Java全局唯一ID生成策略
在分布式系统中常会需要生成系统唯一ID,生成ID有很多方法,根据不同的生成策略,以满足不同的场景、需求以及性能要求。
1、数据库自增序列
这是最常见的一种方式,利用DB来生成全库唯一ID。
优点:
- 此方法使用数据库原有的功能,所以相对简单
- 能够保证唯一性
- 能够保证递增性
- id 之间的步长是固定且可自定义的
缺点:
- 可用性难以保证:数据库常见架构是 一主多从 + 读写分离,生成自增ID是写请求 主库挂了就玩不转了
- 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且 难以扩展
优化方案:
- 冗余主库,避免写入单点
- 数据水平切分,保证各主库生成的ID不重复
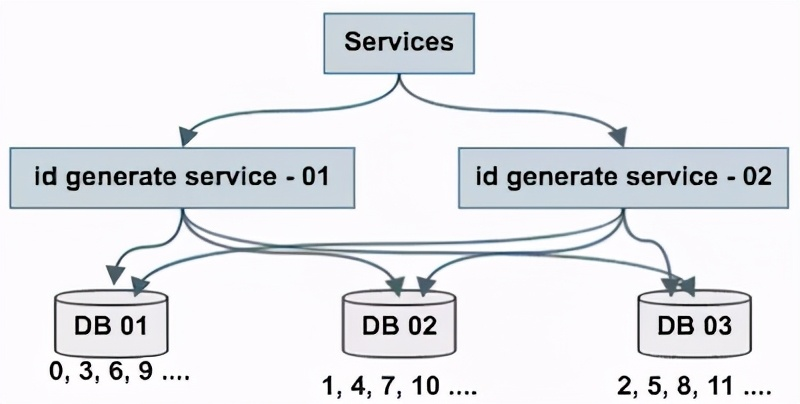
如上图所述,由1个写库变成3个写库,每个写库设置不同的 auto_increment 初始值,以及相同的增长步长,以保证每个数据库生成的ID是不同的(上图中DB 01生成0,3,6,9…,DB 02生成1,4,7,10,DB 03生成2,5,8,11…)
改进后的架构保证了可用性,但缺点是:
- 丧失了ID生成的“绝对递增性”:先访问DB 01生成0,3,再访问DB 02生成1,可能导致在非常短的时间内,ID生成不是绝对递增的(这个问题不大,目标是趋势递增,不是绝对递增
- 数据库的写压力依然很大,每次生成ID都要访问数据库
2、单点批量ID生成服务
为了解决上面优化方案的缺陷,引出了以下方法:
数据库写压力大,是因为每次生成ID都访问了数据库,可以使用批量的方式降低数据库写压力。
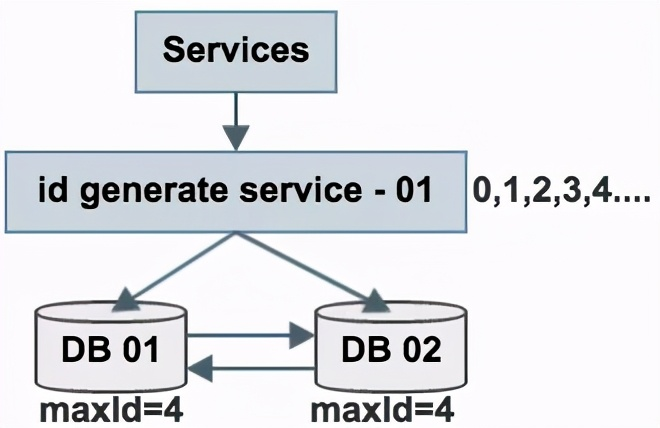
如上图所述,数据库使用双master保证可用性,数据库中只存储当前ID的最大值,例如4。
ID生成服务假设每次批量拉取5个ID,服务访问数据库,将当前ID的最大值修改为4,这样应用访问ID生成服务索要ID,ID生成服务不需要每次访问数据库,就能依次派发0,1,2,3,4这些ID了。
当ID发完后,再将ID的最大值修改为11,就能再次派发6,7,8,9,10,11这些ID了,于是数据库的压力就降低到原来的1/6。
优点:
- 保证了ID生成的绝对递增有序
- 大大地降低了数据库的压力,ID生成可以做到每秒生成几万几十万个
缺点:
- 服务仍然是单点
- 如果服务挂了,服务重启起来之后,继续生成ID可能会不连续,中间出现空洞(服务内存是保存着0,1,2,3,4,数据库中max-id是4,分配到3时,服务重启了,下次会从5开始分配,3和4就成了空洞,不过这个问题也不大)
- 虽然每秒可以生成几万几十万个ID,但毕竟还是有性能上限,无法进行水平扩展
改进方案:
单点服务的常用高可用优化方案是“备用服务”,也叫“影子服务”,所以我们能用以下方法优化上述缺点:
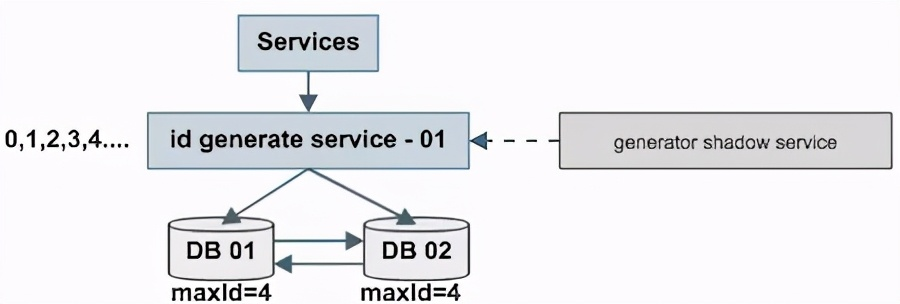
如上图,对外提供的服务是主服务,有一个影子服务时刻处于备用状态,当主服务挂了的时候影子服务顶上。这个切换的过程对调用方是透明的,可以自动完成,常用的技术是 vip+keepalived。另外,id generate service 也可以进行水平扩展,以解决上述缺点,但会引发一致性问题。
3、UUID
不管是通过数据库,还是通过服务来生成ID,业务方Application都需要进行一次远程调用,比较耗时。(前两种)
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”,要想保证绝对的时序,还是只能使用单点服务,用本地时钟保证“绝对时序”。
UUID是一种常见的本地生成ID的方法,UUID保证对在同一时空中的所有机器都是唯一的。
按照开放软件基金会(OSF)制定的标准计算,用到了以太网卡地址、纳秒级时间、芯片ID码和许多可能的数字。
UUID由以下几部分的组合:
(1)当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
(2)时钟序列。
(3)全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
UUID uuid = UUID.randomUUID();
优点:
1)使用简单。
2)生成ID性能高,基本不会有性能问题。
3)全球唯一,当数据迁移、数据合并、数据库变更时,可以从容应对。
缺点:
1)数据无序,无法保证趋势递增。
2)UUID使用字符串存储,查询效率较低。(常见优化方案为“转化为两个uint64整数存储”或者“折半存储”,折半后不能保证唯一性)
3)存储空间较大,如果是海量数据库,需考虑存储量的问题。
4)传输数据量大。
5)可读性差。
4、GUID
1)为了解决UUID不可读,可以使用UUID to Int64的方法。
//根据GUID获取唯一数字序列
public static long GuidToInt64() {
byte[] bytes = Guid.NewGuid().ToByteArray();
return BitConverter.ToInt64(bytes, 0);
}
2)为了解决UUID无序问题,NHibernate在其主键生成方式中提供了Comb算法(combined guid/timestamp)。保留GUID的10个字节,用另6个字节表示GUID生成的时间(DateTime)。
点击查看代码
private Guid GenerateComb() {
byte[] guidArray = Guid.NewGuid().ToByteArray();
DateTime baseDate = new DateTime(1900, 1, 1);
DateTime now = DateTime.Now;
// Get the days and milliseconds which will be used to build the byte string
TimeSpan days = new TimeSpan(now.Ticks - baseDate.Ticks);
TimeSpan msecs = now.TimeOfDay;
// Convert to a byte array Note that SQL Server is accurate to 1/300th of a millisecond so we divide by 3.333333
byte[] daysArray = BitConverter.GetBytes(days.Days);
byte[] msecsArray = BitConverter.GetBytes((long)(msecs.TotalMilliseconds / 3.333333));
// Reverse the bytes to match SQL Servers ordering
Array.Reverse(daysArray);
Array.Reverse(msecsArray);
// Copy the bytes into the guid
Array.Copy(daysArray, daysArray.Length - 2, guidArray, guidArray.Length - 6, 2);
Array.Copy(msecsArray, msecsArray.Length - 4, guidArray, guidArray.Length - 4, 4);
return new Guid(guidArray);
}
5、取当前毫秒数
uuid是一个本地算法,生成性能高,但无法保证趋势递增,且作为字符串ID检索效率低,有没有一种能保证递增的本地算法呢?
取当前毫秒数是一种常见方案。
优点:
- 本地生成ID,不需要进行远程调用,时延低
- 生成的ID趋势递增
- 生成的ID是整数,建立索引后查询效率高
缺点:
- 如果并发量超过1000,会生成重复的ID
- 这个缺点要了命了,不能保证ID的唯一性。当然,使用微秒可以降低冲突概率,但每秒最多只能生成1000000个ID,再多的话就一定会冲突了,所以使用微秒并不从根本上解决问题。
6、使用Redis生成id
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。 这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR 和 INCRBY 来实现。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。
- 需要编码和配置的工作量比较大。
7、用zookeeper生成唯一ID
zookeeper主要通过其znode数据版本来生成序列号,可以生成32位和64位的数据版本号,客户端可以使用这个版本号作为唯一的序列号。
通常很少会使用zookeeper来生成唯一ID。 原因是需要依赖zookeeper,并且是多步调用API,在竞争大时需要考虑使用分布式锁。因此,性能在高并发的分布式环境下,也不甚理想。
8、Twitter开源的Snowflake算法
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。
其核心思想是:
- 最高位是符号位,始终为0,不可用。
- 41 bit 作为毫秒数 - 41位的长度可以使用69年
- 10 bit 作为机器编号 (5个bit是数据中心,5个bit的机器ID) - 10位的长度最多支持部署1024个节点
- 12 bit 作为毫秒内序列号 - 12位的计数顺序号支持每个节点每毫秒产生4096个ID序号
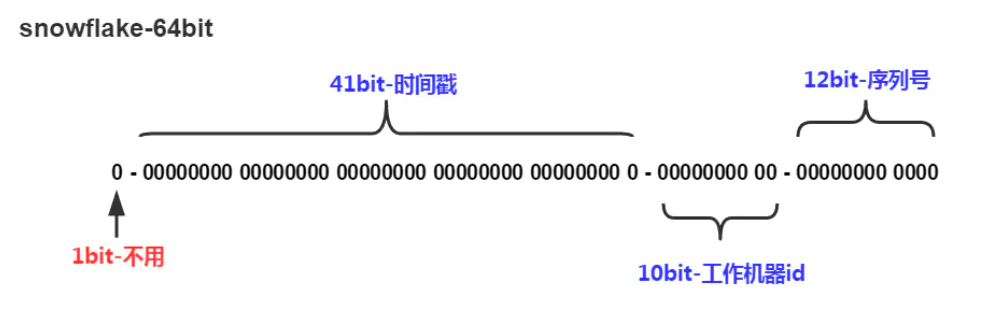
算法单机每秒内理论上最多可以生成1000*(2^12),也就是400W的ID,完全能满足业务的需求。
snowflake算法可以根据自身项目的需要进行一定的修改。比如估算未来的数据中心个数,每个数据中心的机器数以及统一毫秒可以能的并发数来调整在算法中所需要的bit数。
优点:
- 不依赖于数据库,速度快,性能高。
- ID按照时间在单机上是递增的。
- 可以根据实际情况调整各各位段,方便灵活。
缺点:
- 在单机上是递增的,由于涉及到分布式环境,每台机器上的时钟不可能完全同步,有时也会出现不是全局递增的情况。
- 只能趋势递增。(如果绝对递增,竞对中午下单,第二天再下单即可大概判断该公司的订单量,危险!)
- 依赖机器时间,如果发生回拨会导致可能生成id重复。
时间回拨问题
分析时间回拨产生原因:
1)人为操作,在真实环境一般不会出现,基本可以排除。
2)由于有些业务的需要,机器需要同步时间服务器(在这个过程中可能会存在时间回拨)。
时间问题回拨的解决方法:
1)当回拨时间小于15ms,就等时间追上来后继续生成。
2)当时间大于15ms,通过更换workid来产生之前都没有产生过的来解决。
3)把workid的位数进行调整(15位可以达到3万多,一般够用了)
算法的java实现
点击查看代码
public class SnowflakeIdWorker {
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) timestamp = tilNextMillis(lastTimestamp);//阻塞到下一个毫秒,获得新的时间戳
} else {//时间戳改变,毫秒内序列重置
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift)
| (datacenterId << datacenterIdShift)
| (workerId << workerIdShift)
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
9、MyBatis-Plus的雪花算法工具类
MyBatis-Plus默认用雪花算法
mybatis-plus自3.3.0开始,默认使用雪花算法+UUID(不含中划线),但是它并没有强制让开发者配置机器号。查看了下mybatis-plus雪花算法源码com.baomidou.mybatisplus.core.toolkit.Sequence。最终发现在没有设置机器号的情况下,会通过当前物理网卡地址和jvm的进程ID自动生成。这真的是一个较好的解决方案。一般在一个集群中,MAC+JVM进程PID一样的几率非常小。
MyBatis-Plus生成机器序号的方法是:前5位作为dataCenterId(通过MAC地址生成),后5位作为workerId(通过MAC地址结合JVM的PID生成)。
MyBatis-Plus也提供了一个雪花算法工具类
想用的可以使用:com.baomidou.mybatisplus.core.toolkit.IdWorker。
public static void main(String[] args) {
// 返回值 1385106677482582018
System.out.println(IdWorker.getId());
// 返回值 "1385106677482582019"
System.out.println(IdWorker.getIdStr());
}
这只是个工具类,与MyBatis-Plus和它的ID默认的雪花算法无关。
在github中有一个很流行的分布式统一ID生成框架也叫idworker,需要和mybatis-plus中自带的Idworker工具类区分开来。它是一个基于zookeeper和snowflake算法的分布式统一ID生成工具,通过zookeeper自动注册机器(最多1024台),无需手动指定workerId和dataCenterId。idworker官网:https://github.com/imadcn/idworker
Java全局唯一ID生成策略的更多相关文章
- 【Redis场景拓展】秒杀问题-全局唯一ID生成策略
全局唯一ID 为什么要使用全局唯一ID: 当用户抢购时,就会生成订单并保存到订单表中,而订单表如果使用数据库自增ID就存在一些问题: 受单表数据量的限制 id的规律性太明显 场景分析一:如果我们的id ...
- 分布式全局唯一ID生成策略
为什么分布式系统需要用到ID生成系统 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识.如在美团点评的金融.支付.餐饮.酒店.猫眼电影等产品的系统中,数据日渐增长,对数据库的分库分表后需要有 ...
- 常见分布式全局唯一ID生成策略
全局唯一的 ID 几乎是所有系统都会遇到的刚需.这个 id 在搜索, 存储数据, 加快检索速度 等等很多方面都有着重要的意义.工业上有多种策略来获取这个全局唯一的id,针对常见的几种场景,我在这里进行 ...
- 分布式全局唯一ID生成策略
一.背景 分布式系统中我们会对一些数据量大的业务进行分拆,如:用户表,订单表.因为数据量巨大一张表无法承接,就会对其进行分库分表. 但一旦涉及到分库分表,就会引申出分布式系统中唯一主键ID的生成问题. ...
- 关于全局唯一ID生成方法
引:最近业务开发过程中需要涉及到全局唯一ID生成.之前零零总总的收集过一些相关资料,特此整理以便后用 本博客已经迁移至:http://cenalulu.github.io/ 本篇博文已经迁移,阅读全文 ...
- (4.24)【mysql、sql server】分布式全局唯一ID生成方案
参考:分布式全局唯一ID生成方案:https://blog.csdn.net/linzhiqiang0316/article/details/80425437 分表生成唯一ID方案 sql serve ...
- 分布式系统全局唯一ID生成
一 什么是分布式系统唯一ID 在复杂分布式系统中,往往需要对大量的数据和消息进行唯一标识. 如在金融.电商.支付.等产品的系统中,数据日渐增长,对数据分库分表后需要有一个唯一ID来标识一条数据或消息, ...
- 常见分布式唯一ID生成策略
方法一: 用数据库的 auto_increment 来生成 优点: 此方法使用数据库原有的功能,所以相对简单 能够保证唯一性 能够保证递增性 id 之间的步长是固定且可自定义的 缺点: 可用性难以保证 ...
- mysql全局唯一ID生成方案(二)
MySQL数据表结构中,一般情况下,都会定义一个具有‘AUTO_INCREMENT’扩展属性的‘ID’字段,以确保数据表的每一条记录都可以用这个ID唯一确定: 随着数据的不断扩张,为了提高数据库查询性 ...
- 十位用户唯一ID生成策略
新浪微博和twitter 等系统都有一窜数字ID来标示一个唯一的用户,这篇文章就是记录如何实现这种唯一数字ID 原理:使用MYSQL 自增ID 拼接任意字符..然后使用进制转换打乱规则 一般来说实现唯 ...
随机推荐
- list转json tree的工具类
package com.glodon.safety.contingency.job; import com.alibaba.fastjson.JSON; import com.alibaba.fast ...
- 智能工作流:Spring AI高效批量化提示访问方案
基于SpringAI搭建系统,依靠线程池\负载均衡等技术进行请求优化,用于解决科研&开发过程中对GPT接口进行批量化接口请求中出现的问题. github地址:https://github.co ...
- IceRPC之传入响应和拦截器
作者引言 .Net 8.0 下的新RPC 很高兴啊,我们来到了IceRPC之传入响应和拦截器->快乐的RPC, 基础引导,让自已不在迷茫,快乐的畅游世界. 传入响应 Incoming respo ...
- 基于webapi的websocket聊天室(四)
上一篇实现了多聊天室.这一片要继续改进的是实现收发文件,以及图片显示. 效果 问题 websocket本身就是二进制传输.文件刚好也是二进制存储的. 文件本身的传输问题不太,但是需要传输文件元数据,比 ...
- 安装node-sass失败原因及解决办法汇总
node-sass 安装过程 npm 拉下 node-sass包: 根据node版本和node-sass版本拉取对应的binding.node编译器,原因是sass的编译语言比较特殊,需要下载对应版本 ...
- Vue 3入门指南
title: Vue 3入门指南 date: 2024/5/23 19:37:34 updated: 2024/5/23 19:37:34 categories: 前端开发 tags: 框架对比 环境 ...
- WampServer 的安装
一, 下载 wampserver3.2.0_x64.exe 文件 二,在D盘新建wamp64文件 三,以管理员的方式运行安装文件 只有两种语方,选择 English 接受协议 下一步: 点击下一 ...
- 如何从0-1了解 熟悉 精通gitlab
加入gitlab团队项目: 打开其他用户极狐邀请邮件: 点击接受紫色邀请按钮"accept invitation": 选择免费试用90天saas服务: 使用邮箱注册进行邮箱验证[验 ...
- Python OpenCV #1 - OpenCV介绍
一.OpenCV介绍 1.1 OpenCV-Python教程简介 OpenCV由 Gary Bradsky 于1999年在英特尔创立,第一个版本于2000年发布. Vadim Pisarevsky 加 ...
- 什么是Base64算法
HTTP是超文本传输协议,所以HTTP协议中请求.相应都是以ASCII字符方式传输,如果要传输二进制需要经过BASE64或MIME等编码(因为HTTP协议pop3.smtp邮件协议都是针对文本的,而F ...