bagging 和boosting的概念和区别
1.先弄清楚模型融合中的投票的概念
分为软投票和硬投票,硬投票就是几个模型预测的哪一类最多,最终模型就预测那一类,在投票相同的情况下,投票结果会按照分类器的排序选择排在第一个的分类器结果。但硬投票有个缺点就是不能预测概率。而软投票返回的结果是一组概率的加权平均数。

https://blog.csdn.net/yanyanyufei96/article/details/71195063
https://blog.csdn.net/good_boyzq/article/details/54809540(搜投票)
2. booststraping:意思是依靠你自己的资源,称为自助法,它是一种有放回的抽样方法,它是非参数统计中一种重要的估计统计量方差进而进行区间估计的统计方法。
其核心思想和基本步骤如下:
(1)采用重抽样技术从原始样本中抽取一定数量(自己给定)的样本,此过程允许重复抽样。
(2)根据抽出的样本计算统计量T。
(3)重复上述N次(一般大于1000),得到统计量T。
(4)计算上述N个统计量T的样本方差,得到统计量的方差。
应该说是Bootstrap是现代统计学较为流行的方法,小样本效果好,通过方差的估计可以构造置信区间等。
https://blog.csdn.net/wangqi880/article/details/49765673
3.bagging
https://www.cnblogs.com/dudumiaomiao/p/6361777.html
https://blog.csdn.net/ice110956/article/details/10077717
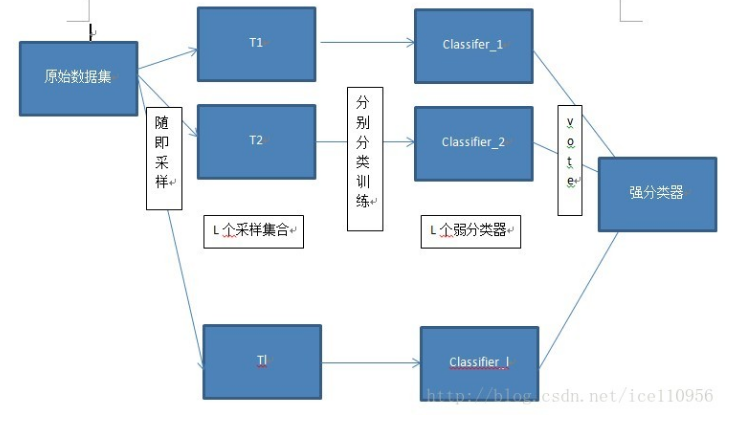
Bagging即套袋法,其算法过程如下:
A)从原始样本集中抽取训练集.每轮从原始样本集中使用Bootstraping的方法抽取n个训练样本(在训练集中,有些样本可能被多次抽取到,而有些样本可能一次都没有被抽中).共进行k轮抽取,得到k个训练集.(k个训练集相互独立)
B)每次使用一个训练集得到一个模型,k个训练集共得到k个模型.(注:根据具体问题采用不同的分类或回归方法,如决策树、神经网络等)
C)对分类问题:将上步得到的k个模型采用投票的方式得到分类结果;对回归问题,计算上述模型的均值作为最后的结果.
4.boosting
https://blog.csdn.net/ice110956/article/details/10077717
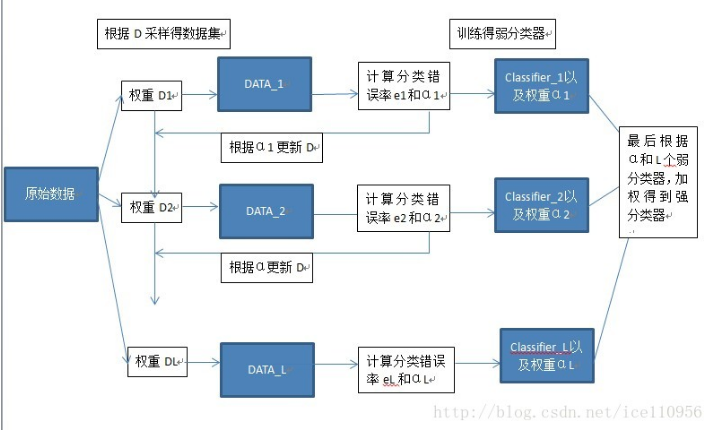
现在觉得这个的解释应该算是adaboost的,adaboost算是boosting里面最经典的模型
1.e表示某个弱分类器的错误分类率,计算用来作为这个分类器的可信度权值a,以及更新采样权值D。
2.D表示原始数据的权值矩阵,用来随机采样。刚开始每个样本的采样概率都一样,为1/m。在某个弱分类器分类时,分类错误或对,则D就会根据e相应地增加或减少,那么分错的样本由于D增大,在下一次分类采样时被采样的概率增加了,从而提高上次错分样本下次分对的概率。
3.α为弱分类器的可信度,bagging中隐含的α为1,boosting中,根据每个弱分类器的表现(e较低),决定这个分类器的结果在总的结果中所占的权重,分类准的自然占较多的权重。
最后根据可信度α,以及各个弱分类器的估计h(x),得到最后的结果。
5.
Bagging,Boosting二者之间的区别
https://www.cnblogs.com/dudumiaomiao/p/6361777.html
Bagging和Boosting的区别:
1)样本选择上:
Bagging:训练集是在原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的.
Boosting:每一轮的训练集不变(个人觉得这里说的训练集不变是说的总的训练集,对于每个分类器的训练集还是在变化的,毕竟每次都是抽样),只是训练集中每个样例在分类器中的权重发生变化.而权值是根据上一轮的分类结果进行调整.
2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大.
3)预测函数:
Bagging:所有预测函数的权重相等.
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重.
4)并行计算:
Bagging:各个预测函数可以并行生成
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果.
个人感觉并行计算,训练集不变才是真正的不同,特别是并行计算
bagging 和boosting的概念和区别的更多相关文章
- Bagging和Boosting的概念与区别
随机森林属于集成学习(ensemble learning)中的bagging算法,在集成算法中主要分为bagging算法与boosting算法, Bagging算法(套袋发) bagging的算法过程 ...
- Bagging和Boosting 概念及区别
Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法.即将弱分类器组装成强分类器的方法. 首先介绍Boot ...
- Bagging和Boosting 概念及区别(转)
Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的分类器,更准确的说这是一种分类算法的组装方法.即将弱分类器组装成强分类器的方法. 首先介绍Boot ...
- Bagging和Boosting的区别(面试准备)
Baggging 和Boosting都是模型融合的方法,可以将弱分类器融合之后形成一个强分类器,而且融合之后的效果会比最好的弱分类器更好. Bagging: 先介绍Bagging方法: Bagging ...
- Bagging和Boosting的区别
转:http://www.cnblogs.com/liuwu265/p/4690486.html Bagging和Boosting都是将已有的分类或回归算法通过一定方式组合起来,形成一个性能更加强大的 ...
- 随机森林(Random Forest),决策树,bagging, boosting(Adaptive Boosting,GBDT)
http://www.cnblogs.com/maybe2030/p/4585705.html 阅读目录 1 什么是随机森林? 2 随机森林的特点 3 随机森林的相关基础知识 4 随机森林的生成 5 ...
- Bagging和Boosting的介绍及对比
"团结就是力量"这句老话很好地表达了机器学习领域中强大「集成方法」的基本思想.总的来说,许多机器学习竞赛(包括 Kaggle)中最优秀的解决方案所采用的集成方法都建立在一个这样的假 ...
- 集成学习---bagging and boosting
作为集成学习的二个方法,其实bagging和boosting的实现比较容易理解,但是理论证明比较费力.下面首先介绍这两种方法. 所谓的集成学习,就是用多重或多个弱分类器结合为一个强分类器,从而达到提升 ...
- 以Random Forests和AdaBoost为例介绍下bagging和boosting方法
我们学过决策树.朴素贝叶斯.SVM.K近邻等分类器算法,他们各有优缺点:自然的,我们可以将这些分类器组合起来成为一个性能更好的分类器,这种组合结果被称为 集成方法 (ensemble method)或 ...
随机推荐
- Ruby 踩坑 “Failed to build gem native extension”
ruby新手,总是会出现这样那样的问题,这里先记录下,希望能解决你得问题. 首先是安装ruby 环境,楼主愚钝,在公司和自己的电脑上来来回回整了好几天,每次安装 gem 包的时候总是报错,错误信息大致 ...
- [javaEE] 数据库连接池和动态代理
实现javax.sql.DataSource接口 实现Connection getConnection()方法 定义一个静态的成员属性LinkedList类型作为连接池,在静态代码块中初始化5条数据库 ...
- CSS实现微信对话框
- java.util.concurrent.CyclicBarrier 使用
1.概述 java.util.concurrent.CyclicBarrier(循环的栅栏), 构造时设置一个计数器数(count), 各线程通过调用barrier.await()进入等待,并且计数+ ...
- window onload || jquery $()
1.window 的 onload 机制只指定一个函数,且在页面DOM及静态资源加载完之后执行: window.onload = function(){ alert(); } 2.$(document ...
- js修改日期
需求说明: (1)首先是input显示年月日时分格式时间,其中年月日实在本地时间基础上,加上后面联动值.小时默认08:00不变 (2)后面input内显示天数,右侧加减按钮,控制天数,天数确定后,前面 ...
- 2-3 Sass的函数功能-列表函数
列表函数主要包括一些对列表参数的函数使用,主要包括以下几种: length($list):返回一个列表的长度值: nth($list, $n):返回一个列表中指定的某个标签值 join($list1, ...
- C语言实现整数数组的逆置算法
读入100个整数到一个数组中,写出实现该数组进行逆置的算法. 方法一: 假设100个整数读入到数组a中,算法f1的思想是分别从数组两端依次将对应数进行交换,即a[i]与a[100 - i - 1]进行 ...
- awk日志分析
前言 今天我们来讲讲如何用awk进行网站日志分析,得到页面平均耗时排行 文件 [xingxing.dxx@30_28_6_20 ~]$ cat logs /Oct/::: +] GET /pages/ ...
- python 多进程数据交互及共享
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最 ...