做一个简单的scrapy爬虫
前言:
做一个简单的scrapy爬虫,带大家认识一下创建scrapy的大致流程。我们就抓取扇贝上的单词书,python的高频词汇。
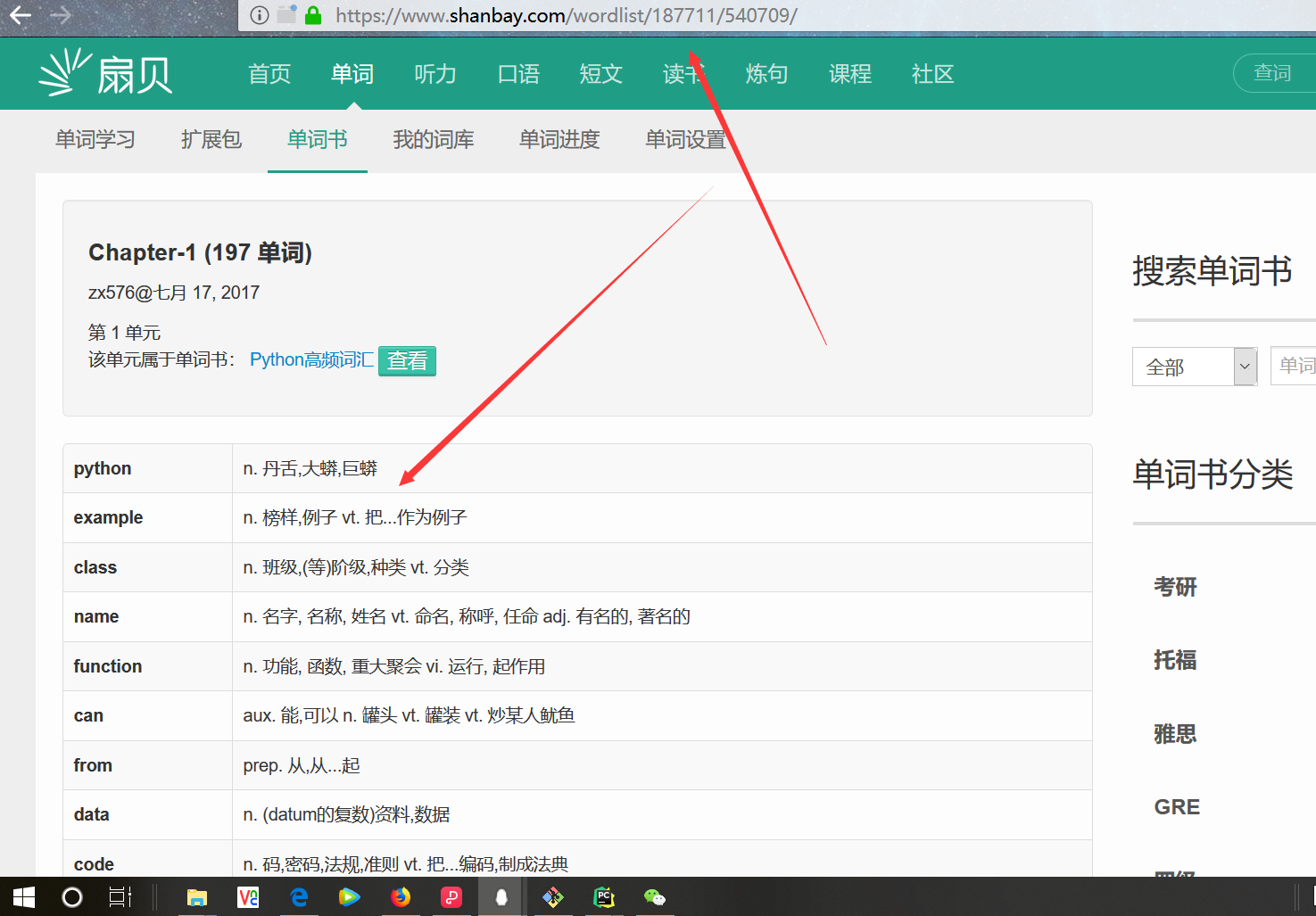
步骤:
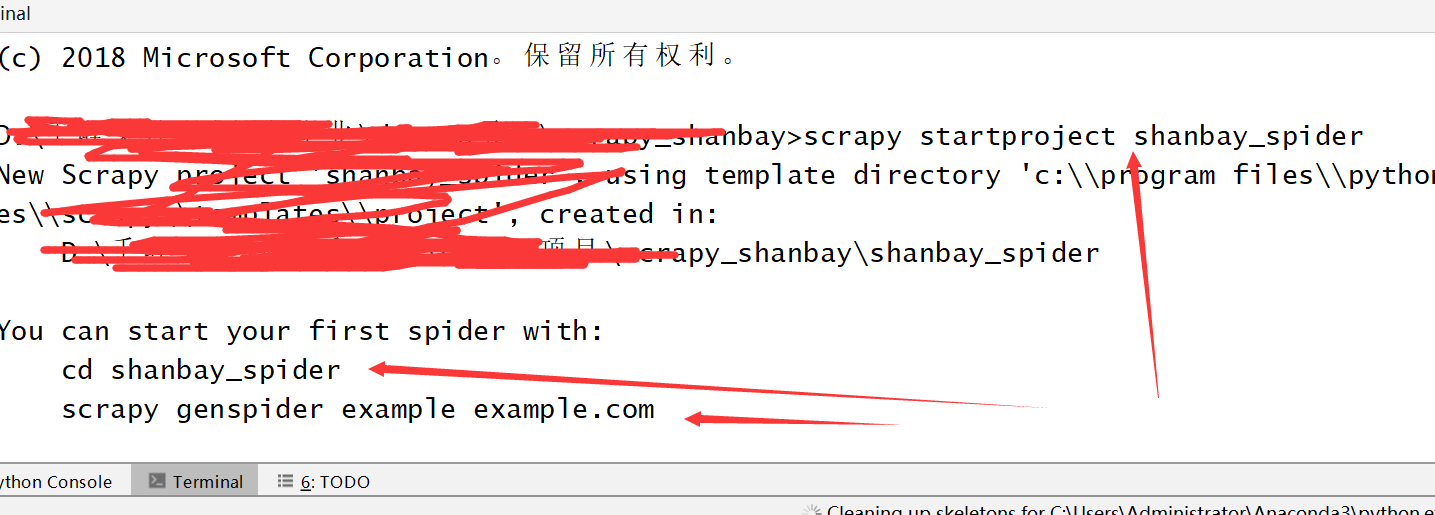
一,新建一个工程scrapy_shanbay
二,在工程中中新建一个爬虫项目,scrapy startproject shanbei_spider
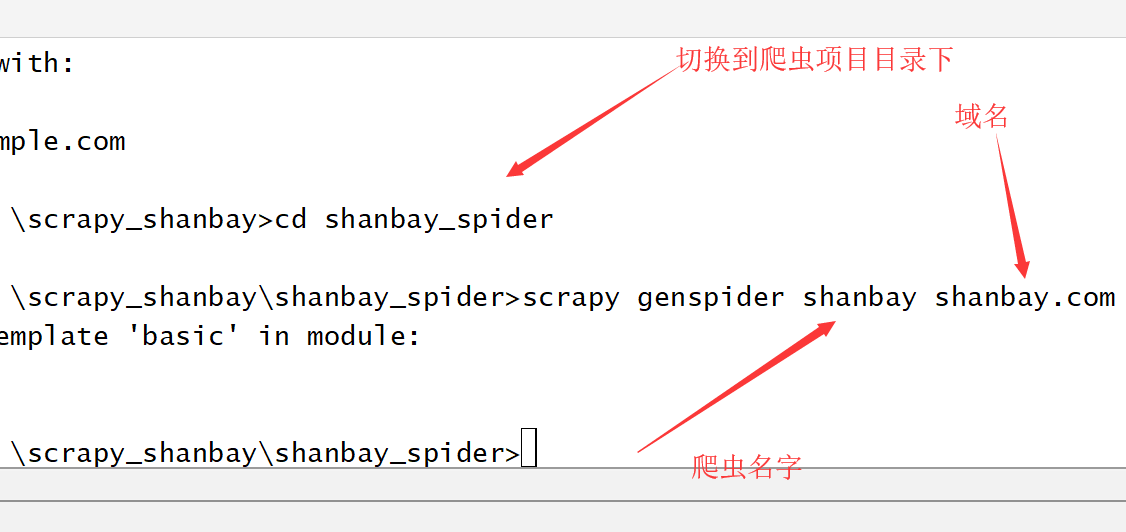
三,切入到项目目录下,然后在项目中,新建一个爬虫spider。scrapy crawl shanbay shanbay.com
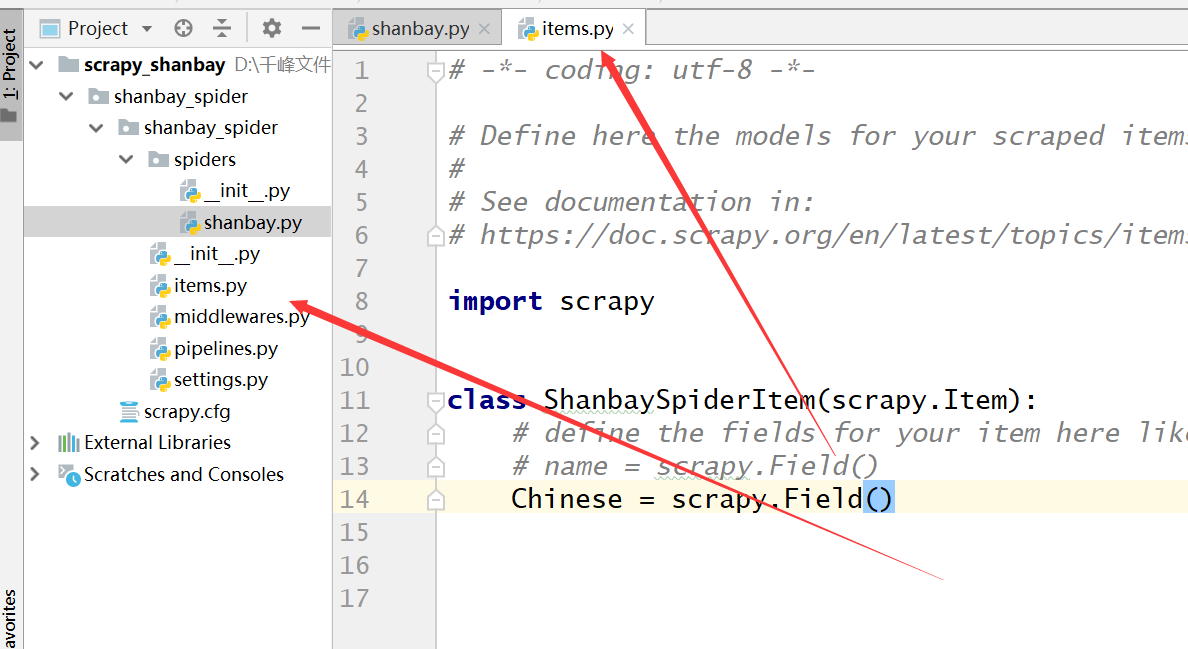
四,在item中,新建一个字段,既要获取的字段。
五,开始书写spider,里面分两部分,第一部分 start_request()主要是获取所有的url,第二部分是解析页面,获取所需要的字段,并存储。
import scrapy
from scrapy.http import Request
from shanbay_spider.items import ShanbaySpiderItem class ShanbaySpider(scrapy.Spider):
name = 'shanbay'
allowed_domains = ['shanbay.com']
# start_urls = ['http://shanbay.com/'] def start_requests(self):
for i in range():
page = + i *
url_base = 'https://www.shanbay.com/wordlist/187711/' + str(page) + '/?page={}'
for x in range():
url = url_base.format(x+ )
yield Request(url,self.parse) def parse(self, response):
html_contents = response.xpath('/html/body/div[3]/div/div[1]/div[2]/div/table/tbody/tr//*/text()')
item = ShanbaySpiderItem() for result in html_contents: item['Chinese'] = result.extract()
yield item
六,执行运行保存命令,scrapy crawl shanbay -o shanbay.csv

七,东西都保存在shanbay.csv中了
总结,其实这个非常简单,但是你用scrapy你会明显感觉到比requests快的很多。而且相比于requests库,你发现用scrapy会很简单。比较明显的一点就是你用request的话,你需要自己写个列表存放url,存进去再一个一个拿出来。再scrapy中,你只需要把url生成,然后yield request就行了,非常之方便。
做一个简单的scrapy爬虫的更多相关文章
- 用Nodejs做一个简单的小爬虫
Nodejs将JavaScript语言带到了服务器端,作为js主力用户的前端们,因此获得了服务器端的开发能力,但除了用express搭建一个博客外,还有什么好玩的项目可以做呢?不如就做一个网络爬虫吧. ...
- 一个简单的scrapy爬虫抓取豆瓣刘亦菲的图片地址
一.第一步是创建一个scrapy项目 sh-3.2# scrapy startproject liuyifeiImage sh-3.2# chmod -R 777 liuyifeiImage/ 二.分 ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 【Bugly干货分享】一起用 HTML5 Canvas 做一个简单又骚气的粒子引擎
Bugly 技术干货系列内容主要涉及移动开发方向,是由Bugly邀请腾讯内部各位技术大咖,通过日常工作经验的总结以及感悟撰写而成,内容均属原创,转载请标明出处. 前言 好吧,说是“粒子引擎”还是大言不 ...
- 使用React并做一个简单的to-do-list
1. 前言 说到React,我从一年之前就开始试着了解并且看了相关的入门教程,而且还买过一本<React:引领未来的用户界面开发框架 >拜读.React的轻量组件化的思想及其virtual ...
- 【 D3.js 入门系列 --- 3 】 做一个简单的图表!
前面说了几节,都是对文字进行处理,这一节中将用 D3.js 做一个简单的柱形图. 做柱形图有很多种方法,比如用 HTML 的 div 标签,或用 svg . 推荐用 SVG 来做各种图形.SVG 意为 ...
- 一起用HTML5 canvas做一个简单又骚气的粒子引擎
前言 好吧,说是"粒子引擎"还是大言不惭而标题党了,离真正的粒子引擎还有点远.废话少说,先看demo 本文将教会你做一个简单的canvas粒子制造器(下称引擎). 世界观 这个简单 ...
- 今天来做一个PHP电影小爬虫。
今天来做一个PHP电影小爬虫.我们来利用simple_html_dom的采集数据实例,这是一个PHP的库,上手很容易.simple_html_dom 可以很好的帮助我们利用php解析html文档.通过 ...
随机推荐
- Normal Equation Algorithm求解多元线性回归的Octave仿真
Normal Equation算法及其简洁,仅需一步即可计算出theta的取值,实现如下: function [theta] = normalEqn(X, y) theta = zeros(size( ...
- Git010--解决冲突
Git--解决冲突 本文来自于:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000/ ...
- .net 项目中cookie丢失解决办法
创建cookie的时候 HttpCookie PdaCookie = new HttpCookie("Pda");PdaCookie ["PdaId"] = 1 ...
- 耗时近一个月,终于录完了VUE.JS2.0前端视频教程!
这次课录制的比较辛苦,圣诞节时原本已经快录制完成了,偶然的一次,播放了一下,感觉不满意,好几篇推倒重来,所以今天才结束. vue.js2.0是Vue.JS的最新版本,视频教程还不多,如果你看到了,学到 ...
- Codeforces - 1194F - Crossword Expert - 组合数学
https://codeforc.es/contest/1194/problem/F 下面是错的. 看起来有点概率dp的感觉? 给你T秒钟时间,你要按顺序处理总共n个事件,每个事件处理花费的时间是ti ...
- python学习第十天列表的增加,修改,删除操作方法
在一个有序的数据列表中,集各种数据类型,可以向列表增加元素,也可以修改列表里面的元素,可以删除列表的里面元素,append(),insert(),remove(),pop(),和全局DEL 删除等. ...
- J Less taolu
链接:https://ac.nowcoder.com/acm/contest/338/J来源:牛客网 题目描述 Less taolu, more sincerity. This problem is ...
- JVM(15)之 类加载器
开发十年,就只剩下这套架构体系了! >>> 今天我们将类加载机制5个阶段中的第一个阶段,加载,又叫做装载.为了便于阅读,以下都叫做装载. 装载的第一步就是要获得二进制的字节 ...
- JavaScript的进制转换
先介绍两个API: 一.number 类型的 toString 方法 语法 JavaScript: numberObject.toString( [ radix ] ) 参数 参数 描述 radix ...
- Ajax ——数据解析
Ajax应用中数据解析是非常重要的一件事情.一般服务器返回数据有三种格式:txt , xml, json 1.解析txt 当服务器返回的数据为字符串,则这种Ajax数据 ...