K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
Wikipedia上的KNN词条中有一个比较经典的图如下:
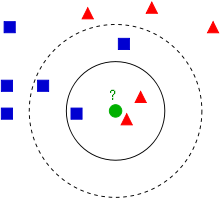
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,机器学习的本质——是基于一种数据统计的方法!那么,这个算法有什么用呢?我们来看几个示例。
产品质量判断
假设我们需要判断纸巾的品质好坏,纸巾的品质好坏可以抽像出两个向量,一个是“酸腐蚀的时间”,一个是“能承受的压强”。如果我们的样本空间如下:(所谓样本空间,又叫Training Data,也就是用于机器学习的数据)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
品质Y |
|
7 |
7 |
坏 |
|
7 |
4 |
坏 |
|
3 |
4 |
好 |
|
1 |
4 |
好 |
那么,如果 X1 = 3 和 X2 = 7, 这个毛巾的品质是什么呢?这里就可以用到KNN算法来判断了。
假设K=3,K应该是一个奇数,这样可以保证不会有平票,下面是我们计算(3,7)到所有点的距离。(关于那些距离公式,可以参看K-Means算法中的距离公式)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
计算到 (3, 7)的距离 |
向量Y |
|
7 |
7 |
|
坏 |
|
7 |
4 |
|
N/A |
|
3 |
4 |
|
好 |
|
1 |
4 |
|
好 |
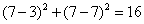
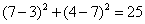
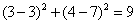
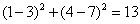
所以,最后的投票,好的有2票,坏的有1票,最终需要测试的(3,7)是合格品。(当然,你还可以使用权重——可以把距离值做为权重,越近的权重越大,这样可能会更准确一些)
注:示例来自这里,K-NearestNeighbors Excel表格下载
预测
假设我们有下面一组数据,假设X是流逝的秒数,Y值是随时间变换的一个数值(你可以想像是股票值)
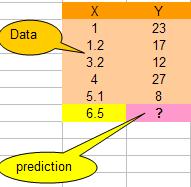
那么,当时间是6.5秒的时候,Y值会是多少呢?我们可以用KNN算法来预测之。
这里,让我们假设K=2,于是我们可以计算所有X点到6.5的距离,如:X=5.1,距离是 | 6.5 – 5.1 | = 1.4, X = 1.2 那么距离是 | 6.5 – 1.2 | = 5.3 。于是我们得到下面的表:
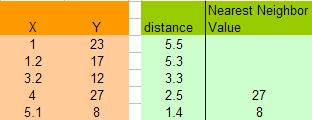
注意,上图中因为K=2,所以得到X=4 和 X =5.1的点最近,得到的Y的值分别为27和8,在这种情况下,我们可以简单的使用平均值来计算: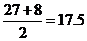
于是,最终预测的数值为:17.5
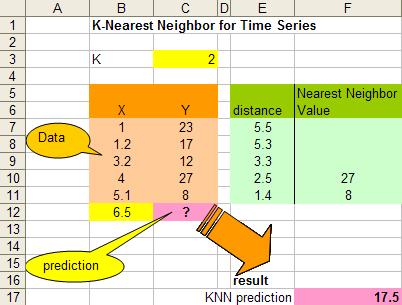
注:示例来自这里,KNN_TimeSeries Excel表格下载
插值,平滑曲线
KNN算法还可以用来做平滑曲线用,这个用法比较另类。假如我们的样本数据如下(和上面的一样):

要平滑这些点,我们需要在其中插入一些值,比如我们用步长为0.1开始插值,从0到6开始,计算到所有X点的距离(绝对值),下图给出了从0到0.5 的数据:
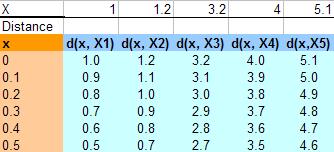
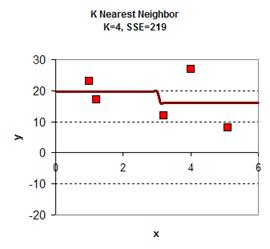
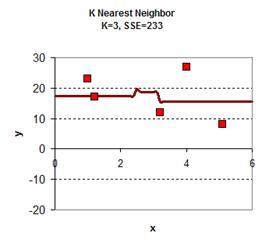
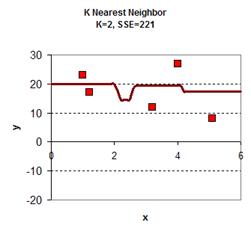
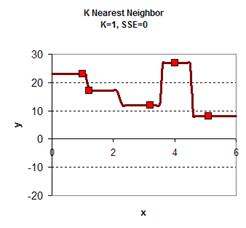
下图给出了从2.5到3.5插入的11个值,然后计算他们到各个X的距离,假值K=4,那么我们就用最近4个X的Y值,然后求平均值,得到下面的表:
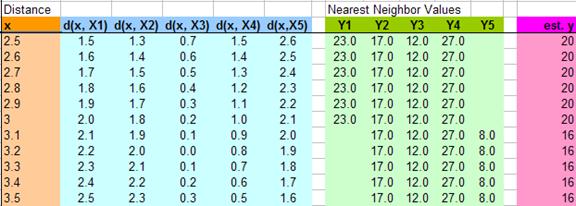
于是可以从0.0, 0.1, 0.2, 0.3 …. 1.1, 1.2, 1.3…..3.1, 3.2…..5.8, 5.9, 6.0 一个大表,跟据K的取值不同,得到下面的图:
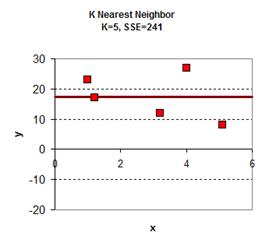 |
 |
 |
 |
 |
注:示例来自这里,KNN_Smoothing Excel表格下载
后记
最后,我想再多说两个事,
1) 一个是机器学习,算法基本上都比较简单,最难的是数学建模,把那些业务中的特性抽象成向量的过程,另一个是选取适合模型的数据样本。这两个事都不是简单的事。算法反而是比较简单的事。
2)对于KNN算法中找到离自己最近的K个点,是一个很经典的算法面试题,需要使用到的数据结构是“最大堆——Max Heap”,一种二叉树。你可以看看相关的算法。
K NEAREST NEIGHBOR 算法(knn)的更多相关文章
- K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KN ...
- K nearest neighbor cs229
vectorized code 带来的好处. import numpy as np from sklearn.datasets import fetch_mldata import time impo ...
- K-Means和K Nearest Neighbor
来自酷壳: http://coolshell.cn/articles/7779.html http://coolshell.cn/articles/8052.html
- class-k近邻算法kNN
1 k近邻算法2 模型2.1 距离测量2.2 k值选择2.3 分类决策规则3 kNN的实现--kd树3.1 构造kd树3.2 kd树搜索 1 k近邻算法 k nearest neighbor,k-NN ...
- [机器学习系列] k-近邻算法(K–nearest neighbors)
C++ with Machine Learning -K–nearest neighbors 我本想写C++与人工智能,但是转念一想,人工智能范围太大了,我根本介绍不完也没能力介绍完,所以还是取了他的 ...
- K近邻(k-Nearest Neighbor,KNN)算法,一种基于实例的学习方法
1. 基于实例的学习算法 0x1:数据挖掘的一些相关知识脉络 本文是一篇介绍K近邻数据挖掘算法的文章,而所谓数据挖掘,就是讨论如何在数据中寻找模式的一门学科. 其实人类的科学技术发展的历史,就一直伴随 ...
- 转载: scikit-learn学习之K最近邻算法(KNN)
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- k最邻近算法——使用kNN进行手写识别
上篇文章中提到了使用pillow对手写文字进行预处理,本文介绍如何使用kNN算法对文字进行识别. 基本概念 k最邻近算法(k-Nearest Neighbor, KNN),是机器学习分类算法中最简单的 ...
- <机器学习实战>读书笔记--k邻近算法KNN
k邻近算法的伪代码: 对未知类别属性的数据集中的每个点一次执行以下操作: (1)计算已知类别数据集中的点与当前点之间的距离: (2)按照距离递增次序排列 (3)选取与当前点距离最小的k个点 (4)确定 ...
随机推荐
- (译)Getting Started——1.2.3 Defining the Interaction(定义交互)
IOS应用编程是基于事件驱动的编程.也就是说,应用的流程由事件来决定:事件包括系统事件和用户操作.界面上用户执行的操作会触发事件.这些事件导致应用的逻辑被执行,数据被操作.应用对用户动作的响应反映在界 ...
- adb 安装apk到指定手机 登录shell
电脑链接多个设备时,给指定的设备安装apk, 1. 先查看手机的编码 adb devices 2. adb -s 手机编码 install xxx.apk 如果是无线链接调试状态,adb device ...
- tp三级联动
<script type="text/javascript">$(document).ready(function(){ $("#province" ...
- python笔记- 发送邮件
依赖: Python代码实现发送邮件,使用的模块是smtplib.MIMEText,实现代码之前需要导入包: import smtplib from email.mime.text import MI ...
- 初识Python、PyCharm、Anaconda与tensorflow
最近裸辞了,未来希望转深度学习.语音识别.文本挖掘,觉得这块特别有意思,比较好玩.开始自学相关知识,为了能够独立地.系统地了解和学习相关知识,计划不定期记录和更新一些平时的学习总结,个人关于以上几个方 ...
- 嵌入式开发之信号采集同步---VSYNC和HSYNC的作用以及它们两者之间的关系
VSYNC和HSYNC的作用以及它们两者之间的关系 VSYNC和HSYNC的作用以及它们两者之间的关系 VSYNC和HSYNC是什么 VSYNC: vertical synchronization,指 ...
- Sql server不同数据类型间拼接(+)
)+'m' 输出 4m 若 +'m' 输出:在将 varchar 值 'm' 转换成数据类型 int 时失败.
- 20个JS 小技巧超级实用
1. 将彻底屏蔽鼠标右键 oncontextmenu=”window.event.returnValue=false” < table border oncontextmenu=return(f ...
- jquery代码规范让代码越来越好看
最近学了jQuery,感觉这个jQuery是真的挺不错的,果然像他说的那样,少些多做!刚一入手感觉真是不错.但是写多了,就会发现这个代码一行居然能写那么长.而且可读性还不好. 有幸自己买了一本锋利的 ...
- sql privot
http://www.studyofnet.com/news/295.html 本文导读:T-SQL语句中,Pivot运算符用于在列和行之间对数据进行旋转或透视转换,PIVOT命令可以实现数据表的列转 ...