Neo4j百万级数据导入只需30s
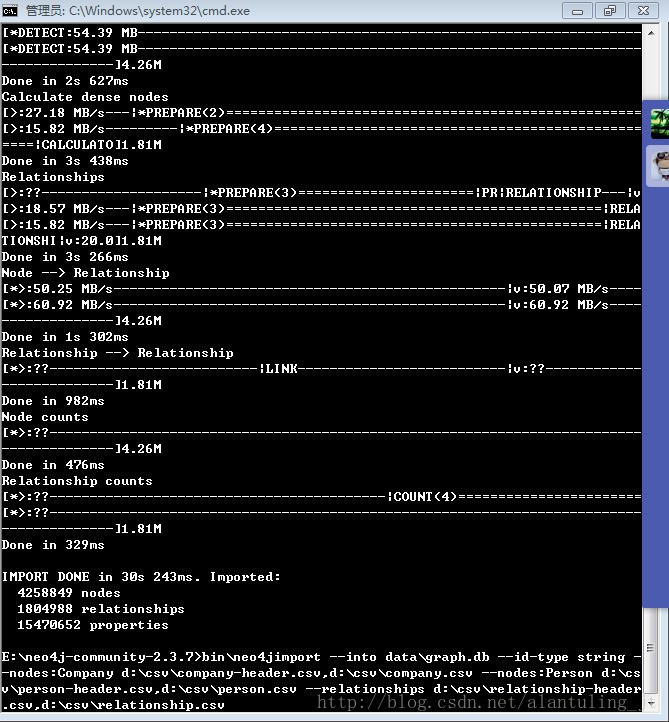
先上图:425万nodes、180万relationships只用了30s 243ms
项目需要生成关系图,开始考虑的是用Neo4j官网提供的REST API,从solr中查出2组数据先创建节点再创建关系,过程相当痛苦,速度非常慢,一天都处理不完;
后来改用cypher语句,通过load csv方法,先将数据生成cvs节点文件和关系文件,再通过load csv file create 语法创建,但文件超过30万条时,服务就出错了,遂放弃;
以上2种方法适合小数据量的图库操作,和局部插入更新,不适合大量数据的导入,生成关系图;
后来通过使用官方提供的Neo4jImport 命令行导入数据成功。命令格式在上图中最下面部分有。
首先是要通过查库生成一定格式的csv数据,按node,relationship分别生成,这个可以通过java写代码生成,格式如下:
例子:
节点文件:
文件名:person.csv
文件内容:
id:ID,name,sex,age
p123,jobs,male,28
文件名:company-header.csv
文件内容:
id:ID,entName
文件名:company.csv
文件内容:
c111,Apple
关系文件:
文件名:relationship-header.csv
文件内容:
:START_ID,:END_ID,:TYPE
文件名:relationship.csv
文件内容:
p123,c111,founder
说明:其中一个文件可以分两部分写,一部分写文件头部信息,这些可能需要人为更改,较方便;内容部分一般是代码生成,数据量大,打开修改很费事,一般不动,所以建议分开写,如例子中company-header.csv和company.csv文件就分属于头部文件和内容文件。
:ID表示此列的值作为接连值,并会创建索引,所以如果这列的值有重复,在创建的时候会报错;
:START_ID表示起始节点的ID值;
:END_ID表示结束节点的ID值;
:TYPE表示关系值;
例子中表示的是jobs是Apple公司的创始人;
当然还有其他一些格式,比如:
:LABEL 给列设置标签,可以设置多个标签,用分号分隔;
:IGNORE该列不创建properties
:START_ID(Company)指定该列只能是company中ID的值,前提是company中id:ID(Company)也这样写。
另外,有问题可以留言探讨,我也是刚研究了一周。
原文地址:https://www.jianshu.com/p/0aff60f766f3
Neo4j百万级数据导入只需30s的更多相关文章
- 详解如何挑战4秒内百万级数据导入SQL Server(转)
对于大数据量的导入,是DBA们经常会碰到的问题,在这里我们讨论的是SQL Server环境下百万级数据量的导入,希望对大家有所帮助.51CTO编辑向您推荐<SQL Server入门到精通&g ...
- NEO4J亿级数据导入导出以及数据更新
1.添加配置 apoc.export.file.enabled=true apoc.import.file.enabled=true dbms.directories.import=import db ...
- 实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- 【转 】实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- Excel导入数据库百万级数据瞬间插入
Excel导入数据库百万级数据瞬间插入 百万级别,瞬间,有点吊哇
- Sql Server中百万级数据的查询优化
原文:Sql Server中百万级数据的查询优化 万级别的数据真的算不上什么大数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写方法有着千差万别的性能,都在这个级别中显现出来了,它不仅考 ...
- EF查询百万级数据的性能测试--多表连接复杂查询
相关文章:EF查询百万级数据的性能测试--单表查询 一.起因 上次做的是EF百万级数据的单表查询,总结了一下,在200w以下的数据量的情况(Sql Server 2012),EF是可以使用,但是由于 ...
- 【eclipse jar包】在编写java代码时,为方便编程,常常会引用别人已经实现的方法,通常会封装成jar包,我们在编写时,只需引入到Eclipse中即可。
Eclipse中导入外部jar包 在编写java代码时,为方便编程,常常会引用别人已经实现的方法,通常会封装成jar包,我们在编写时,只需引入到Eclipse中即可. 工具/原料 Eclipse 需要 ...
- MSSQL、MySQL 数据库删除大批量千万级百万级数据的优化
原文:https://blog.csdn.net/songyanjun2011/article/details/7308414 SQL Server上面删除1.6亿条记录,不能用Truncate(因为 ...
随机推荐
- elasticsearch 基础 —— Explain、Version、min_score、query rescorer
Explain 相关度得分计算: GET /_search { "explain": true, "query" : { "term" : ...
- shell条件判断命令test
- tensorflow教程:tf.contrib.rnn.DropoutWrapper
tf.contrib.rnn.DropoutWrapper Defined in tensorflow/python/ops/rnn_cell_impl.py. def __init__(self, ...
- css3 清除浮动
eg:三个div,父级div下面有两个div分别float:left和float:right <style> .container{width:400px;border:3px soild ...
- spring整合Quartz2持久化任务调度
转摘 https://blog.csdn.net/qwe6112071/article/details/50999386 因为通过Bean配置生成的JobDetail和CronTrigger或Simp ...
- CSS9:动态 REM-手机专用的自适应方案
CSS9:动态 REM-手机专用的自适应方案 动态 REM是手机专用,是如何适配所有手机的方案,不是响应式方案,例如 : taobao.com 是专门的PC端m.taobao.com 是专门的手机端, ...
- python3-Django初始化项目详细
0.背景 近期在学习django,在初始化项目的时候遇到了一丢坑,记录一下. 1.安装django 下载安装包解压出来后,python3 setup.py install 即可 2.创建项目 djan ...
- Java并发与多线程与锁优化
前言 目前CPU的运算速度已经达到了百亿次每秒,所以为了提高生产率和高效地完成任务,基本上都采用多线程和并发的运作方式. 并发(Concurrency):是指在某个时间段内,多任务交替处理的能力.CP ...
- php strtok()函数 语法
php strtok()函数 语法 作用:逐一分割字符串大理石构件 语法:strtok(string,split) 参数: 参数 描述 string 必需.规定要分割的字符串. split 必需.规定 ...
- PHP curl_copy_handle函数
curl_copy_handle — 复制一个cURL句柄和它的所有选项 说明 resource curl_copy_handle ( resource $ch ) 复制一个cURL句柄并保持相同的选 ...