神经网络训练技巧:训练参数初始化、Drop out及Batch Normalization
参数初始化:
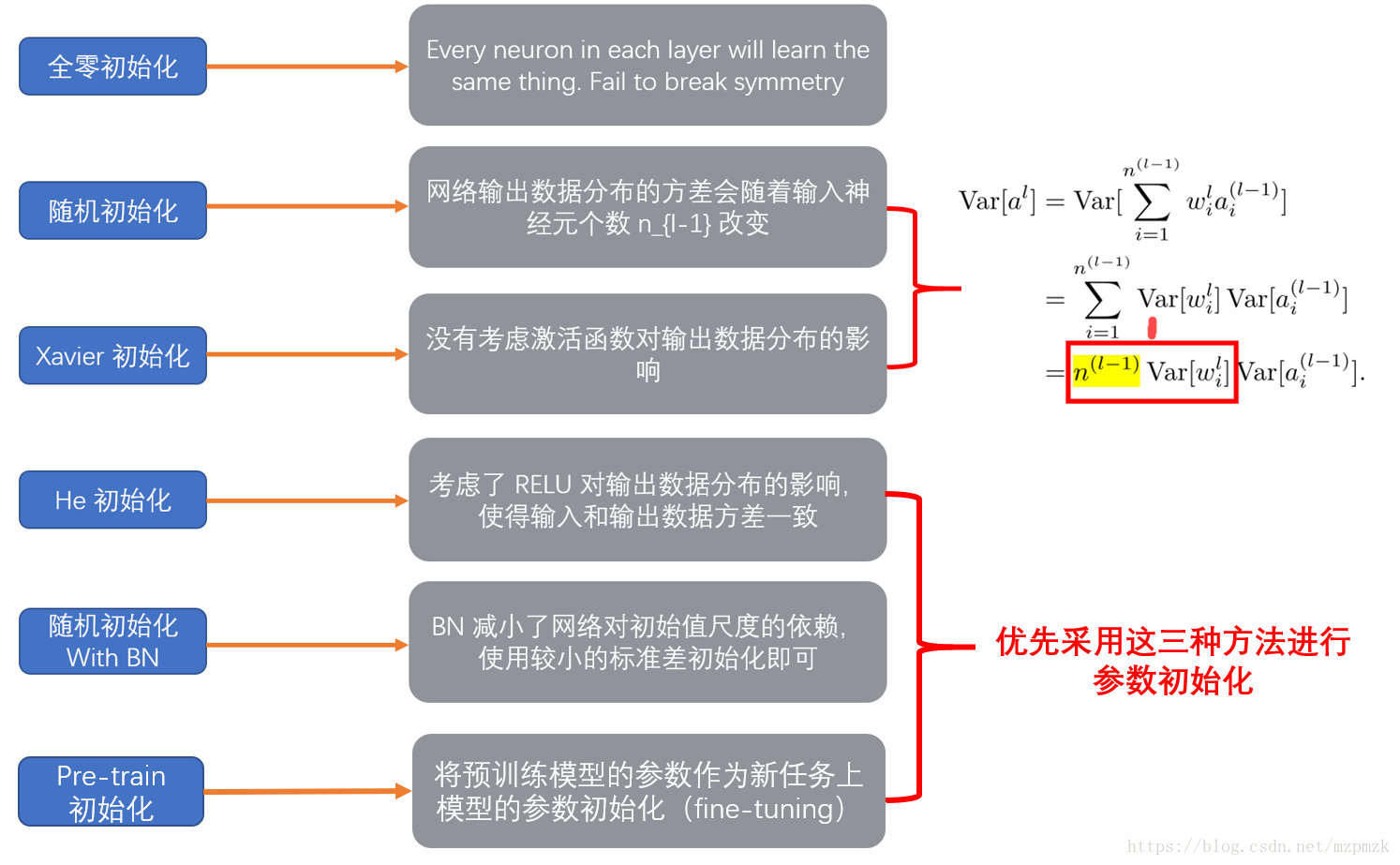
xavier初始化: https://blog.csdn.net/VictoriaW/article/details/73000632
条件:优秀的初始化应该使得各层的激活值和梯度的方差在传播过程中保持一致
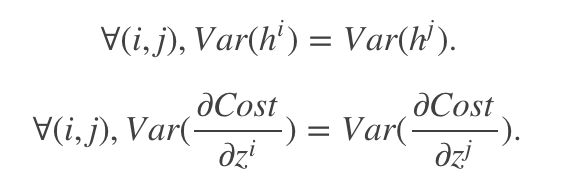
初始化方法: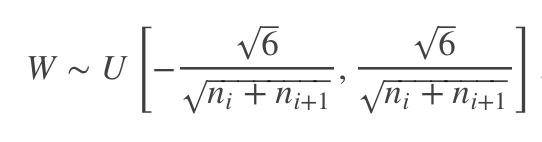
- 假设激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign
He初始化:https://blog.csdn.net/xxy0118/article/details/84333635
- 条件:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
- 适用于ReLU的初始化方法:
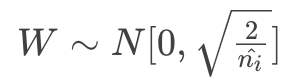
Drop out: https://blog.csdn.net/stdcoutzyx/article/details/49022443
https://zhuanlan.zhihu.com/p/38200980
dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃,故而每一个mini-batch都在训练不同的网络。对于一个有N个节点的神经网络,有了dropout后,就可以看做是$2^n$个模型的集合了,但此时要训练的参数数目却是不变的。
没有dropout的神经网络 :
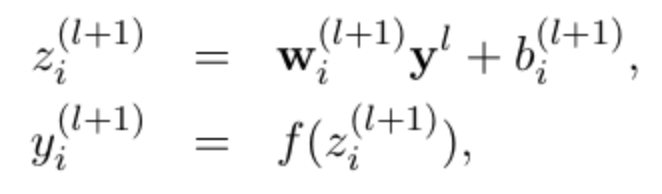
有dropout的神经网络:
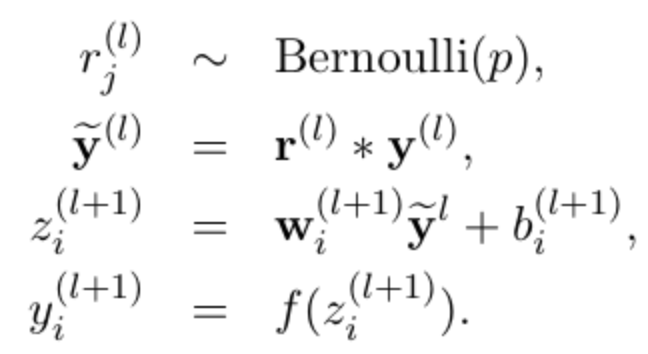
上面的Bernoulli函数的作用是以概率系数p随机生成一个取值为0或1的向量,代表每个神经元是否需要被丢弃。
代码层面实现让某个神经元以概率p停止工作,其实就是让它的激活函数值以概率p变为0。比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、......、y1000,我们dropout比率选择0.4,那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
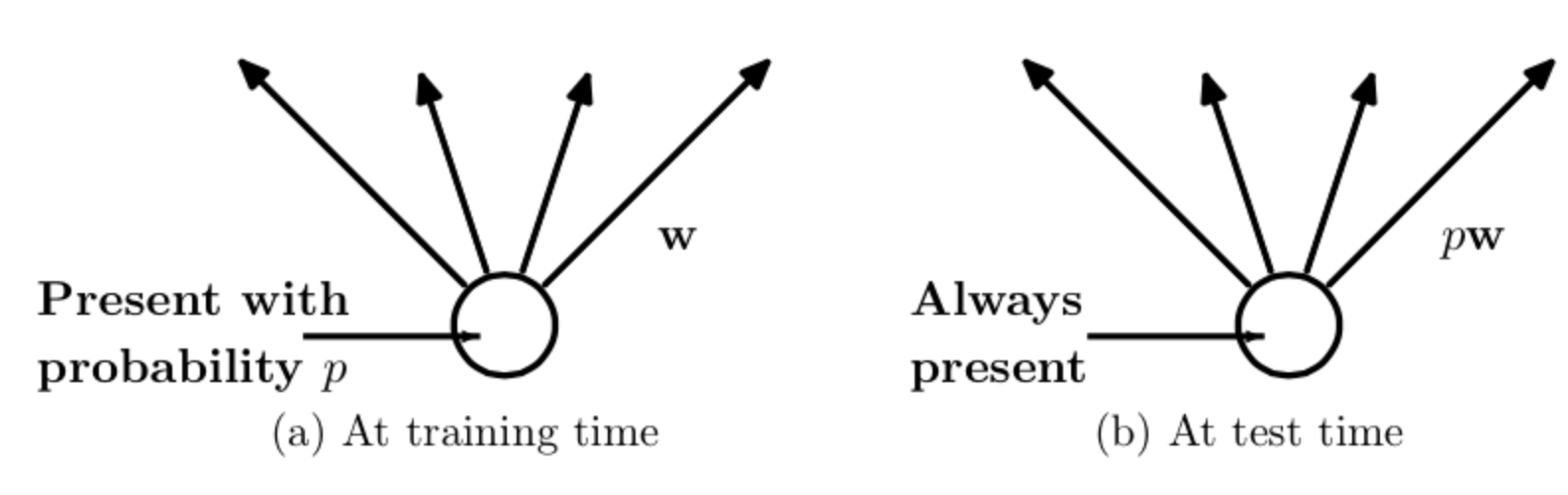
预测的时候,每一个单元的参数要预乘以p:
Batch Normalization:
随着网络训练的进行,每个隐层的参数变化使得后一层的输入发生变化,从而每一批训练数据的分布也随之改变,致使网络在每次迭代中都需要拟合不同的数据分布,增大训练的复杂度以及过拟合的风险。
批量归一化方法是针对每一批数据,在网络的每一层输入之前增加归一化处理(均值为0,标准差为1),将所有批数据强制在统一的数据分布下。
批量归一化降低了模型的拟合能力,归一化之后的输入分布被强制为0均值和1标准差。比如下图,在使用sigmoid激活函数的时候,如果把数据限制到0均值单位方差,那么相当于只使用了激活函数中近似线性的部分,这显然会降低模型表达能力。
为此,作者又为BN增加了2个参数,用来保持模型的表达能力。
于是最后的输出为: 
上述公式中用到了均值E和方差Var,需要注意的是理想情况下E和Var应该是针对整个数据集的,但显然这是不现实的。因此,作者做了简化,用一个Batch的均值和方差作为对整个数据集均值和方差的估计。
整个BN的算法如下:

参考:
https://blog.csdn.net/mzpmzk/article/details/79839047
http://blog.csdn.net/shuzfan/article/details/50723877
https://arxiv.org/pdf/1502.03167.pdf
神经网络训练技巧:训练参数初始化、Drop out及Batch Normalization的更多相关文章
- DL基础补全计划(五)---数值稳定性及参数初始化(梯度消失、梯度爆炸)
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- 神经网络之 Batch Normalization
知乎 csdn Batch Normalization 学习笔记 原文地址:http://blog.csdn.net/hjimce/article/details/50866313 作者:hjimce ...
- 深度学习与CV教程(6) | 神经网络训练技巧 (上)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- TensorFlow之DNN(二):全连接神经网络的加速技巧(Xavier初始化、Adam、Batch Norm、学习率衰减与梯度截断)
在上一篇博客<TensorFlow之DNN(一):构建“裸机版”全连接神经网络>中,我整理了一个用TensorFlow实现的简单全连接神经网络模型,没有运用加速技巧(小批量梯度下降不算哦) ...
- 训练技巧详解【含有部分代码】Bag of Tricks for Image Classification with Convolutional Neural Networks
训练技巧详解[含有部分代码]Bag of Tricks for Image Classification with Convolutional Neural Networks 置顶 2018-12-1 ...
- caffe︱深度学习参数调优杂记+caffe训练时的问题+dropout/batch Normalization
一.深度学习中常用的调节参数 本节为笔者上课笔记(CDA深度学习实战课程第一期) 1.学习率 步长的选择:你走的距离长短,越短当然不会错过,但是耗时间.步长的选择比较麻烦.步长越小,越容易得到局部最优 ...
- loss训练技巧
一,train loss与test loss结果分析4666train loss 不断下降,test loss不断下降,说明网络仍在学习; train loss 不断下降,test loss趋于不变, ...
- 对抗生成网络-图像卷积-mnist数据生成(代码) 1.tf.layers.conv2d(卷积操作) 2.tf.layers.conv2d_transpose(反卷积操作) 3.tf.layers.batch_normalize(归一化操作) 4.tf.maximum(用于lrelu) 5.tf.train_variable(训练中所有参数) 6.np.random.uniform(生成正态数据
1. tf.layers.conv2d(input, filter, kernel_size, stride, padding) # 进行卷积操作 参数说明:input输入数据, filter特征图的 ...
- GAN训练技巧汇总
GAN自推出以来就以训练困难著称,因为它的训练过程并不是寻找损失函数的最小值,而是寻找生成器和判别器之间的纳什均衡.前者可以直接通过梯度下降来完成,而后者除此之外,还需要其它的训练技巧. 下面对历年关 ...
随机推荐
- chrome 调试
https://developers.google.com/web/tools/chrome-devtools/javascript/step-code step over next function ...
- Maven中的dependency详解
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> & ...
- 阶段3 1.Mybatis_08.动态SQL_01.mybatis中的动态sql语句-if标签
创建新的工程 复制到新建的项目里面 pom.xml依赖部分复制过来 dao中整理代码 只保留四个查询 映射文件也只保留四个查询方法 增加一个根据条件查询的方法. 由于用了别名,所以parpameter ...
- MySQL 常用报错注入原理分析
简介 这段时间学习SQL盲注中的报错注入,发现语句就是那么两句,但是一直不知道报错原因,所以看着别人的帖子学习一番,小本本记下来 (1) count() , rand() , group by 1.报 ...
- 解决Pip install Pillow 失败问题
当我在使用Django一个上传图片功能的时候, Django 提示我安装 Pillow这个图片处理的库, 当我尝试安装的时候. 总是提示安装失败 报如下错误. v = self._sslobj.rea ...
- 03.大型数据库应用技术课堂测试3(java.lang.NoSuchMethodError: com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V)
本次问题主要出在了之前没有安装hive,结构导致大部分时间花在了安装上面,主要一直报错,网上找不到相关教程.
- JavaScript —— 常见用途
javaScript 简介 第一个JavaScript 程序: 点击按钮显示日期 <!DOCTYPE html> <html> <head> <meta ...
- CSS——插入形式 基本格式 常见css代码
常见css代码 无下划线链接 字体颜色 + 左边距 背景颜色 字体.字体颜色.大小 文本对齐方式[取代了<center>]
- 【MM系列】SAP MB5B中FI凭证摘要是激活的/结果可能不正确 的错误
公众号:SAP Technical 本文作者:matinal 原文出处:http://www.cnblogs.com/SAPmatinal/ 原文链接:[MM系列]SAP MB5B中FI凭证摘要是激活 ...
- mysql的my.sock不存在问题
因为是初步学习Linux,所以为了对其更加了解,没有使用yum对mysql进行安装,而是使用xftp6的方式上传然后解压安装 1.在安装过程中,好像如果不安装在usr/local目录下会存在不能启动的 ...