以 \(n = \frac{H^{2}}{k^{2}}\) 将输入特征图划分为 \(n\times n\) 个局部窗口,其中 \(k\) 是窗口大小,如下所示:
\quad\quad (2)
\]
通过池化每个窗口得到 \(L=2^{c}\) 个token来初始化CT:
\quad\quad (3)
\]
其中 \(\mathbf{Conv}_{3\times 3}\) 为Twins中使用的高效位置编码,\(\hat{\bf x}_{\mathrm{ct}}\) 和AvgPool分别表示carrier token和特征池化操作。这些池化的token代表了各自局部窗口的总结,一般都有 \(L << k\),论文将c设置为1。CT的初始化在每个阶段仅执行一次,每个局部窗口 \({\hat{\mathbf{x}}}_{l}\) 都有唯一的CT\(\hat{\bf x}_{\mathrm{ct},1}\),构成\(\hat{\bf x}_{\mathrm{ct}}\:=\:\{\hat{\bf x}_{\mathrm{ct},1}\}_{1=0}^{n}.\)集合。
在每个HAT块中,CT都会经历以下注意力处理:
\quad\quad (4)
\]
其中LN表示层归一化,MHSA表示多头自注意力,\(\gamma\) 是可学习的每个通道特定的缩放因子,\(\mathbf{MLP}_{d\rightarrow4d\rightarrow d}\) 是带有GeLU激活函数的两层MLP结构。
接下来,为了对长短距离空间信息进行建模,论文需要进行局部token\(\hat{\mathbf{x}}_{l}\) 和carrier token\({\hat{\mathbf{x}}}_{\mathrm{ct,l}}\) 之间的交互信息。
首先,将局部特征和CT连接起来,每个局部窗口只能访问其相应的CT:
\quad\quad (5)
\]
随后进行另一组注意力处理:
\quad\quad (6)
\]
最后,token被进一步拆分回局部特征和CT,用于后续的分层注意力层:
\quad\quad (7)
\]
公式 4-7 在阶段中的迭代执行,为了进一步促进长距离交互,论文在阶段末尾设计了全局信息传播计算如下:
\quad\quad (8)
\]
在公式 4 和 6 中,MHSA具有token位置不变性,但显然特征在空间维度中的位置能提供更丰富的信息。为了解决这个问题,论文效仿SwinV2采用两层MLP将2D绝对位置信息嵌入到CT和局部窗口token中。为了促进类似图像的局部归纳偏差,论文还使用SwinV2的对数空间的相对位置偏差来增强注意力计算,确保token的相对位置有助于注意力学习。因为位置编码由MLP插值,这种方法对图像大小变化是具有灵活性的,经过训练的模型可以应用于任何输入分辨率。

多种全局-局部自注意力之间的比较如图 5 所示,分层注意力将全局注意力分为局部注意力和次全局注意力,两者都可压缩为 2 个密集注意力。CT参与双方的关注并促进信息交换。
Complexity Analysis of HAT
最传统和流行的完全注意力的复杂性是 \(O(H^{4}d)\),将特征大小划分为大小为 \(k\) 的窗口并运行注意力,能简化到 \(O(k^2H^{2}d)\)。
众所周知,窗口注意力更有效但缺乏全局特征交互。论文基于CT在整个特征图上进行总结和交互,以弥补全局交互的缺失。给定每个窗口的 \(L\) 个CT,局部窗口计算的复杂度为 \(O((k^{2}+L)H^{2}d)\),CT注意力计算的复杂度为 \(O((\frac{H^{2}}{k^{2}}L)^{2}d)\),两种注意力的总成本为 \(O(k^{2}H^{2}d+LH^{2}d+\frac{H^{4}}{k^{4}}L^{2}d).\)
多级注意力的另一种方式为局部注意力提供子采样的全局信息,如Twins对全局特征图进行二次采样并将其用作局部窗口注意力的键和值,复杂度为\(O(k^{2}H^{2}d+\frac{H^{4}}{k^{2}}d)\)。在相同大小的局部窗口(\(k\))和 \(H\) 下,HAT的复杂度为 \(O(L\ +\ {\frac{H^{2}L^{2}}{k^{4}}})\),Twins的复杂度为 \(O\bigl({\frac{H^{2}}{k^{2}}}\bigr)\)。分辨率越高,HAT的效率越高。对于 \(H=32\)、 \(k=8\) ,当 \(L=4\) 时,HAT为 \(O(8)\),而Twins为 \(O(16)\)。
Experiments
Image Classification
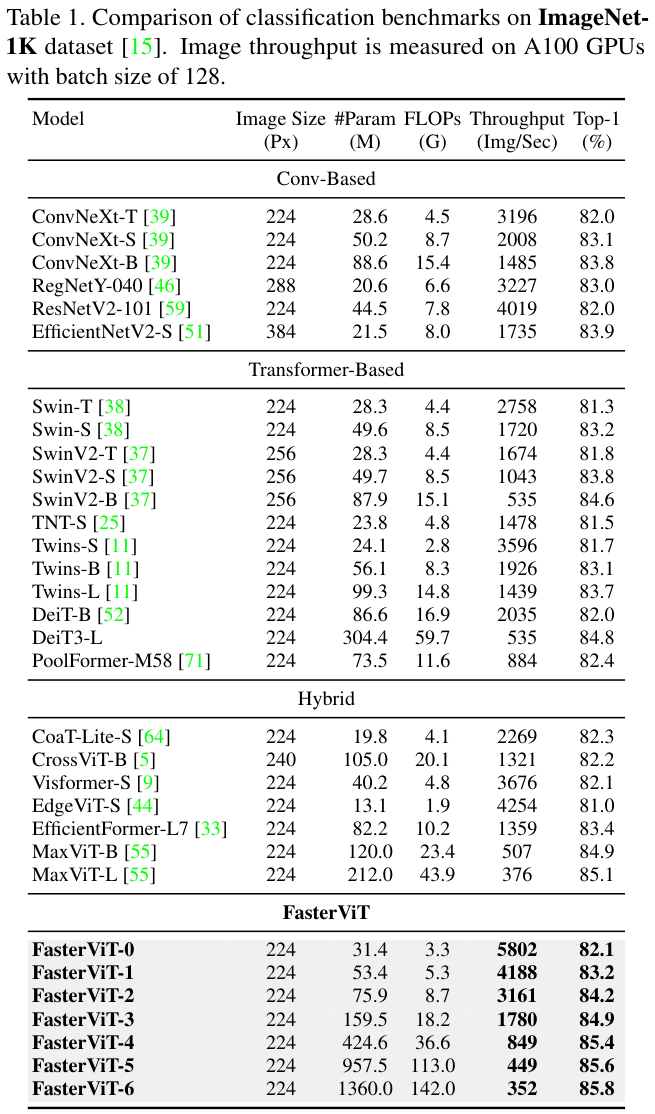
表 1 中展示了FasterViT模型其它模型在ImageNet-1K数据集表现。

为了验证所提出模型的可扩展性,论文在ImageNet-21K数据集上预训练FasterViT-4,并在ImageNet-1K数据集上对各种图像分辨率进行微调。一般来说,与其他同类模型相比,FasterViT-4具有更好的精度-吞吐量权衡。
Object Detection and Instance Segmentation
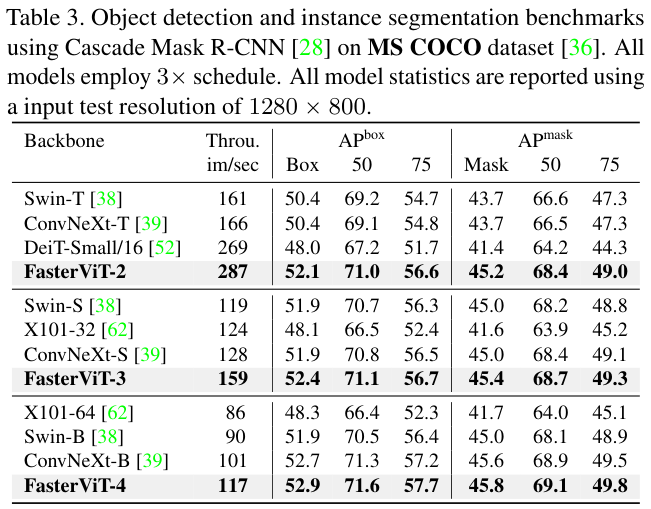
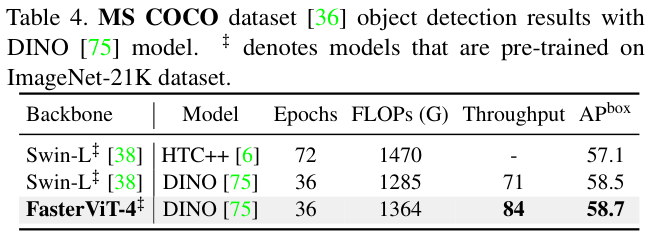
表 3 展示了使用Cascade Mask R-CNN网络在MS COCO数据集上的对象检测和实例分割基准。与其他模型相比,FasterViT模型作为主干会具有更好的精度-吞吐量权衡。
Semantic Segmentation
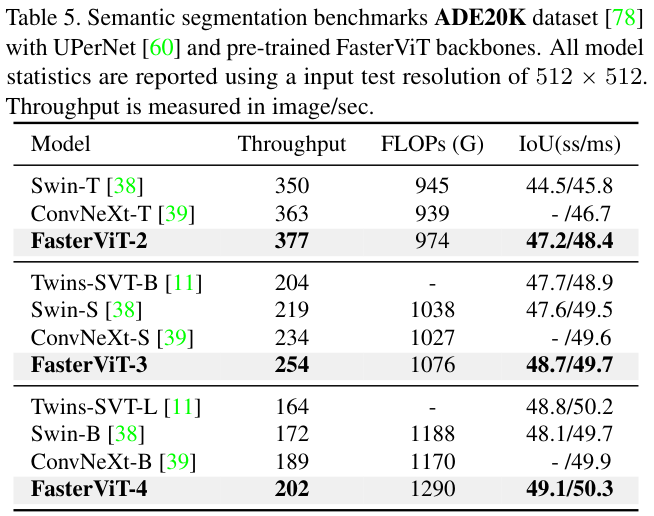
表 5 展示了使用UPerNet网络在ADE20K数据集上的语义分割基准。与之前的任务类似,FasterViT模型同样有更好的性能与吞吐量权衡。
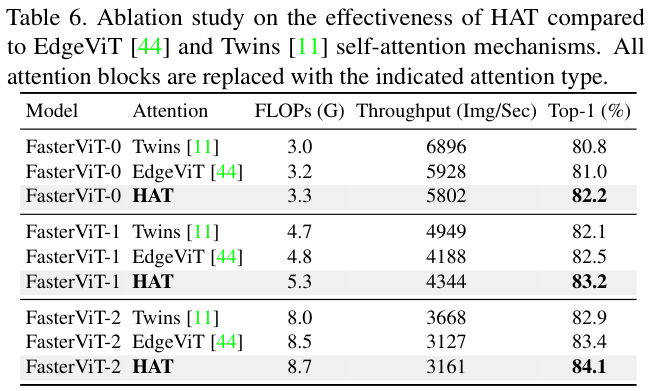
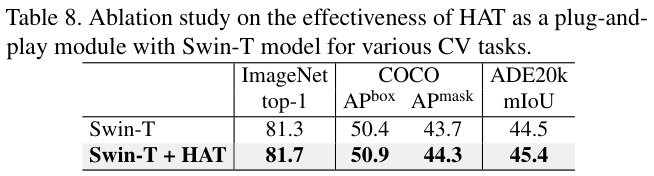
Component-wise study


如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

FasterViT:英伟达提出分层注意力,构造高吞吐CNN-ViT混合网络 | ICLR 2024的更多相关文章
- 第一篇:CUDA 6.0 安装及配置( WIN7 64位 / 英伟达G卡 / VS2010 )
前言 本文讲解如何在VS 2010开发平台中搭建CUDA开发环境. 当前配置: 系统:WIN7 64位 开发平台:VS 2010 显卡:英伟达G卡 CUDA版本:6.0 若配置不同,请谨慎参考本文. ...
- 英伟达CUVID硬解,并通过FFmpeg读取文件
虽然FFmpeg本身有cuvid硬解,但是找不到什么好的资料,英伟达的SDK比较容易懂,参考FFmpeg源码,将NVIDIA VIDEO CODEC SDK的数据获取改为FFmpeg获取,弥补原生SD ...
- Ubuntu18.04安装英伟达显卡驱动
前几天买了一张RTX2060显卡,想自学一下人工智能,跑一些图形计算,安装Ubuntu18.04后发现英伟达显卡驱动安装还是有点小麻烦,所以这里记录一下安装过程,以供参考: 1.卸载系统里低版本的英伟 ...
- 不用写代码就能实现深度学习?手把手教你用英伟达 DIGITS 解决图像分类问题
2006年,机器学习界泰斗Hinton,在Science上发表了一篇使用深度神经网络进行维数约简的论文 ,自此,神经网络再次走进人们的视野,进而引发了一场深度学习革命.深度学习之所以如此受关注,是因为 ...
- NCCL(Nvidia Collective multi-GPU Communication Library) Nvidia英伟达的Multi-GPU多卡通信框架NCCL 学习;PCIe 速率调研;
为了了解,上来先看几篇中文博客进行简单了解: 如何理解Nvidia英伟达的Multi-GPU多卡通信框架NCCL?(较为优秀的文章) 使用NCCL进行NVIDIA GPU卡之间的通信(GPU卡通信模式 ...
- 【视频开发】【CUDA开发】英伟达CUVID硬解,并通过FFmpeg读取文件
虽然FFmpeg本身有cuvid硬解,但是找不到什么好的资料,英伟达的SDK比较容易懂,参考FFmpeg源码,将NVIDIA VIDEO CODEC SDK的数据获取改为FFmpeg获取,弥补原生SD ...
- 玩深度学习选哪块英伟达 GPU?有性价比排名还不够!
本文來源地址:https://www.leiphone.com/news/201705/uo3MgYrFxgdyTRGR.html 与“传统” AI 算法相比,深度学习(DL)的计算性能要求,可以说完 ...
- 【并行计算与CUDA开发】英伟达硬件加速编解码
硬件加速 并行计算 OpenCL OpenCL API VS SDK 英伟达硬件编解码方案 基于 OpenCL 的 API 自己写一个编解码器 使用 SDK 中的编解码接口 使用编码器对于 OpenC ...
- 【并行计算-CUDA开发】英伟达硬件解码器分析
这篇文章主要分析 NVCUVID 提供的解码器,里面提到的所有的源文件都可以在英伟达的 nvenc_sdk 中找到. 解码器的代码分析 SDK 中的 sample 文件夹下的 NvTranscoder ...
- 【并行计算-CUDA开发】从熟悉到精通 英伟达显卡选购指南
举报 说到显卡,就不免令人想到英伟达和AMD两家面向个人消费级和企业级最大的显示芯片生产企业,英伟达和AMD,今天小编为大家简单的介绍一下英伟达的显卡选购方面的攻略,为一些想要购买显卡的用户提供一些参 ...
随机推荐
- aardio 代码格式化 自动保存 自定义 ctrl + s bug:这个快捷键是全局拦截
aardio 代码格式化工具 https://gitee.com/pengchenggang/aardio---code-formatting-tool 修改内容 1 代码进行了一定的修改,默认ctr ...
- BigDecimal类处理高精度计算
BigDecimal类处理高精度计算 Java在java.math包中提供的API类BigDecimal,用来对超过16位有效位的数进行精确的运算.双精度浮点型变量double可以处理16位有效数,但 ...
- springboot实现post请求
找了一堆,发现还是这个靠谱 package com.qishiyun.poplar.qlib.util; import cn.hutool.json.JSONUtil; import com.alib ...
- 02.Android崩溃Crash库之App崩溃分析
目录总结 01.抛出异常导致崩溃分析 02.RuntimeInit类分析 03.Looper停止App就退出吗 04.handleApplicationCrash 05.native_crash如何监 ...
- 关于volatile与指令重排序的探讨
写在开头 在之前的学习我们了解到,为了充分利用缓存,提高程序的执行速度,编译器在底层执行的时候,会进行指令重排序的优化操作,但这种优化,在有些时候会带来 有序性 的问题. 那何为有序性呢?我们可以通俗 ...
- 记录--canvas 复刻锤子时钟
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 介绍 canvas:使用脚本 (通常为 JavaScript) 来绘制图形的 HTML 元素. 本人遍历了以下两份文档,学习完就相当于有了 ...
- 记录--这样封装列表 hooks,一天可以开发 20 个页面
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 这样封装列表 hooks,一天可以开发 20 个页面 前言 在做移动端的需求时,我们经常会开发一些列表页,这些列表页大多数有着相似的功能: ...
- pycharm 常见易错的PEP8规范
PEP8规范 ( Python Enhancement Proposal ) PEP 8: E231 missing whitespace after ','这个意思是逗号后面要有一个空格 PEP 8 ...
- 记一次 .NET某半导体CIM系统 崩溃分析
一:背景 1. 讲故事 前些天有一位朋友在公众号上找到我,说他们的WinForm程序部署在20多台机器上,只有两台机器上的程序会出现崩溃的情况,自己找了好久也没分析出来,让我帮忙看下怎么回事,就喜欢这 ...
- 攻防世界 gametime 使用IDA pro+OD动调
自学犟种琢磨动调的一个记录,算是第一次动调的新手向,大佬请飘过 题目 准备工作--IDA pro(32X) 下载得到一个exe文件,首先丢到PE里面--无壳,32bit 丢到IDA pro(x32)里 ...