大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle
yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle
因为mapreduce程序运行在nodemanager上,nodemanager运行mapreduce程序的方式就是shuffle。
1.首先,数据在HDFS上是以数据块的形式保存,默认大小128M。
2.数据块对应成数据切片送到Mapper。默认一个数据块对应一个数据切块。
3.Mapper阶段
4.Mapper处理完,写到内存中作缓冲(环形缓冲区,默认100M)
5.内存满80%就发生溢写,进行一次IO操作,写到HDFS的文件系统上。
6.作一个处理,将小文件合成一个大文件
7.Combiner:在Mapper端先做一次Reducer,做一个合并操作
8.将Combiner的数据放到Reducer
9.输出到HDFS
图解:
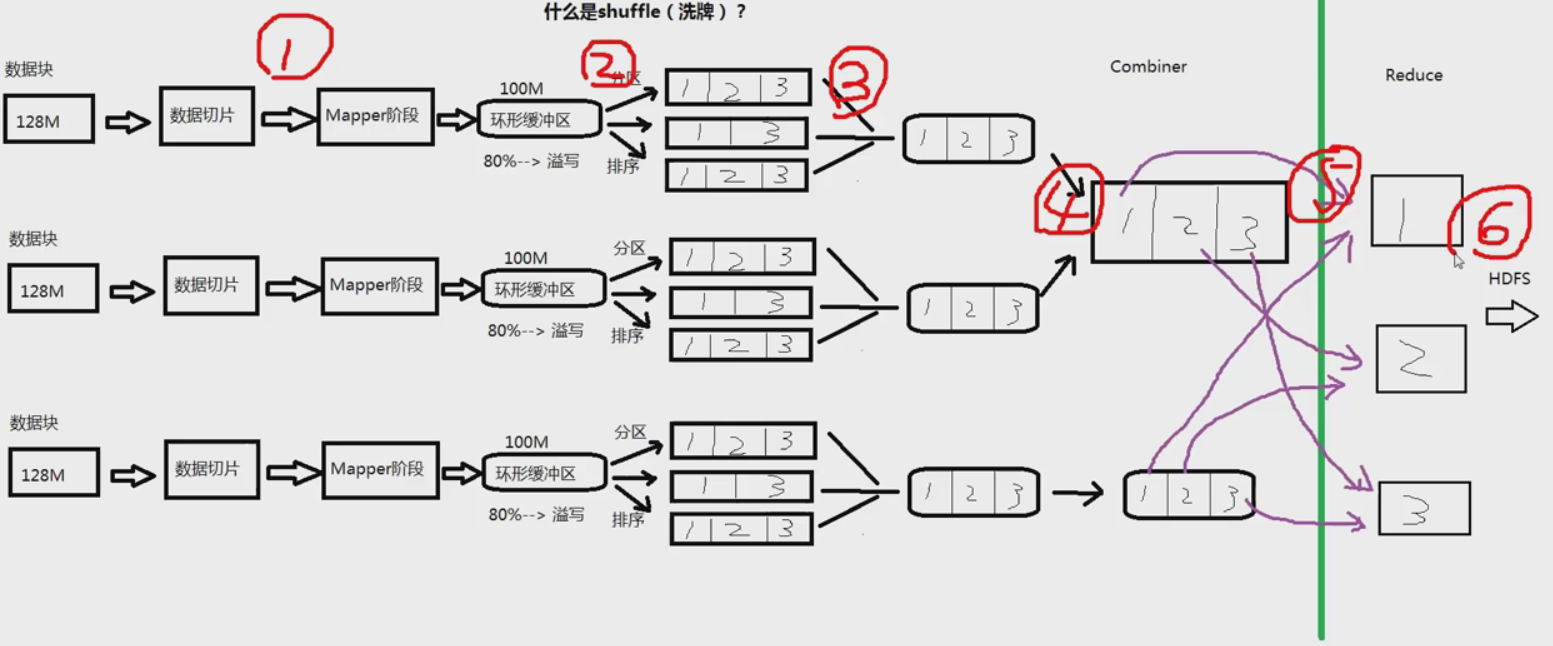
Maprecue的缺点:发生的IO次数太多(图示标号),严重影响性能。
解决方式:Spark(基于内存)
二.MapReduce编程案例
1.多表查询:等值连接
查询员工信息:部门名称、员工姓名
实现SQL语句:在emp表,dept表联合查询,查询每个部门下面的员工
select d.dname,e.ename
from emp e,dept d
where e.deptno=d.deptno;
分析:
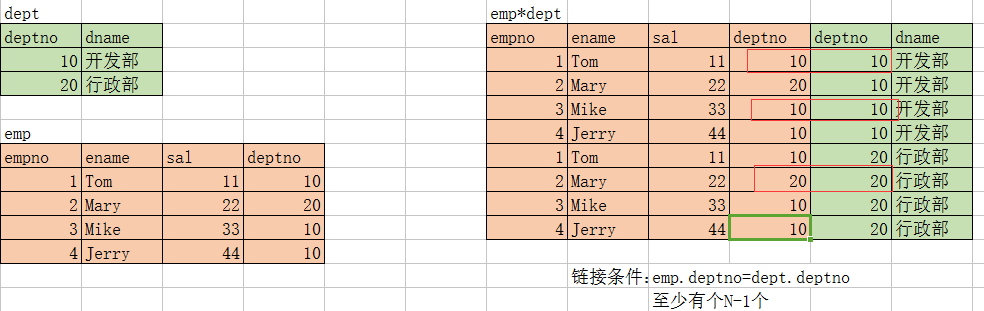
使用MR实现等值连接的分析流程:
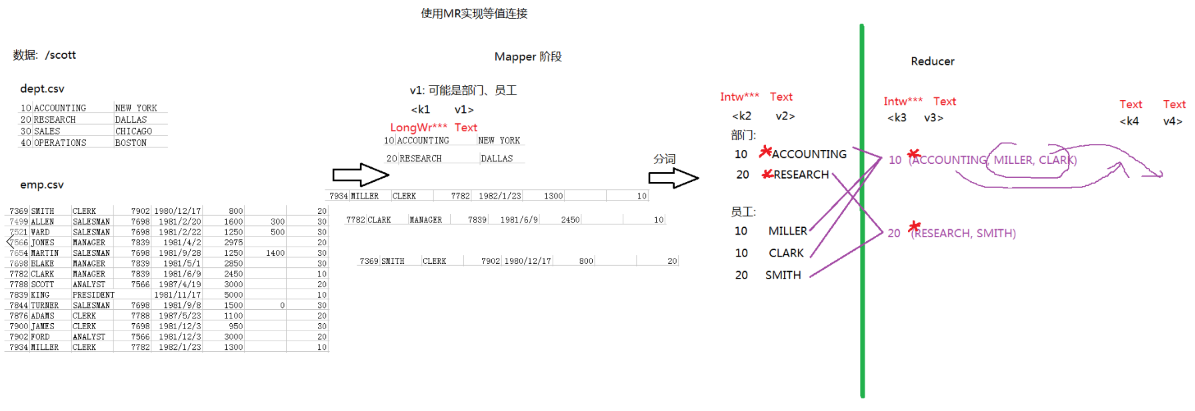
程序:
MultiTableQueryMapper.java
package demo.multiTable; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
//k2 部门号 v2 部门名称
public class MultiTableQueryMapper extends Mapper<LongWritable, Text, LongWritable, Text> { @Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
//数据:可能是部门,也可能是员工
String data = value1.toString();
//分词
String[] words = data.split(",");
//判断数组的长度
if (words.length == 3) {
//部门表:部门号 部门名称
context.write(new LongWritable(Long.parseLong(words[0])), new Text("*"+words[1]));
}else {
//员工表:部门号 员工名称
context.write(new LongWritable(Long.parseLong(words[7])), new Text(words[1]));
}
} }
MultiTableQueryReducer.java
package demo.multiTable; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class MultiTableQueryReducer extends Reducer<LongWritable, Text, Text, Text> { @Override
protected void reduce(LongWritable k3, Iterable<Text> v3, Context context)
throws IOException, InterruptedException {
//定义变量:保存 部门名称和员工姓名
String dname = "";
String empNameList = ""; for (Text text : v3) {
String string = text.toString();
//找到* 号的位置
int index = string.indexOf("*");
if (index >= 0) {
//代表的是部门名称
dname = string.substring(1);
}else {
//代表的是员工姓名
empNameList = string + ";" + empNameList;
}
} //输出 部门名字 员工姓名字符串
context.write(new Text(dname), new Text(empNameList));
} }
MultiTableQueryMain.java
package demo.multiTable; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.DoubleWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class MultiTableQueryMain { public static void main(String[] args) throws Exception {
Job job = Job.getInstance(new Configuration()); job.setJarByClass(MultiTableQueryMain.class); job.setMapperClass(MultiTableQueryMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class); job.setReducerClass(MultiTableQueryReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true);
} }
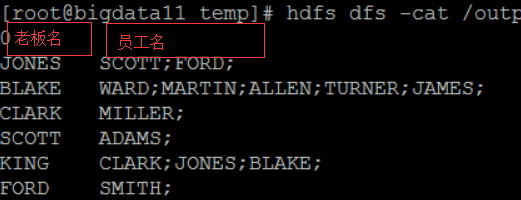
结果:

2.多表查询:自连接
自连接:通过表的别名,将同一张表看成多张表
需求:查询一个表内老板姓名和对应的员工姓名
实现SQL语句:
select b.ename,e.ename
from emp b,emp e
where b.empno=e.mgr;
分析:
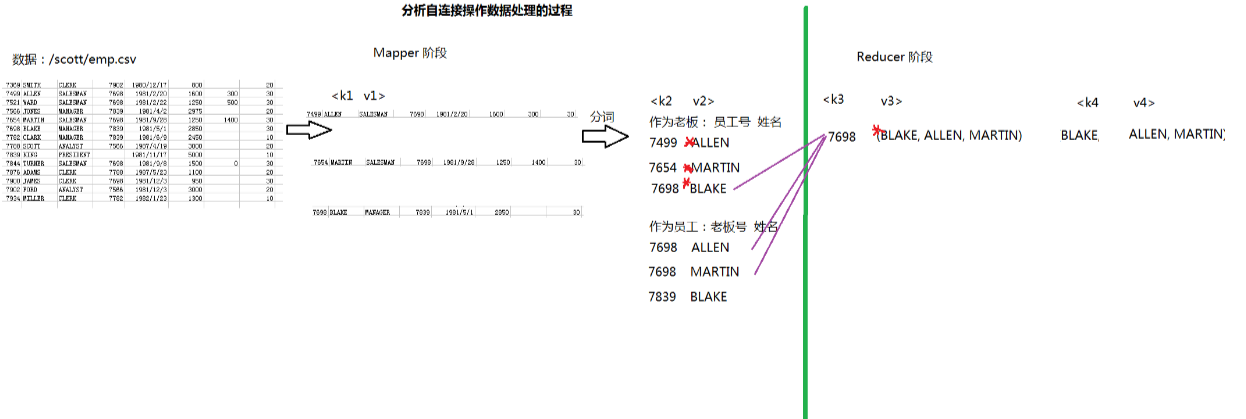
实现:
SelfJoinMapper.java
package demo.selfJoin; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper; public class SelfJoinMapper extends Mapper<LongWritable, Text, LongWritable, Text> { @Override
protected void map(LongWritable key1, Text value1, Context context)
throws IOException, InterruptedException {
//7698,BLAKE,MANAGER,7839,1981/5/1,2850,30
String data = value1.toString(); //分词
String[] words = data.split(","); //输出
//1.作为老板表
context.write(new LongWritable(Long.parseLong(words[0])), new Text("*"+words[1])); //2.作为员工表
try{
context.write(new LongWritable(Long.parseLong(words[3])), new Text(words[1]));
}catch(Exception e){
//老板号为空值
context.write(new LongWritable(-1), new Text(words[1]));
}
} }
SelfJoinReducer.java
package demo.selfJoin; import java.io.IOException; import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer; public class SelfJoinReducer extends Reducer<LongWritable, Text, Text, Text> { @Override
protected void reduce(LongWritable k3, Iterable<Text> v3, Context context)
throws IOException, InterruptedException {
//定义变量:保存老板姓名 员工姓名
String bossName = "";
String empNameList = ""; for (Text text : v3) {
String string = text.toString();
//判断是否存在*号
//*号的作用为了区分是哪张表
int index = string.indexOf("*");
if (index >= 0) {
//老板姓名 去掉*号
bossName = string.substring(1);
}else {
//员工姓名
empNameList = string + ";" + empNameList;
}
} //输出
//如果存在老板和员工 才输出
if (bossName.length() > 0 && empNameList.length() > 0) {
context.write(new Text(bossName), new Text(empNameList));
}
} }
SelfJoinMain.java
package demo.selfJoin; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import demo.multiTable.MultiTableQueryMain;
import demo.multiTable.MultiTableQueryMapper;
import demo.multiTable.MultiTableQueryReducer; public class SelfJoinMain { public static void main(String[] args) throws Exception { Job job = Job.getInstance(new Configuration()); job.setJarByClass(SelfJoinMain.class); job.setMapperClass(SelfJoinMapper.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class); job.setReducerClass(SelfJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class); FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1])); job.waitForCompletion(true); } }
结果:
大数据笔记(十)——Shuffle与MapReduce编程案例(A)的更多相关文章
- 大数据笔记(九)——Mapreduce的高级特性(B)
二.排序 对象排序 员工数据 Employee.java ----> 作为key2输出 需求:按照部门和薪水升序排列 Employee.java package mr.object; impo ...
- 大数据笔记(八)——Mapreduce的高级特性(A)
一.序列化 类似于Java的序列化:将对象——>文件 如果一个类实现了Serializable接口,这个类的对象就可以输出为文件 同理,如果一个类实现了的Hadoop的序列化机制(接口:Writ ...
- 大数据笔记(七)——Mapreduce程序的开发
一.分析Mapreduce程序开发的流程 1.图示过程 输入:HDFS文件 /input/data.txt Mapper阶段: K1:数据偏移量(以单词记)V1:行数据 K2:单词 V2:记一次数 ...
- 大数据学习(4)MapReduce编程Helloworld:WordCount
Maven依赖: <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools< ...
- 《Data-Intensive Text Processing with mapReduce》读书笔记之二:mapreduce编程、框架及运行
搜狐视频的屌丝男士第二季大结局了,惊现波多野老师,怀揣着无比鸡冻的心情啊,可惜随着剧情的推进发展,并没有出现期待中的屌丝奇遇,大鹏还是没敢冲破尺度的界线.想百度些种子吧,又不想让电脑留下污点证据,要知 ...
- 跟上节奏 大数据时代十大必备IT技能
跟上节奏 大数据时代十大必备IT技能 新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT ...
- 大数据技术之Hadoop(MapReduce)
第1章 MapReduce概述 1.1 MapReduce定义 1.2 MapReduce优缺点 1.2.1 优点 1.2.2 缺点 1.3 MapReduce核心思想 MapReduce核心编程思想 ...
- 跟上节奏 大数据时代十大必备IT技能(转)
新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT发展趋势,使得IT人必须了解甚至掌握最 ...
- 大数据笔记01:大数据之Hadoop简介
1. 背景 随着大数据时代来临,人们发现数据越来越多.但是如何对大数据进行存储与分析呢? 单机PC存储和分析数据存在很多瓶颈,包括存储容量.读写速率.计算效率等等,这些单机PC无法满足要求. 2. ...
随机推荐
- 手写一个IOC容器
链接:https://pan.baidu.com/s/1MhKJYamBY1ejjjhz3BKoWQ 提取码:e8on 明白什么是IOC容器: IOC(Inversion of Control,控制反 ...
- [DS+Algo] 003 一维表结构 Python 代码实现
接上一篇 前言 本篇共 3 个代码实现 严格来说 code1 相当于模仿了 Python 的 list 的部分简单功能 code2 与 code3 简单实现了"循环单链表"与&qu ...
- tensorflow学习笔记一----------tensorflow安装
2016年11月30日,tensorflow(https://www.tensorflow.org/)更新了0.12版本,这标志着我们终于可以在windows下使用tensorflow了(但是还是推荐 ...
- CSS 属性小记
1. 选择器的介绍 普通选择器 标签选择器:p{...} id选择器:#xiaoming{...} 类选择器:.class{...} 通用选择器: *{...}, 对所有的元素都有效 伪类选择器 Lo ...
- 开发jquery插件小结
用jquery开发插件其实很简单.今天实现了一个入门级别的功能. 随便来个DIV,便于理解. div{ height:100px;width:100px;display:block;backgroun ...
- 执行npm publish 报错:403 Forbidden - PUT https://registry.npmjs.org/kunmomotest - you must verify your email before publishing a new package: https://www.npmjs.com/email-edit
前言 执行npm publish 报错:403 Forbidden - PUT https://registry.npmjs.org/kunmomotest - you must verify you ...
- Linux系统安装使用实录--传送门(持续更新)
1.安装Linux系统 经过两种系统对比,发现ubuntu的资源依赖更方便更全, centos安装时可以配置开发环境,默认有安装的jdk,这一点比Ubuntu方便一点. win10+centos ...
- PAT Advanced 1046 Shortest Distance (20 分) (知识点:贪心算法)
The task is really simple: given N exits on a highway which forms a simple cycle, you are supposed t ...
- Html5+ 开发APP 后台运行代码
function backRunning(){ if(plus.os.name == 'Android'){ var main = plus.android.runtimeMainActivity() ...
- apply_nodes_func
import torch as th import dgl g=dgl.DGLGraph() g.add_nodes(3) g.ndata["x"]=th.ones(3,4) #n ...