I/O模型系列之二:Unix的五种网络I/O模型
1. Unix的五种I/O模型
从上往下:阻塞程度(高-----低)I/O效率 (低-----高)
阻塞I/O(Blocking I/O):传统的IO模型
非阻塞I/O(Non-Blocking I/O): 注意这里所说的NIO并非Java的NIO(New IO)库。
I/O多路复用(I/O Multiplexing): 经典的Reactor设计模式,有时也称异步阻塞IO,Java中的Selector和Linux中的epoll都是这种模型。
信号驱动I/O(Signal Driven I/O)
异步I/O(Asychronous I/O): 经典的Proactor设计模式,也称为异步非阻塞IO。
2. Unix的输入操作
Unix的一个输入操作一般有两个不同的阶段:
第一步,等待数据准备好。(目标:减小便可以提高效率)
第二步,从内核到进程拷贝数据。
对于一个套接口上的输入操作(两次拷贝):
第一步,等待数据到达网络,当分组到达时,它被拷贝到内核中的某个缓冲区。
第二步,将数据从内核缓冲区拷贝到应用缓冲区。
3. 阻塞I/O
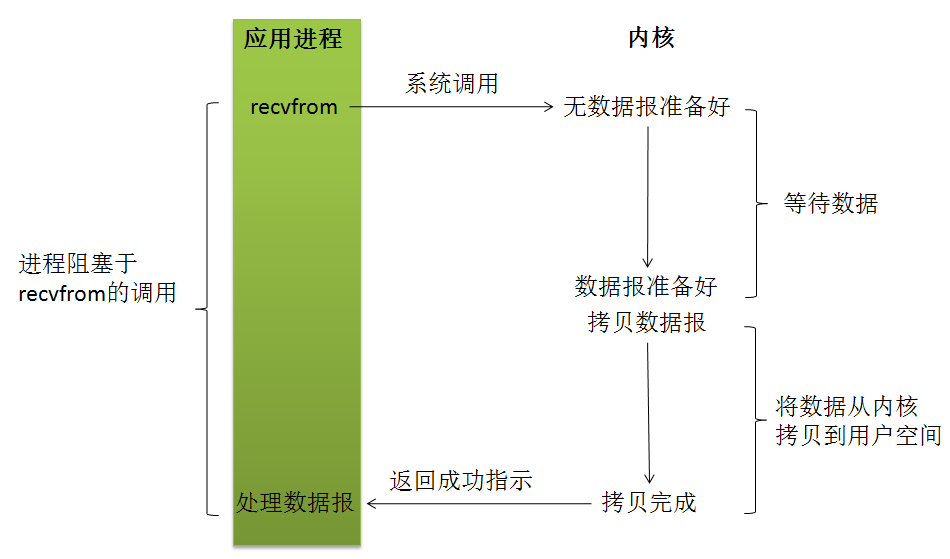
所以,blocking IO的特点就是在IO执行的两个阶段都被block了。
4. 非阻塞I/O模型
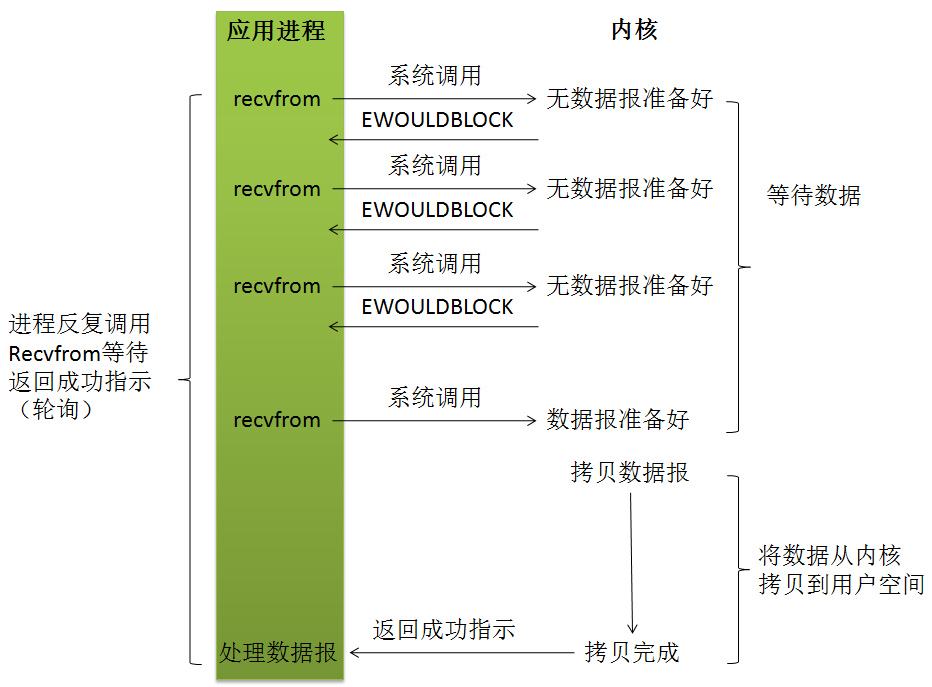
所以,nonblocking IO的特点是用户进程需要不断的主动询问kernel数据好了没有,如果数据已经准备好,从内核拷贝到用户空间,否则一直轮询问下去。
5. I/O多路复用模型
I/O多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知应用进程进行相应的读写操作。
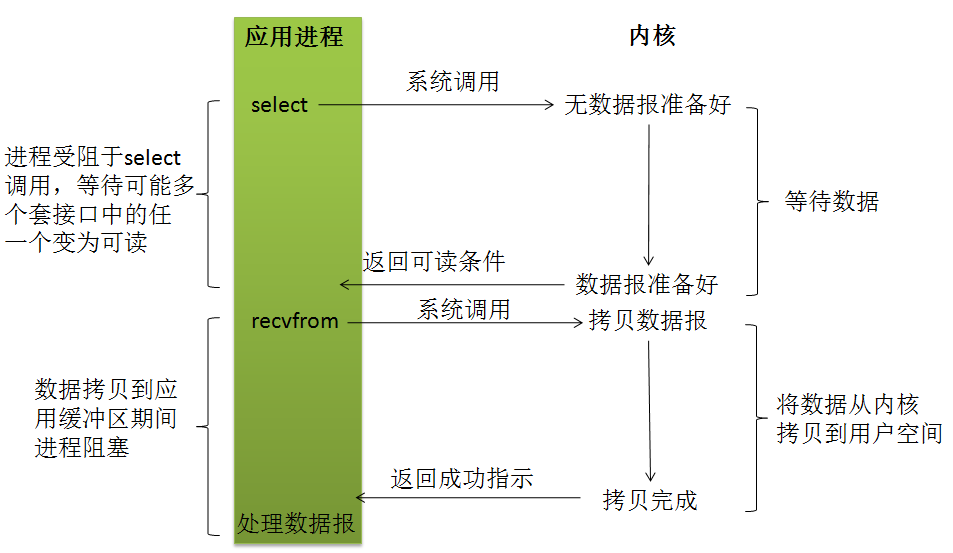
所以,I/O 多路复用的特点是 整个用户的process其实是一直被block的。只不过第一阶段process是被select这个函数block,而不是被socket IO给block。
6. 信号驱动I/O模型
信号驱动 I/O模型:可以用信号,让内核在描述符就绪时发送SIGIO信号通知我们何时可以启动一个IO操作。

所以,信号驱动 I/O模型的特点是 由内核通知我们何时可以启动一个IO操作。
7. 异步I/O模型
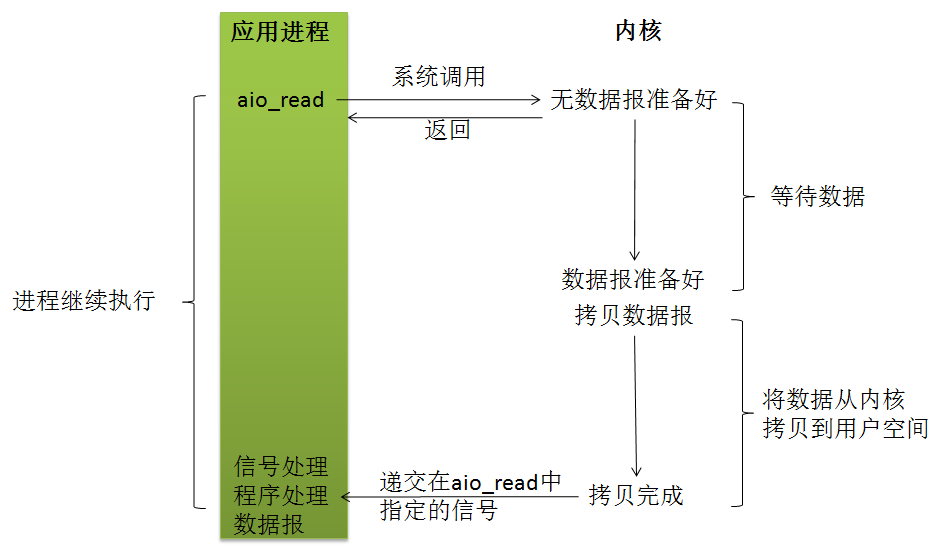
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了。
调用aio_read(Posix异步I/O函数以aio_或lio_开头)函数,给内核传递描述字、缓冲区指针、缓冲区大小(与read相同的3个参数)、文件偏移以及通知的方式,然后系统立即返回。我们的进程不阻塞于等待I/0操作的完成。当内核将数据拷贝到缓冲区后,再通知应用程序。
linux下的asynchronous IO其实用得很少。
所以,异步I/O模型的特点是 由内核通知我们I/O操作何时完成。
8. 阻塞IO vs 非阻塞IO
blocking:调用blocking IO会一直block对应的进程直到准备数据操作完成。
non-blocking:在kernel还准备数据的情况下会立刻返回。
(等待数据阶段)
9. 同步IO vs 异步IO
在说明synchronous IO和asynchronous IO的区别之前,需要先给出两者的定义。POSIX的定义是这样子的:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes;
- An asynchronous I/O operation does not cause the requesting process to be blocked;
同步IO:IO操作导致请求进程阻塞,直到IO操作完成;(Blocking IO,Non-blocking IO,IO multiplexing,Singnal Driven IO)
异步IO:IO操作不导致请求进程阻塞;(Asynchronous IO)
(拷贝数据阶段)
有人会说,non-blocking IO并没有被block啊。这里有个非常“狡猾”的地方,定义中所指的”IO operation”是指真实的IO操作,就是例子中的recvfrom这个system call。non-blocking IO在执行recvfrom这个system call的时候,如果kernel的数据没有准备好,这时候不会block进程。但是,当kernel中数据准备好的时候,recvfrom会将数据从kernel拷贝到用户内存中,这个时候进程是被block了,在这段时间内,进程是被block的。
而asynchronous IO则不一样,当进程发起IO 操作之后,就直接返回再也不理睬了,直到kernel发送一个信号,告诉进程说IO完成。在这整个过程中,进程完全没有被block。
10. 五种I/O模型对比
各个IO Model的比较如图所示:(若要提高IO效率,需要将等待的时间降低)
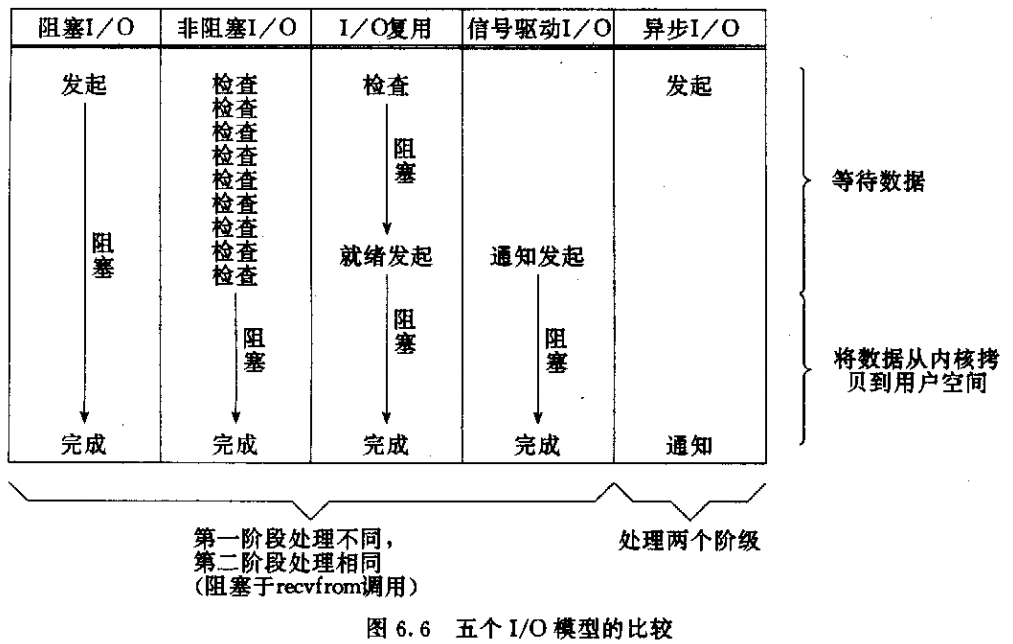
通过上面的图片,可以发现non-blocking IO和asynchronous IO的区别还是很明显的。在non-blocking IO中,虽然进程大部分时间都不会被block,但是它仍然要求进程去主动的check,并且当数据准备完成以后,也需要进程主动的再次调用recvfrom来将数据拷贝到用户内存。而asynchronous IO则完全不同。它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
11. 总结
阻塞I/O(Blocking I/O):应用程序调用一个IO函数,导致应用程序阻塞,如果数据已经准备好,从内核拷贝到用户空间,否则一直等待下去。
非阻塞I/O(Non-Blocking I/O): 用户进程需要不断的主动询问kernel数据好了没有,如果数据已经准备好,从内核拷贝到用户空间,否则一直轮询问下去。
I/O多路复用(I/O Multiplexing): 通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知应用进程进行相应的读写操作。select,poll,epoll都是IO多路复用的机制,有些地方也称这种IO方式为event driven IO(事件驱动I/O)。
信号驱动I/O(Signal Driven I/O):可以用信号,让内核在描述符就绪时发送SIGIO信号通知我们何时可以启动一个IO操作。
异步I/O(Asychronous I/O): 告知内核启动某个操作,并让内核在整个操作(包括将内核复制到我们自己的缓冲区)完成后通知我们。
摘录网址
参考Richard Stevens的“UNIX® Network Programming Volume 1, Third Edition: The Sockets Networking ”,6.2节“I/O Models ”
参考《unix网络编程》
参考http://blog.csdn.net/blueboy2000/article/details/4485874
参考http://blog.csdn.net/suxinpingtao51/article/details/46314097
ps: 抛弃本文上下文
同步与异步是对应的,它们是线程之间的关系,两个线程之间要么是同步的,要么是异步的。
阻塞与非阻塞是对同一个线程来说的,在某个时刻,线程要么处于阻塞,要么处于非阻塞。
阻塞是使用同步机制的结果,非阻塞则是使用异步机制的结果。
同步IO和异步IO的区别就在于:数据拷贝的时候进程是否阻塞!
阻塞IO和非阻塞IO的区别就在于:应用程序的调用是否立即返回!
I/O模型系列之二:Unix的五种网络I/O模型的更多相关文章
- I/O模型之一:Unix的五种I/O模型
目录: <I/O模型之一:Unix的五种I/O模型> <I/O模型之二:Linux IO模式及 select.poll.epoll详解> <I/O模型之三:两种高性能 I ...
- 2018.5.4 Unix的五种IO模型
阻塞非阻塞和异步同步 同步和异步关注的是消息通信机制,关注两个对象之间的调用关系. 阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态,关注单一程序. Unix的五种IO模型 以下基于Li ...
- Unix下五种IO模型
http://blog.chinaunix.net/uid-25324849-id-247813.html 1. I/O模型 Unix下共有五种I/O模型 a. 阻塞I/O b. 非阻塞I/O c. ...
- Unix下 五种 I/O模型
Unix下共有五种I/O模型: 1. 阻塞式I/O 2. 非阻塞式I/O 3. I/O复用(select和poll) 4. 信号驱动式I/O(SIGIO) 5. 异步I/O(POSIX的aio ...
- 五种网络IO模型以及多路复用IO中select/epoll对比
下面都是以网络读数据为例 [2阶段网络IO] 第一阶段:等待数据 wait for data 第二阶段:从内核复制数据到用户 copy data from kernel to user 下面是5种网络 ...
- Jerry带您了解Restful ABAP Programming模型系列之二:Action和Validation的实现
相信通过Jerry的前一篇文章 30分钟用Restful ABAP Programming模型开发一个支持增删改查的Fiori应用,想必大家对Restful ABAP Programming模型已经有 ...
- Javascript事件模型系列(二)事件的捕获-冒泡机制及事件委托机制
一.事件的捕获与冒泡 由W3C规定的DOM2标准中,一次事件的完整过程包括三步:捕获→执行目标元素的监听函数→冒泡,在捕获和冒泡阶段,会依次检查途径的每个节点,如果该节点注册了相应的监听函数,则执行监 ...
- 分布式缓存技术redis学习系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
Redis数据类型 与Memcached仅支持简单的key-value结构的数据记录不同,Redis支持的数据类型要丰富得多,常用的数据类型主要有五种:String.List.Hash.Set和Sor ...
- 分布式缓存技术redis系列(二)——详细讲解redis数据结构(内存模型)以及常用命令
https://www.cnblogs.com/hjwublog/p/5639990.html
随机推荐
- Numpy库的学习(三)
今天我们继续学习一下Numpy库的学习 废话不多说 ,开始讲 比如我们现在想创建一个0-14这样一个15位的数组 可以直接写,但是很麻烦,Numpy中就给我们了一个方便创建的方法 numpy中有一个a ...
- matlab中的实时音频
音频系统工具箱™针对实时音频处理进行了优化.audioDeviceReader, audioDeviceWriter, audioPlayerRecorder, dsp.AudioFileReader ...
- Docker-Linux环境安装
不同服务器操作系统安装命令不同,例如centOS默认用yum,Ubuntu可能默认用apt-get.这里推荐一种安装方式,通过下载shell脚本 https://get.docker.com,会检测操 ...
- Storm入门-Storm与Spark对比
作为一名程序员通病就是不安分,对业界的技术总要折腾一番,哪怕在最终实际工作中应用到的就那么一点.最近自己准备入门Storm学习,关于流式大数据框架目前比较流行的有Spark和Storm等,在入门之前, ...
- delphi中WMI的使用(网卡是否接入)
WMI(Windows Management Instrumentation,Windows 管理规范)是一项核心的 Windows 管理技术:用户可以使用 WMI 管理本地和远程计算机. 通过使用W ...
- Ecto中的changeset,schema,struct,map
概要 schema changeset struct map 总结 概要 Ecto 中, 对数据库的操作中经常用到 4 个类型: schema changeset struct map 在 Ecto ...
- express+sequelize 做后台
第一部分:安装express 第一步:执行 npm install -g express-generator note:必须安装这个,不然创建express项目的时候会提示express命令没有找到 ...
- C++一些基本数据结构:字面常量、符号常量、枚举常量
常量:C++包括两种常量,字面常量和符号常量. 字面常量:指的是直接输入到程序中的值 比如:in myAge=26: myAge是一个int类型变量,而26是一个字面常量. 符号常量:指的是用名称表示 ...
- Linux新手随手笔记1.7
配置网卡(本地电脑) Vment1 仅主机模式 Vment8 nat模式 物理机 : 192.16810.1 /255.255.255.0 服务器 : 192.168.10.10 /255. ...
- neutron二
第四篇neutron— 网络实践 一.虚拟机获取 ip: 用 namspace 隔离 DHCP 服务 Neutron 通过 dnsmasq 提供 DHCP 服务,而 dnsmasq 通过 ...