spark exectors的启动总结
在spark启动之后,worker和master注册通信之后,在进入用户提交app中,new SparkContext之后就会在worker上分配exectors了。
首先在sparkContext中,会先创建和启动TaskScheduler和DAGSchedule
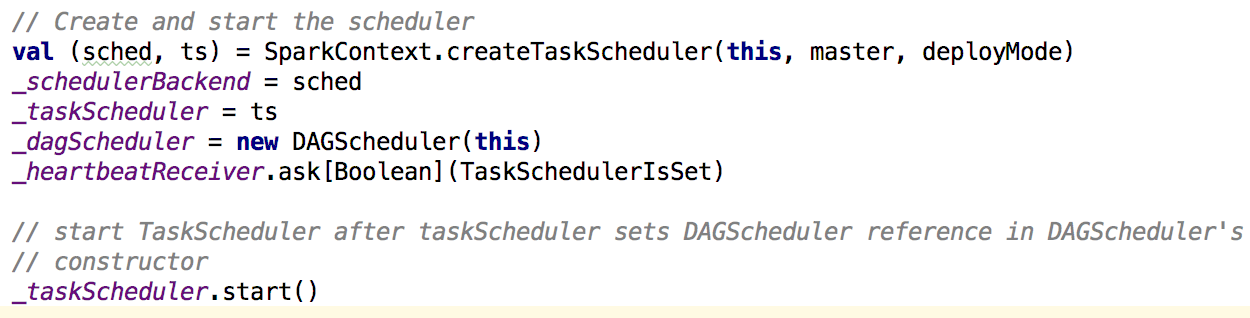
在创建TaskScheduler的时候也会创建schedulerBackend;下面看createTaskScheduler方法:
private def createTaskScheduler(
sc: SparkContext,
master: String,
deployMode: String): (SchedulerBackend, TaskScheduler) = {
import SparkMasterRegex._ // When running locally, don't try to re-execute tasks on failure.
val MAX_LOCAL_TASK_FAILURES = 1 master match {
case "local" =>
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, 1)
scheduler.initialize(backend)
(backend, scheduler) case LOCAL_N_REGEX(threads) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*] estimates the number of cores on the machine; local[N] uses exactly N threads.
val threadCount = if (threads == "*") localCpuCount else threads.toInt
if (threadCount <= 0) {
throw new SparkException(s"Asked to run locally with $threadCount threads")
}
val scheduler = new TaskSchedulerImpl(sc, MAX_LOCAL_TASK_FAILURES, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler) case LOCAL_N_FAILURES_REGEX(threads, maxFailures) =>
def localCpuCount: Int = Runtime.getRuntime.availableProcessors()
// local[*, M] means the number of cores on the computer with M failures
// local[N, M] means exactly N threads with M failures
val threadCount = if (threads == "*") localCpuCount else threads.toInt
val scheduler = new TaskSchedulerImpl(sc, maxFailures.toInt, isLocal = true)
val backend = new LocalSchedulerBackend(sc.getConf, scheduler, threadCount)
scheduler.initialize(backend)
(backend, scheduler) case SPARK_REGEX(sparkUrl) =>
val scheduler = new TaskSchedulerImpl(sc)
val masterUrls = sparkUrl.split(",").map("spark://" + _)
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
(backend, scheduler) case LOCAL_CLUSTER_REGEX(numSlaves, coresPerSlave, memoryPerSlave) =>
// Check to make sure memory requested <= memoryPerSlave. Otherwise Spark will just hang.
val memoryPerSlaveInt = memoryPerSlave.toInt
if (sc.executorMemory > memoryPerSlaveInt) {
throw new SparkException(
"Asked to launch cluster with %d MB RAM / worker but requested %d MB/worker".format(
memoryPerSlaveInt, sc.executorMemory))
} val scheduler = new TaskSchedulerImpl(sc)
val localCluster = new LocalSparkCluster(
numSlaves.toInt, coresPerSlave.toInt, memoryPerSlaveInt, sc.conf)
val masterUrls = localCluster.start()
val backend = new StandaloneSchedulerBackend(scheduler, sc, masterUrls)
scheduler.initialize(backend)
backend.shutdownCallback = (backend: StandaloneSchedulerBackend) => {
localCluster.stop()
}
(backend, scheduler) case masterUrl =>
val cm = getClusterManager(masterUrl) match {
case Some(clusterMgr) => clusterMgr
case None => throw new SparkException("Could not parse Master URL: '" + master + "'")
}
try {
val scheduler = cm.createTaskScheduler(sc, masterUrl)
val backend = cm.createSchedulerBackend(sc, masterUrl, scheduler)
cm.initialize(scheduler, backend)
(backend, scheduler)
} catch {
case se: SparkException => throw se
case NonFatal(e) =>
throw new SparkException("External scheduler cannot be instantiated", e)
}
}
}
在这个方法中会根据配置的master的url来创建相应的TaskScheduler和schedulerBackend,如果是local则创建TaskSchedulerImpl和LocalSchedulerBackend,如果是Standalone则创建TaskSchedulerImpl和StandaloneSchedulerBackend,如果是其他,例如yarn,则会在getClusterManager方法中从加载的类文件中获取ExternalClusterManager类型的类,并调用其canCreate查看是否可以创建,来创建其他的TaskScheduler和scheduler。
下面就以Standalone模式来分析接下来的操作:
扎起创建完TaskSchedulerImpl和StandaloneSchedulerBackend之后会接着创建DAGScheduler,创建的时候回用到上面创建的TaskSchedulerImpl作为参数,在其创建的过程中也会创建一个eventProcessLoop,它是DAGScheduler接收处理各类消息的时间循环体,其继承自EventLoop,它会启动一个线程来处理eventQueue中保存的信息。下面是具体的代码:
private[scheduler] val eventProcessLoop = new DAGSchedulerEventProcessLoop(this)
taskScheduler.setDAGScheduler(this)
.............
private[scheduler] class DAGSchedulerEventProcessLoop(dagScheduler: DAGScheduler)
extends EventLoop[DAGSchedulerEvent]("dag-scheduler-event-loop") with Logging
...............
private[spark] abstract class EventLoop[E](name: String) extends Logging { private val eventQueue: BlockingQueue[E] = new LinkedBlockingDeque[E]() private val stopped = new AtomicBoolean(false) private val eventThread = new Thread(name) {
setDaemon(true) override def run(): Unit = {
try {
while (!stopped.get) {
val event = eventQueue.take()
try {
onReceive(event)
} catch {
case NonFatal(e) =>
try {
onError(e)
} catch {
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
}
}
} catch {
case ie: InterruptedException => // exit even if eventQueue is not empty
case NonFatal(e) => logError("Unexpected error in " + name, e)
}
} }
}
在OnReceive接收处理的事件信息在DAGScheduler中有定义:
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
case MapStageSubmitted(jobId, dependency, callSite, listener, properties) =>
dagScheduler.handleMapStageSubmitted(jobId, dependency, callSite, listener, properties)
case StageCancelled(stageId, reason) =>
dagScheduler.handleStageCancellation(stageId, reason)
case JobCancelled(jobId, reason) =>
dagScheduler.handleJobCancellation(jobId, reason)
case JobGroupCancelled(groupId) =>
dagScheduler.handleJobGroupCancelled(groupId)
case AllJobsCancelled =>
dagScheduler.doCancelAllJobs()
case ExecutorAdded(execId, host) =>
dagScheduler.handleExecutorAdded(execId, host)
case ExecutorLost(execId, reason) =>
val workerLost = reason match {
case SlaveLost(_, true) => true
case _ => false
}
dagScheduler.handleExecutorLost(execId, workerLost)
case WorkerRemoved(workerId, host, message) =>
dagScheduler.handleWorkerRemoved(workerId, host, message)
case BeginEvent(task, taskInfo) =>
dagScheduler.handleBeginEvent(task, taskInfo)
case SpeculativeTaskSubmitted(task) =>
dagScheduler.handleSpeculativeTaskSubmitted(task)
case GettingResultEvent(taskInfo) =>
dagScheduler.handleGetTaskResult(taskInfo)
case completion: CompletionEvent =>
dagScheduler.handleTaskCompletion(completion)
case TaskSetFailed(taskSet, reason, exception) =>
dagScheduler.handleTaskSetFailed(taskSet, reason, exception)
case ResubmitFailedStages =>
dagScheduler.resubmitFailedStages()
}
关于eventloop在sparkStreaming中job生出和处理中也有用到,都是同样的原理;
在sparkContext创建完成TaskScheduler和DAGScheduler之后,会调用taskScheduler.start来启动TaskScheduler。这里指向的是TaskSchedulerImpl
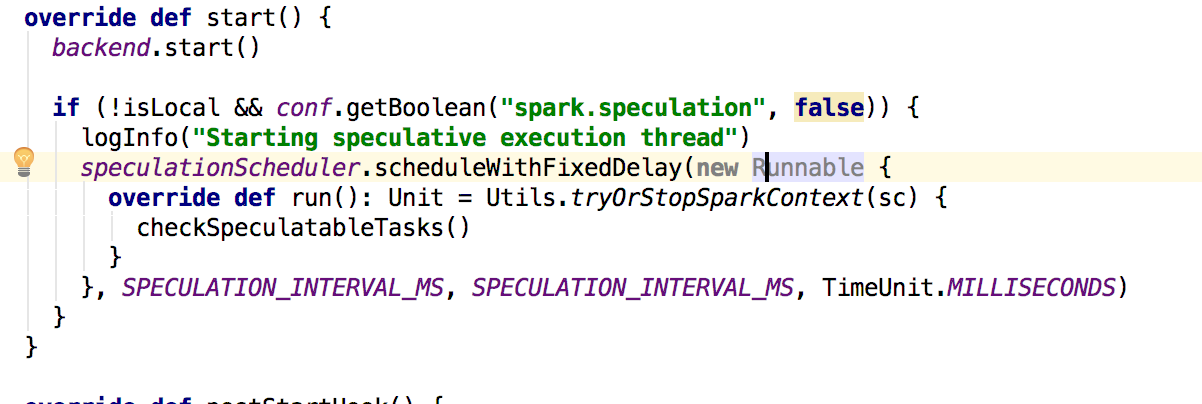
其首先会启动backend也就是StandaloneSchedulerBackend,然后在看是否开启了推测执行,如果开始则进行推测执行的相关操作,下面看看StandaloneSchedulerBackend的start方法
override def start() {
//调用父类的start方法,会根据配置参数创建DriverEndpointRef,这里的父类是CoarseGrainedSchedulerBackend
super.start()
// SPARK-21159. The scheduler backend should only try to connect to the launcher when in client
// mode. In cluster mode, the code that submits the application to the Master needs to connect
// to the launcher instead.
if (sc.deployMode == "client") {
launcherBackend.connect()
}
// The endpoint for executors to talk to us
val driverUrl = RpcEndpointAddress(
sc.conf.get("spark.driver.host"),
sc.conf.get("spark.driver.port").toInt,
CoarseGrainedSchedulerBackend.ENDPOINT_NAME).toString
//设置关于程序运行的参数变量
val args = Seq(
"--driver-url", driverUrl,
"--executor-id", "{{EXECUTOR_ID}}",
"--hostname", "{{HOSTNAME}}",
"--cores", "{{CORES}}",
"--app-id", "{{APP_ID}}",
"--worker-url", "{{WORKER_URL}}")
val extraJavaOpts = sc.conf.getOption("spark.executor.extraJavaOptions")
.map(Utils.splitCommandString).getOrElse(Seq.empty)
val classPathEntries = sc.conf.getOption("spark.executor.extraClassPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
val libraryPathEntries = sc.conf.getOption("spark.executor.extraLibraryPath")
.map(_.split(java.io.File.pathSeparator).toSeq).getOrElse(Nil)
// When testing, expose the parent class path to the child. This is processed by
// compute-classpath.{cmd,sh} and makes all needed jars available to child processes
// when the assembly is built with the "*-provided" profiles enabled.
val testingClassPath =
if (sys.props.contains("spark.testing")) {
sys.props("java.class.path").split(java.io.File.pathSeparator).toSeq
} else {
Nil
}
// Start executors with a few necessary configs for registering with the scheduler
val sparkJavaOpts = Utils.sparkJavaOpts(conf, SparkConf.isExecutorStartupConf)
val javaOpts = sparkJavaOpts ++ extraJavaOpts
//这里的CoarseGraninedExecutorBackend最后会在exector启动相当与exector容器
val command = Command("org.apache.spark.executor.CoarseGrainedExecutorBackend",
args, sc.executorEnvs, classPathEntries ++ testingClassPath, libraryPathEntries, javaOpts)
val webUrl = sc.ui.map(_.webUrl).getOrElse("")
val coresPerExecutor = conf.getOption("spark.executor.cores").map(_.toInt)
// If we're using dynamic allocation, set our initial executor limit to 0 for now.
// ExecutorAllocationManager will send the real initial limit to the Master later.
val initialExecutorLimit =
if (Utils.isDynamicAllocationEnabled(conf)) {
Some(0)
} else {
None
}
//这里包含了注册这个app的所有的信息
val appDesc = ApplicationDescription(sc.appName, maxCores, sc.executorMemory, command,
webUrl, sc.eventLogDir, sc.eventLogCodec, coresPerExecutor, initialExecutorLimit)
//创建AppClient,然后启动
client = new StandaloneAppClient(sc.env.rpcEnv, masters, appDesc, this, conf)
client.start()
launcherBackend.setState(SparkAppHandle.State.SUBMITTED)
waitForRegistration()
launcherBackend.setState(SparkAppHandle.State.RUNNING)
}
接下来看client的start方法,其主要是创建了一个ClientEndpoint;ClientEndpoint继承了ThreadSafeRpcEndpoint,在创建的过程中会调用他的onStart方法

在ClientEndpoint的方法中主要是调用了registerWithMaster(1)方法,最终调用的是tryRegisterAllMasters方法:
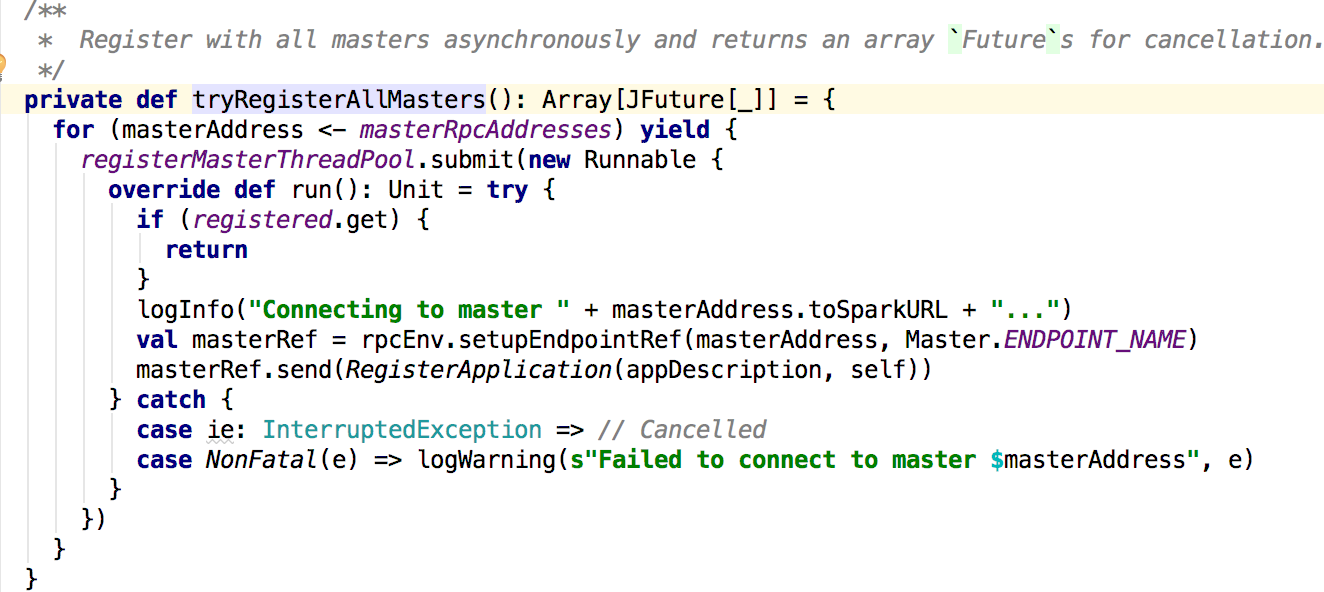
这里向master发送了一个 消息;接下来看看master对这个消息的处理:
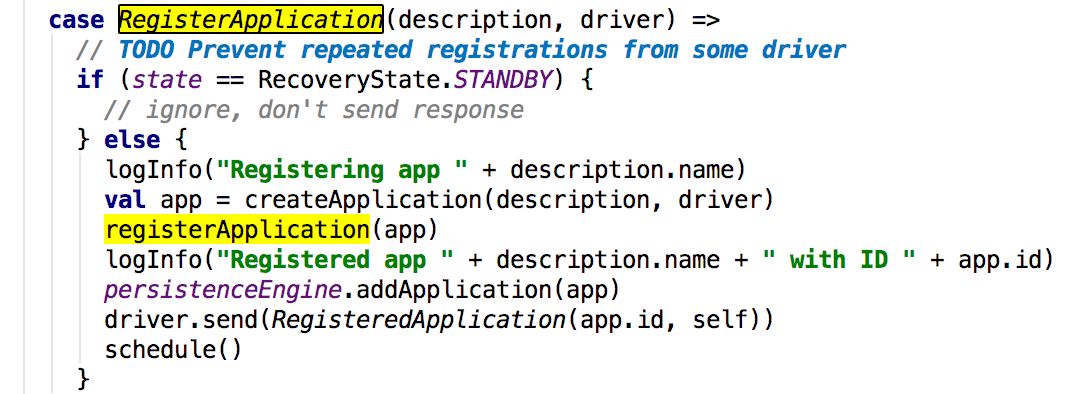
可以看到最后调用的是master的registerApplication方法,其主要就是获取传递到master关于app的数据,然后添加这个app倒Waitingapps中,其后给driver发送registeredApplication消息,
最后调用scheduler方法,其实scheduler在worker启动的时候已经调用过,因此exector,在worker启动完成之后就已经启动了,此处只是新的app过来,因此需要调用scheduler来为app分配资源:
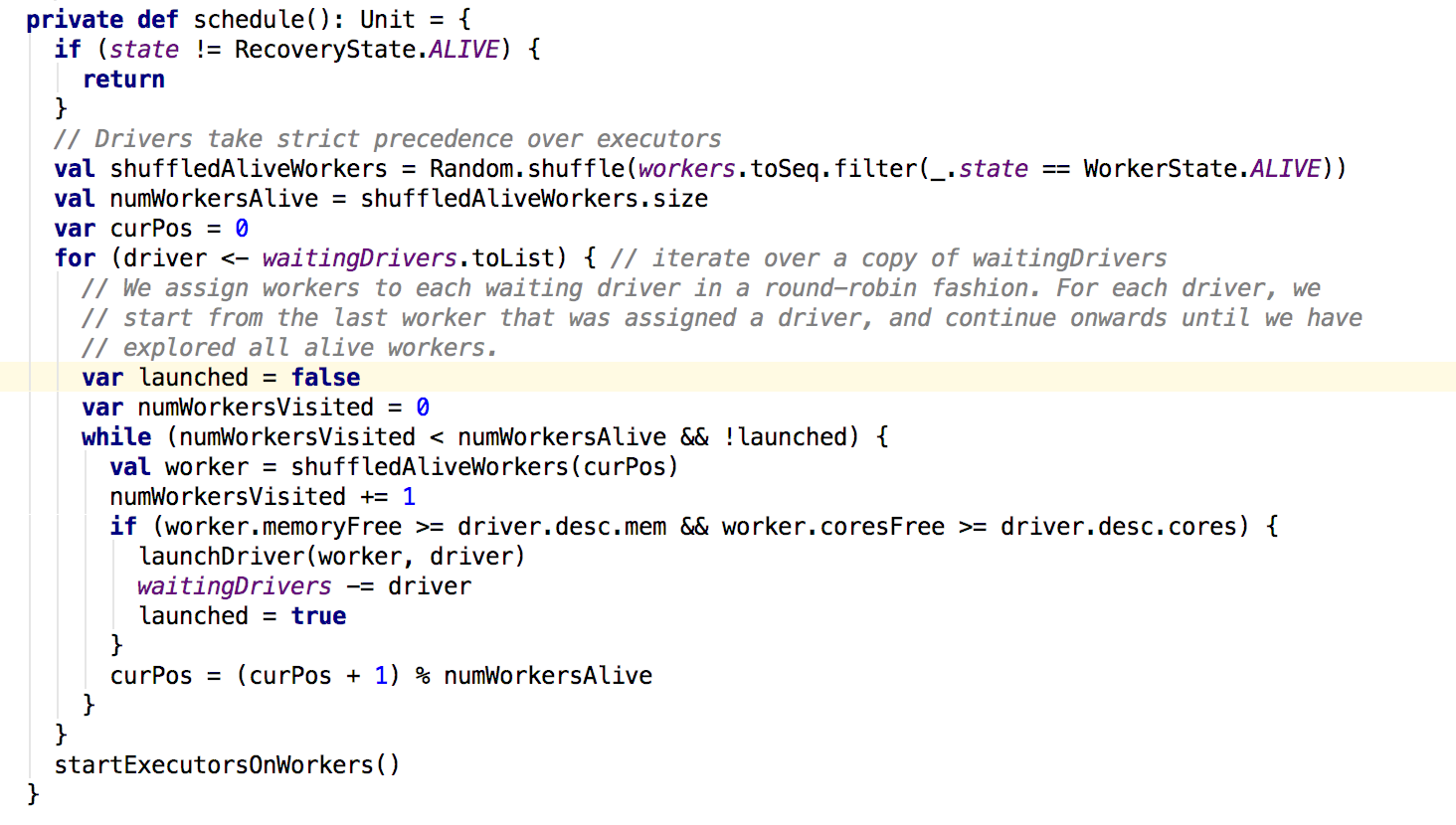
在schedule方法中,首先会进行shuffle操作,类似模拟随机选取操作,然后返回新的随机选取的集合并且过滤出来存活的worker,然后给等待调度的driver分配worker;利用while循环遍历每个woker,若满足申请的内存和core,则分配资源,并结束分配,获取下个等待调度的dirver。。。。在dirver分配到worker之后会调用launchDriver方法:
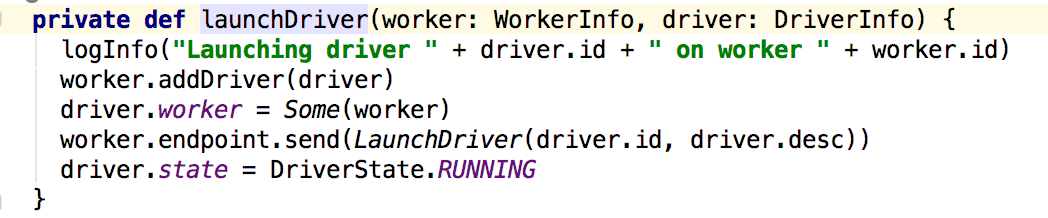
这个方法向worker发送了一个LaunchDriver消息:然后更新了driver的信息,接下来看看worker对消息的处理,
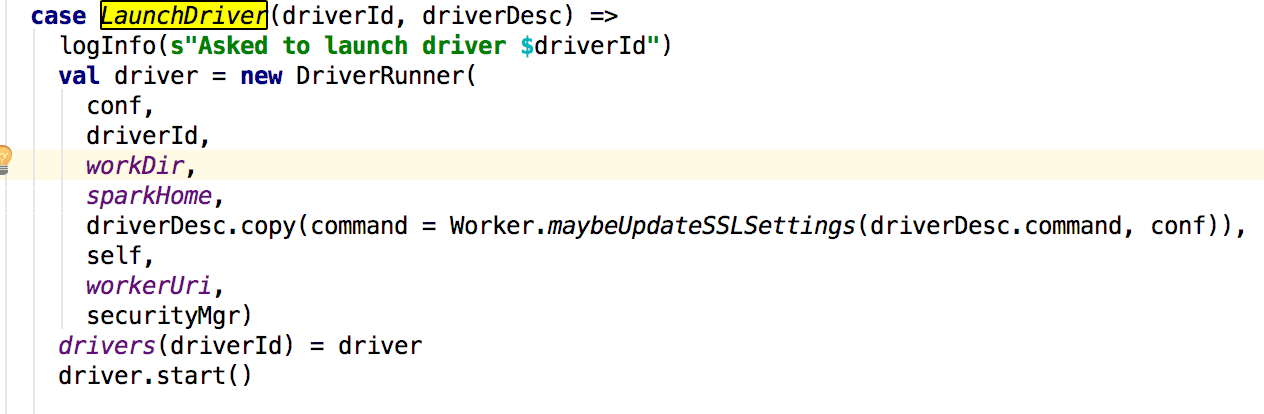
这里创建了一个DriverRunner并且进行了启动,接下来看start方法:
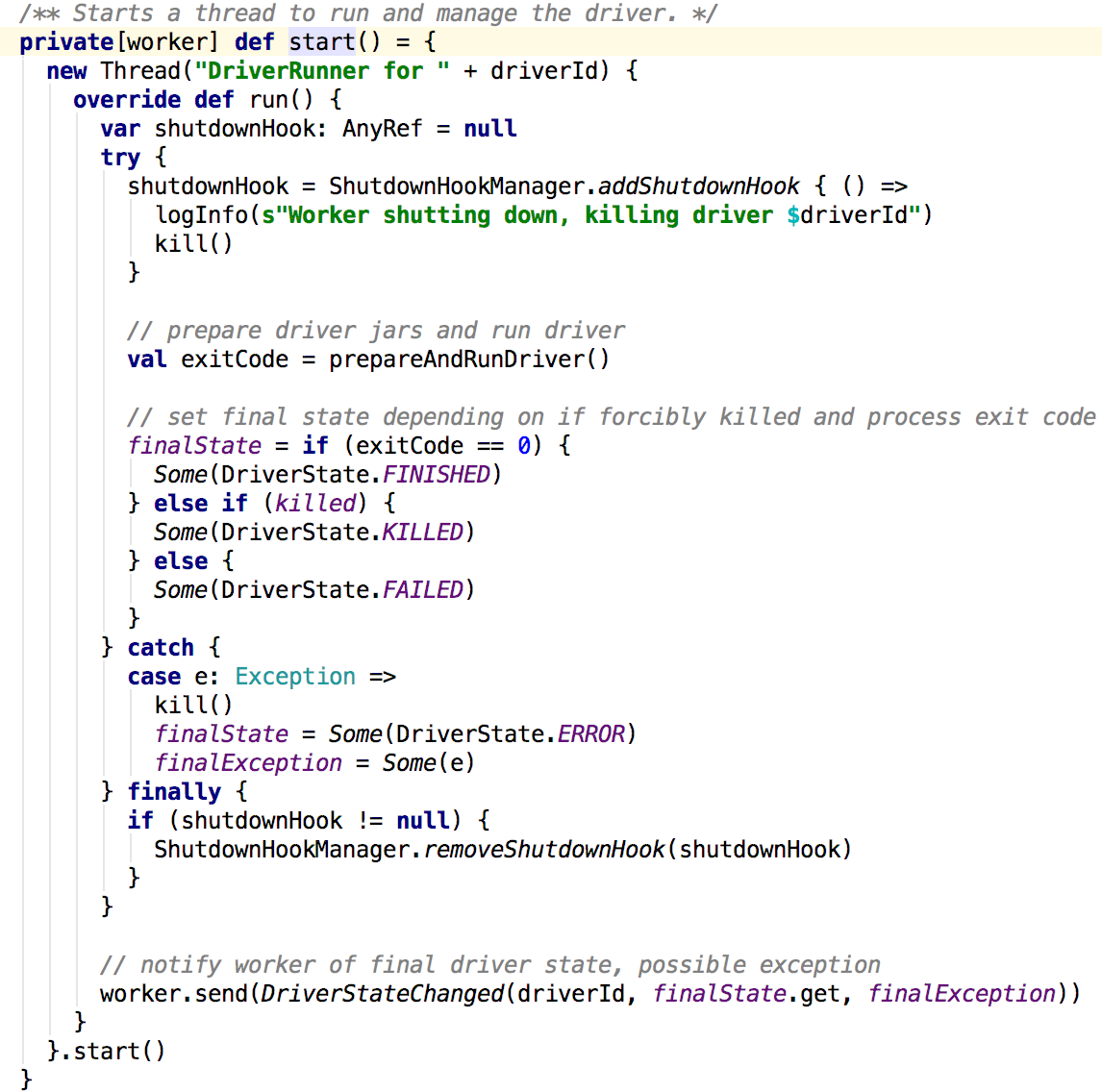
在prepareAndRunDriver中:

可以看到worker启动了一个线程来启动driver,driver利用command的参数builder而成,参数在sparkSubmit启动启动app的时候发送给master加入waitingDrivers中
接下来看startExecutorOnWorkers方法:
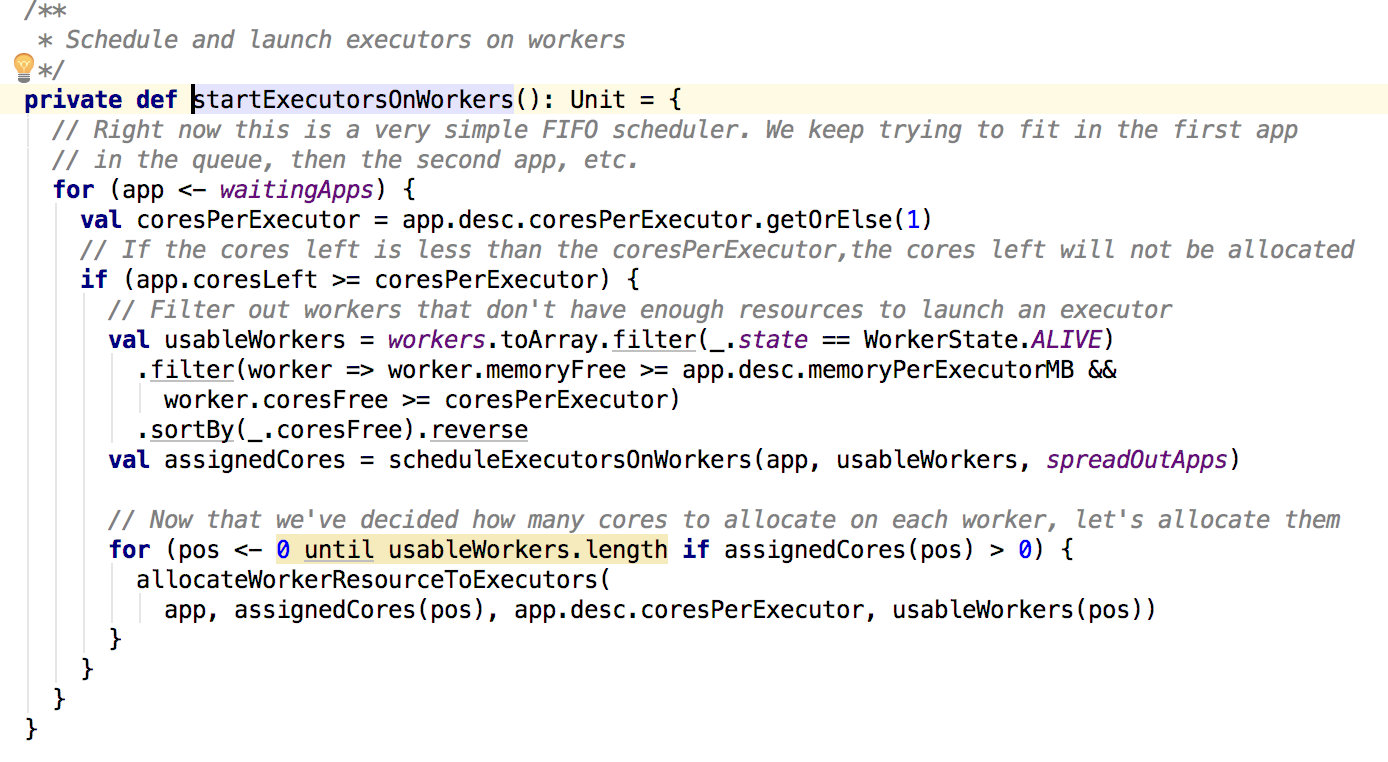
其中主要逻辑就是根据等待的app依次来分配资源,过滤满足需要的内存和core的worker来运行app,最后调用allocateWorkerResourseToExectors,然后在调用了launchExecutor方法:
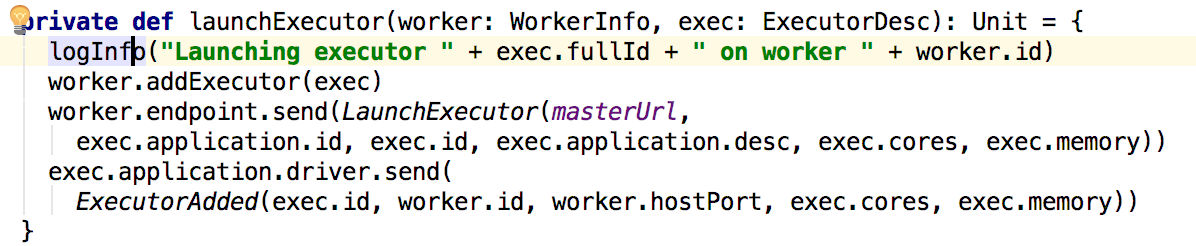
可以看到master向worker发送了启动execitor的信息,下面看worker对这个信息的处理即可:
case LaunchExecutor(masterUrl, appId, execId, appDesc, cores_, memory_) =>
if (masterUrl != activeMasterUrl) {
logWarning("Invalid Master (" + masterUrl + ") attempted to launch executor.")
} else {
try {
logInfo("Asked to launch executor %s/%d for %s".format(appId, execId, appDesc.name)) // 创建exector的工作目录
val executorDir = new File(workDir, appId + "/" + execId)
if (!executorDir.mkdirs()) {
throw new IOException("Failed to create directory " + executorDir)
} // Create local dirs for the executor. These are passed to the executor via the
// SPARK_EXECUTOR_DIRS environment variable, and deleted by the Worker when the
// application finishes.
val appLocalDirs = appDirectories.getOrElse(appId, {
val localRootDirs = Utils.getOrCreateLocalRootDirs(conf)
val dirs = localRootDirs.flatMap { dir =>
try {
val appDir = Utils.createDirectory(dir, namePrefix = "executor")
Utils.chmod700(appDir)
Some(appDir.getAbsolutePath())
} catch {
case e: IOException =>
logWarning(s"${e.getMessage}. Ignoring this directory.")
None
}
}.toSeq
if (dirs.isEmpty) {
throw new IOException("No subfolder can be created in " +
s"${localRootDirs.mkString(",")}.")
}
dirs
})
appDirectories(appId) = appLocalDirs
//创建executorRunner来真正运行executor
val manager = new ExecutorRunner(
appId,
execId,
appDesc.copy(command = Worker.maybeUpdateSSLSettings(appDesc.command, conf)),
cores_,
memory_,
self,
workerId,
host,
webUi.boundPort,
publicAddress,
sparkHome,
executorDir,
workerUri,
conf,
appLocalDirs, ExecutorState.RUNNING)
executors(appId + "/" + execId) = manager
//executorRunner启动
manager.start()
coresUsed += cores_
memoryUsed += memory_
//通知masterexecitor状态
sendToMaster(ExecutorStateChanged(appId, execId, manager.state, None, None))
} catch {
case e: Exception =>
logError(s"Failed to launch executor $appId/$execId for ${appDesc.name}.", e)
if (executors.contains(appId + "/" + execId)) {
executors(appId + "/" + execId).kill()
executors -= appId + "/" + execId
}
sendToMaster(ExecutorStateChanged(appId, execId, ExecutorState.FAILED,
Some(e.toString), None))
}
}
在ExecutorRunner的run方法最后启动一个线程调用的是fetchAndRunExector方法
private def fetchAndRunExecutor() {
try {
// 通过应用程序的信息和环境配置创建构造器builder
val builder = CommandUtils.buildProcessBuilder(appDesc.command, new SecurityManager(conf),
memory, sparkHome.getAbsolutePath, substituteVariables)
val CoarseGrainedExecutorBackend = builder.command()
val formattedCommand = command.asScala.mkString("\"", "\" \"", "\"")
logInfo(s"Launch command: $formattedCommand")
builder.directory(executorDir)
builder.environment.put("SPARK_EXECUTOR_DIRS", appLocalDirs.mkString(File.pathSeparator))
// In case we are running this from within the Spark Shell, avoid creating a "scala"
// parent process for the executor command
builder.environment.put("SPARK_LAUNCH_WITH_SCALA", "0")
// 添加webUi相关设置
val baseUrl =
if (conf.getBoolean("spark.ui.reverseProxy", false)) {
s"/proxy/$workerId/logPage/?appId=$appId&executorId=$execId&logType="
} else {
s"http://$publicAddress:$webUiPort/logPage/?appId=$appId&executorId=$execId&logType="
}
builder.environment.put("SPARK_LOG_URL_STDERR", s"${baseUrl}stderr")
builder.environment.put("SPARK_LOG_URL_STDOUT", s"${baseUrl}stdout")
//启动构造器,这里实际创建的CorarseGrainedExecutorBackend
process = builder.start()
val header = "Spark Executor Command: %s\n%s\n\n".format(
formattedCommand, "=" * 40)
// Redirect its stdout and stderr to files
val stdout = new File(executorDir, "stdout")
stdoutAppender = FileAppender(process.getInputStream, stdout, conf)
val stderr = new File(executorDir, "stderr")
Files.write(header, stderr, StandardCharsets.UTF_8)
stderrAppender = FileAppender(process.getErrorStream, stderr, conf)
// Wait for it to exit; executor may exit with code 0 (when driver instructs it to shutdown)
// or with nonzero exit code
//情启动executor的进程,并等待退出
val exitCode = process.waitFor()
state = ExecutorState.EXITED
val message = "Command exited with code " + exitCode
//通知worker关于executor的状态
worker.send(ExecutorStateChanged(appId, execId, state, Some(message), Some(exitCode)))
} catch {
case interrupted: InterruptedException =>
logInfo("Runner thread for executor " + fullId + " interrupted")
state = ExecutorState.KILLED
killProcess(None)
case e: Exception =>
logError("Error running executor", e)
state = ExecutorState.FAILED
killProcess(Some(e.toString))
}
}
到此work的executor已经启动就等taskScheduler调度的task来运行。
spark exectors的启动总结的更多相关文章
- Spark(四十九):Spark On YARN启动流程源码分析(一)
引导: 该篇章主要讲解执行spark-submit.sh提交到将任务提交给Yarn阶段代码分析. spark-submit的入口函数 一般提交一个spark作业的方式采用spark-submit来提交 ...
- Spark Streaming应用启动过程分析
本文为SparkStreaming源码剖析的第三篇,主要分析SparkStreaming启动过程. 在调用StreamingContext.start方法后,进入JobScheduler.start方 ...
- <spark> error:启动spark后查看进程,进程中master和worker进程冲突
启动hadoop再启动spark后jps,发现master进程和worker进程同时存在,调试了半天配置文件. 测试发现,当我关闭hadoop后 worker进程还是存在, 但是,当我再关闭spark ...
- spark集群启动步骤及web ui查看
集群启动步骤:先启动HDFS系统,在启动spark集群,最后提交jar到spark集群执行. 1.hadoop启动cd /home/***/hadoop-2.7.4/sbinstart-all.sh ...
- Spark On YARN启动流程源码分析(一)
本文主要参考: a. https://www.cnblogs.com/yy3b2007com/p/10934090.html 0. 说明 a. 关于spark源码会不定期的更新与补充 b. 对于spa ...
- [Spark][Flume]Flume 启动例子
Flume 启动例子: flume-ng agent --conf /etc/flume-ng/conf --conf-file /etc/flume-ng/conf/flume.conf --nam ...
- Spark分析之启动流程
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(六)针对spark2.2.1以yarn方式启动spark-shell抛出异常:ERROR cluster.YarnSchedulerBackend$YarnSchedulerEndpoint: Sending RequestExecutors(0,0,Map(),Set()) to AM was unsuccessful
Spark以yarn方式运行时抛出异常: [spark@master bin]$ cd /opt/spark--bin-hadoop2./bin [spark@master bin]$ ./spark ...
- Spark(五十一):Spark On YARN(Yarn-Cluster模式)启动流程源码分析(二)
上篇<Spark(四十九):Spark On YARN启动流程源码分析(一)>我们讲到启动SparkContext初始化,ApplicationMaster启动资源中,讲解的内容明显不完整 ...
随机推荐
- OTRS工单管理系统
OTRS简介 OTRS的名字是由Open-source Ticket Request System首字母縮略字而来,是一个开源的缺陷跟踪管理系统软件. OTRS将电话,邮件等各种渠道提交进来的服务请 ...
- 深度解析pos机,养卡人必看!
好多人对POS 好像都比较迷茫,这个说这个POS 好,那个说那个POS 好.下面就我对POS 的认知给兄弟们说下.对与不对的各位见谅. 第一.一清机 一清机是指在结算日结算后直接通过支付公司账号转 ...
- css3 box-shadow属性 鼠标移动添加阴影效果
text-shadow是给文本添加阴影效果,box-shadow是给元素块添加周边阴影效果. 基本语法:{box-shadow:[inset] x-offset y-offset blur-rad ...
- 名词后变为复数+s,或者+es等怎么读
, 以ce,se,ze, (d)ge等结尾的词 加 -s 读 /iz/ license-licenses, office offices 最佳答案1: 当名词后加-e(-es)变成复数,动词单数第三人 ...
- mongodb 备份、还原、导入、导出
mongodump备份数据库 常用的备份命令格式 mongodump -h IP --port 端口 -u 用户名 -p 密码 -d 数据库 -o 文件存在路径 如果想导出所有数据库,可以去掉-d - ...
- Visual Studio中头文件stdafx.h的作用
在较新版的Visual Studio中,新生成的C++项目文件的的头文件夹下会默认有头文件stdafx.h,而源文件夹下则默认有源文件stdafx.cpp,手动将这些文件删除后,编译时系统还会报错.下 ...
- 蓝牙BLE4.0的LL层数据和L2CAP层数据的区分与理解
一直搞不太清楚蓝牙BLE协议,不知道LL层和L2CAP层是如何划分的,后来博士给我讲了讲就理解了,写下来,做个记录: 1. 我们知道,除了蓝牙5.1新出的CTE,所有的BLE都是如下类型的包: 对于连 ...
- nrf52840蓝牙BLE5.0空中数据解析
一.基础知识: 我没找到蓝牙5.0的ATT数据格式图片,在蓝牙4.0的基础上做修改吧,如下图所示: 二.测试与分析: 参数设置: data length = 251字节,MTU = 247字节, ...
- C/C++心得-从内存开始
因工作与自身各方面需要,开始重新学C,其实说重新也不太准,原来只是大学里面接触过,且还未得多少精髓就转其他开发,不过也正是因此才有了重新学习的必要,基础部分的心得将通过博文记录下来,对于初学者应该有些 ...
- Linux学习总结(二) 网络配置-NAT方式静态IP配置篇
一:DHCP 服务验证 1: 之前我们在里面已经装好了centos,当时我们选择的组网方式为NAT方式,那么我们怎么样如何快速实现虚拟机系统访问外网呢?能不能直接上网呢,来我们试一下ping baid ...