记一次idea性能调优


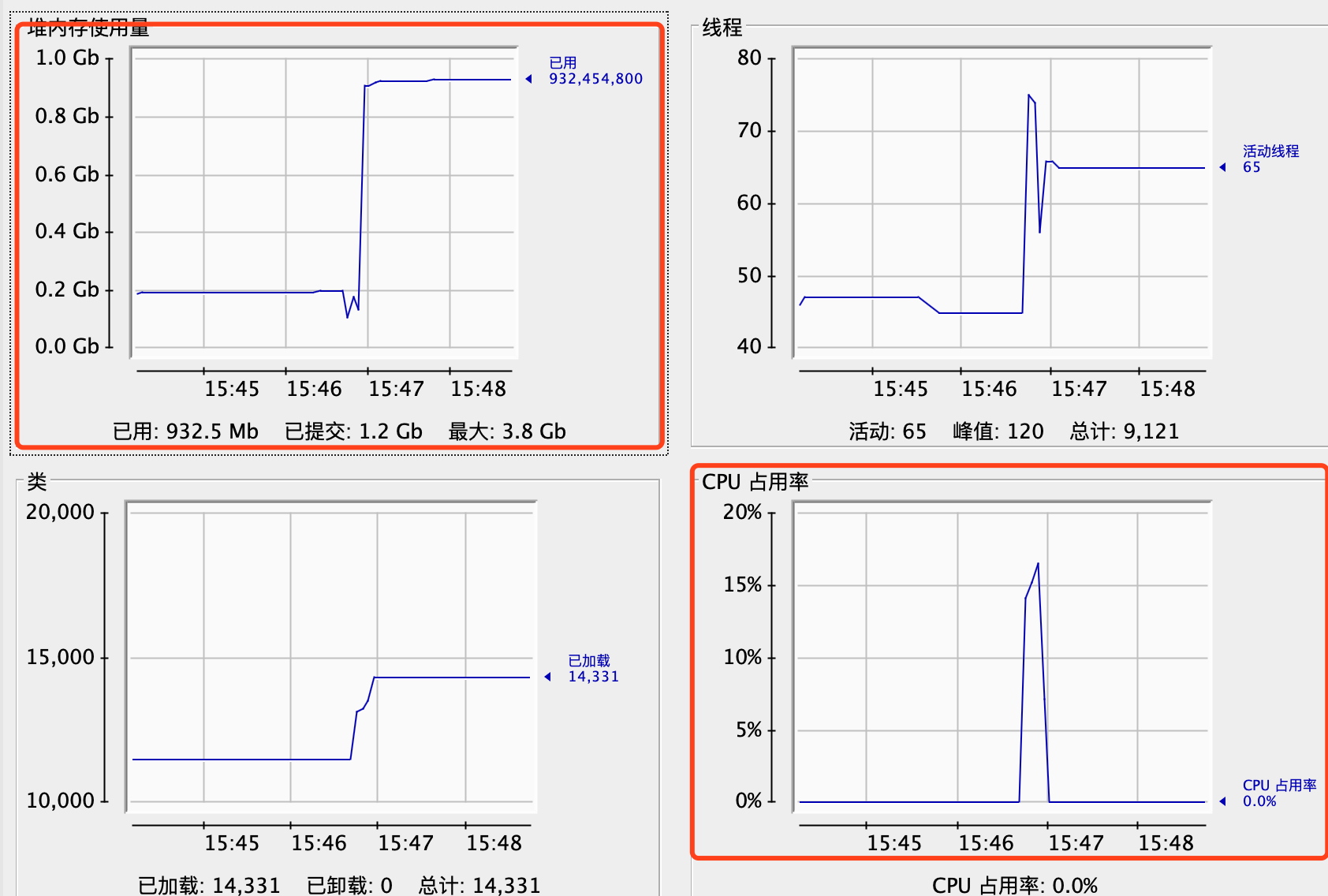
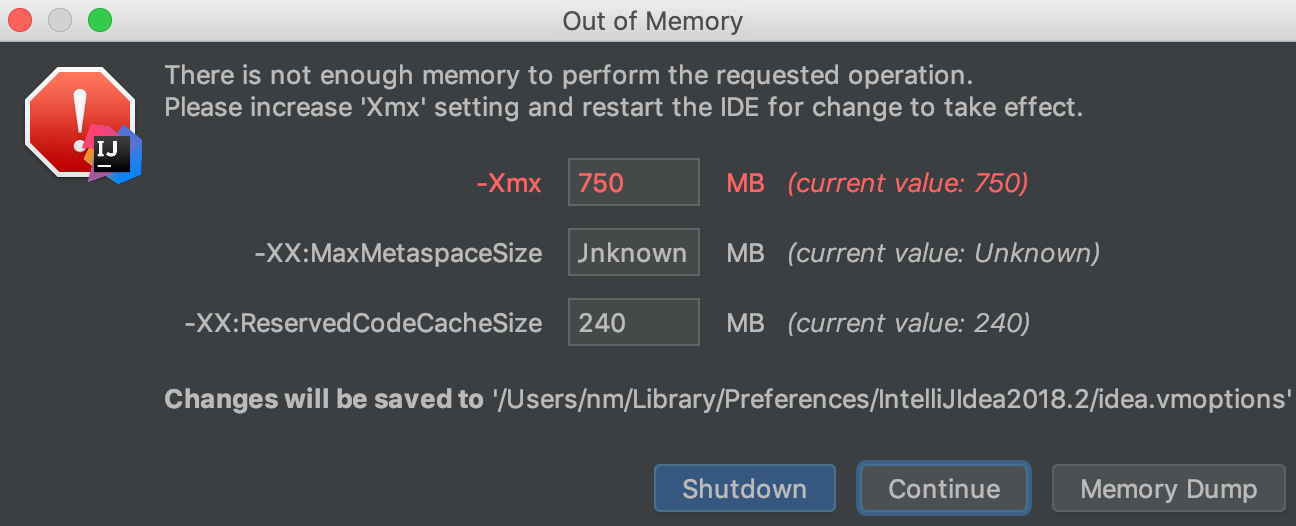
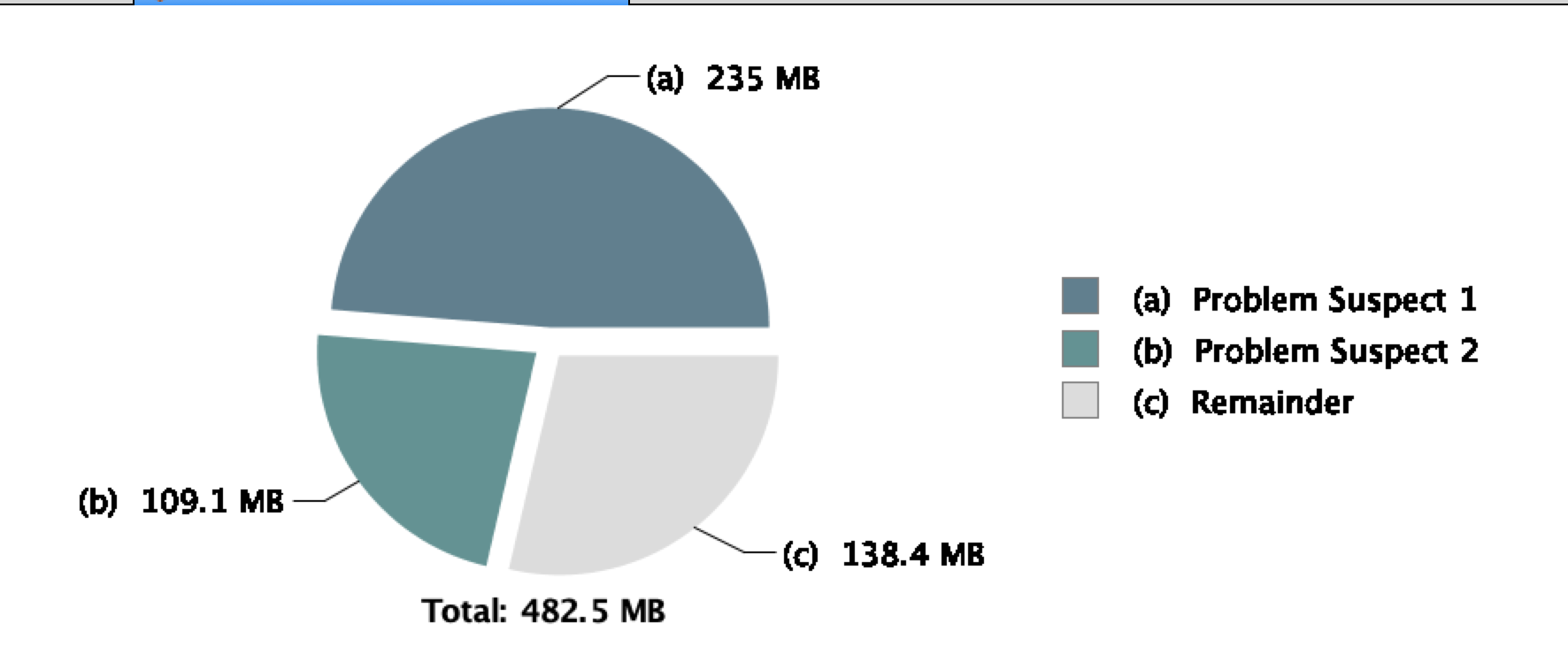
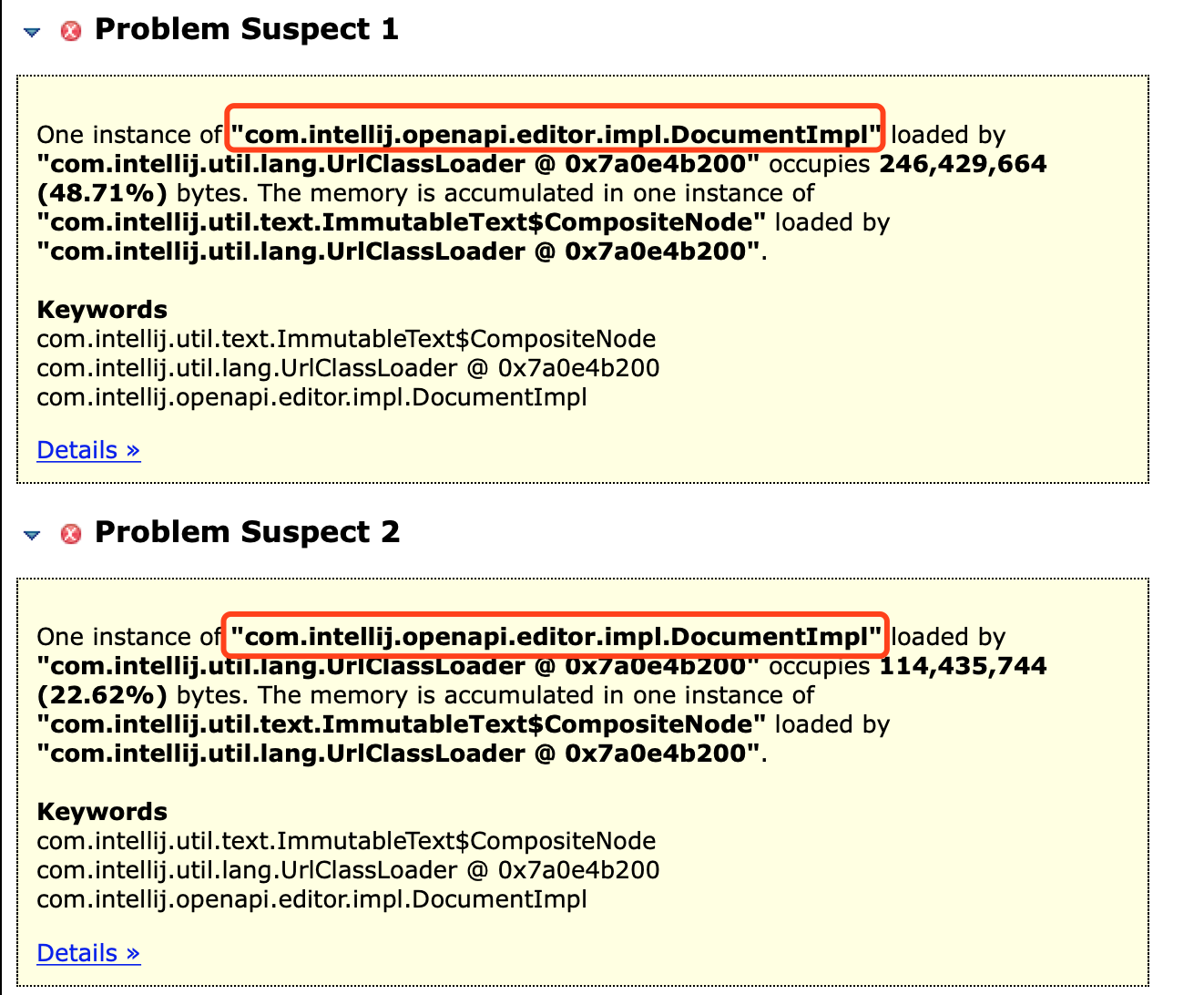
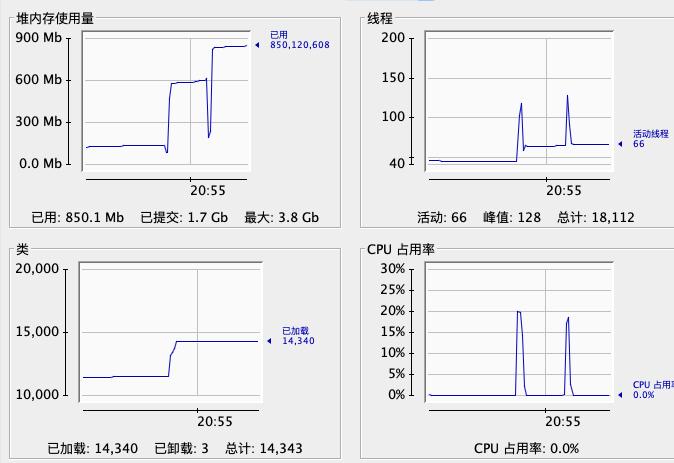
启动程序,再次观察cpu跟内存,cpu从2%到了10%,内存增长300M:







-Xms512m
-Xmn512m
-Xmx2048m
-XX:ReservedCodeCacheSize=240m
-XX:+UseCompressedOops
-Dfile.encoding=UTF-8
-XX:+UseG1GC //使用G1收集器,好处是并行收集
-XX:+UseNUMA //优先使用速度较快的内存
-XX:SoftRefLRUPolicyMSPerMB=50
-ea
-Dsun.io.useCanonCaches=false
-Djava.net.preferIPv4Stack=true
-Djdk.http.auth.tunneling.disabledSchemes=""
-XX:+HeapDumpOnOutOfMemoryError
-XX:-OmitStackTraceInFastThrow
-Xverify:none -XX:ErrorFile=$USER_HOME/java_error_in_idea_%p.log
-XX:HeapDumpPath=$USER_HOME/java_error_in_idea.hprof
-javaagent:JetbrainsCrack-3.1-release-enc.jar

记一次idea性能调优的更多相关文章
- [MYSQL] 记一次MySQL性能调优
最近在做数据迁移工作,已有一堆数据文件,要把这些数据文件写到MySQL 数据库里面去. MySQL数据库上架了一层服务接口,可以直接调用.博主写了一个迁移程序,放在服务器A上. *********** ...
- 记一次GreenPlum性能调优
在部署了的GreenPlum集群中进行数据查询时,发现数据量一旦大了,查询一跑就中断,提示某个segment中断了连接. ERROR 58M01 "Error on receive from ...
- 记一次Web服务的性能调优
前言 一个项目在经历开发.测试.上线后,当时的用户规模还比较小,所以刚刚上线的项目一般会表现稳定.但是随着时间的推移,用户数量的增加,qps的增加等因素会造成项目慢慢表现出网页半天无响应的状况.在之前 ...
- 记一次sql server 性能调优,查询从20秒至2秒
一.需求 需求很简单,就是需要查询一个报表,只有1个表,数据量大约60万左右,但是中间有些逻辑. 先说明一下服务器配置情况:1核CPU.2GB内存.机械硬盘.Sqlserver 2008 R2.Win ...
- JVM性能调优2:JVM性能调优参数整理
序号 参数名 说明 JDK 默认值 使用过 1 JVM执行模式 2 -client-server 设置该JVM运行与Client 或者Server Hotspot模式,这两种模式从本质上来说是在JVM ...
- 如何合理的规划一次jvm性能调优
https://blog.csdn.net/miracle_8/article/details/78347172 摘要: JVM性能调优涉及到方方面面的取舍,往往是牵一发而动全身,需要全盘考虑各方面的 ...
- MySQL性能调优与架构设计——第12章 可扩展设计的基本原则
第12章 可扩展设计的基本原则 前言: 随着信息量的飞速增加,硬件设备的发展已经慢慢的无法跟上应用系统对处理能力的要求了.此时,我们如何来解决系统对性能的要求?只有一个办法,那就是通过改造系统的架构体 ...
- 如何合理的规划jvm性能调优
JVM性能调优涉及到方方面面的取舍,往往是牵一发而动全身,需要全盘考虑各方面的影响.但也有一些基础的理论和原则,理解这些理论并遵循这些原则会让你的性能调优任务将会更加轻松.为了更好的理解本篇所介绍的内 ...
- JVM性能调优入门
1. 背景 虽然大多数应用程序使用JVM的默认设置就能很好地工作,仍然有不少应用程序需要对JVM进行额外的配置才能达到其期望的性能要求. 现在JVM为了满足各种应用的需要,为程序运行提供了大量的JVM ...
随机推荐
- android屏幕适配,生成不同分辨率的dimen.xml文件
一.在项目下新建moudle,选择Java Library 二.DimenUtils类 public class DimenUtils { //文件保存的路径 是在该项目下根路径下创建 比如该项目创建 ...
- 构造复杂Lambda困惑之学会用LinqPad和Linqer实现Sql 和 Lambda之间的互转
一:linq的话我们可能会遇到两个问题: 1. 我们的linq出现性能低下的时候,如果优化???? 我们写的linq所生成的sql是无法控制的... (要做性能优化,必须预先知道sql会生成啥样的?? ...
- Win7系统下搭建FTP
一.创建FTP站点 1.打开:控制面板---系统和安全---管理工具---Internet 信息服务 2. 建站:右键点击网站---添加FTP站点 3. 输入FTP 站点名称---选择你的 FTP ...
- 201621123023《Java程序设计》第3周学习总结
一. 本周学习总结 写出你认为本周学习中比较重要的知识点关键词,如类.对象.封装等 关键字:面向对象,类,对象,构造函数,封装,继承 用思维导图或者Onenote或其他工具将这些关键词组织起来 二.书 ...
- python字符串的切片
# 字符串的切片 """ (5)字符串的切片 :切片就是截取字符串的意思 (1)语法 =>字符串[::] 完整格式:[开始索引:结束索引:间隔值 (2)[:结束索引 ...
- 一个简单的HTML病毒分析
一直就想写这篇东西了,仅仅是上班时说要上班,不写.回家后又忙着玩游戏,丢一边去了.如今仅仅好不务正业的开写了.希望头儿不会知道我的blog.哈哈 在非常久之前就对HTML的病毒非常感兴趣了,非常好奇怎 ...
- 如何实现 Python 中 selnium 模块的换行
如何实现 Python 中 selnium 模块的换行 三种方法: 直接调用 .submit() 方法,常使用在用户密码登录中 # driver.find_element_by_xpath('//*[ ...
- 网络CCNA基础了解
关于网络 CCNA.CCNP.CCIE 中的 CCNA 一.逻辑与.或.非 AND --> "与"计算 1 AND 1 = 1(取严) 1 AND 0 = 0 0 AND 1 ...
- 2016级算法第五次上机-E.AlvinZH的学霸养成记IV
1039 AlvinZH的学霸养成记IV 思路 难题,最大二分图匹配. 难点在于如何转化问题,n对n,一个只能攻击一个,判断是否存在一种攻击方案我方不死团灭对方.可以想到把所有随从看作点,对于可攻击的 ...
- sql charIndex用法
CHARINDEX(): 写SQL语句我们经常需要判断一个字符串中是否包含另一个字符串,但是SQL SERVER中并没有像C#提供了Contains函数,不过SQL SERVER中提供了一个叫CHAE ...