协程和异步io
一. 并发、并行、同步、异步、阻塞、非阻塞
1.并发:是指一个时间段中有几个程序都处于已启动运行到运行完毕之间,且这几个程序都是在同一个处理机(CPU)上运行,但任一个时刻点上只有一个程序在处理机上运行。
2.并行:是指任何时间点,有多个程序运行在多个CPU上(最多和CPU数量一致)。
3.并发和并行的区别:
并发和并行是即相似又有区别的两个概念,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。在多道程序环境下,并发性是指在一段时间内宏观上有多个程序在同时运行,但在单处理机系统中,每一时刻却仅能有一道程序执行,故微观上这些程序只能是分时地交替执行。倘若在计算机系统中有多个处理机,则这些可以并发执行的程序便可被分配到多个处理机上,实现并行执行,即利用每个处理机来处理一个可并发执行的程序,这样,多个程序便可以同时执行。
4.同步:是指代码调用IO操作时,必须等待IO操作完成才能返回的调用方式。
5.异步:是指代码调用IO操作时,不必等待IO操作完成就能返回的调用方式。
6.阻塞:是指调用函数的时候当前线程被挂起。
7.非阻塞:是指调用函数的时候当前线程不会被挂起,而是立即返回。
二. C10K问题和io多路复用(select、poll、epoll)
1.C10K问题:
谓c10k问题,指的是服务器同时支持成千上万个客户端的问题,也就是concurrent 10 000 connection(这也是c10k这个名字的由来)。由于硬件成本的大幅度降低和硬件技术的进步,如果一台服务器同时能够服务更多的客户端,那么也就意味着服务每一个客户端的成本大幅度降低,从这个角度来看,问题显得非常有意义。
2.五种I/O模型(详情:https://www.cnblogs.com/findumars/p/6361627.html):

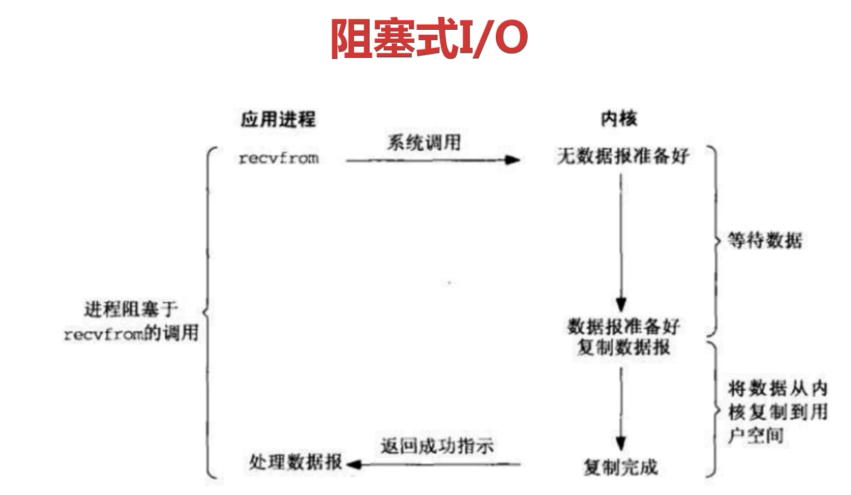
5.1阻塞I式/O:系统调用不会立即返回结果,当前线程会阻塞,等到获得结果或报错时在返回(问题:如在调用send()的同时,线程将被阻塞,在此期间,线程将无法执行任何运算或响应任何的网络请求。)

5.2非阻塞式I/O:调用后立即返回结果(问题:不一定三次握手成功,recv() 会被循环调用,循环调用recv()将大幅度推高CPU 占用率),做计算任务或者再次发起其他连接就较有优势


5.3I/O复用:它的基本原理就是select/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。(阻塞式的方法,可以监听多个socket状态)(问题:将数据从内核复制到用户空间的时间不能省)

5.4信号驱动式I/O:运用较少

5.5异步I/O:它就像是用户进程将整个IO操作交给了他人(kernel)完成,然后他人做完后发信号通知。在此期间,用户进程不需要去检查IO操作的状态,也不需要主动的去拷贝数据。
3.解决方法(参照:https://blog.csdn.net/wangtaomtk/article/details/51811011):
3.1每个线程/进程处理一个连接:
但是由于申请进程/线程会占用相当可观的系统资源,同时对于多进程/线程的管理会对系统造成压力,因此这种方案不具备良好的可扩展性。因此,这一思路在服务器资源还没有富裕到足够程度的时候,是不可行的;即便资源足够富裕,效率也不够高。
问题:资源占用过多,可扩展性差。
3.2每个进程/线程同时处理多个连接(IO多路复用):
3.2.1传统思路
最简单的方法是循环挨个处理各个连接,每个连接对应一个 socket,当所有 socket 都有数据的时候,这种方法是可行的。但是当应用读取某个 socket 的文件数据不 ready 的时候,整个应用会阻塞在这里等待该文件句柄,即使别的文件句柄 ready,也无法往下处理。
思路:直接循环处理多个连接。问题:任一文件句柄的不成功会阻塞住整个应用。
3.2.2select:

思路:有连接请求抵达了再检查处理。
问题:句柄上限+重复初始化+逐个排查所有文件句柄状态效率不高。
3.2.3poll

思路:设计新的数据结构提供使用效率。
问题:逐个排查所有文件句柄状态效率不高。
3.2.4epoll(nginx使用的是epoll)

思路:只返回状态变化的文件句柄。
问题:依赖特定平台(Linux)。
注:epoll不一定比select好(在高并发的情况下,连接活跃度不是很高,epoll比select好;在并发性不高,同时连接很活跃select比epoll好(游戏))
三. epoll+回调+事件循环方式url
1. 通过非阻塞I/O实现http请求:
import socket
from urllib.parse import urlparse def get_url(url):
#通过socket请求html
url=urlparse(url)
host=url.netloc
path=url.path
if path=="":
path="/"
#建立socket连接
client=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
#设置成非阻塞(抛异常:BlockingIOError: [WinError 10035] 无法立即完成一个非阻止性套接字操作。)
client.setblocking(False)
try:
client.connect((host,80))
except BlockingIOError as e:
pass
#向服务器发送数据(还未连接会抛异常)
while True:
try:
client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(path, host).encode("utf8"))
break
except OSError as e:
pass
#将数据读取完
data=b""
while True:
try:
d=client.recv(1024)
except BlockingIOError as e:
continue
if d:
data+=d
else:
break
#会将header信息作为返回字符串
data=data.decode('utf8')
print(data.split('\r\n\r\n')[1])
client.close() if __name__=='__main__':
get_url('http://www.baidu.com')
2.使用select完成http请求(循环回调):
优点:并发性高(驱动整个程序主要是回调循环loop(),不会等待,请求操作系统有什么准备好了,准备好了就执行【没有线程切换等,只有一个线程,当一个url连接建立完成后就会注册,然后回调执行】,省去了线程切换和内存)
#自动根据环境选择poll和epoll
from selectors import DefaultSelector,EVENT_READ,EVENT_WRITE
selector=DefaultSelector()
urls=[]
#全局变量
stop=False
class Fetcher:
def connected(self, key):
#取消注册
selector.unregister(key.fd)
self.client.send("GET {} HTTP/1.1\r\nHost:{}\r\nConnection:close\r\n\r\n".format(self.path, self.host).encode("utf8"))
selector.register(self.client.fileno(),EVENT_READ,self.readable) def readable(self,key):
d = self.client.recv(1024)
if d:
self.data += d
else:
selector.unregister(key.fd)
# 会将header信息作为返回字符串
data = self.data.decode('utf8')
print(data.split('\r\n\r\n')[1])
self.client.close()
urls.remove(self.spider_url)
if not urls:
global stop
stop=True def get_url(self,url):
self.spider_url = url
url = urlparse(url)
self.host = url.netloc
self.path = url.path
self.data = b""
if self.path == "":
self.path = "/"
# 建立socket连接
self.client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
self.client.setblocking(False)
try:
self.client.connect((self.host, 80))
except BlockingIOError as e:
pass #注册写事件,及回调函数
selector.register(self.client.fileno(),EVENT_WRITE,self.connected) def loop():
#回调+事件循环+select(poll/epoll)
#事件循环,不停的调用socket的状态并调用对应的回调函数
#判断哪个可读可写,select本身不支持register模式
#socket状态变化后的回调使用程序员完成的
if not stop:
while True:
ready=selector.select()
for key,mask in ready:
call_back=key.data
call_back(key) if __name__=='__main__':
fetcher=Fetcher()
fetcher.get_url('http://www.baidu.com')
loop()
四. 回调之痛
1.可读性差;2.共享状态管理困难;3.异常处理困难

协程能解决
五. C10M问题和协程
1.C10M问题:
如何利用8核心CPU,64G内存,在10gps的网络上保持1000万的并发连接。
2.协程:
2.1问题:回调模式编码复杂度高;同步编程的并发性不高;多线程需要线程间同步,look会降低性能
2.2解决:
采用同步的方式去编写异步的代码;
采用单线程去解决任务:线程是由操作系统切换,单线程切换意味着需要我们自己去调度任务;不在需要锁,并发性高,如果单线程内切换函数,性能远高于线程切换,并发性更高。
2.3协程:
传统函数调用 过程 A->B->C;
我们需要一个可以暂停的函数,并且可以在适当的时候恢复该函数的继续执行;
出现了协程 -> 有多个入口的函数, 可以暂停的函数, 可以暂停的函数(可以向暂停的地方传入值);
def get_url(url):
#do someting 1
html = get_html(url) #此处暂停,切换到另一个函数去执行
# #parse html
urls = parse_url(html) def get_url(url):
#do someting 1
html = get_html(url) #此处暂停,切换到另一个函数去执行
# #parse html
urls = parse_url(html)
六. 生成器的send和yield from
1.生成器send和next方法:
启动生成器方式有两种:1.next();2.send();
生成器可以产出值;也可以接收值(调用方传递进来的值);
send方法可以传递值进入生成器内部,同时还可以重启生成器执行到下一个yield的位置(注:在调用send()发送非none之前,我们必须启动一次生成器,否则会抛错,方式有两种gen.send(None)或者next(gen))
2.close()方法:(关闭生成器)
自己处理的话会抛异常,gen.close(),RuntimeError: generator ignored GeneratorExit,如果是except Exception就不会抛异常,GeneratorExit是继承至BaseException的,Exception也是继承于BaseException的
def gen_func():
#自己处理的话会抛异常,gen.close(),RuntimeError: generator ignored GeneratorExit
try:
yield 'https://www.baidu.com'
#如果是except Exception就不会抛异常,GeneratorExit是继承至BaseException的,Exception也是继承于BaseException的
except GeneratorExit as e:
pass
yield 1
yield 2
return 'LYQ' if __name__=='__main__':
#抛异常StopIteration:
gen=gen_func()
print(next(gen))
gen.close()
print(next(gen))
3.throw()方法:向生成器中扔异常,需要自己处理,否则会抛错
def gen_func():
try:
yield 'https://www.baidu.com'
except Exception:
pass
yield 1
yield 2
return 'LYQ' if __name__=='__main__':
#抛异常StopIteration:
gen=gen_func()
print(next(gen))
#扔一个异常,是第一句的异常
gen.throw(Exception,'download error')
print(next(gen))
#扔一个异常,是第二句的异常
gen.throw(Exception,'download error')
print(next(gen))
4.yield from:(Python 3.3新加的语法)
4.1简介:
from itertools import chain
my_list=[1,2,3]
my_dict={'name1':'LYQ1',
'name2':'LYQ2'}
#将所有值遍历输出
# for value in chain(my_list,my_dict,range(5,10)):
# print(value) def g1(iterable):
yield range(10)
#yield from iterable
def my_chain(*args,**kwargs):
for my_iterable in args:
#功能非常多
yield from my_iterable
# for value in my_iterable:
# yield value
for value in my_chain(my_list,my_dict,range(5,10)):
print(value)
4.2main调用方 g1:委托生成器 gen:子生成器:
def g1(gen):
yield from gen
gen=range(10)
def main():
g=g1(gen)
#直接发送给子生成器
print(g.send(None))
#main:调用方 g1:委托生成器 gen:子生成器
#yield from会在调用方与子生成器之间建立一个双向通道
main()
4.3例子:
final_result = {}
def sales_sum(pro_name):
total = 0
nums = []
while True:
x = yield
print(pro_name + "销量: ", x)
if not x:
break
total += x
nums.append(x)
#直接返回到yield from sales_sum(key)
return total, nums
def middle(key):
while True:
final_result[key] = yield from sales_sum(key)
print(key + "销量统计完成!!.")
def main():
data_sets = {
"面膜": [1200, 1500, 3000],
"手机": [28, 55, 98, 108],
"大衣": [280, 560, 778, 70],
}
for key, data_set in data_sets.items():
print("start key:", key)
m = middle(key)
#直接send到子生成器里面(x = yield)
m.send(None) # 预激middle协程
for value in data_set:
m.send(value) # 给协程传递每一组的值
m.send(None)
print("final_result:", final_result)
if __name__ == '__main__':
main()
无yield from:
def sales_sum(pro_name):
total = 0
nums = []
while True:
x = yield
print(pro_name + "销量: ", x)
if not x:
break
total += x
nums.append(x)
#直接返回到yield from sales_sum(key)
return total, nums if __name__ == "__main__":
#直接与子生成器通信(没用yield from就需要捕获异常)
my_gen = sales_sum("手机")
my_gen.send(None)
my_gen.send(1200)
my_gen.send(1500)
my_gen.send(3000)
try:
my_gen.send(None)
#获取返回值
except StopIteration as e:
result = e.value
print(result)
4.4介绍yield from详情:
#pep380 #1. RESULT = yield from EXPR可以简化成下面这样
#一些说明
"""
_i:子生成器,同时也是一个迭代器
_y:子生成器生产的值
_r:yield from 表达式最终的值
_s:调用方通过send()发送的值
_e:异常对象 """ _i = iter(EXPR) # EXPR是一个可迭代对象,_i其实是子生成器;
try:
_y = next(_i) # 预激子生成器,把产出的第一个值存在_y中;
except StopIteration as _e:
_r = _e.value # 如果抛出了`StopIteration`异常,那么就将异常对象的`value`属性保存到_r,这是最简单的情况的返回值;
else:
while 1: # 尝试执行这个循环,委托生成器会阻塞;
_s = yield _y # 生产子生成器的值,等待调用方`send()`值,发送过来的值将保存在_s中;
try:
_y = _i.send(_s) # 转发_s,并且尝试向下执行;
except StopIteration as _e:
_r = _e.value # 如果子生成器抛出异常,那么就获取异常对象的`value`属性存到_r,退出循环,恢复委托生成器的运行;
break
RESULT = _r # _r就是整个yield from表达式返回的值。 """
1. 子生成器可能只是一个迭代器,并不是一个作为协程的生成器,所以它不支持.throw()和.close()方法;
2. 如果子生成器支持.throw()和.close()方法,但是在子生成器内部,这两个方法都会抛出异常;
3. 调用方让子生成器自己抛出异常
4. 当调用方使用next()或者.send(None)时,都要在子生成器上调用next()函数,当调用方使用.send()发送非 None 值时,才调用子生成器的.send()方法;
"""
_i = iter(EXPR)
try:
_y = next(_i)
except StopIteration as _e:
_r = _e.value
else:
while 1:
try:
_s = yield _y
except GeneratorExit as _e:
try:
_m = _i.close
except AttributeError:
pass
else:
_m()
raise _e
except BaseException as _e:
_x = sys.exc_info()
try:
_m = _i.throw
except AttributeError:
raise _e
else:
try:
_y = _m(*_x)
except StopIteration as _e:
_r = _e.value
break
else:
try:
if _s is None:
_y = next(_i)
else:
_y = _i.send(_s)
except StopIteration as _e:
_r = _e.value
break
RESULT = _r
看完代码,我们总结一下关键点:
1. 子生成器生产的值,都是直接传给调用方的;调用方通过.send()发送的值都是直接传递给子生成器的;如果发送的是 None,会调用子生成器的__next__()方法,如果不是 None,会调用子生成器的.send()方法;
2. 子生成器退出的时候,最后的return EXPR,会触发一个StopIteration(EXPR)异常;
3. yield from表达式的值,是子生成器终止时,传递给StopIteration异常的第一个参数;
4. 如果调用的时候出现StopIteration异常,委托生成器会恢复运行,同时其他的异常会向上 "冒泡";
5. 传入委托生成器的异常里,除了GeneratorExit之外,其他的所有异常全部传递给子生成器的.throw()方法;如果调用.throw()的时候出现了StopIteration异常,那么就恢复委托生成器的运行,其他的异常全部向上 "冒泡";
6. 如果在委托生成器上调用.close()或传入GeneratorExit异常,会调用子生成器的.close()方法,没有的话就不调用。如果在调用.close()的时候抛出了异常,那么就向上 "冒泡",否则的话委托生成器会抛出GeneratorExit异常。
七. 生成器如何变成协程?
1.生成器可以暂停并获取状态:
#生成器是可以暂停的函数
import inspect
def gen():
yield 1
return True if __name__=='__main__':
g1=gen()
#获取生成器状态 GEN_CREATED(创建)
print(inspect.getgeneratorstate(g1))
next(g1)
#GEN_SUSPENDED暂停
print(inspect.getgeneratorstate(g1))
try:
next(g1)
except StopIteration:
pass
#GEN_CLOSED关闭
print(inspect.getgeneratorstate(g1))
2.协程的调度依然是 事件循环+协程模式 ,协程是单线程模式:
#生成器是可以暂停的函数
import inspect
# def gen_func():
# value=yield from
# #第一返回值给调用方, 第二调用方通过send方式返回值给gen
# return "bobby"
#1. 用同步的方式编写异步的代码, 在适当的时候暂停函数并在适当的时候启动函数
import socket
def get_socket_data():
yield 1 def downloader(url):
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
client.setblocking(False) try:
client.connect((host, 80)) # 阻塞不会消耗cpu
except BlockingIOError as e:
pass selector.register(self.client.fileno(), EVENT_WRITE, self.connected)
#如果get_socket_data()中出现异常,会直接抛给downloader(向上抛)
source = yield from get_socket_data()
data = source.decode("utf8")
html_data = data.split("\r\n\r\n")[1]
print(html_data) def download_html(html):
html = yield from downloader() if __name__ == "__main__":
#协程的调度依然是 事件循环+协程模式 ,协程是单线程模式
pass
八. async和await原生协程
1.python为了将语义变得更加明确,就引入了async和await关键字定义原生的协程:
生成器实现的协程又可以当生成器,又可以当协程,且代码凌乱,不利于后期维护。原生的协程中不可以yield,否则会抛错(让协程更加明确)

可异步调用:实际实现了__await__魔法函数
await:将控制权交出去并等待结果返回,await只能接收awaitable对象,可以理解成yield from
# from collections import Awaitable
#如果是函数,就要使用coroutine装饰器,实际将__await_指向___iter__
# import types
# @types.coroutine
# def downloader(url):
# return "haha" async def downloader(url):
return "haha"
async def download_url(url):
#将控制权交出去并等待结果返回,await只能接收awaitable对象,可以理解成yield from
html=await downloader(url)
return html if __name__=='__main__':
coro=download_url('www.baidu.com')
#原生协程不能调用next
coro.send(None)
协程和异步io的更多相关文章
- 第十一章:Python高级编程-协程和异步IO
第十一章:Python高级编程-协程和异步IO Python3高级核心技术97讲 笔记 目录 第十一章:Python高级编程-协程和异步IO 11.1 并发.并行.同步.异步.阻塞.非阻塞 11.2 ...
- Python-09-线程、进程、协程、异步IO
0. 什么是线程(thread)? 线程,有时被称为轻量级进程(Lightweight Process,LWP),是程序执行流的最小单元.一个标准的线程由线程ID,当前指令指针(PC),寄存器集合和堆 ...
- 协程、异步IO
协程,又称微线程,纤程.英文名Coroutine,协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器 ...
- python 自动化之路 day 10 协程、异步IO、队列、缓存
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 RabbitMQ队列 Redis\Memcached缓存 Paramiko SSH Twsited网络框架 引子 到目 ...
- Python【第十篇】协程、异步IO
大纲 Gevent协程 阻塞IO和非阻塞IO.同步IO和异步IO的区别 事件驱动.IO多路复用(select/poll/epoll) 1.协程 1.1协程的概念 协程,又称微线程,纤程.英文名Coro ...
- Day10 - Python协程、异步IO、redis缓存、rabbitMQ队列
Python之路,Day9 - 异步IO\数据库\队列\缓存 本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitM ...
- Python开发【第九篇】:协程、异步IO
协程 协程,又称微线程,纤程.英文名Coroutine.一句话说明什么是协程,协程是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文和栈保存到其他地方,在切换回 ...
- Python 10 协程,异步IO,Paramiko
本节内容 Gevent协程 异步IO Paramiko 携程 协程,又称为微线程,纤程(coroutine).是一种用户态的轻量级线程. 协程拥有自己的寄存器上下文和栈.协程调度切换时,将寄存器上下文 ...
- Python协程、异步IO
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko SS ...
随机推荐
- Asp.net Web Api开发Help Page配置和扩展
为了方面APP开发人员,服务端的接口都应当提供详尽的API说明.但每次有修改,既要维护代码,又要维护文档,一旦开发进度紧张,很容易导致代码与文档不一致. Web API有一个Help Page插件,可 ...
- 第10章 RDB持久化
Redis是一种内存数据库,掉电即失,为了解决这个问题Redis提供了RDB持久化功能,该功能可以把Redis中的内容以RDB文件的形式存储在硬盘上,并且每次RedisServer启动的时候都会尝试从 ...
- linux上安装完torch后仍报错:ImportError: No module named torch
linux上安装完torch后仍报错: Traceback (most recent call last): File , in <module> import torch ImportE ...
- yaml的简单学习
参考http://www.ruanyifeng.com/blog/2016/07/yaml.html 基本语法规则如下. • 大小写敏感 • 使用缩进表示层级关系 • ...
- 在使用 Spring Boot 和 MyBatis 动态切换数据源时遇到的问题以及解决方法
相关项目地址:https://github.com/helloworlde/SpringBoot-DynamicDataSource 1. org.apache.ibatis.binding.Bind ...
- 《HTTP协议:菜鸟入门系列》
很多测试人员在有了一定的测试经验(一般是1-2年)后,就会陷入瓶颈阶段,想提升,但不知道如何提升,学习又没有比较明确的方向,曾经我也是... 那么,我建议系统的学习一下HTTP协议,好处很多:对接口测 ...
- Luogu P4323 [JSOI2016]独特的树叶
一道比较好的树Hash的题目,提供一种不一样的Hash方法. 首先无根树的同构判断一般的做法只有树Hash,所以不会的同学可以做了Luogu P5043 [模板]树同构([BJOI2015]树的同构) ...
- Java多线程学习(四)---控制线程
控制线程 摘要: Java的线程支持提供了一些便捷的工具方法,通过这些便捷的工具方法可以很好地控制线程的执行 1. join线程控制,让一个线程等待另一个线程完成的方法 2. 后台线程,又称为守护线程 ...
- 【原创】Mysql中select的正确姿势
引言 大家在开发中,还有很多童鞋在写查询语句的时候,习惯写下面这种不规范sql select * from table 而不写成下面的这种规范方式 select col1,col2,...,coln ...
- .NET 框架 Microsoft .NET Framework (更新至.NET Framework4.8)
https://dotnet.microsoft.com/download/dotnet-framework 产品名称 离线安装包 .NET Framework 4.8 点击下载 .NET Frame ...