6.3 OrderBy 优化
1. 创建实例
create table tblA(
age int,
birth TIMESTAMP not null
); insert into tblA(age,birth) values(22,now());
insert into tblA(age,birth) values(23,now());
insert into tblA(age,birth) values(24,now()); create index idx_A_ageBirth no tblA(age,birth); select * from tblA;
2.查询实例
a.
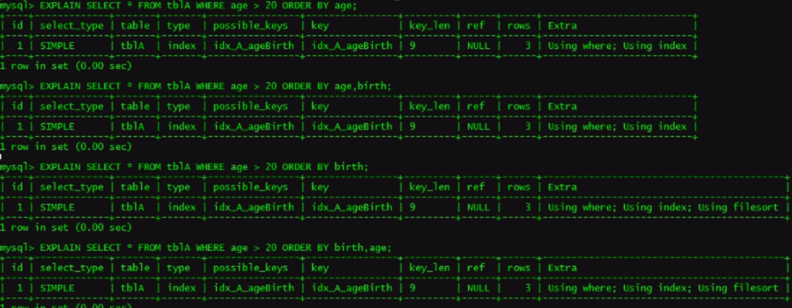
b.
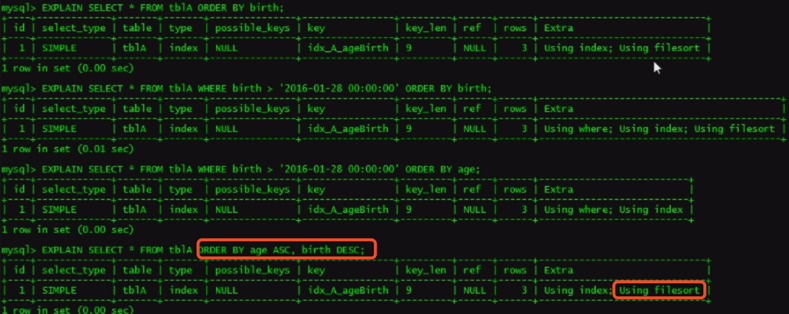
小总结:OrderBy满足两种情况,会使用Index方式排序
order by 语句使用索引最左前列。
使用where子句与Order by 子句条件列组合满足索引最左前列。
3. 如果不在索引列上,filesort有两种算法(双路排序、单路排序)
双路排序:
mysql4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,
读取行指针和orderby列,对他们进行排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读取对应的数据输出。
取一批数据,要对磁盘惊进行两次扫描,众所周知,I/O是很耗时间,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。 单路排序:
从磁盘读取查询需要的所有列,按照orderby列在buffer对他们进行排序,然后扫描排序后的列表进行输出,
它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用等多的空间,因为他的每一行数据都是保存在内存中。 单路排序引发的问题:
在sort_buffer中,单路比双路要多占用很多空间,因为单路是把所有的数据都去出来,所以可能取出的数据总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排……从而多次I/O。
本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
优化策略:
增大sort_buffer_size参数的设置
增大max_length_for_sort_data参数设置 why? 1. Order by时select * 是一个大忌Query需要的字段,这点非常重要。在这里的影响是:
a. 当Query的字段大小总和小于max_length_for_sort_data而且排序字段不是TEXT|BLOB类时,会用改进后的算法——单路排序,否则用老算法——多路排序。
b. 两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size。 2. 尝试提高sort_buffer_size
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。 3.尝试提高max_length_for_sort_data
提高这个参数,会增加用改进算法的概率,但是如果设的太高,数据总容量超出sort_buffer_size的概率就会增大,明显症状就是高的磁盘I/O活动和低的处理器使用率。
小总结:


关注我的公众号,精彩内容不能错过
6.3 OrderBy 优化的更多相关文章
- MySQL高级优化
MySQL高级 1.索引是什么? (1)索引是排好序可以快速查找的数据结构 (2)方便快速查找,索引实际上也是一张表所以也是要占内存的 2.索引存在哪里? (1)InnoDB引擎 ①索引是和数据存放在 ...
- mysql随笔
MySQL查询优化器--非SPJ的优化 MySQL查询优化器--非SPJ优化(一)--GROUPBY优化 http://blog.163.com/li_hx/blog/static/183991413 ...
- MySQL泛泛而谈(3W字)
下面对于MySQL进行相关介绍,文档的内容较为基础,仅仅设计操作,少量原理,大佬请绕道哦. 废话少说,开冲! 一.MySQL架构介绍 1-MySQL简介 概述 MySQL是一个关系型数据库管理系统,由 ...
- hive 的分隔符、orderby sort by distribute by的优化
一.Hive 分号字符 分号是SQL语句结束标记,在HiveQL中也是,可是在HiveQL中,对分号的识别没有那么智慧,比如: select concat(cookie_id,concat(';',' ...
- 记一次mysql关于limit和orderby的优化
针对于大数据量查询,我们一般使用分页查询,查询出对应页的数据即可,这会大大加快查询的效率: 在排序和分页同时进行时,我们一定要注意效率问题,例如: select a.* from table1 a i ...
- 【C#代码实战】群蚁算法理论与实践全攻略——旅行商等路径优化问题的新方法
若干年前读研的时候,学院有一个教授,专门做群蚁算法的,很厉害,偶尔了解了一点点.感觉也是生物智能的一个体现,和遗传算法.神经网络有异曲同工之妙.只不过当时没有实际需求学习,所以没去研究.最近有一个这样 ...
- 深入浅出聊优化:从Draw Calls到GC
前言: 刚开始写这篇文章的时候选了一个很土的题目...<Unity3D优化全解析>.因为这是一篇临时起意才写的文章,而且陈述的都是既有的事实,因而给自己“文(dou)学(bi)”加工留下的 ...
- SQL优化案例—— RowNumber分页
将业务语句翻译成SQL语句不仅是一门技术,还是一门艺术. 下面拿我们程序开发工程师最常用的ROW_NUMBER()分页作为一个典型案例来说明. 先来看看我们最常见的分页的样子: WITH CTE AS ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
随机推荐
- ansible 关闭ssh首次连接时提示
关闭ssh首次连接时提示. 修改/etc/ansible/ansible.cfg配置文件 方法一:(推荐,配置文件中存在) host_key_checking = False 方法二: ssh_arg ...
- 利用Socket 实现多客户端的请求与响应
import java.io.IOException; import java.net.ServerSocket; import java.net.Socket; public class Serve ...
- why microsoft named their cloud service Azure?
best guess I can personally make is that because Azure literally means “bright blue color of the clo ...
- Java基础巩固——排序
快速排序 基本思想: 通过一趟排序将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分关键字小,则分别对两部分继续进行排序,直到整个序列有序. 实例: 1.一趟排序的过程: 2.排序的全 ...
- Java程序员的成长之路
阅读本文大概需要 8.2 分钟. tips:虽然题目是写的Java程序员,但对其他语言的开发来说也会有借鉴作用. 本篇介绍的是大体思路,以及每个节点所需要学习的书籍内容,如果大家对详细的技术点有需要, ...
- 比较empty()与 isset()d的区别
比较empty()与 isset()的区别 注意:empty()在PHP5.5之前只能检测变量 isset()只能检测变量 两者之间的联系:empty($var) 等价于 !isset($var)|| ...
- remote: Incorrect username or password ( access token )
解决问题 进入控制面板 用户账号,选择管理您的凭据 修改凭据 修改完成后,保存即可
- Java核心技术及面试指南 IO部分的面试题归纳以及答案
4.6.1 java中有几种类型的流? Java中的流分为两种,一种是字节流,另一种是字符流,分别由四个抽象类来表示(每种流包括输入和输出两种所以一共四个):InputStream,OutputStr ...
- NiftyNet开源平台的使用 -- 配置文件
NiftyNet开源平台的使用 NiftyNet基础架构是使研究人员能够快速开发和分发用于分割.回归.图像生成和表示学习应用程序,或将平台扩展到新的应用程序的深度学习解决方案. 详细介绍请见: ...
- wap开发中的cookie
安卓和ios的wap开发,安卓中的cookie可以识别中文,但是ios不能识别,需要转码成通用码(UNICODE),解决办法:直接转成16进制码, escape('测试文字') 友情链接:http:/ ...