强化学习(八):Eligibility Trace
Eligibility Traces
Eligibility Traces是强化学习中很基本很重要的一个概念。几乎所有的TD算法可以结合eligibility traces获得更一般化的算法,并且通常会更有效率。
Eligibility traces可以将TD和Monte Carlo算法统一起来。之前我们见过n-step方法将二者统一起来,eligibility traces 优于n-step的主要地方在于计算非常有效率,其只需要一个trace向量,而不需要储存n个特征向量。另外,eligibility trace的学习是逐步的,而不需要等到n-steps之后。
Eligibility traces机制是通过一个短期的向量得到的,这个向量称为eligibility trace \(\pmb{z_t} \in R^d\)。正好呼应算法中的权重向量\(\pmb{w_t}\in R^d\). 大致的思想是这样的:当权重向量的某些分量参与到估计价值当中,那么与之相对应的eligibility trace分量也会立即变化,然后变化会慢慢的消失。
强化学习的很多算法都是‘向前看’的算法,即当前状态或动作的价值更新是依赖于未来状态或动作的,这样的 算法称为‘前向视角’。前向视角实施起来多少有些不方便,毕竟未来的事,当前并知道。还有另外一种思路是所谓的‘后向视角’,通过eligibility trace来考虑最近刚刚访问过的状态或动作。
The \(\lambda\)-return
之前定义过n-steps return为最初n rewards加上n步之后的状态的价值估计的总和:
\]
其实一个有效的更新不一定只依赖于n-steps return,可能依赖于多个n-step return的平均会更好,比如:
\]
\(\lambda\)-return 可以理解为一种特殊的平均多个n-step return,它平均所有n-step return:
\]
基于\(\lambda\) return 的学习算法比如off-line \(\lambda\)-return algorithm:
\]
以上其实就是一种前向视角:
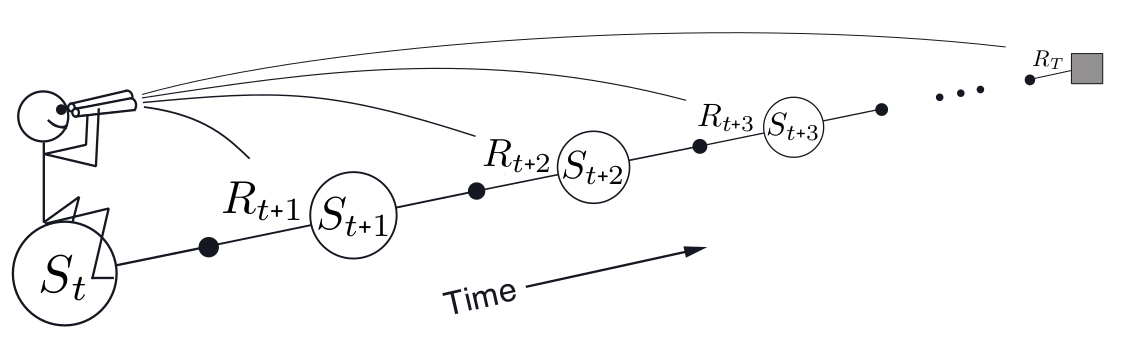
TD(\(\lambda\))
TD(\(\lambda\))是上面off-line \(\lambda\)-return算法的改进,主要有三点:一是它每步更新,二是因为每步更新,它的计算过程分布在每一时间步上,三是它可以应用于连续过程而不仅限于episodic problems。
如上所述,eligibility trace 通过一个向量\(\pmb{z_t}\in R^d\) 实现,其与\(\pmb{w_t}\)维度相同,\(\pmb{w_t}\)可看作是长时记忆,而eligibility trace则是短时记忆。
\]
其中\(\gamma\)是discount rate,\(\lambda\) 是trace decay参数。Eligibility trace记录权重向量各成分在近期状态价值评估中的贡献。
TD error:
\]
那么权重向量的更新:
\]
# semi-gradient TD(lambda) for estimating v_hat = v_pi
Input: the policy pi to be evaluated
Input: a differentiable function v_hat: S_plus x R^d --> R such that v_hat(terminal,.) = 0
Algorithm parameters: step size alpha > 0, trace decay rate lambda in [0,1]
Initialize value-function weights w arbitrarily (e.g. w = 0)
Loop for each episode:
Initialize S
z = 0
Loop for each step of episode:
Choose action A based on pi(.|S)
Take A, observe R,S'
z = gamma * lambda *z + grad V(S,w)
delta = R + gamma v_hat(S',w) - v_hat(S,w)
w = w + alpha delta z
S = S'
until S' is terminal
TD(\(\lambda\))是时间上反向的,从当前状态,向后考虑已经经历过的状态。
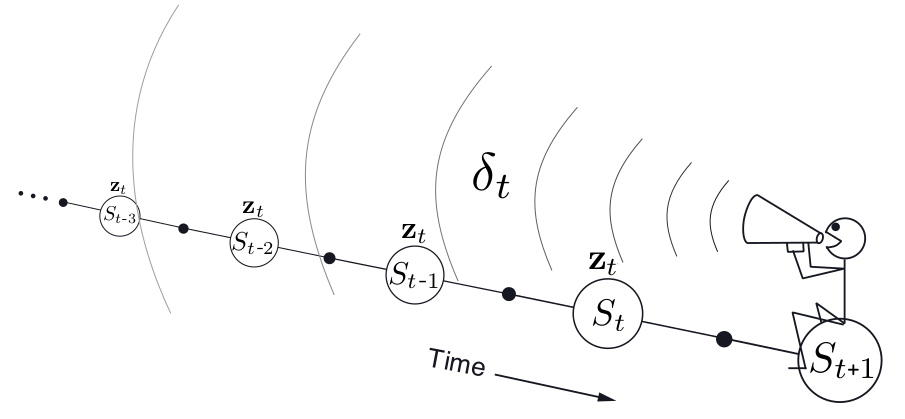
易知,当\(\lambda = 0\) \(TD(\lambda)\)退化成为one step semi-gradient也就是TD(0);当\( = 1\lambda = 1\)时,TD(1)则表现出MC的特征。
n-step Truncated \(\lambda\)-return Methods
线下的\(\lambda-return\)算法具有很大的局限性,因为\(\lambda\)-return要在最后才知道,在连续状态情况下,甚至永远得不到。我们知道,一般\(\gamma\lambda<1\),因此太长时间的状态价值的影响就会消失掉,那么可以想到一种近似\(\lambda\)-return的方法称为Truncated \(\lambda\)-return方法:
\]
同理可以推广出truncated TD(\(\lambda\))(TTD(\(\lambda\))):
\]
此算法可以以一种比较有效率的方式来改写,使其不依赖于n(当然,背后的理论关系还是依赖n的):
\]
其中\(\delta_t' \dot = R_{t+1} + \gamma\hat v(S_{t+1},w_t) -\hat v(S_t,w_{t-1})\).
Redoing Updates: The On-line \(\lambda\)-return Algorithm
TTD(\(\lambda\))中n的选取是要有取舍的,n可以很大,这样更接近off-line \(\lambda\)-return algorithm;或者很小这样更新参数不用等很久。这两种好处增加一些计算复杂度可以都得到。
其思想是这样的:在每一步时,都会得到新的数据,然后从头重新更新。
\]
\(w_t \dot = w_t^t\)此即为on-line \(\lambda\)-return algorithm.
True On-line TD(\(\lambda\))
借助eligibility trace,将on-line \(\lambda\) -return 的前向视角转变成后向视角即成为true on-line TD(\(\lambda\)).
\]
其中$\hat v(s,w) = w^T x(s),\ x_t\dot = x(S_t),\ \delta_t \dot = R_{t+1} +\gamma\hat v(S_{t+1},w_t)- \hat v(S_t,w_t),\ z_t = \dot = \gamma\lambda z_{t-1}+(1-\alpha \gamma\lambda z_{t-1}^Tx_t)x_t $.
# True On-line TD(lambda) for estimating w^T x = v_pi
Input: the policy pi to be evaluated
Input: a feature function x: S_plus --> R such that x(terminal,.) = 0
Algorithm parameters: step size alpha > 0, trace decay rate lambda in [0,1]
Initialize value-function weights w in R
Loop for each episode:
Initialize state and obtain initial feature vector x
z = 0
V_old = 0
Loop for each step of episode:
choose A from pi.
take action A, observe R, x'(feature vector of the next state)
V = w^T x
V' = w^T x'
delta = R + gamma V' - V
z = gamma lambda z + (1- alpha gamma z^T x)x
w = w + alpha(delta + V- V_old)z - alpha (V-V_old) x
V_old = V'
x = x'
until x' = 0(signaling arrival at a terminal state)
这里的eligibility trace 称为 dutch trace, 还有一种称为replacing trace:
\gamma\lambda z_{i,t-1} \qquad otherwise.\end{array}\right.
\]
Dutch Traces in Monte Carlo Learning
Eligibility traces也可应用于Monte Carlo 相产算法之中。
在梯度Monte Carlo算法的线性版本中:
\]
其中G是在episode结束后得到的奖励,因此没有下标,也没有折扣因子。因为MC方法只能在episode结束后更新参数,这个特点我们不试图改进,而是在尽力将计算分布在各个时间步上。
w_T& =& w_{T-1} + \alpha(G - w_{T-1}^Tx_{T-1})x_{T-1}\\
&=& w_{T-1} +\alpha x_{T-1}(-x_{T-1}^Tw_{T-1})+\alpha Gx_{T-1}\\
&=& (I - \alpha x_{T-1}x_{T-1}^T)w_{T-1}+\alpha Gx_{T-1}\\
&=& F_{T-1}w_{T-1}+\alpha Gx_{T-1}
\end{array}
\]
其中\(F_t \dot = I - \alpha x_t x_t^T\)是一个遗忘矩阵或称衰退矩阵(forgetting or fading matrix), 可以递归得到。
Sarsa(\(\lambda\))
Sarsa(\(\lambda\))是一个TD方法,与TD(\(\lambda\))类似,只不过,Sarsa(\(\lambda\))是针对state-action pair的:
\]
其中:
\]
而:
z_{-1} &=& 0,\\
z_t&=& \gamma \lambda z_{t-1}+\nabla\hat q(S_t,A_t,w_t),\qquad 0\le t\le T.
\end{array}
\]
# Sarsa(lambda) with binary features and linear function approximation for estimating # w^T x q_{pi} or q*
Input: a function F(s,a) returning teh set of (indices of ) active features for s,a
Input: a policy pi (if estimating q_pi)
Algorithm parameteres: step size alpha > 0, trace decay rate lambda in [0,1]
Initialize: w= (w1,...,wd)^T in R^d z = (z1,...,z_d)^T in R^d
Loop for each episode:
Initialize S
Choose A from pi(.|S) or e-greedy according to q_hat(S,.,w)
z = 0
Loop for each step of episode:
take action A, observe R,S'
delta = R
Loop for i in F(S,A):
delta = delta - w_i
z_i = z_i + 1 (accumulating traces)
or z_i = 1 (replacing traces)
If S' is terminal then:
w = w + alpha delta z
Go to next episode
Choose A' in pi(.|S) or near greedily q_hat(S',.,w)
Loop for i in F(S',A'): dleta = delta + gamma w_i
w = w + alpha delta z
z = gamma lambda z
S = S', A = A'
# True Online Sarsa(lambda) for estimating w^Tx = q_pi or q*
Input: a feature function x: s_plus x A = R^d such that x(terminal,.) = 0
Input: a policy pi (if estimating q_pi)
Algorithm parameters: step size alpha >0, trace decay rate lambda in [0,1]
Initialize: w in R^d
Loop for each episode:
Initialize S
Choose A from pi(.|S) or nearly greedily from S using w
x = x(S,A)
z = 0
Q_old = 0
Loop for each step of episode:
Take action A, observe R,S'
Choose A' from pi(.|S') or near greedily from S' using w
x' = x(S',A')
Q = w^Tx
Q' = w^Tx'
delta = R + gamma Q' - Q
z = gamma lambda z + (1 - alpha gamma lambda z^T x) x
w = w + alpha(delta + Q - Q_old )z - alpha(Q - Q_old) x
Q_old = Q'
x = x'
A = A'
until S' is terminal
Off-policy Eligibility Traces with Control Variates
Watkins's Q(\(\lambda\)) to Tree-Backup(\(\lambda\))
Stable Off-policy Methods with Traces
强化学习(八):Eligibility Trace的更多相关文章
- 强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces)
强化学习读书笔记 - 12 - 资格痕迹(Eligibility Traces) 学习笔记: Reinforcement Learning: An Introduction, Richard S. S ...
- 强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)
在强化学习(十七) 基于模型的强化学习与Dyna算法框架中,我们讨论基于模型的强化学习方法的基本思路,以及集合基于模型与不基于模型的强化学习框架Dyna.本文我们讨论另一种非常流行的集合基于模型与不基 ...
- 【转载】 强化学习(八)价值函数的近似表示与Deep Q-Learning
原文地址: https://www.cnblogs.com/pinard/p/9714655.html ------------------------------------------------ ...
- 强化学习(八)价值函数的近似表示与Deep Q-Learning
在强化学习系列的前七篇里,我们主要讨论的都是规模比较小的强化学习问题求解算法.今天开始我们步入深度强化学习.这一篇关注于价值函数的近似表示和Deep Q-Learning算法. Deep Q-Lear ...
- 强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods)
强化学习读书笔记 - 13 - 策略梯度方法(Policy Gradient Methods) 学习笔记: Reinforcement Learning: An Introduction, Richa ...
- adaptive heuristic critic 自适应启发评价 强化学习
https://www.cs.cmu.edu/afs/cs/project/jair/pub/volume4/kaelbling96a-html/node24.html [旧知-新知 强化学习:对 ...
- 【强化学习RL】model-free的prediction和control —— MC,TD(λ),SARSA,Q-learning等
本系列强化学习内容来源自对David Silver课程的学习 课程链接http://www0.cs.ucl.ac.uk/staff/D.Silver/web/Teaching.html 本文介绍了在m ...
- 强化学习(十九) AlphaGo Zero强化学习原理
在强化学习(十八) 基于模拟的搜索与蒙特卡罗树搜索(MCTS)中,我们讨论了MCTS的原理和在棋类中的基本应用.这里我们在前一节MCTS的基础上,讨论下DeepMind的AlphaGo Zero强化学 ...
- 强化学习(五)用时序差分法(TD)求解
在强化学习(四)用蒙特卡罗法(MC)求解中,我们讲到了使用蒙特卡罗法来求解强化学习问题的方法,虽然蒙特卡罗法很灵活,不需要环境的状态转化概率模型,但是它需要所有的采样序列都是经历完整的状态序列.如果我 ...
随机推荐
- Oracle中row_number()、rank()、dense_rank() 的区别
link:https://www.cnblogs.com/qiuting/p/7880500.html
- 【转】jenkins+gitlab配置遇到问题
搭建jenkins+gitlab拉取代码失败,日志如下: ERROR: Error fetching remote repo 'origin'hudson.plugins.git.GitExcepti ...
- python:sys.exit() os._exit() exit() quit()
1>sys.exit() >>> import sys>>> help(sys.exit)Help on built-in function exit in ...
- 【SparkStreaming学习之四】 SparkStreaming+kafka管理消费offset
环境 虚拟机:VMware 10 Linux版本:CentOS-6.5-x86_64 客户端:Xshell4 FTP:Xftp4 jdk1.8 scala-2.10.4(依赖jdk1.8) spark ...
- Navicat Premium 简体中文版 12.0.16 以上版本国外官网下载地址(非国内)
国内Navicat网址是:http://www.navicat.com.cn 国外Navicat网址是:http://www.navicat.com 国外的更新比国内的快,而且同一个版本,国内和国外下 ...
- vue-cli —— 项目打包及一些注意事项
打包方法: 1.把绝对路径改为相对路径:打开config/index.js 会看到一个build属性,这里就是我们打包的基本配置了.在这里可以修改打包的目录,打包的文件名.最重要的是一定要把绝对目录改 ...
- connect设置连接超时
转自:庖丁解牛 /** * connect_timeout - 带超时的connect(方法中已执行connect) * @fd:文件描述符 * @addr:地址结构体指针 * @wait_secon ...
- 手机APP应用外网访问本地WEB应用
手机APP应用外网访问本地WEB应用 本地安装了WEB服务端,手机APP应用只能在局域网内访问本地WEB,怎样使手机APP应用从公网也能访问本地WEB? 本文将介绍具体的实现步骤. 1. 准备工作 1 ...
- vue-cli3.0+node.js+axios跨域请求session不一样的问题
一.问题重述 使用的是,前后端分离,前端vue+axios请求,后端使用node搭建服务端接口,遇到的问题是,我通过登录接口吧数据存储型在session,我登录上以后,发现再次验证登录(另一个接口)的 ...
- get 和 post 请求的区别,一个不错的链接
https://www.cnblogs.com/logsharing/p/8448446.html