[十一]基础数据类型之Character
Character与Unicode

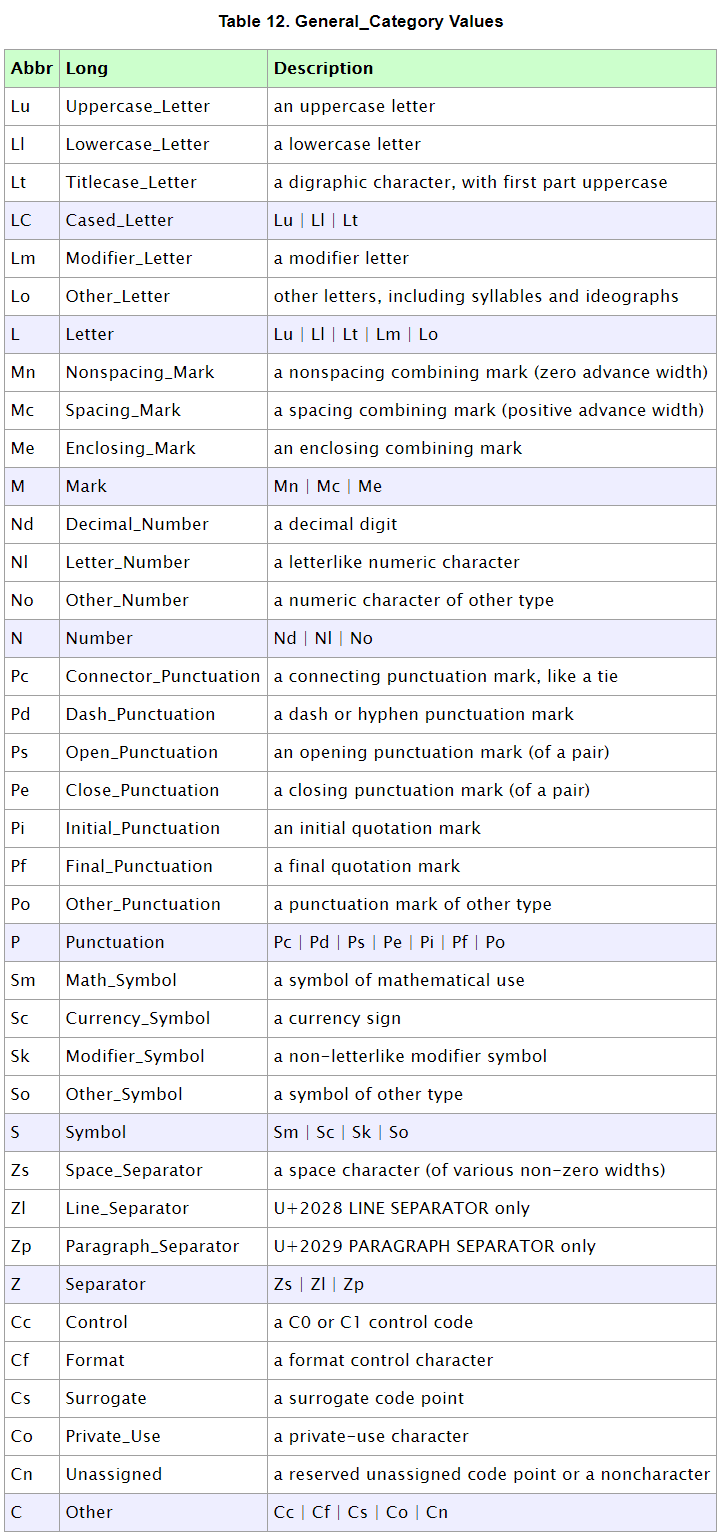
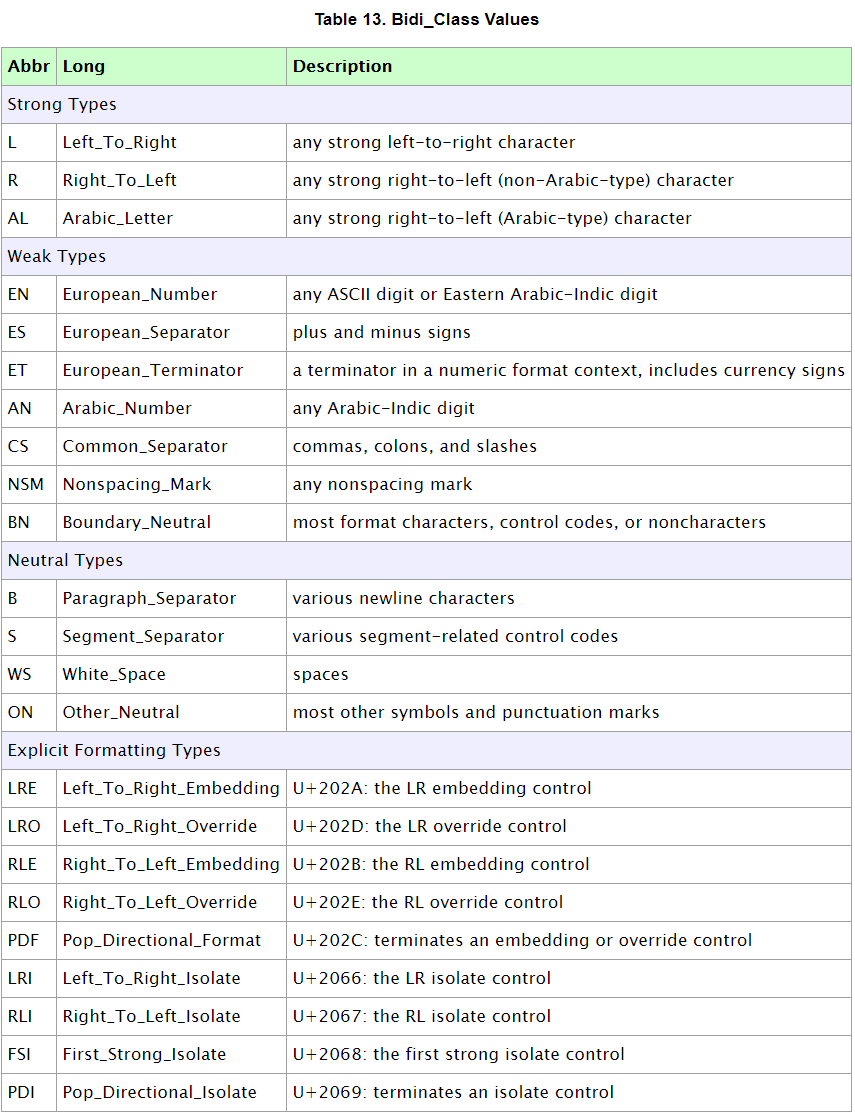
| Character 类的方法和数据是通过 UnicodeData 文件中的信息定义的
char 数据类型(和 Character 对象封装的值)基于原始的 Unicode 规范
提供的方法和数据也是基于Unicode规范来的
|
|
他将字符定义为固定宽度的 16 位实体,也就是只能表示一个代码单元
而Unicode也可能是有两个代码单元组成
也就是一个代码单元可能完整的表示了一个代码点,也可能是一个代码点的一部分
|
|
除非你真的有必要对UTF-16中的代码单元进行操作,
否则最好不要在程序中使用char类型的原因
原因很简单,一个char并不一定能够代表一个字符,可能只是一半字符
|
常用属性
| 无符号二进制形式表示 char 值的位数 |
public static final int SIZE = 16; |
| 无符号二进制形式表示 char 值的字节数 |
public static final int BYTES = SIZE / Byte.SIZE; |
| 表示基本类型 char 的 Class 实例 |
public static final Class<Character> TYPE = (Class<Character>) Class.getPrimitiveClass("char"); |
| 常量值是 char 类型的最小值,即 '\u0000' | public static final char MIN_VALUE = '\u0000'; |
| 常量值是 char 类型的最大值,即 '\uFFFF' | public static final char MAX_VALUE = '\uFFFF' |
| Unicode代码点的最小值 | public static final int MIN_CODE_POINT = 0x000000; |
| Unicode代码点的最大值 | public static final int MAX_CODE_POINT = 0X10FFFF; |
| UTF-16 编码中的 Unicode 高代理项代码单元的最小值 | public static final char MIN_HIGH_SURROGATE = '\uD800'; |
| UTF-16 编码中的 Unicode 高代理项代码单元的最大值 | public static final char MAX_HIGH_SURROGATE = '\uDBFF'; |
| UTF-16 编码中的 Unicode 低代理项代码单元的最小值 | public static final char MIN_LOW_SURROGATE = '\uDC00' |
| UTF-16 编码中的 Unicode 低代理项代码单元的最大值 | public static final char MAX_LOW_SURROGATE = '\uDFFF' |
| 代理项的最小值 也就是高代理项的最小值 |
public static final char MIN_SURROGATE = MIN_HIGH_SURROGATE; |
| 代理项的最大值 也就是低代理项的最大值 |
public static final char MAX_SURROGATE = MAX_LOW_SURROGATE; |
| 增补代码点的最小值 也就是除了0号平面的第一个值 |
public static final int MIN_SUPPLEMENTARY_CODE_POINT = 0x010000 |
| 可用于与字符串相互转换的最大基数 | public static final int MAX_RADIX = 36; |
| 可用于与字符串相互转换的最小基数 | public static final int MIN_RADIX = 2 |
构造方法
| Character(char) | 只有一种形式的构造方法 直接设置value的值 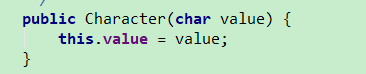 |
常用方法
比较
| compare(char, char) |
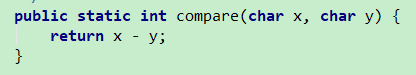 看起来可能会有人觉得奇怪,怎么还能直接减法? 其实char不就是一个UTF-16的代码单元么,他不就是一个十六进制数么 如下图所示,0x0058 - 0x002B 得到的值的十进制就是45 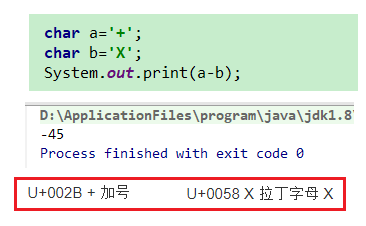 比较的也就是前后顺序了 |
| compareTo(Character) | 实例方法 借助于静态方法  |
valueOf
| valueOf系列一直都是将基本类型包装为对象类型,此处也是如此 Character也是有缓存的 |
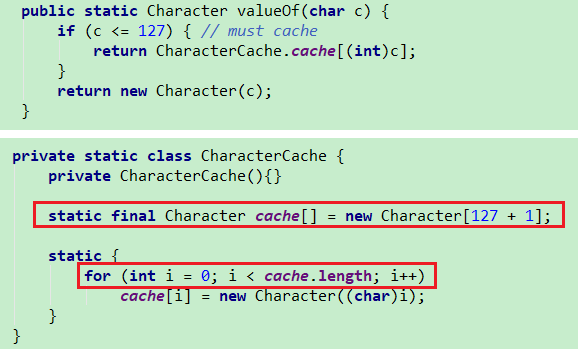 |
XXXValue
| charValue() | 直接返回基本类型数据 |
toString

equals

hashcode
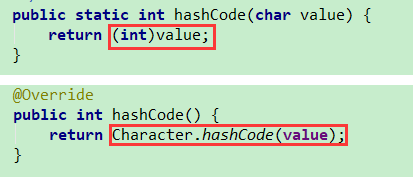
reverseBytes
ch)

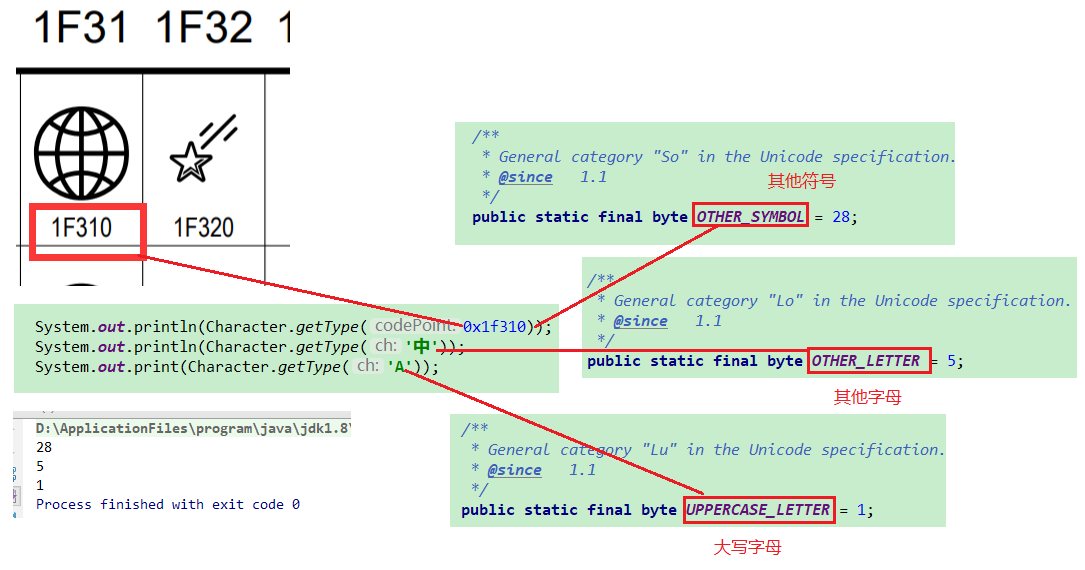
getType
toChars
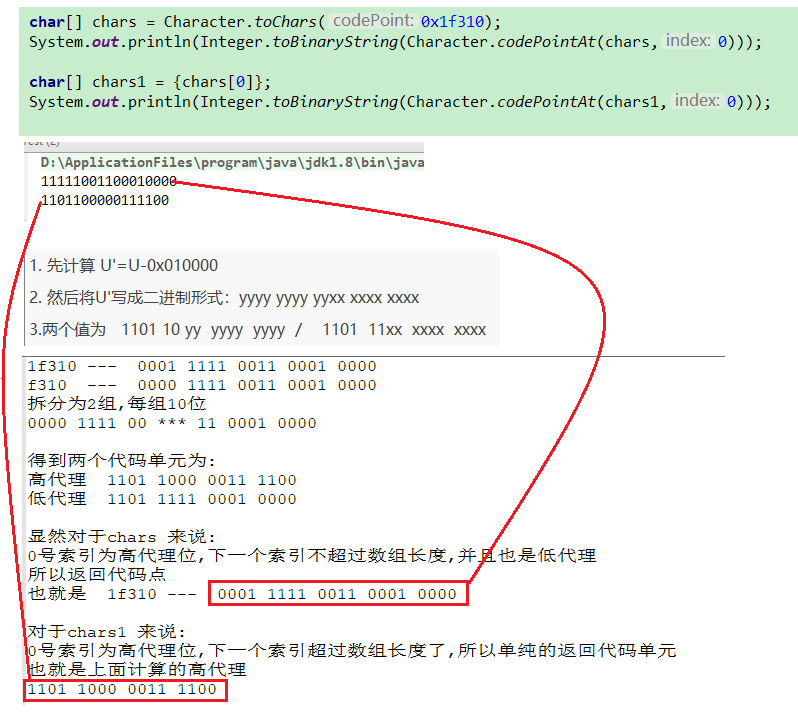
| public static int toChars(int codePoint, char[] dst, int dstIndex) |
保存到指定的数组的指定位置 如果0号平面内 dst[dstIndex] 中存储相同的值,并返回 1 如果辅助平面 dst[dstIndex]高代理 dst[dstIndex+1]低代理返回2 |
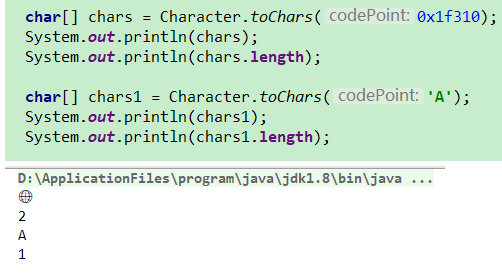
| public static char[] toChars(int codePoint) |
返回一个char数组保存指定代码点 |
codePointCount

offsetByCodePoints
|
public static int offsetByCodePoints(char[] a,
int start,
int count,
int index,
int
codePointOffset) |
|
public static int offsetByCodePoints(CharSequence seq,
int index,
int
codePointOffset) |
codePointAt
|
public static int codePointAt(char[] a, int index)
|
|
public static int codePointAt(CharSequence seq, int index)
|
|
public static int codePointAt(char[] a, int index, int limit )
|
codePointBefore
是一个数组内的有效数据
>=start了
|
public static int codePointBefore(CharSequence seq,int index)
|
|
public static int codePointBefore(char[] a, int index)
|
|
public static int codePointBefore(char[] a, int index, int start
) |
charCount
0x10000,则该方法返回的值为 2。否则,该方法返回的值为 1

toLowerCase / toUpperCase
/toTitleCase
|
toLowerCase(char)
toLowerCase(int)
|
|
toUpperCase(char)
toUpperCase(int)
|
|
toTitleCase(char)
toTitleCase(int)
|
代码点获取
| public static char highSurrogate(int codePoint) |
返回代码点的高代理 如果不是辅助平面的字符,返回未知char |
| public static char lowSurrogate(int codePoint) |
返回代码点的低代理 如果不是辅助平面的字符,返回未知char |
代理位信息判断
| public static boolean isSurrogate(char ch) |
是否代理部分 |
| public static boolean isSurrogatePair(char high, char low) |
是否是代理对 |
| public static boolean isHighSurrogate(char ch) |
是否是高代理 |
| public static boolean isLowSurrogate(char ch) |
是否是低代理 |
代码点信息的校验
| public static boolean isValidCodePoint(int codePoint) |
是否是合法的代码点 确定指定的代码点是否为从 0x0000 到 0x10FFFF 范围之内的有效 Unicode 代码点值 |
| public static boolean isBmpCodePoint(int codePoint) |
是否位于0号平面,是的话就可以使用一个char表示了 |
| public static boolean isSupplementaryCodePoint(int codePoint) |
是否位于辅助平面 辅助平面必然需要使用两个char |
toCodePoint(char, char)
|
public static int toCodePoint(char high,char low)
将指定的代理项对转换为其增补代码点值。该方法没有验证指定的代理项对
如有必要,调用者必须使用 isSurrogatePair 验证它
就是高代理 低代理的合并
|
isXXX 系列
|
小写?
isLowerCase(char)
isLowerCase(int)
|
大写?
isUpperCase(char)
isUpperCase(int)
|
首字母大写?
isTitleCase(char)
isTitleCase(int)
|
|
数字?
isDigit(char)
isDigit(int)
|
被定义为 Unicode 中的字符?
isDefined(char)
isDefined(int)
|
字母?
isLetter(char)
isLetter(int)
|
|
字母或数字?
isLetterOrDigit(char)
isLetterOrDigit(int)
|
是否能够作为 Java 标识符中的首字符?
isJavaIdentifierStart(char)
isJavaIdentifierStart(int)
|
是否能够作为 Java 标识符中的首字符以外的字符?
isJavaIdentifierPart(char)
isJavaIdentifierPart(int)
|
|
是否允许作为 Unicode 标识符中的首字符?
isUnicodeIdentifierStart(char)
isUnicodeIdentifierStart(int)
|
是否允许作为 Unicode 标识符中的首字符以外的字符?
isUnicodeIdentifierPart(char)
isUnicodeIdentifierPart(int)
|
是否是 Java 标识符或 Unicode 标识符中可忽略的一个字符?
isIdentifierIgnorable(char)
isIdentifierIgnorable(int)
|
|
空白字符?
isSpaceChar(char)
isSpaceChar(int)
|
Java 标准是否为空白字符?
isWhitespace(char)
isWhitespace(int)
|
ISO 控制字符?
isISOControl(char)
isISOControl(int)
|
| 字母? isAlphabetic(int) |
中日越韩文字? isIdeographic(int) |
依据 Unicode 规范是否对称?
isMirrored(char)
isMirrored(int)
|
|
UPPERCASE_LETTER LOWERCASE_LETTER TITLECASE_LETTER MODIFIER_LETTER OTHER_LETTER LETTER_NUMBER
|
|
UPPERCASE_LETTER LOWERCASE_LETTER TITLECASE_LETTER MODIFIER_LETTER OTHER_LETTER
|
| 返回使用指定基数的 字符 ch/Unicode 代码点 的数值 |
public static int digit(char ch, int radix)
public static int digit(int codePoint, int radix)
|
| 确定使用指定基数的特定数字的字符表示形式 | public static char forDigit(int digit, int radix) |
| 返回给定字符的 Unicode 方向属性 |
public static byte getDirectionality(char ch)
public static byte getDirectionality(int codePoint)
|
| 返回指定的 Unicode 字符/Unicode 代码点 表示的int值 |
public static int getNumericValue(char ch)
public static int getNumericValue(int codePoint)
|
| 返回指定字符codePoint的Unicode名称,如果代码点未被分配,则返回null | public static String getName(int codePoint) |
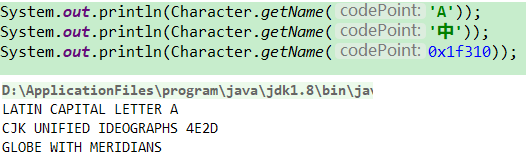
总结
[十一]基础数据类型之Character的更多相关文章
- Java 基础复习 基础数据类型与包装器类型
Java 基础 基础数据类型与包装器类型 基础数据类型 java 中包含哪些基础数据类型,默认值分别是多少? 基础数据类型 byte short int long double float char ...
- 【Swift】学习笔记(一)——熟知 基础数据类型,编码风格,元组,主张
自从苹果宣布swift之后,我一直想了解,他一直没有能够把它的正式学习,从今天开始,我会用我的博客来驱动swift得知,据我们了解还快. 1.定义变量和常量 var 定义变量,let定义常量. 比如 ...
- java基础数据类型包装类
*/ .hljs { display: block; overflow-x: auto; padding: 0.5em; color: #333; background: #f8f8f8; } .hl ...
- day2(基础数据类型)
一.基础数据类型操作 1.数字 int 数字主要是用于计算用的,使用方法并不是很多,就记住一种就可以: int.bit_length() -> int Number of bits necess ...
- c# CTS 基础数据类型笔记
C#中的基础数据类型并没有内置于c#语言中,而内置于.net freamework. C#有15个预定义类型,其中13个是值类型,两个是引用类型(string和object) 一.值类型 值类型 数据 ...
- Python中的基础数据类型
Python中基础数据类型 1.数字 整型a=12或者a=int(2),本质上各种数据类型都可看成是类,声明一个变量时候则是在实例化一个类. 整型具备的功能: class int(object): & ...
- day01——python初始、变量、常量、注释、基础数据类型、输入、if
python的历史: 04年Django框架诞生了 内存回收机制是什么(面试题) python2:源码不统一,有重复的功能代码 python3:没有重复的功能代码 python是一个什么的编程语言 编 ...
- Java 基础数据类型
Java 提供的基础数据类型(也称内置数据类型)包含:整数类型.浮点类型.字符类型.布尔类型. 整数类型 整数类型变量用来表示整数的数据类型.整数类型又分为字节型(byte).短整型(short).整 ...
- PostgreSQL的基础数据类型分析记录-转
src:http://www.codeweblog.com/postgresql%E7%9A%84%E5%9F%BA%E7%A1%80%E6%95%B0%E6%8D%AE%E7%B1%BB%E5%9E ...
随机推荐
- 【安全性测试】drozer中关于AttackSurface的一些理解
在推荐扫描Android APP的工具中,扫描组件可以推荐drozer.使用过drozer的使用者知道,如何查找各个组件上的攻击层面 run app.package.AttackSurface . 它 ...
- javascript js原生ajax post请求 实例
HTML代码: 注意: xmlhttp.setRequestHeader("Content-Type", "application/x-www-form-urlencod ...
- margin与padding的bug
1.在页面布局时,值对于块元素来说,相邻的两个兄弟块元素间的margin-top与上一个兄弟的margin-bottom重合时, 解决办法:对其中一个块元素中设置 display:inline- ...
- UI框架
一,框架构成:目录分别有bin,lib,page,report,test_case,(百度网盘) 1.bin>run.py 2.lib>HTMLTestRunner.py lib>l ...
- vue+element-ui之tree树形控件有关子节点和父节点之间的各种选中关系详解
做后端管理系统,永远是最蛋疼.最复杂也最欠揍的事情,也永远是前端开发人员最苦逼.最无奈也最尿性的时刻.蛋疼的是需求变幻无穷,如同二师兄的三十六般变化:复杂的是开发难度寸步难行,如同蜀道难,难于上青天: ...
- DOM-基本概念及使用
1.获取元素的方式总结 1.根据 id 的属性的值获取元素,返回值是一个元素对象 document.getElementById("id属性的值"); 2.根据标签名获取元素,返回 ...
- linux学习:curl与netcat用法整理
CURL 语法: curl [option] [url] 常用参数:-A/--user-agent <string> 设置用户代理发送给服务器-b/--cookie <name=st ...
- 基础SQL语句用法
1.插入数据:Insert 2.更新数据:update 每行金额增加100 3.删除数据:delete 4.查询:select 1)精确查询 2)模糊查询:like 模糊查询 % 匹配 3)Betw ...
- 不会git的程序员,会不会被鄙视?
昨天一朋友在微信上问了我一个问题,我觉得很有趣,于是将本次聊天的内容分享给大家. 我朋友说,如果一个程序员不会使用 git,会不会被别人觉得低一个档次? 事先声明啊,这与公司技术栈无关,不要说有些公司 ...
- vue本地项目设置通过手机访问
最近再用vue写一个移动端的应用,想通过手机访问看看页面效果,于是有了下文. 1.shif+右键打开命令行工具,输入ipconfig,回车,得到电脑的ip 2.找到工作目录下的config文件夹中的i ...