配置Spark
参考《深入理解Spark:核心思想与源码分析》
Spark使用Scala进行编写,而Scala又是基于JVM运行,所以需要先安装JDK,这个不再赘述。
1.安装Scala
安装获取Scala:
wget http://download.typesafe.com/scala/2.11.5/scala-2.11.5.tgz
将下载的文件移动到自家想要放置的目录。
修改压缩文件的权限为755(所有者读写执行,同组成员读和执行,其他成员读和执行)
chmod 755 scala-2.11.5.tgz
解压缩:
tar -xzvf scala-2.11.5.tgz
打开/etc/profile,添加scala的环境变量
vim /etc/profile

查看scala是否安装成功:
scala

2.安装完scala后,就要安装spark了
只接从网站上下载了spark安装包:
http://spark.apache.org/downloads.html
将安装包移动到自己指定的位置,解压缩。
配置环境变量:
vim /etc/profile
添加spark环境变量

使环境变量生效:
source /etc/profile
进入spark的conf文件目录,
cd /home/hadoop/spark/spark-2.1.0-bin-hadoop2.7/conf
cp spark-env.sh.template spark-env.sh
在spark-env.sh目录中添加java hadoop scala的环境变量

启动spark:
cd /home/hadoop/spark/spark-2.1.0-bin-hadoop2.7/sbin
./start-all.sh
打开浏览器,输入http://localhost:8080
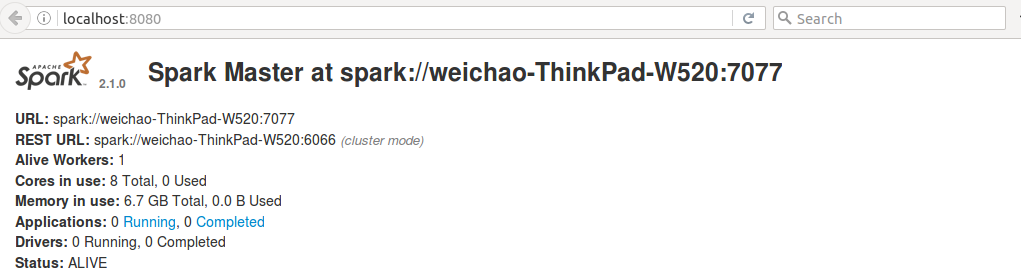
可见Spark已经运行了。
http://blog.csdn.net/wuliu_forever/article/details/52605198这个博客写的很好
配置Spark的更多相关文章
- 配置Spark on YARN集群内存
参考原文:http://blog.javachen.com/2015/06/09/memory-in-spark-on-yarn.html?utm_source=tuicool 运行文件有几个G大,默 ...
- CentOS 7.0下面安装并配置Spark
安装环境: 虚拟机:VMware® Workstation 8.0.1(网络桥接) OS:CentOS 7 JDK版本:jdk-7u79-linux-x64.tar Scala版本:scala-2.1 ...
- spark快速入门之最简配置 spark 1.5.2 hadoop 2.7 配置
配置的伪分布式,ubuntu14.04上 先配置hadoop,参见这个博客,讲的很好 http://www.powerxing.com/install-hadoop/, 但是我在配的过程中还是遇到了问 ...
- 安装配置Spark集群
首先准备3台电脑或虚拟机,分别是Master,Worker1,Worker2,安装操作系统(本文中使用CentOS7). 1.配置集群,以下步骤在Master机器上执行 1.1.关闭防火墙:syste ...
- Linux中安装配置spark集群
一. Spark简介 Spark是一个通用的并行计算框架,由UCBerkeley的AMP实验室开发.Spark基于map reduce 算法模式实现的分布式计算,拥有Hadoop MapReduce所 ...
- 配置spark集群
配置spark集群 1.配置spark-env.sh [/soft/spark/conf/spark-env.sh] ... export JAVA_HOME=/soft/jdk 2.配置slaves ...
- linux上配置spark集群
环境: linux spark1.6.0 hadoop2.2.0 一.安装scala(每台机器) 1.下载scala-2.11.0.tgz 放在目录: /opt下,tar -zxvf scal ...
- 在win10环境下IED配置spark项目
eclipse在对spark的支持上并不友好,所以需要新下载并安装IntelliJ IDEA 2019.1.我下载安装的是专业版的,直接在网上搜索了破解码进行破解. 1. 配置java和scala I ...
- Windows32或64位下载安装配置Spark
[学习笔记] Windows 32或64位下载安装配置Spark:1)下载地址:http://spark.apache.org/downloads.html 马克-to-win @ 马克java社区: ...
- Jupyter配置Spark开发环境
兄弟连大数据培训和大家一起探究Jupyter配置 Spark 开发环境 简介 为Jupyter配置Spark开发环境,可以安装全家桶–Spark Kernel或Toree,也可按需安装相关组件. 考虑 ...
随机推荐
- Coroutine的原理以及实现
最近在写WinForm,在UI界面需要用到异步的操作,比如加载数据的同时刷系进度条,WinForm提供了不少多线程的操作, 但是多线程里,无法直接修改主线程里添加的UI的get/set属性访问器(可以 ...
- docker学习------docker私有仓库的搭建
192.168.138.102:23451.私有仓库的搭建(docker pull registry),拉取最新的镜像 2.查看拉取的仓库镜像(docker images) 3.启用registry镜 ...
- 使用IntelliJ IDEA 配置Maven(转)
1. 下载Maven 官方地址:http://maven.apache.org/download.cgi 解压并新建一个本地仓库文件夹 2.配置本地仓库路径 3.配置maven环境变量 4.在Inte ...
- tomcat7的安装与maven安装
tomcat7的安装与配置: 下载tomcat7 :wget 地址 解压:tar -zxvf 文件名 编辑tomcat目录下的conf下的server.xml文件: <Connector por ...
- 集成方法 Boosting原理
1.Boosting方法思路 Boosting方法通过将一系列的基本分类器组合,生成更好的强学习器 基本分类器是通过迭代生成的,每一轮的迭代,会使误分类点的权重增大 Boosting方法常用的算法是A ...
- PageUtil.java分页工具类
package com.chabansheng.util; /** * 分页工具类 * @author Administrator * */ public class PageUtil { /** * ...
- 逆元知识普及(进阶篇) ——from Judge
关于一些逆元知识的拓展 刚艹完一道 提高- 的黄题(曹冲养猪) ,于是又来混一波讲解了 ——承接上文扫盲篇 四.Lucas定理(求大组合数取模) 题外话 这里Lucas定理的证明需要用到很多关 ...
- JDBC连接MariaDB:数据传输加密
环境:win7+springboot+mybatis+mariadb 需求说明: 未做安全加固前用wireshark抓包: 可以很明显看到用户名.数据库和 SQL,这种情况是有安全风险的. 1.下载o ...
- Misc杂项隐写题writeup
MISC-1 提示:if you want to find the flag, this hint may be useful: the text files within each zip cons ...
- PHP -- 七牛云 在线视频 获取某一帧作为封面图
### 最近碰到视频处理,需要视频封面? 但用的是七牛云存储视频,索性搜了一下,怎么获取视频的某一帧作为视频的封面图... 发现了七牛官网又自身的接口 ### https://developer.qi ...