机器学习基石7-The VC Dimension
注:
文章中所有的图片均来自台湾大学林轩田《机器学习基石》课程。
笔记原作者:红色石头
微信公众号:AI有道
前几节课着重介绍了机器能够学习的条件并做了详细的推导和解释。机器能够学习必须满足两个条件:
- 当假设空间\(\mathcal{H}\)的Size M是有限的时候,则\(N\)足够大的时候,对于假设空间中任意一个假设\(g\),都有\(E_{out}\approx E_{in}\) 。
- 利用算法A从假设空间\(\mathcal{H}\)中,挑选一个\(g\),使\(E_{in}(g)\approx 0\),则\(E_{out}\approx 0\)。
这两个条件,正好对应着test和trian两个过程。train的目的是使损失期望\(E_{in}(g)\approx 0\);test的目的是使将算法用到新的样本时的损失期望也尽可能小,即\(E_{out}(g)\approx 0\)。
因此,上次课引入了break point,并推导出只要break point存在,则\(M\)有上界(成长函数\(m_H(N)\)),一定存在\(E_{out}\approx E_{in}\)。
本节课主要介绍VC Dimension的概念,同时也总结VC Dimension与\(E_{in}(g)\approx 0\)、\(E_{out}(g)\approx 0\)、Model Complexity Penalty的关系。
一、Definition of VC Dimension
首先,我们知道如果一个假设空间\(\mathcal{H}\)有break point \(k\),那么它的成长函数是有界的,它的上界称为Bound function。根据数学归纳法,Bound function也是有界的,且上界为\(N^{k-1}\)。从下面的表格可以看出,\(N^{k-1}\)比\(B(N,k)\)松弛很多。

根据上一节课的推导,VC bound转化为:
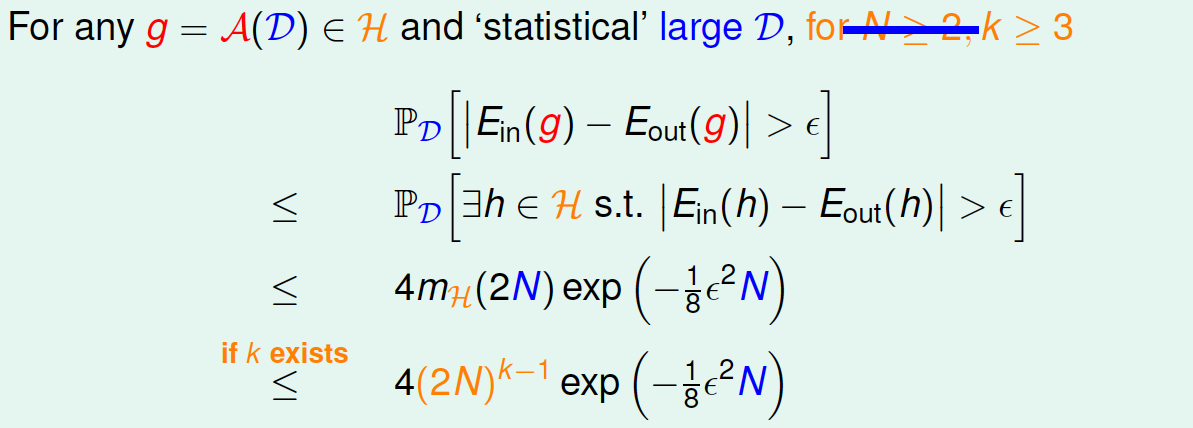
如此一来,不等式只与\(k\)和\(N\)相关,一般情况下样本\(N\)足够大,只考虑\(k\)值,有如下结论:
- 若假设空间\(\mathcal{H}\)有break point \(k\),且\(N\)足够大,则根据VC bound理论,算法有良好的泛化能力,即出现坏事情的机率非常低
- 在假设空间中选择一个\(g\),使得\(E_{in}\approx 0\),则其在全局数据中的错误率也会比较低

接下来,根据break point介绍一个新的名词:VC Dimension。注意,break point的定义是,假设集不能被shatter的任何分布类型的inputs的最少个数。VC Dimension就是某假设集\(\mathcal{H}\)能够shatter的最多inputs的个数,只要存在一种分布的inputs能够被shatter就可以。根据定义,可以看到,VC Dimension 等于break point 的个数减一。

回顾之前的案例,它们对应的VC Dimension:
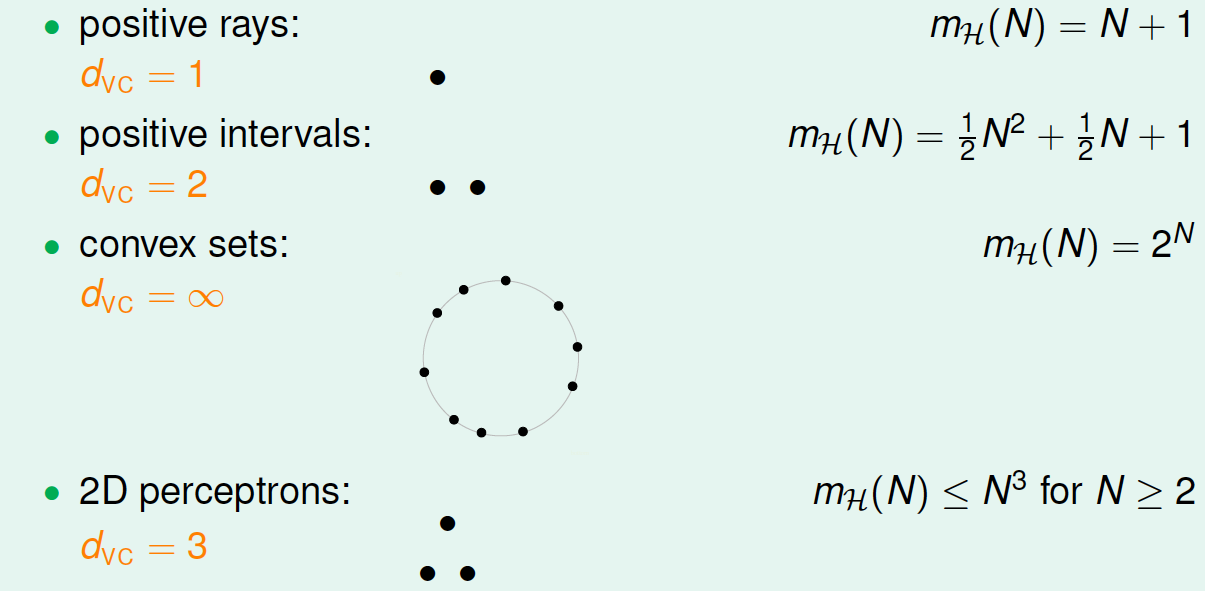
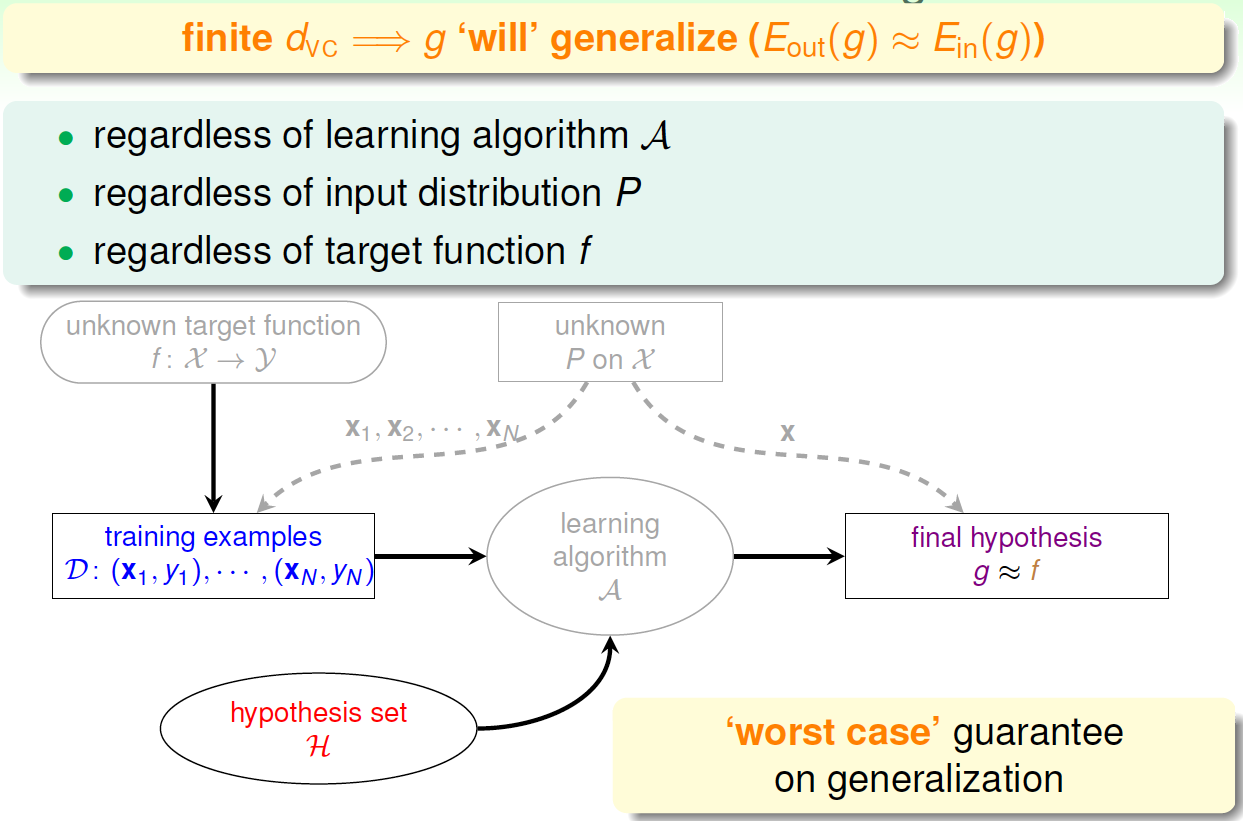
用\(d_{vc}\)代替\(k\),那么VC bound的问题也就转换为与\(d_{vc}\)和\(N\)相关了。同时,如果一个假设集\(\mathcal{H}\)的\(d_{vc}\)确定了,则就能满足机器能够学习的第一个条件\(E_{out}\approx E_{in}\),与算法、
样本数据分布和目标函数都没有关系。
二、VC Dimension of Perceptrons
回顾一下之前介绍的2D下的PLA算法,已知Perceptrons的\(k=4\),即\(d_{vc}=3\)。根据VC Bound理论,当\(N\)足够大的时候,\(E_{out}(g)\approx E_{in}(g)\) 。如果找到一个\(g\),使\(E_{in}(g)\approx 0\),那么就能证明PLA是可以学习的。
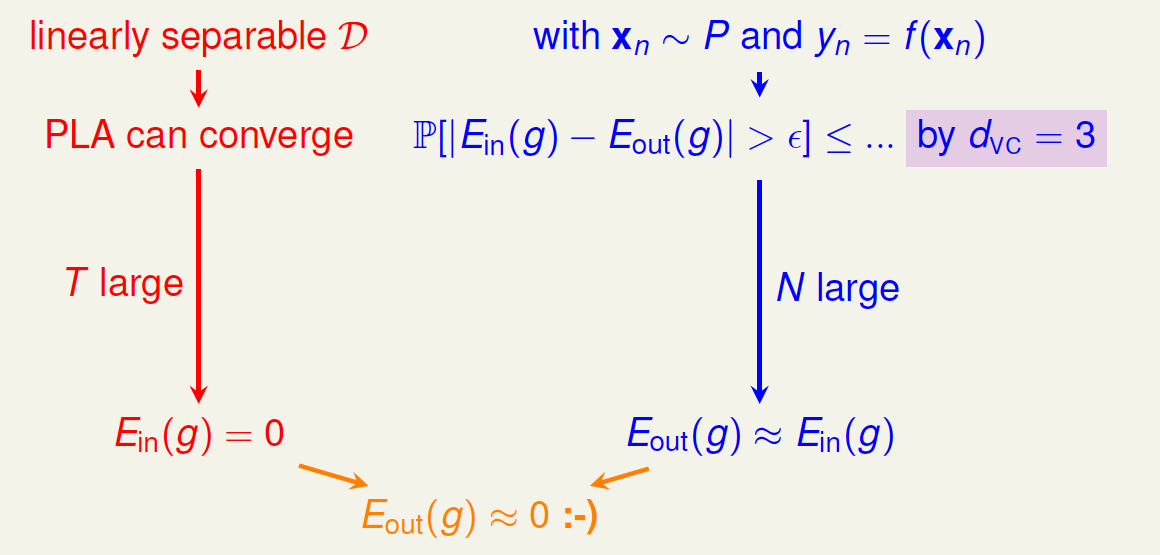
这是在2D情况下,那如果是多维的Perceptron,它对应的\(d_{vc}\)又等于多少呢?
已知在1D Perceptron,\(d_{vc}=2\) ,在2D Perceptrons,\(d_{vc}=3\) ,那么我们有如下假设:\(d_{vc}=d+1\),其中\(d\)为维数。
要证明的话,需要分两步:
- \(d_{vc}\geq d+1\)
- \(d_{vc}\leq d+1\)
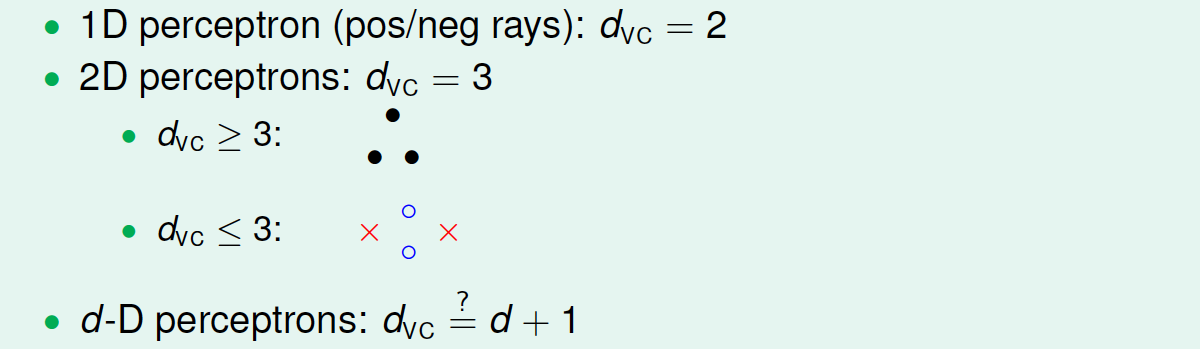
首先证明第一个不等式:\(d_{vc}\geq d+1\) 。
在\(d\)维感知器中,只要找到某一类的\(d+1\)个inputs可以被shatter的,就可以得到\(d_{vc}\geq d+1\)。构造如下一个\(d+1\)维矩阵\(X\):
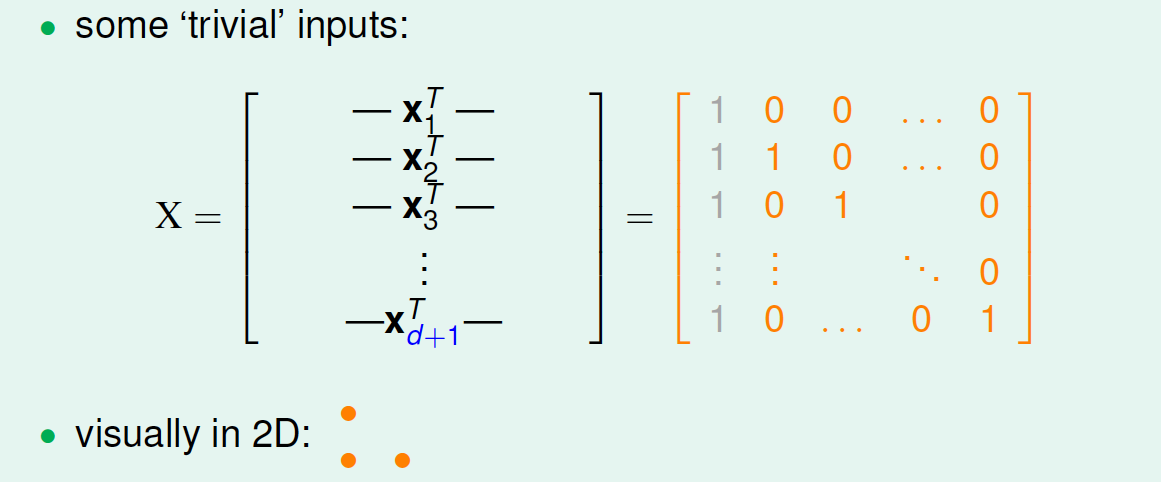
注意到\(X\)是可逆的,对于任意的\(y=\begin{bmatrix}y_1 \\ y_2\\ \cdots \\ y_{d+1}\end{bmatrix}=\begin{bmatrix}\pm 1 \\ \pm 1 \\ \cdots \\ \pm 1\end{bmatrix}\),如果能找到一个向量\(w\)使得\(sign(Xw)=y\),则说明这\(d+1\)个input是可以被shatter的,也就是说\(d_{vc}\geq d+1\), 由于\(X\)是可逆的,所以\(w=X^{-1}y\)就满足条件。
现在证明第二个不等式:\(d_{vc}\geq d+1\) 。
只要证明任意\(d+2\)个inputs,一定不能被shatter。构造一个任意的矩阵\(X\),包含\(d+2\)个inputs,该矩阵有\(d+1\)列,\(d+2\)行。这\(d+2\)个向量的某个向量一定可以被另外\(d+1\)个向量线性表示,例如对于向量\(X_{d+2}\),可表示为: \[X_{d+2}=a_1*X_1+a_2*X_2+...+a_{d+1}*X_{d+1}\]假设\(a_1>0\),\(a_2\),...,\(a_{d+1}\leq 0\),能否找到一个\(w\)使得\(y=sign(Xw)=(sign(a_1),sign(a_2),...,sign(a_{d+1}),\times)\)
假设这样的\(w\)存在,则有\(sign(X_iw)=sign(a_i),i=1,...,d+1\),然而对于这样的\(w\),必有\[X_{d+2}w=a_1*X_1*w+a_2*X_2*w+...+a_{d+1}*X_{d+1}*w>0\]与\(w\)的存在矛盾。所以,找不到这样的\(w\),即任意的\(d+2\)个inputs都不能被shatter,\(d_{vc}\geq d+1\) 。

综上可得\(d_{vc}=d+1\) 。
三、Physical Intuition VC Dimension

上节公式中\(W\)又名features,即自由度。自由度是可以任意调节的,如同上图中的旋钮一样。VC Dimension代表了假设空间的分类能力,即反映了\(\mathcal{H}\)的自由度,产生dichotomy的数量,也就等于features的个数,但不是绝对的。

例如,对2D Perceptrons,线性分类,\(d_{vc}=3\),则\(W={w_0,w_1,w_2}\),也就是说只要3个features就可以进行学习,自由度为3。
可以发现,\(M\)与\(d_{vc}\)是成正比的:

四、Interpreting VC Dimension
下面,更深入地探讨VC Dimension的意义。首先,把VC Bound重新写到这里:

根据之前的泛化不等式,\(|E_{in}-E_{out}|>\epsilon\),即出现bad的情况的概率最大不超过\(\delta\)。那么反过来,对于good的情况发生的概率最小为\(1-\delta\),对上述不等式进行重新推导:

\(\epsilon\)表现了假设空间\(H\)的泛化能力,\(\epsilon\)越小,泛化能力越大。

至此,已经推导出泛化误差\(E_{out}\)的边界,我们更关心的是其上界,即
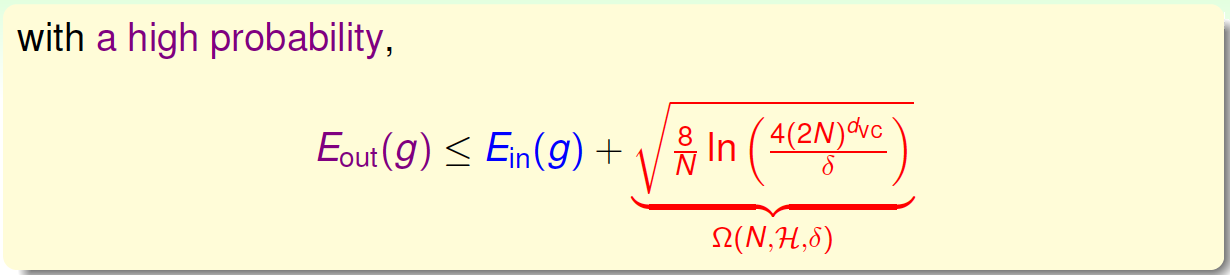
上述不等式的右边第二项称为模型复杂度(Model Complexity Penalty),其模型复杂度与样本数量\(N\)、假设空间\(H\)的VC Dimension、\(\epsilon\)有关。\(E_{out}\)由\(E_{in}\)和模型复杂度共同决定。下面绘制出\(E_{out}\)、Model Complexity 、\(E_{in}\)随\(d_{vc}\)变化的曲线图:

可以看到:
- \(d_{vc}\)越大(假设空间可选择的余地越大),\(E_{in}\)越小,\(\Omega\)越大(复杂)
- \(d_{vc}\)越小(假设空间可选择的余地越小),\(E_{in}\)越大,\(\Omega\)越小(简单)
- 随着\(d_{vc}\)增大,\(E_{out}\)会先减小,再增大
所以为了得到最小的\(E_{out}\),不能一味地增大\(d_{vc}\)以减小\(E_{in}\),因为\(E_{in}\)太小的时候,模型复杂度会增加,造成\(E_{out}\)变大。
下面介绍一个概念:样本复杂度(Sample Complexity)。如果给定\(d_{vc}\),样本数据D选择多少合适呢?通过下面一个例子可以帮助我们理解:

通过计算得到\(N=29300\),刚好满足的条件。\(N\)大约是\(d_{vc}\)的10000倍。这个数值太大了,实际中往往不需要这么多的样本数量,大概只需要\(d_{vc}\)的10倍就够了。\(N\)的理论值之所以这么大是因为VC Bound 过于宽松了,我们得到的是一个比实际大得多的上界。

值得一提的是,VC Bound是比较宽松的,而如何收紧它却不是那么容易,这也是机器学习的一大难题。但是,令人欣慰的一点是,VC Bound基本上对所有模型的宽松程度是基本一致的,所以,不同模型之间还是可以横向比较。从而,VC Bound宽松对机器学习的可行性还是没有太大影响。
五、总结
本节课主要介绍了VC Dimension的概念,即最大的non-break point。然后,我们得到了Perceptrons在\(d\)维度下的VC Dimension是\(d+1\)。接着,我们在物理意义上,将\(d_{vc}\)与自由度联系起来。最终得出结论\(d_{vc}\)不能过大也不能过小。选取合适的值(这个可以自由选择?有待进一步理解),才能让\(E_{out}\)足够小,使假设空间H具有良好的泛化能力。
机器学习基石7-The VC Dimension的更多相关文章
- 【The VC Dimension】林轩田机器学习基石
首先回顾上节课末尾引出来的VC Bound概念,对于机器学习来说,VC dimension理论到底有啥用. 三点: 1. 如果有Break Point证明是一个好的假设集合 2. 如果N足够大,那么E ...
- 【机器学习基石笔记】七、vc Dimension
vc demension定义: breakPoint - 1 N > vc dimension, 任意的N个,就不能任意划分 N <= vc dimension,存在N个,可以任意划分 只 ...
- Coursera台大机器学习课程笔记6 -- The VC Dimension
本章的思路在于揭示VC Dimension的意义,简单来说就是假设的自由度,或者假设包含的feature vector的个数(一般情况下),同时进一步说明了Dvc和,Eout,Ein以及Model C ...
- 机器学习基石12-Nonlinear Transformation
注: 文章中所有的图片均来自台湾大学林轩田<机器学习基石>课程. 笔记原作者:红色石头 微信公众号:AI有道 上一节课介绍了分类问题的三种线性模型,可以用来解决binary classif ...
- 机器学习基石8-Noise and Error
注: 文章中所有的图片均来自台湾大学林轩田<机器学习基石>课程. 笔记原作者:红色石头 微信公众号:AI有道 上一节课,我们主要介绍了VC Dimension的概念.如果Hypothese ...
- 机器学习基石11-Linear Models for Classification
注: 文章中所有的图片均来自台湾大学林轩田<机器学习基石>课程. 笔记原作者:红色石头 微信公众号:AI有道 上一节课,我们介绍了Logistic Regression问题,建立cross ...
- 机器学习基石9-Linear Regression
注: 文章中所有的图片均来自台湾大学林轩田<机器学习基石>课程. 笔记原作者:红色石头 微信公众号:AI有道 上节课,主要介绍了在有noise的情况下,VC Bound理论仍然是成立的.同 ...
- 【Theory of Generalization】林轩田机器学习基石
紧接上一讲的Break Point of H.有一个非常intuition的结论,如果break point在k取到了,那么k+1, k+2,... 都是break point. 那么除此之外,我们还 ...
- VC Dimension -衡量模型与样本的复杂度
(1)定义VC Dimension: dichotomies数量的上限是成长函数,成长函数的上限是边界函数: 所以VC Bound可以改写成: 下面我们定义VC Dimension: 对于某个备选函数 ...
随机推荐
- Python--day09(内存管理、垃圾回收机制)
昨天内容回顾 1. 操作文件的三个步骤: 1. 打开文件:硬盘的空间被操作系统持有,文件对象被用用程序持续 2. 操作文件:读写操作 3. 释放文件:释放操作系统对硬盘空间的持有 2. 基础 ...
- CSS3动画效果transition
1.transition的浏览器支持情况 IE10+支持,IE6\7\8\9都不支持!目前,其他浏览器最新版本都支持,不需要再加前缀 -webkit- 之类的了 2. 还是一步一步说说怎么用trans ...
- Spring 框架中注释驱动的事件监听器详解
事件交互已经成为很多应用程序不可或缺的一部分,Spring框架提供了一个完整的基础设施来处理瞬时事件.下面我们来看看Spring 4.2框架中基于注释驱动的事件监听器. 1.早期的方式 在早期,组件要 ...
- [ffmpeg] h.264解码所用的主要缓冲区介绍
在进行h264解码过程中,有两个最重要的结构体,分别为H264Picture.H264SliceContext. H264Picture H264Picture用于维护一帧图像以及与该图像相关的语法元 ...
- BUGKU Misc 普通的二维码
下载的文件是一个bmp文件,在我的印象中bmp好像没有什么隐写技巧,有些慌张. 既然是二维码,那不妨先扫一下试一试 哈哈!就不告诉你flag在这里! 嗯,意料之中 1首先我把它放到了stegosolv ...
- SWIG 扩展Opencv python调用C++
osx:10.12 g++ 7.1 swig 3.0.12 opencv 3.2.0 SWIG是Simplified Wrapper and Interface Generator的缩写.是Pytho ...
- windows下网络编程UDP
转载 C++ UDP客户端服务器Socket编程 UDPServer.cpp #include<winsock2.h>#include<stdio.h>#include< ...
- 安装redis服务
wget http://download.redis.io/releases/redis-3.2.6.tar.gz tar -zxvf redis-3.2.6.tar.gzcd redis-3.2.6 ...
- marquee标签的使用
marquee语法 <marquee></marquee> 实例一<marquee>Hello, World</marquee> marquee常 ...
- SVG---DEMO
SVG代码: <svg id="circle" data-name="circle_1" xmlns="http://www.w3.org/20 ...