Python--模块之sys模块、logging模块、序列化json模块、序列化pickle模块
sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit()
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
示例:
import sys
count =
while count <:
print(count)
if count == :
sys.exit()
count += print('ending')
结果:
1
2
3
4
5
6
7
8
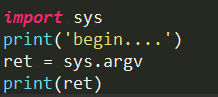

import sys
print(sys.path)
结果:
['C:\\Users\\Administrator\\PycharmProjects\\untitled', 'C:\\Users\\Administrator\\PycharmProjects\\untitled4', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\python36.zip', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\DLLs', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\lib', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36', 'C:\\Users\\Administrator\\AppData\\Local\\Programs\\Python\\Python36\\lib\\site-packages']
logging模块
函数式简单配置
import logging
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
灵活配置日志级别,日志格式,输出位置:
import logging
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(name)s %(levelname)s %(message)s')
logging.debug('debug message')
logging.info('info message')
logging.warning('warning message')
logging.error('error message')
logging.critical('critical message')
结果:
-- ::, root DEBUG debug message
-- ::, root INFO info message
-- ::, root WARNING warning message
-- ::, root ERROR error message
-- ::, root CRITICAL critical message
配置参数:
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有: filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件 format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(message)s用户输出的消息
logger对象配置
import logging
def get_logger():
logger_obj=logging.getLogger()
print(type(logger_obj)) #<class 'logging.RootLogger'>
#创建一个handler,用于写入日志文件
fh=logging.FileHandler('logger_file.txt')
fh.setLevel(logging.ERROR) #再创建一个handler,用于输出到控制台
ch=logging.StreamHandler()
ch.setLevel(logging.CRITICAL) formatter=logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') fh.setFormatter(formatter)
ch.setFormatter(formatter) #logger对象可以添加多个fh和ch对象
logger_obj.addHandler(fh)
logger_obj.addHandler(ch) return logger_obj logger_obj=get_logger() logger_obj.info('info')
logger_obj.debug('debug')
logger_obj.warning('warning')
logger_obj.error('error')
logger_obj.critical('critical')
结果:
<class 'logging.RootLogger'>
-- ::, - root - CRITICAL - critical
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别。
序列化模块
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json模块
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象一个子集,JSON和Python内置的数据类型对应如下:
json类型 Python类型
{} dict
[] list
"string" str
1234.56 int或float
true/false True/False
null None
栗子:
import json
i=
s='hello'
t=(,,)
l=[,,]
d={'name':'yuanhao'} json_str1=json.dumps(i)
json_str2=json.dumps(s)
json_str3=json.dumps(t)
json_str4=json.dumps(l)
json_str5=json.dumps(d) print(json_str1,type(json_str1)) # <class 'str'>
print(json_str2,type(json_str2)) #"hello" <class 'str'>
print(json_str3,type(json_str3)) #[, , ] <class 'str'>
print(json_str4,type(json_str4)) #[, , ] <class 'str'>
print(json_str5,type(json_str5)) #{"name": "yuanhao"} <class 'str'>
python在文本中的使用:
# 序列化
import json dic={'name':'egon','age':,'sex':"male"}
print(type(dic)) #<class 'dict'> data=json.dumps(dic)
print('type',type(data)) #type <class 'str'>
print('data',data) #data {"name": "egon", "age": , "sex": "male"} f=open(r'C:\Users\Administrator\PycharmProjects\untitled3\623周末大作业\作业2\序列化对象','w')
f.write(data)
f.close() #反序列化
import json
f=open(r'C:\Users\Administrator\PycharmProjects\untitled3\623周末大作业\作业2\序列化对象','r')
new_data=json.loads(f.read())
print(new_data,type(new_data))
pickle模块
##----------------------------序列化
import pickle dic={'name':'alvin','age':,'sex':'male'} print(type(dic))#<class 'dict'> j=pickle.dumps(dic)
print(type(j))#<class 'bytes'> f=open('序列化对象_pickle','wb')#注意是w是写入str,wb是写入bytes,j是'bytes'
f.write(j) #-------------------等价于pickle.dump(dic,f) f.close()
#-------------------------反序列化
import pickle
f=open('序列化对象_pickle','rb') data=pickle.loads(f.read())# 等价于data=pickle.load(f)
print(data)
print(data['age'])
运行结果: <class 'dict'>
<class 'bytes'>
{'name': 'alvin', 'age': 23, 'sex': 'male'}
23
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve
f=shelve.open(r'shelve.txt')
f['stu1_info']={'name':'alex','age':''}
f['stu2_info']={'name':'alvin','age':''}
f['school_info']={'website':'oldboyedu.com','city':'beijing'}
#
# f.close()
print(f.get('stu1_info')['age'])
print(f.get('stu2_info')['name'])
print(f.get('school_info')['website'])
运行结果:
alvin
oldboyedu.com
Python--模块之sys模块、logging模块、序列化json模块、序列化pickle模块的更多相关文章
- Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式
Python第十四天 序列化 pickle模块 cPickle模块 JSON模块 API的两种格式 目录 Pycharm使用技巧(转载) Python第一天 安装 shell 文件 Py ...
- python pickle模块的使用/将python数据对象序列化保存到文件中
# Python 使用pickle/cPickle模块进行数据的序列化 """Python序列化的概念很简单.内存里面有一个数据结构, 你希望将它保存下来,重用,或者发送 ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- 【python标准库模块四】Json模块和Pickle模块学习
Json模块 原来有个eval函数能能够从字符串中提取出对应的数据类型,比如"{"name":"zhangsan"}",可以提取出一个字典. ...
- python之pickle模块
1 概念 pickle是python语言的标准模块,安装python后以包含pickle库,不需要再单独安装. pickle提供了一种简单的持久化功能,可以将对象以文件的形式存放在磁盘上. pickl ...
- python数据持久存储-pickle模块
pickle模块实现了基本的数据序列和反序列化.pickle模块的序列化操作我们能够将程序中运行的对象信息保存到文件中去,通过pickle模块的反序列化操作,能够从文件中创建上一次程序保存的对象. 接 ...
- 第十章、json和pickle模块
目录 第十章.json和pickle模块 一.序列化 二.json 三.pickle模块 第十章.json和pickle模块 一.序列化 把对象(变量)从内存中变成可存储或传输的过程称之为序列化, 序 ...
- Python基础(12)_python模块之sys模块、logging模块、序列化json模块、pickle模块、shelve模块
5.sys模块 sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 ...
- python---基础知识回顾(四)(模块sys,os,random,hashlib,re,序列化json和pickle,xml,shutil,configparser,logging,datetime和time,其他)
前提:dir,__all__,help,__doc__,__file__ dir:可以用来查看模块中的所有特性(函数,类,变量等) >>> import copy >>& ...
- python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess logging re正则
python 常用模块 time random os模块 sys模块 json & pickle shelve模块 xml模块 configparser hashlib subprocess ...
随机推荐
- boost variant
Boost Variant resembles union. You can store values of different types in a boost::variant. 1. #incl ...
- php fmod()函数 语法
php fmod()函数 语法 作用:fmod()函数的作用是两个数值做除法运算后的余数 语法:fmod(X,Y).大理石平台哪家好 参数: 参数 描述 X 必须,X为除数 Y 必须,被除数,如果Y为 ...
- Python构造器及析构器:__init__与__new__及__del__
__init__与__new__这两个魔法方法组成了Python类对象的构造器,在Python类实例化时,其实最先调用的不是__init__而是__new__.__new__是负责实例化对象的,而__ ...
- PHP之namespace小结
命名空间的使用 在声明命名空间之前唯一合法的代码是用于定义源文件编码方式的 declare 语句.所有非 PHP 代码包括空白符都不能出现在命名空间的声明之前. PHP 命名空间中的类名可以通过三种方 ...
- 20175120彭宇辰 《Java程序设计》第十一周学习总结
教材内容总结 第十三章 Java网络编程 一.URL类 一个URL对象包含的三个基本信息:协议.地址和资源. -协议:必须是URL对象所在的Java虚拟机支持的协议,常用的有:Http.Ftp.Fil ...
- Codeforces Round #506 (Div. 3) E
Codeforces Round #506 (Div. 3) E dfs+贪心 #include<bits/stdc++.h> using namespace std; typedef l ...
- About Intel® Processor Numbers
http://www.intel.com/content/www/us/en/processors/processor-numbers.html About Intel® Processor Numb ...
- APP运营怎么利用留存率等数据分析用户减少的原因?
APP运营怎么利用留存率等数据分析用户减少的原因? 数据分析最核心的方法是作比较,因为绝对的数值在大多数场合下是没有意义的,通过在不同维度之间做数据的比较分析,能帮助开发者找到数据变化的原因.举一个典 ...
- electron测试TCP通信
这几天学习了一下Elctron,对于这个应用有了一点简单的认识,将这个过程记录一下. 首先,electron会加载main.js,在这里将整个程序启动,相当于其他程序的main函数了. 我是基于ele ...
- ctDNA的分析理论上也可以为多样性的肿瘤
导语 肺腺癌(LUAD)和肺鳞癌(LUSC)是最常见的非小细胞肺癌类型.循环肿瘤DNA(ctDNA)是由凋亡或坏死的肿瘤细胞释放并在血液中循环的小片段DNA.与常规肿瘤活检相比,ctDNA检测具有一定 ...