Shell基础(四):字符串截取及切割、字符串初值的处理、基使用Shell数组、expect预期交互、使用正则表达式
一、字符串截取及切割
目标:
使用Shell完成各种Linux运维任务时,一旦涉及到判断、条件测试等相关操作时,往往需要对相关的命令输出进行过滤,提取出符合要求的字符串。
本案例要求熟悉字符串的常见处理操作,完成以下任务练习:
1> 参考PPT示范操作,完成子串截取、替换等操作
2> 根据课上的批量改名脚本,编写改进版renfilex.sh:能够批量修改当前目录下所有文件的扩展名,修改前/后的扩展名通过位置参数$1、$2提供
方案:
子串截取的三种用法:
• ${var:起始位置:长度}
• expr substr "$var" 起始位置 长度
• echo $var | cut -b 起始位置-结束位置
路径分割:
• 取目录位置:dirname "字符串"
• 取文档的基本名称:basename "字符串"
子串替换的两种用法:
• 只替换第一个匹配结果:${var/old/new}
• 替换全部匹配结果:${var//old/new}
字符串掐头去尾:
• 从左向右,最短匹配删除:${变量名#*关键词}
• 从左向右,最长匹配删除:${变量名##*关键词}
• 从右向左,最短匹配删除:${变量名%关键词*}
• 从右向左,最长匹配删除:${变量名%%关键词*}
步骤:
步骤一:字符串的截取
1)方法一,使用 ${}表达式
格式:${var:起始位置:长度}
定义一个变量Phone,并确认其字符串长度:
[root@svr5 ~]# Phone="13788768897"
[root@svr5 ~]# echo ${#Phone}
11 //包括11个字符
使用${}截取时,起始位置可以省略,省略时从第一个字符开始截。比如,以下操作都可以从左侧开始截取前6个字符:
[root@svr5 ~]# echo ${Phone::6}
137887
或者
[root@svr5 ~]# echo ${Phone:0:6}
137887
使用${}方式截取字符串时,起始位置是从0开始的(和数组下标编号类似) 。
因此,如果从起始位置1开始截取6个字符,那就变成这个样子了:
[root@svr5 ~]# echo ${Phone:1:6}
378876
2)方法二,使用 expr substr
格式:expr substr "$var" 起始位置 长度
还以前面的Phone变量为例,确认原始值:
[root@svr5 ~]# echo $Phone
13788768897
[root@svr5 ~]# echo ${#Phone}
11
使用expr substr截取字符串时,起始编号从1开始,这个要注意与${}相区分。
从左侧截取Phone变量的前6个字符:
[root@svr5 ~]# expr substr "$Phone" 1 6
137887
从左侧截取Phone变量的第9-11个字符:
[root@svr5 ~]# expr substr "$Phone" 9 11
897
3)方式三,使用cut分割工具
格式:echo $var | cut -b 起始位置-结束位置
选项 -b 表示按字节截取字符,其中起始位置、结束位置都可以省略。当省略起始位置时,视为从第1个字符开始(编号也是从1开始,与expr类似),当省略结束位置时,视为截取到最后。
还以前面的Phone变量为例,确认原始值:
[root@svr5 ~]# echo $Phone
13788768897
[root@svr5 ~]# echo ${#Phone}
11
从左侧截取前6个字符,可执行以下操作:
[root@svr5 ~]# echo $Phone | cut -b 1-6
137887
从第8个字符截取到末尾:
[root@svr5 ~]# echo $SCHOOL | cut -b 8-
8897
只截取单个字符,比如第9个字符:
[root@svr5 ~]# echo $SCHOOL | cut -b 9
8
步骤二:字符串的替换
1)只替换第1个子串
格式:${var/old/new}
以SCHOOL变量作为测试,先确认变量值:
[root@svr5 ~]# SCHOOL="Tarena IT Group"
[root@svr5 ~]# echo $SCHOOL
Tarena IT Group.
将字符串中的第1个r替换为RRRR:
[root@svr5 ~]# echo ${SCHOOL/r/RRRR}
TaRRRRena IT Group.
2)替换全部子串
格式:${var//old/new}
将SCHOOL字符串中的所有r都替换为RRRR:
[root@svr5 ~]# echo ${SCHOOL//r/RRRR}
TaRRRRena IT GRRRRoup.
步骤三:字符串的匹配删除
以处理系统默认的邮箱路径为例,可直接使用环境变量MAIL:
[root@svr5 ~]# echo $MAIL
/var/spool/mail/root
1)从左向右,最短匹配删除
格式:${变量名#*关键词}
删除从左侧第1个字符到最近的关键词“oo”的部分,* 作通配符理解:
[root@svr5 ~]# echo ${MAIL#*oo}
l/mail/root
删除从左侧第1个字符到最近的关键词“/”的部分:
[root@svr5 ~]# echo ${MAIL#*/}
var/spool/mail/root
2)从左向右,最长匹配删除
格式:${变量名##*关键词}
删除从左侧第1个字符到最远的关键词“oo”的部分:
[root@svr5 ~]# echo $MAIL //确认变量MAIL的值
/var/spool/mail/root
[root@svr5 ~]# echo ${MAIL##*oo}
t
删除从左侧第1个字符到最远的关键词“/”的部分:
[root@svr5 ~]# echo ${MAIL##*/}
root
操作 ${MAIL##*/} 的效果与使用basename命令提取基本名称的效果相同:
[root@svr5 ~]# basename $MAIL
root
3)从右向左,最短匹配删除
格式:${变量名%关键词*}
删除从右侧最后1个字符到往左最近的关键词“oo”的部分,* 做通配符理解:
[root@svr5 ~]# echo $MAIL //确认变量MAIL的值
[root@svr5 ~]# echo ${MAIL%oo*}
/var/spool/mail/r
删除从右侧最后1个字符到往左最近的关键词“/”的部分:
[root@svr5 ~]# echo ${MAIL%/*}
/var/spool/mail
操作 ${MAIL%/*} 的效果与使用dirname命令提取目录名称的效果相同:
[root@svr5 ~]# dirname $MAIL
/var/spool/mail
4)从右向左,最长匹配删除
格式:${变量名%%关键词*}
删除从右侧最后1个字符到往左最远的关键词“oo”的部分:
[root@svr5 ~]# echo $MAIL //确认变量MAIL的值
/var/spool/mail/root
root@svr5 ~]# echo ${MAIL%%oo*}
/var/sp
删除从右侧最后1个字符到往左最远的关键词“/”的部分(删没了):
[root@svr5 ~]# echo ${MAIL%%/*}
[root@svr5 ~]#
步骤四:编写renfilex.sh脚本
1)验证原始改名脚本renfile.sh的效果
脚本用途为:批量修改当前目录下的文件扩展名,将.doc改为.txt。
脚本内容参考如下:
[root@svr5 ~]# vim renfile.sh
#!/bin/bash
for FILE in *.doc
do
mv $FILE ${FILE%.doc}.txt
done
[root@svr5 ~]# chmod +x renfile.sh
创建一个测试用的文件夹rendir,并在其下建几个测试文件
[root@svr5 ~]# mkdir rendir
[root@svr5 ~]# cd rendir
[root@svr5 rendir]# touch file1.doc abcde.doc xxyyzz.doc other1.xls killbill.mp4
[root@svr5 rendir]# ls
abcde.doc file1.doc killbill.mp4 other1.xls xxyyzz.doc
调用renfile.sh脚本,查看修改结果(原来扩展名为.doc的文件,其扩展名都变成了.txt):
[root@svr5 rendir]# ../renfile.sh
[root@svr5 rendir]# ls
abcde.txt file1.txt killbill.mp4 other1.xls xxyyzz.txt
2)建立改进版脚本renfilex.sh
要适应不同扩展名文件的修改,并能够反向还原。
修改前的扩展名、修改后的扩展名通过位置变量 $1、$2提供。
改进的脚本编写参考如下:
[root@svr5 rendir]# cp ../renfile.sh ../renfilex.sh
[root@svr5 rendir]# vim ../renfilex.sh
#!/bin/bash
for FILE in "$1"
do
mv $FILE ${FILE%$1}"$2"
done
3)验证、测试改进后的脚本
将 *.doc文件的扩展名改为.txt:
[root@svr5 rendir]# ls //修改前
abcde.txt file1.txt killbill.mp4 other1.xls xxyyzz.txt
[root@svr5 rendir]# ../renfilex.sh .txt .doc
[root@svr5 rendir]# ls //修改后
abcde.doc file1.doc killbill.mp4 other1.xls xxyyzz.doc
将 *.mp4文件的扩展名改为.mkv:
[root@svr5 rendir]# ls //修改前
abcde.doc file1.doc killbill.mp4 other1.xls xxyyzz.doc
[root@svr5 rendir]# ../renfilex.sh .mp4 .mkv
[root@svr5 rendir]# ls //修改后
abcde.doc file1.doc killbill.mkv other1.xls xxyyzz.doc
二、字符串初值的处理
目标:
本案例要求编写一个脚本sumx.sh,求从1-x的和,相关要求如下:
• 从键盘读入x值
• 当用户未输入任何值时,默认按1计算
方案:
通过${var:-word}判断变量是否存在,决定是否给变量赋初始值。
步骤:
步骤一:认识字符串初值的最常见处理方法
1)只取值,${var:-word}
若变量var已存在且非Null,则返回 $var 的值;否则返回字串“word”,原变量var的值不受影响。
变量值已存在的情况:
[root@svr5 ~]# echo $SCHOOL //查看原变量值
Tarena IT Group.
[root@svr5 ~]# echo ${SCHOOL:-Tarena} //因SCHOOL已存在,输出变量SCHOOL的值
Tarena IT Group.
[root@svr5 ~]# echo $SCHOOL //原变量的值并不改变
Tarena IT Group.
变量值不存在的情况:
[root@svr5 ~]# unset SCHOOL //清除SCHOOL变量
[root@svr5 ~]# echo ${SCHOOL:-Tarena} //因SCHOOL已不存在,输出“Tarena”
Tarena
[root@svr5 ~]# echo $SCHOOL //变量SCHOOL仍然不存在
[root@svr5 ~]#
编写一个验证知识点的参考示例脚本如下:
[root@svr5 ~]# cat /root/test.sh
#!/bin/bash
read -p "请输入用户名:" user
read -p "请输入用户名:" pass
user=${pass:-123456} //如果用户没有输入密码,则默认密码为123456
useradd $user
echo "123456" | passwd --stdin $pass
步骤二:编写sumx.sh脚本,处理read输入的初值
用来从键盘读入一个正整数x,求从1到x的和;当用户未输入值(直接回车)时,为了避免执行出错,应为x赋初值1 。
1)脚本编写参考如下
[root@svr5 ~]# vim sumx.sh
#!/bin/bash
read -p "请输入一个正整数:" x
x=${x:-1}
i=1; SUM=0
while [ $i -le $x ]
do
let SUM+=i
let i++
done
echo "从1到$x的总和是:$SUM"
[root@svr5 ~]# chmod +x sumx.sh
2)验证、测试脚本执行效果:
[root@svr5 ~]# ./sumx.sh
请输入一个正整数:25 //输入25,正常读入并计算、输出结果
从1到25的总和是:325
[root@svr5 ~]# ./sumx.sh
请输入一个正整数:70 //输入70,正常读入并计算、输出结果
从1到70的总和是:2485
[root@svr5 ~]# ./sumx.sh
请输入一个正整数: //直接回车,设x=1后计算、输出结果
从1到1的总和是:1
三、基使用Shell数组
目标:
本案例要求编写一个Shell脚本getips.sh,相关要求如下:
• 能够反复从键盘输入IP地址,保存到数组
• 当用户输入“EOF”后结束输入,显示数组IPADDS各元素的值
• 最后报告本次录入的IP地址个数、其中第1个录入的地址
方案:
建立数组的方法:
• 格式1,整体赋值:数组名=(值1 值2 .. .. 值n)
• 格式2,单个元素赋值:数组名[下标]=值
查看数组元素的方法:
• 获取单个数组元素:${数组名[下标]}
• 获取所有数组元素:${数组名[*]}
• 获取连续的多个数组元素:${数组名[@]:起始下标:元素个数}
• 截取数组元素值的一部分:${数组名[下标]:起始下标:字符数}
步骤:
步骤一:认识数组的赋值/引用基本方法
1)定义/赋值数组
若要定义数组的成员,可以在declare声明时定义,也可以直接整体定义。整体赋值的格式为“数组名=(值1 值2 值3 .. ..)”,比如:
[root@svr5 ~]# MY_SVRS=(www ftp mail club)
[root@svr5 ~]# set | grep "MY_" //查看数组定义结果
MY_SVRS=([0]="www" [1]="ftp" [2]="mail" [3]="club")
Shell中的语法要求是比较松散的,所以我们也可以直接为单个数组元素赋值,格式为“数组名[下标]=值”,每个数组元素的编号(即下标)从0开始。比如,以下操作会产生一个包括3个元素的数组:
[root@svr5 ~]# WEB_SVRS[0]="www.tarena.com" //为第1个元素赋值
[root@svr5 ~]# WEB_SVRS[1]="mail.tarena.com" //为第2个元素赋值
[root@svr5 ~]# WEB_SVRS[2]="club.tarena.com" //为第3个元素赋值
[root@svr5 ~]# set | grep "WEB_" //查看数组定义
WEB_SVRS=([0]="www.tarena.com" [1]="mail.tarena.com"
[2]="club.tarena.com")
为数组元素赋值时,并不要求每个成员都需要指定,下标也可以不连续。比如,可跳过下标3,直接为下标为4的元素赋值:
[root@svr5 ~]# WEB_SVRS[4]="tts6.tarena.com"
[root@svr5 ~]# set | grep "WEB_" //确认设置结果
WEB_SVRS=([0]="www.tarena.com" [1]="mail.tarena.com" [2]="club.tarena.com" [4]="tts6.tarena.com")
3)查看数组、查看数组元素
输出整个数组的内容:
[root@svr5 ~]# echo ${MY_SVRS[*]}
www ftp mail club
查看第1个(下标为0的)数组元素:
[root@svr5 ~]# echo ${MY_SVRS[0]}
www
输出下标为2的数组元素:
[root@svr5 ~]# echo ${MY_SVRS[2]}
mail
步骤二:编写getips.sh脚本
1)任务需求及思路分析
使用read命令从键盘读入用户指定的IP地址,每次读入一个。
因为需要读多次,直到输入“EOF”时结束,所以可采用while循环结构,循环条件为输入的字符串不为“EOF”。
要求用数组保存每次输入的IP地址,那肯定从下标为0的元素开始存放,赋值操作放在循环体内,下标的递增通过一个变量i控制。
遇“EOF”结束while循环后,输出整个数组的内容,并显示数组元素的个数、第1个录入的IP地址。
2)根据实现思路编写脚本文件
[root@svr5 ~]# vim getips.sh
#!/bin/bash
i=0 //控制下标增长的变量
while :
do
read -p "请添加IP地址(输EOF结束):" IP
[ $IP == "EOF" ] && break
IPADDS[$i]="$IP" //每次录入赋值给不同的数组元素
let i++
done
echo "您已录入的IP地址如下:"
echo ${IPADDS[@]} //输出整个数组
echo "总共包括 ${#IPADDS[@]} 个地址," //报告数组元素的个数
echo "其中第1个IP地址是:${IPADDS[0]}" //输出第1个元素
[root@svr5 ~]# chmod +x getips.sh
3)验证、测试脚本
[root@svr5 ~]# ./getips.sh
请添加IP地址(输EOF结束):192.168.4.77
请添加IP地址(输EOF结束):172.16.16.220
请添加IP地址(输EOF结束):218.56.57.58
请添加IP地址(输EOF结束):192.168.1.5
请添加IP地址(输EOF结束):192.168.1.202
请添加IP地址(输EOF结束):220.106.0.20
请添加IP地址(输EOF结束):EOF
您已录入的IP地址如下:
192.168.4.77 172.16.16.220 218.56.57.58 192.168.1.5 192.168.1.202 220.106.0.20
总共包括 6 个地址,
其中第1个IP地址是:192.168.4.77
四、expect预期交互
目标:
本案例要求编写一个expect脚本,实现SSH登录的自动交互:
1> 提前准备好目标主机,IP地址为192.168.4.5
2> 用户名为mike、密码为1234567
3> 执行脚本后自动登入,并且在目标主机建立测试文件 /tmp/mike.txt
方案:
expect可以为交互式过程(比如FTP、SSH等登录过程)自动输送预先准备的文本或指令,而无需人工干预。触发的依据是预期会出现的特征提示文本。
常见的expect指令:
1> 定义环境变量:set 变量名 变量值
2> 创建交互式进程:spawn 交互式命令行
3> 触发预期交互:expect "预期会出现的文本关键词:" { send "发送的文本\r" }
4> 在spawn建立的进程中允许交互指令:interact
步骤:
步骤一:准备expect及SSH测试环境
1)安装expect工具
[root@svr5 ~]# yum -y install expect //安装expect
.. ..
Installed:
expect.x86_64 0:5.44.1.15-5.el6_4
Dependency Installed:
tcl.x86_64 1:8.5.7-6.el6
[root@svr5 ~]# which expect //确认expect路径
/usr/bin/expect
步骤二:编写expect_ssh脚本,实现免交互登录
1)任务需求及思路分析
在SSH登录过程中,如果是第一次连接到该目标主机,则首先会被要求接受密钥,然后才提示输入密码:
[root@svr5 ~]# ssh mike@192.168.4.5 //连接目标主机
The authenticity of host '192.168.4.5 (192.168.4.5)' can't be established.
RSA key fingerprint is 58:a0:d6:00:c7:f1:34:5d:6c:6d:70:ce:e0:20:f8:f3.
Are you sure you want to continue connecting (yes/no)? yes //接受密钥
Warning: Permanently added '192.168.4.5' (RSA) to the list of known hosts.
mike@192.168.4.5's password: //验证密码
Last login: Thu May 7 22:05:44 2015 from 192.168.4.5
[mike@svr5 ~]$ exit //返回客户端
logout
Connection to 192.168.4.5 closed.
当然,如果SSH登录并不是第一次,则接受密钥的环节就没有了,而是直接进入验证密码的过程:
[root@svr5 ~]# ssh mike@192.168.4.5 //连接目标主机
mike@192.168.4.5's password: //验证密码
Last login: Mon May 11 12:02:39 2015 from 192.168.4.5
[mike@svr5 ~]$ exit //返回客户端
logout
Connection to 192.168.4.5 closed.
2)根据实现思路编写脚本文件
脚本内容参考如下:
[root@svr5 ~]# vim expect_ssh.sh
#!/bin/bash
host=192.168.4.5
expect << EOF
spawn ssh root@$host #//创建交互式进程
expect "password:" { send "123456\r" } #//自动发送密码
expect "# { send "pwd > /tmp/$user.txt \r" } #//发送命令
expect "#" { send "exit\r" }
EOF
[root@svr5 ~]# chmod +x expect_ssh.sh
3)验证、测试脚本
执行脚本前,目标主机上并没有/tmp/mike.txt文件:
[root@svr5 ~]# ls /tmp/mike.txt
ls: 无法访问/tmp/mike.txt: 没有那个文件或目录
执行expect_ssh.sh自动登录脚本:
[root@svr5 ~]# ./expect_ssh.sh
spawn ssh mike@192.168.4.5
mike@192.168.4.5's password:
Last login: Mon May 11 12:08:47 2015 from 192.168.4.5
pwd > /tmp/mike.txt ; exit
[mike@svr5 ~]$ pwd > /tmp/mike.txt ; exit
logout
Connection to 192.168.4.5 closed.
再次检查目标主机,会看到已经建立了/tmp/mike.txt文件,说明expect自动登录并远程执行命令成功:
[root@svr5 ~]# ls -l /tmp/mike.txt
-rw-rw-r--. 1 mike mike 11 5月 11 12:17 /tmp/mike.txt
五、使用正则表达式
目标:
本案例要求熟悉正则表达式的编写,完成以下任务:
1> 利用egrep工具练习正则表达式的基本用法
2> 提取出httpd.conf文件的有效配置行
3> 编写正则表达式,分别匹配MAC地址、E-Mail邮箱地址、IP地址、主机名
方案:
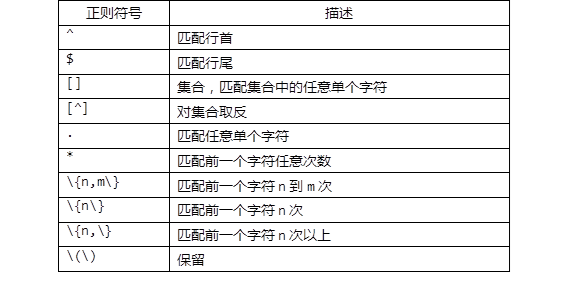
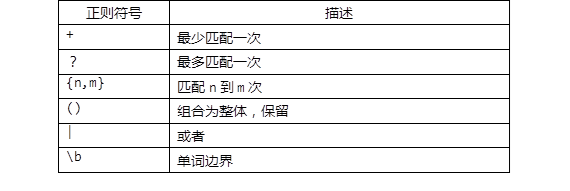
步骤:
步骤一:正则表达式匹配练习
1)典型的应用场合:grep、egrep检索文本行
使用不带-E选项的grep命令时,支持基本正则匹配模式。比如“word”关键词检索、“^word”匹配以word开头的行、“word$”匹配以word结尾的行……等等。
输出以“r”开头的用户记录:
[root@svr5 ~]# grep '^r' /etc/passwd
root:x:0:0:root:/root:/bin/bash
rpc:x:32:32:Portmapper RPC user:/:/sbin/nologin
rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
输出以“localhost”结尾的行:
[root@svr5 ~]# grep 'localhost$' /etc/hosts
127.0.0.1 localhost.localdomain localhost
若希望在grep检索式同时组合多个条件,比如输出以“root”或者以“daemon”开头的行,这时候基本正则就不太方便了(“或者”必须转义为“\|”):
[root@svr5 ~]# grep '^root|^daemon' /etc/passwd //搜索无结果
[root@svr5 ~]#
[root@svr5 ~]# grep '^root\|^daemon' /etc/passwd //正确获得结果
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
而若若使用grep -E或egrep命令,可支持扩展正则匹配模式,能够自动识别 |、{ 等正则表达式中的特殊字符,用起来更加方便,比如:
[root@svr5 ~]# grep -E '^root|^daemon' /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
或者
[root@svr5 ~]# egrep '^root|^daemon' /etc/passwd
root:x:0:0:root:/root:/bin/bash
daemon:x:2:2:daemon:/sbin:/sbin/nologin
使用grep -E 与 使用egrep命令完全等效,推荐使用后者,特别是涉及到复杂的正则表达式的时候。
2)grep、egrep命令的-q选项
选项 -q 表示 quiet(静默)的意思,结合此选项可以只做检索而并不输出,通常在脚本内用来识别查找的目标是否存在,通过返回状态 $? 来判断,这样可以忽略无关的文本信息,简化脚本输出。
比如,检查/etc/hosts文件内是否存在192.168.4.4的映射记录,如果存在则显示“YES”,否则输出“NO”,一般会执行:
[root@svr5 ~]# grep '^192.168.4.4' /etc/hosts && echo "YES" || echo "NO"
192.168.4.4 svr5.tarena.com svr5
YES
这样grep的输出信息和脚本判断后的提示混杂在一起,用户不易辨别,所以可以改成以下操作:
[root@svr5 ~]# grep -q '^192.168.4.4' /etc/hosts && echo "YES" || echo "NO"
YES
是不是清爽多了,从上述结果也可以看到,使用 -q 选项的效果与使用 &> /dev/null的效果类似。
3)基本元字符 ^、$ —— 匹配行首、行尾
输出默认运行级别的配置记录(以id开头的行):
[root@svr5 ~]# egrep '^id' /etc/inittab
id:3:initdefault:
输出主机名配置记录(以HOSTNAME开头的行):
[root@svr5 ~]# egrep '^HOSTNAME' /etc/sysconfig/network
HOSTNAME=svr5.tarena.com
统计本地用户中登录Shell为“/sbin/nologin”的用户个数:
[root@svr5 ~]# egrep -m10 '/sbin/nologin$' /etc/passwd //先确认匹配正确
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
gopher:x:13:30:gopher:/var/gopher:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@svr5 ~]# egrep -c '/sbin/nologin$' /etc/passwd
32 //结合 -c 选项输出匹配的行数
使用 -c 选项可输出匹配行数,这与通过管道再 wc -l的效果是相同的,但是写法更简便。比如,统计使用“/bin/bash”作为登录Shell的正常用户个数,可执行:
[root@svr5 ~]# egrep -c '/bin/bash$' /etc/passwd
26
或者
[root@svr5 ~]# egrep '/bin/bash$' /etc/passwd | wc -l
26
4)基本元字符 . —— 匹配任意单个字符
以/etc/rc.local文件为例,确认文本内容:
[root@svr5 ~]# cat /etc/rc.local
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff. //和下一行之间空出一行
touch /var/lock/subsys/local
输出/etc/rc.local文件内至少包括一个字符(\n换行符除外)的行,即非空行:
[root@svr5 ~]# egrep '.' /etc/rc.local
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff. //和下一行之间没有空行
touch /var/lock/subsys/local
输出/etc/rc.local文件内的空行(用 –v 选项将条件取反):
[root@svr5 ~]# egrep -v '.' /etc/rc.local
[root@svr5 ~]#
上述取空行的操作与下列操作效果相同:
[root@svr5 ~]# egrep '^$' /etc/rc.local
[root@svr5 ~]#
5)基本元字符 +、?、* —— 目标出现的次数
还以/etc/rc.local文件为例:
[root@svr5 ~]# cat /etc/rc.local
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
touch /var/lock/subsys/local
输出包括 f、ff、ff、……的行,即“f”至少出现一次:
[root@svr5 ~]# egrep 'f+' /etc/rc.local
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
输出包括init、initial的行,即末尾的“ial”最多出现一次(可能没有):
[root@svr5 ~]# egrep 'init(ial)?' /etc/rc.local
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
输出包括stu、stuf、stuff、stufff、……的行,即末尾的“f”可出现任意多次,也可以没有。重复目标只有一个字符时,可以不使用括号:
[root@svr5 ~]# egrep 'stuf*' /etc/rc.local
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
输出所有行,单独的“.*”可匹配任意行(包括空行):
[root@svr5 ~]# egrep '.*' /etc/rc.local
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
touch /var/lock/subsys/local
输出/etc/passwd文件内“r”开头且以“nologin”结尾的用户记录,即中间可以是任意字符:
[root@svr5 ~]# egrep '^r.*nologin$' /etc/passwd
rpc:x:32:32:Portmapper RPC user:/:/sbin/nologin
rpcuser:x:29:29:RPC Service User:/var/lib/nfs:/sbin/nologin
6)元字符 {} —— 限定出现的次数范围
创建一个练习用的测试文件:
[root@svr5 ~]# vim brace.txt
ab def ghi abdr
dedef abab ghighi
abcab CD-ROM
TARENA IT GROUP
cdcd ababab
Hello abababab World
输出包括ababab的行,即“ab”连续出现3次:
[root@svr5 ~]# egrep '(ab){3}' brace.txt
cdcd ababab
Hello abababab World
输出包括abab、ababab、abababab的行,即“ab”连续出现2~4次:
[root@svr5 ~]# egrep '(ab){2,4}' brace.txt
dedef abab ghighi
cdcd ababab
Hello abababab World
输出包括ababab、abababab、……的行,即“ab”最少连续出现3次:
[root@svr5 ~]# egrep '(ab){3,}' brace.txt
cdcd ababab
Hello abababab World
7)元字符 [] —— 匹配范围内的单个字符
还以前面的测试文件bracet.txt为例:
[root@svr5 ~]# cat brace.txt
ab def ghi abdr
dedef abab ghighi
abcab CD-ROM
TARENA IT GROUP
cdcd ababab
Hello abababab World
输出包括abc、abd的行,即前两个字符为“ab”,第三个字符只要是c、d中的一个就符合条件:
[root@svr5 ~]# egrep 'ab[cd]' brace.txt
ab def ghi abdr
abcab CD-ROM
输出包括大写字母的行,使用[A-Z]匹配连续范围:
[root@svr5 ~]# egrep '[A-Z]' brace.txt
abcab CD-ROM
TARENA IT GROUP
Hello abababab World
输出包括“非空格也非小写字母”的其他字符的行,本例中大写字母和 – 符合要求:
[root@svr5 ~]# egrep '[^ a-zA-Z]' brace.txt
abcab CD-ROM
8)单词边界匹配
以文件/etc/rc.local为例:
[root@svr5 ~]# cat /etc/rc.local
#!/bin/sh
#
# This script will be executed *after* all the other init scripts.
# You can put your own initialization stuff in here if you don't
# want to do the full Sys V style init stuff.
touch /var/lock/subsys/local
输出包括单词“init”的行,文件中“initialization”不合要求:
[root@svr5 ~]# egrep '\binit\b' /etc/rc.local
# This script will be executed *after* all the other init scripts.
# want to do the full Sys V style init stuff.
或者:
[root@svr5 ~]# egrep '\<init\>' /etc/rc.local
# This script will be executed *after* all the other init scripts.
# want to do the full Sys V style init stuff.
输出包括以“ll”结尾的单词的行,使用 \> 匹配单词右边界:
[root@svr5 ~]# egrep 'll\>' /etc/rc.local
# This script will be executed *after* all the other init scripts.
# want to do the full Sys V style init stuff.
或者:
[root@svr5 ~]# egrep 'll\b' /etc/rc.local
# This script will be executed *after* all the other init scripts.
# want to do the full Sys V style init stuff.
9)多个条件的组合
通过dmesg启动日志查看与IDE接口、CDROM光盘相关的设备信息:
[root@svr5 ~]# egrep '\<IDE\>|\<CDROM\>' /var/log/dmesg
Uniform Multi-Platform E-IDE driver Revision: 7.00alpha2
PIIX4: IDE controller at PCI slot 0000:00:07.1
Probing IDE interface ide0...
Probing IDE interface ide1...
hdc: VMware Virtual IDE CDROM Drive, ATAPI CD/DVD-ROM drive
Probing IDE interface ide0...
通过dmesg启动日志查看蓝牙设备、网卡设备相关的信息:
[root@svr5 ~]# egrep -i 'eth|network|bluetooth' /var/log/dmesg
Initalizing network drop monitor service
Bluetooth: Core ver 2.10
Bluetooth: HCI device and connection manager initialized
Bluetooth: HCI socket layer initialized
Bluetooth: HCI USB driver ver 2.9
Intel(R) PRO/1000 Network Driver - version 7.3.21-k4-3-NAPI
e1000: eth0: e1000_probe: Intel(R) PRO/1000 Network Connection
步骤二:利用正则表达式完成检索任务
1)提取出httpd.conf文件的有效配置行
以RHEL6自带的httpd软件包为例,默认的httpd.conf配置文件内提供了大量的注释信息(# 开头或空几个格再 #),以及一些分隔的空行:
[root@svr5 ~]# head /etc/httpd/conf/httpd.conf //确认文件内容
#
# This is the main Apache server configuration file. It contains the
# configuration directives that give the server its instructions.
# See <URL:http://httpd.apache.org/docs/2.2/> for detailed information.
# In particular, see
# <URL:http://httpd.apache.org/docs/2.2/mod/directives.html>
# for a discussion of each configuration directive.
#
#
# Do NOT simply read the instructions in here without understanding
[root@svr5 ~]# egrep -c ".*" /etc/httpd/conf/httpd.conf
991 //总行数
[root@svr5 ~]# egrep -c "#" /etc/httpd/conf/httpd.conf
674 //含注释的行数
[root@svr5 ~]# egrep -c "^$" /etc/httpd/conf/httpd.conf
95 //空行的数量
提取有效配置行,也就是说应排除掉注释行、空行,根据上面的结果可得知有效配置行的数量应该是“991-674-95=222”,确认一下:
[root@svr5 ~]# egrep -c -v '#|^$' /etc/httpd/conf/httpd.conf
222
结合 > 重定向操作,提取httpd.conf的有效配置,将其保存到文件 httpd.conf.min,相关操作如下:
[root@svr5 ~]# egrep -v '#|^$' /etc/httpd/conf/httpd.conf > httpd.conf.min
[root@svr5 ~]# head httpd.conf.min //确认有效配置的前10行
ServerTokens OS
ServerRoot "/etc/httpd"
PidFile run/httpd.pid
Timeout 120
KeepAlive Off
MaxKeepAliveRequests 100
KeepAliveTimeout 15
<IfModule prefork.c>
StartServers 8
MinSpareServers 5
2)匹配MAC地址、邮箱地址、IP地址
以使用ifconfig查看的结果为例,MAC地址的特征是以“:”分隔的6组十六进制数,每组由2个字符组成,比如:
[root@svr5 ~]# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:0C:29:82:09:E9
inet addr:192.168.4.4 Bcast:192.168.4.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe82:9e9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:177666 errors:0 dropped:0 overruns:0 frame:0
TX packets:101720 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:18454015 (17.5 MiB) TX bytes:13467792 (12.8 MiB)
采用正则表达式匹配“00:0C:29:82:09:E9”形式的MAC地址,可以写成:
[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}
或者:
[0-9a-fA-F]{2}(:[0-9a-fA-F]{2}){5}
其中,[0-9a-fA-F]{2} 表示一段十六进制数值,第二种方式的{5}表示连续出现5组前置 : 的十六进制。
因此,若要从ifconfig eth0的输出结果中过滤出包含MAC地址值的行,可以执行以下操作:
[root@svr5 ~]# ifconfig eth0 | egrep '[0-9a-fA-F]{2}(:[0-9a-fA-F]{2}){5}'
eth0 Link encap:Ethernet HWaddr 00:0C:29:82:09:E9
或者:
[root@svr5 ~]# ifconfig eth0 | egrep \
'[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}:[0-9a-fA-F]{2}'
eth0 Link encap:Ethernet HWaddr 00:0C:29:82:09:E9
根据上述操作结果,稍微扩展一下。利用MAC匹配条件,可以检查一个变量的值是否是合法的MAC地址。参考下列操作:
先定义三个变量:
[root@svr5 ~]# MAC01="00:50:56:C0:00:08"
[root@svr5 ~]# MAC02="20:68:9D:48:C4:98"
[root@svr5 ~]# MAC03="20:69:74:R2:C5:27" //设一个无效地址
利用正则表达式判断出其中哪个MAC地址是无效的:
[root@svr5 ~]# echo $MAC01 | egrep -q \
'[0-9a-fA-F]{2}(:[0-9a-fA-F]{2}){5}' && echo "有效" || echo "无效"
有效
[root@svr5 ~]# echo $MAC02 | egrep -q \
'[0-9a-fA-F]{2}(:[0-9a-fA-F]{2}){5}' && echo "有效" || echo "无效"
有效
[root@svr5 ~]# echo $MAC03 | egrep -q \
'[0-9a-fA-F]{2}(:[0-9a-fA-F]{2}){5}' && echo "有效" || echo "无效"
无效
3)匹配邮箱地址
电子邮箱地址的特征是“用户名@域名”,主要包括:
1> 用户名与域名之间以 @ 分隔
2> 用户名不少于3个字符,可能由字母、下划线、句点 . 、数字组成
3> 域名应至少有一个 . 分隔,分隔的各部分至少2个字符,可能由字母、减号、数字组成
根据上述特点,编写的正则表达式参考如下:其中域名分隔以“\.”表示,不能表示为 . ,否则会匹配任意单个字符。
[0-9a-zA-Z_.]{3,}@[0-9a-zA-Z.-]{2,}(\.[0-9a-zA-Z-]{2,})+
创建一个测试文件,添加若干行主机名、Email、域名地址:
[root@svr5 ~]# vim mailadd.txt
www.tarena.com.cn
mail.163.com
hackli@gmail.com
qq.com
www.sina.com.cn
baidu.com
root@tarena.com
bill@microsoft //无效的邮箱地址,用作测试
suen11_20@163.com
过滤出上述文件中包含有效Email地址的行:
[root@svr5 ~]# egrep '[0-9a-zA-Z_.]{3,}@\
[0-9a-zA-Z.-]{2,}(\.[0-9a-zA-Z-]{2,})+' mailadd.txt
hackli@gmail.com
root@tarena.com.cn
suen11_20@163.com
4)匹配主机名
以FQDN(完整主机名)为例,描述其特点:
1> 由 . 分隔,至少包括3组字符串
2> 每组字符串不少于2个字符,可能由字母、减号、数字、下划线组成
3> 主机名后必须是单词边界,主机名前不能有@符号
编写正则表达式参考如下:
^[^@][0-9a-zA-Z_-]{2,}(\.[0-9a-zA-Z_-]{2,}){2,}\>
以前面的mailadd.txt文件为例,过滤测试如下所示:
[root@svr5 ~]# egrep '^[^@][0-9a-zA-Z_-]{2,}(\.[0-9a-zA-Z_-]{2,}){2,}\>' \
mailadd.txt
www.tarena.com.cn
mail.163.com
www.sina.com.cn
5)匹配IP地址
归纳合法IP地址的特点:
1> 以 . 分隔,一共由四组十进制数构成
2> 每组数值的范围为0-255,字符宽度为1-3位
3> 前后必须是单词边界
编写正则表达式参考如下:
\<[0-9]{1,3}(\.[0-9]{1,3}){3}\>
以过滤出ifconfig命令输出结果中包含IP地址的行为例,过滤测试如下所示:
[root@svr5 ~]# ifconfig //确认原始信息
eth0 Link encap:Ethernet HWaddr 00:0C:29:82:09:E9
inet addr:192.168.4.5 Bcast:192.168.4.255 Mask:255.255.255.0
inet6 addr: fe80::20c:29ff:fe82:9e9/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:182773 errors:0 dropped:0 overruns:0 frame:0
TX packets:104834 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:18913180 (18.0 MiB) TX bytes:13855676 (13.2 MiB)
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:838 errors:0 dropped:0 overruns:0 frame:0
TX packets:838 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:93855 (91.6 KiB) TX bytes:93855 (91.6 KiB)
[root@svr5 ~]# ifconfig | egrep '\<[0-9]{1,3}(\.[0-9]{1,3}){3}\>'
inet addr:192.168.4.4 Bcast:192.168.4.255 Mask:255.255.255.0
inet addr:127.0.0.1 Mask:255.0.0.0
Shell基础(四):字符串截取及切割、字符串初值的处理、基使用Shell数组、expect预期交互、使用正则表达式的更多相关文章
- 字符串截取及切割,正则表达式,expect预期交互
字符串截取及切割,正则表达式,expect预期交互 案例1:字符串截取及切割 案例2:字符串初值的处理 案例3:expe ...
- 笔记:iOS字符串的各种用法(字符串插入、字符串覆盖、字符串截取、分割字符串)(别人的代码直接复制过来的,我脸皮有点厚)
NSString* str=@"hello";//存在代码区,不可变 NSLog(@"%@",str); //1.[字符串插入] NSMutableString ...
- iOS字符串的各种用法(字符串插入、字符串覆盖、字符串截取、分割字符串)
NSString* str=@"hello";//存在代码区,不可变 NSLog(@"%@",str); //1.[字符串插入] NSMutableString ...
- PHP字符串截取,计算字符串长度
/** * 字符串截取,支持中文和其他编码 * @param [string] $str [字符串] * @param integer $start [起始位置] * @param integer $ ...
- loadrunner通过字符串左右边界切割字符串
void web_reg_save_param_custom(char *sourceStr, char* outpuStr, char *leftBdry, char *rightBdry){ ...
- 【iOS】Swift字符串截取方法的改进
字符串截取方法是字符串处理中经常使用的基本方法.熟悉iOS的朋友都知道在基础类的NSString中有substringToIndex:,substringFromIndex:以及substringWi ...
- Python第一天 - list\字符串截取
(一)list截取L =['Adam', 'Lisa', 'Bart'] print(L[0:3]) ======>['Adam'(idnex:0), 'Lisa'(index:1), 'Bar ...
- BAT批处理中的字符串处理详解(字符串截取)
BAT批处理中的字符串处理详解(字符串截取) BAT批处理中的字符串处理详解(字符串截取 批处理有着具有非常强大的字符串处理能力,其功能绝不低于C语言里面的字符串函数集.批处理中可实现的字符串处理 ...
- 【转】BAT批处理中的字符串处理详解(字符串截取)
下面对这些功能一一进行讲解. 1.截取字符串 截取字符串可以说是字符串处理功能中最常用的一个子功能了,能够实现截取字符串中的特定位置的一个或多个字符.举例说明其基本功能: @echo off set ...
随机推荐
- 【Flutter学习】组件学习之目录
01. Flutter组件-Layout-Container-容器 02. Flutter组件-Text-Text-文本 03. Flutter组件-Text-RichText-富文本 04. ...
- BZOJ 1778: [Usaco2010 Hol]Dotp 驱逐猪猡(高斯消元+期望dp)
传送门 解题思路 设\(f(x)\)表示到\(x\)这个点的期望次数,那么转移方程为\(f(x)=\sum\frac{f(u)*(1 - \frac{p}{q})}{deg(u)}\),其中\(u\) ...
- JAVA 的StringBuffer类
StringBuffer类和String一样,也用来代表字符串,只是由于StringBuffer的内部实现方式和String不同,所以StringBuffer在进行字符串处理时,不生成新的对象,在内存 ...
- P3203 [HNOI2010]弹飞绵羊(LCT)
弹飞绵羊 题目传送门 解题思路 LCT. 将每个节点的权值设为\(1\),连接\(i\)和\(i+ki\),被弹飞就连上\(n\),维护权值和\(sum[]\).从\(j\)弹飞需要的次数就是\(sp ...
- LightOJ 1030 Discovering Gold (概率/期望DP)
题目链接:LightOJ - 1030 Description You are in a cave, a long cave! The cave can be represented by a \(1 ...
- upc组队赛6 GlitchBot【枚举】
GlitchBot 题目描述 One of our delivery robots is malfunctioning! The job of the robot is simple; it shou ...
- 类的私有private构造函数 ,为什么要这样做
通常我们都将构造函数的声明置于public区段,假如我们将其放入private区段中会发生什么样的后果?没错,我也知道这将会使构造函数成为私有的,这意味着什么? 我们知道,当我们在程序中声明一个对象时 ...
- echarts 视图自适应问题
最近在项目中用到了echarts,在处理视图自适应问题上记录一下:同时比较一下和highcharts的区别: 在echarts中有一个resize的函数,可以直接在监听窗口变化时重新渲染即可: //在 ...
- 25-python基础-python3-集合(set)常用操作
sets 支持 x in set, len(set),和 for x in set.作为一个无序的集合,sets不记录元素位置或者插入点.因此,sets不支持 indexing, slicing, 或 ...
- 3.3-Cypher语言及语法使用
Cypher是一种图数据库查询语言,表现力丰富,查询效率高,其地位和作用与关系型数据库中的SQL语言相当. Cypher具备的能力: Cypher通过模式匹配图数据库中的节点和关系,来提取信息或者修改 ...