Flask-SQLAlchemy常用操作
一.SQLAlchemy介绍
SQLAlchemy是一个基于Python实现的ORM框架。该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并获取执行结果。
|
1
|
pip3 install sqlalchemy |

组成部分:
- Engine,框架的引擎
- Connection Pooling ,数据库连接池
- Dialect,选择连接数据库的DB API种类
- Schema/Types,架构和类型
- SQL Exprression Language,SQL表达式语言
SQLAlchemy本身无法操作数据库,其本质上是依赖pymysql.MySQLdb,mssql等第三方插件,Dialect用于和数据API进行交流,根据配置文件的不同调用不同的数据库API,从而实现对数据库的操作,如:
SQLAlchemy用一个字符串表示连接信息:
'数据库类型+数据库驱动名称://用户名:口令@机器地址:端口号/数据库名'
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
MySQL-Python mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname> pymysql mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>] MySQL-Connector mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname> cx_Oracle oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...] 更多:http://docs.sqlalchemy.org/en/latest/dialects/index.html |
底层处理
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# auth : pangguoping
from sqlalchemy import create_engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5) # 执行SQL
# cur = engine.execute(
# "INSERT INTO hosts (host, color_id) VALUES ('1.1.1.22', 3)"
# ) # 新插入行自增ID
# cur.lastrowid # 执行SQL
# cur = engine.execute(
# "INSERT INTO hosts (host, color_id) VALUES(%s, %s)",[('1.1.1.22', 3),('1.1.1.221', 3),]
# ) # 执行SQL
# cur = engine.execute(
# "INSERT INTO hosts (host, color_id) VALUES (%(host)s, %(color_id)s)",
# host='1.1.1.99', color_id=3
# ) # 执行SQL
# cur = engine.execute('select * from hosts')
# 获取第一行数据
# cur.fetchone()
# 获取第n行数据
# cur.fetchmany(3)
# 获取所有数据
# cur.fetchall()
说白了就是使用pymysql的方法一样.
二. 使用
1. 执行原生SQL语句
import time
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/t1?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程时,最多等待的时间,超时报错,默认30秒
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置),-1代表永远不回收,即一直被重用
) def task(arg):
conn = engine.raw_connection() #拿到的是一个原生的pymysql连接对象
cursor = conn.cursor()
cursor.execute(
"select * from t1"
)
result = cursor.fetchall()
cursor.close()
conn.close() for i in range(20):
t = threading.Thread(target=task, args=(i,))
t.start()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=0, pool_size=5) def task(arg):
conn = engine.contextual_connect()
with conn:
cur = conn.execute(
"select * from t1"
)
result = cur.fetchall()
print(result) for i in range(20):
t = threading.Thread(target=task, args=(i,))
t.start()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading
import sqlalchemy
from sqlalchemy import create_engine
from sqlalchemy.engine.base import Engine
from sqlalchemy.engine.result import ResultProxy
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=0, pool_size=5) def task(arg):
cur = engine.execute("select * from t1")
result = cur.fetchall()
cur.close()
print(result) for i in range(20):
t = threading.Thread(target=task, args=(i,))
t.start()
注意: 查看连接,进程cmd,mysql中>输入 show status like 'Threads%';
2. ORM
a. 创建数据库表
创建单表
import datetime
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index Base = declarative_base() # 创建对象的基类: # 定义User对象:
class Users(Base):
# 表的名字:
__tablename__ = 'users' # 表的结构:
id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False,default='xx') # index指定是否是索引,nullable是否能为空
email = Column(String(32), unique=True) # 指定唯一
ctime = Column(DateTime, default=datetime.datetime.now) #注意,此处设置时datetime.datetime.now若加了括号,则时间永远是程序启动时的时间,后面创建数据时,不会变化
extra = Column(Text, nullable=True) __table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), # 联合唯一索引
Index('ix_id_name', 'name', 'email'), #给name和email创建普通索引,索引名为ix_id_name
) def init_db():
"""
根据类创建数据库表
:return:
"""
# 初始化数据库连接:
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.create_all(engine) #找到所有继承了Base的类,按照其结构建表 def drop_db():
"""
根据类删除数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.drop_all(engine) if __name__ == '__main__':
drop_db()
init_db()
默认建的表的引擎是MyISAM,如果要设置成InnoDB(支持事务),该怎么设置呢?
__table_args__ = {
'mysql_engine': 'InnoDB', # 指定表的引擎
'mysql_charset': 'utf8' # 指定表的编码格式
}
FK,M2M关系的创建
from sqlalchemy import create_engine
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime,UniqueConstraint, Index
from sqlalchemy.orm import relationship
Base = declarative_base() # 创建对象的基类: # ##################### 一对多示例 #########################
class Hobby(Base):
__tablename__ = 'hobby'
id = Column(Integer, primary_key=True)
caption = Column(String(50), default='篮球') class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
hobby_id = Column(Integer, ForeignKey("hobby.id")) #建FK关系 # 与生成表结构无关,仅用于查询方便
hobby = relationship("Hobby", backref='pers') #反向关联的名字 # ##################### 多对多示例 #########################
# 这里多对多需要自己建第三张表,并绑定关系
class Server2Group(Base):
__tablename__ = 'server2group'
id = Column(Integer, primary_key=True, autoincrement=True) #autoincrement 设置自增
server_id = Column(Integer, ForeignKey('server.id'))
group_id = Column(Integer, ForeignKey('group.id')) class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False) # 与生成表结构无关,仅用于查询方便
servers = relationship('Server', secondary='server2group', backref='groups') #反向关联的名字 class Server(Base):
__tablename__ = 'server' id = Column(Integer, primary_key=True, autoincrement=True)
hostname = Column(String(64), unique=True, nullable=False) def init_db():
"""
根据类创建数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/userinfo?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.create_all(engine) def drop_db():
"""
根据类删除数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/userinfo?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.drop_all(engine) if __name__ == '__main__':
drop_db()
init_db()
SQLALchemy不同于Django的ORM,当创建多对多关联事,不会自动创建第三张表,需要我们自己定义关系表,进行关联
b. 操作数据库表
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from models import Users engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) #创建Session类 # 每次执行数据库操作时,都需要创建一个session
session = Session() # 创建session对象: # ############# 执行ORM操作 #############
# 创建新User对象
obj1 = Users(name="alex1")
# 添加到session:
session.add(obj1)
# 提交即保存到数据库:
session.commit()
# 关闭session
session.close()
c.通过原生SQL语句执行
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) session = Session() # 查询
# cursor = session.execute('select * from users')
# result = cursor.fetchall() # 添加
cursor = session.execute('insert into users(name) values(:value)',params={"value":'hc'})
# 注意占位符和传参的形式
session.commit()
print(cursor.lastrowid) session.close() 原生SQL语句
d.基本增删改查示例
https://www.keakon.net/2012/12/03/SQLAlchemy使用经验
import time
import threading from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text from db import Users, Hosts engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) session = Session() # ################ 添加 ################ obj1 = Users(name="hc")
session.add(obj1) #添加一个对象 session.add_all([
Users(name="hc"),
Users(name="alex"),
Hosts(name="c1.com"),
]) #添加多个对象
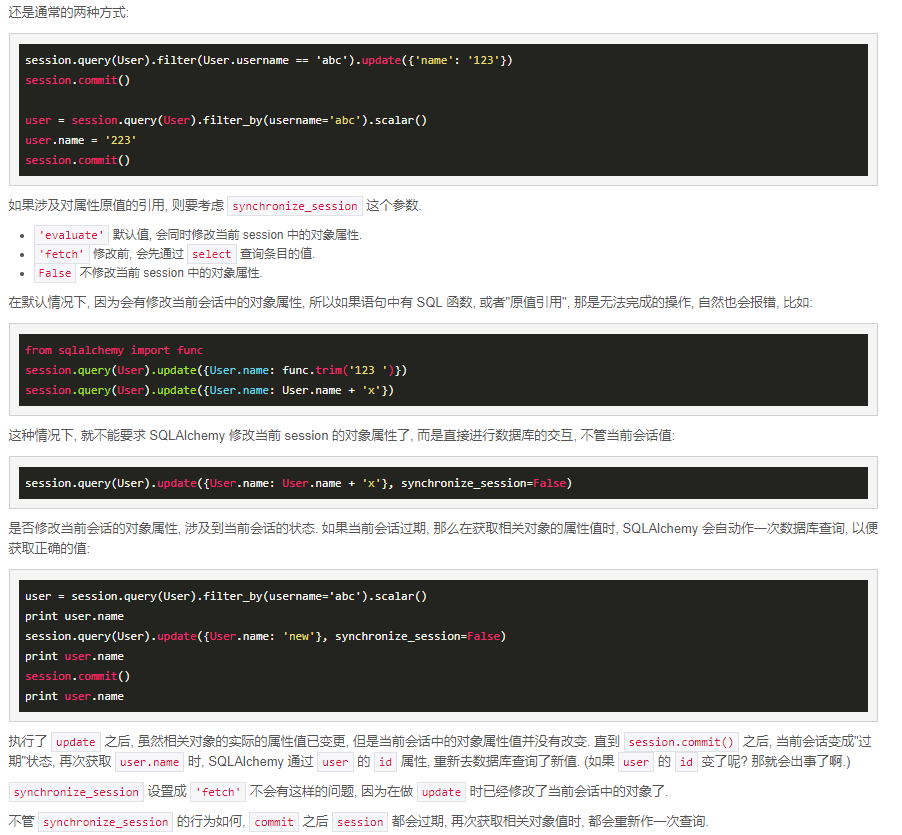
session.commit() # ################ 删除 ################ # filter是where条件,最后调用one()或first()返回唯一行,如果调用all()则返回所有行
session.query(Users).filter(Users.id > 2).delete() #删除Users表中id大于2的数据
session.commit() # ################ 修改 ################ session.query(Users).filter(Users.id > 0).update({"name" : ""}) # 将Users表中id>0的数据,把name字段改为099
# 更新user表中id大于2的name列,在原字符串后边增加099
session.query(Users).filter(Users.id > 0).update({Users.name: Users.name + ""}, synchronize_session=False) #synchronize_session设置为False即执行字符串拼接
# 更新user表中id大于2的num列,使最终值在原来数值基础上加1
session.query(Users).filter(Users.id > 0).update({"age": Users.age + 1}, synchronize_session="evaluate") #synchronize_session设置为evaluate即执行四则运算 session.commit() # ################ 查询 ################ r1 = session.query(Users).all()
r2 = session.query(Users.name.label('xx'), Users.age).all() #label 取别名的,即在查询结果中,显示name的别名'xx'
r3 = session.query(Users).filter(Users.name == "alex").one() # one()返回唯一行,类似于django的get,如果返回数据为多个则报错
r3 = session.query(Users).filter(Users.name == "alex").all() # all()获取所有数据
r4 = session.query(Users).filter_by(name='alex').all() # 注意filter和filter_by后面括号内条件的写法
r5 = session.query(Users).filter_by(name='alex').first() # first()获取返回数据的第一行
r6 = session.query(Users).filter(text("id<:value and name=:name")).params(value=224, name='fred').order_by(Users.id).all()
#order_by后面还可以.desc()降序排列,默认为.asc()升序排列
# text(自定义条件,:的功能类似%s占位),params中进行传参
r7 = session.query(Users).from_statement(text("SELECT * FROM Hosts where name=:name")).params(name='ed').all()
# text中还能从另一个表中查询,前面要用from_statement,而不是filter session.close()
当我们使用in_查询时,如果进行删除会更新,会出现如下错误
InvalidRequestError: Could not evaluate current criteria in Python. Specify 'fetch' or False for the synchronize_session parameter.
解决办法:加上 synchronize_session=False
https://segmentfault.com/q/1010000000130368
e.基于relationship操作ForeignKey
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 添加
"""
session.add_all([
Hobby(caption='乒乓球'),
Hobby(caption='羽毛球'),
Person(name='张三', hobby_id=3),
Person(name='李四', hobby_id=4),
]) person = Person(name='张九', hobby=Hobby(caption='姑娘'))
session.add(person) hb = Hobby(caption='人妖')
hb.pers = [Person(name='文飞'), Person(name='博雅')]
session.add(hb) # 会同时创建3条数据(1条hobby的数据,2条person的数据) session.commit()
""" # 使用relationship正向查询
"""
v = session.query(Person).first()
print(v.name)
print(v.hobby.caption)
""" # 使用relationship反向查询
"""
v = session.query(Hobby).first()
print(v.caption)
print(v.pers)
""" session.close()
f.基于relationship操作m2m
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session()
# 添加
"""
session.add_all([
Server(hostname='c1.com'),
Server(hostname='c2.com'),
Group(name='A组'),
Group(name='B组'),
])
session.commit() s2g = Server2Group(server_id=1, group_id=1)
session.add(s2g)
session.commit() gp = Group(name='C组')
gp.servers = [Server(hostname='c3.com'),Server(hostname='c4.com')]
session.add(gp)
session.commit() ser = Server(hostname='c6.com')
ser.groups = [Group(name='F组'),Group(name='G组')]
session.add(ser)
session.commit()
""" # 使用relationship正向查询
"""
v = session.query(Group).first()
print(v.name)
print(v.servers)
""" # 使用relationship反向查询
"""
v = session.query(Server).first()
print(v.hostname)
print(v.groups)
""" session.close() 基于relationship操作m2m
g.进阶操作
in_、notin_、and、or、like、limit、排序、分组、连表、组合
# 条件
ret = session.query(Users).filter_by(name='alex').all() #
ret = session.query(Users).filter(Users.id > 1, Users.name == 'eric').all() # 且的关系
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'eric').all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all() # ~表示非。就是not in的意思
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all() # 联表查询
from sqlalchemy import and_, or_ # 且和or的关系
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'eric')).all() # 条件以and方式排列
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'eric')).all() # 条件以or方式排列
ret = session.query(Users).filter(
or_( #这部分表示括号中的条件都以or的形式匹配
Users.id < 2, # 或者 or User.id < 2
and_(Users.name == 'eric', Users.id > 3),# 表示括号中这部分进行and匹配
Users.extra != ""
)).all() # 通配符
ret = session.query(Users).filter(Users.name.like('e%')).all()
ret = session.query(Users).filter(~Users.name.like('e%')).all() # 表示not like # 限制 limit用法
ret = session.query(Users)[1:2] # 等于limit ,具体功能需要自己测试 # 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all() # 按照name从大到小排列,如果name相同,按照id从小到大排列 # 分组
from sqlalchemy.sql import func ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all() ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all() # having对聚合的内容再次进行过滤 # 连表 ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all() ret = session.query(Person).join(Favor).all()
# 默认是inner join
ret = session.query(Person).join(Favor, isouter=True).all() # isouter表示是left join # 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all() #union默认会去重 q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all() # union_all不去重
去重
https://segmentfault.com/a/1190000006949536
关联子查询
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from sqlalchemy.sql import text, func
from sqlalchemy.engine.result import ResultProxy
from db import Users, Hosts, Hobby, Person, Group, Server, Server2Group engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6?charset=utf8", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine)
session = Session() # 关联子查询
subqry = session.query(func.count(Server.id).label("sid")).filter(Server.id == Group.id).correlate(Group).as_scalar()
result = session.query(Group.name, subqry)
"""
SELECT `group`.name AS group_name, (SELECT count(server.id) AS sid
FROM server
WHERE server.id = `group`.id) AS anon_1
FROM `group`
""" # 原生SQL
"""
# 查询
cursor = session.execute('select * from users')
result = cursor.fetchall() # 添加
cursor = session.execute('insert into users(name) values(:value)',params={"value":'wupeiqi'})
session.commit()
print(cursor.lastrowid)
""" session.close()
子查询:
session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='eric'))).all()
"""
select * from users where id in (select id from xxx)
""" subqry = session.query(func.count(Server.id).label("sid")).filter(Server.id == Group.id).correlate(Group).as_scalar()
#第一步: session.query(func.count(Server.id).label("sid")).filter(Server.id == Group.id)
#这句的sql语句为 select count(id) as sid from server where server.id = group.id 如果直接运行,则会报错
# 第二步:.correlate(Group).as_scalar() ==> 代表此时不执行查询操作,将其当作条件,在group表中查询时,才执行查询 result = session.query(Group.name, subqry)
# sql语句为:select group.name subqry from group
#第三步:将subqry替换为上面的条件,则此句的SQL为:
# select group.name,(select count(id) as sid from server where server.id = group.id) as xx from group
class User(db.Model):
__tablename__ = "user"
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(100), unique=True, nullable=False)
pwd = db.Column(db.String(100), nullable=False)
role_id = db.Column(db.Integer, default=0)
email = db.Column(db.String(100), nullable=True)
addtime = db.Column(db.DateTime, index=True, default=datetime.now)
is_active = db.Column(db.Boolean, default=True)
uid = db.Column(db.String(24), nullable=False, default=uuid, unique=True, server_default=uuid()) class Userlog(db.Model):
__tablename__ = "userlog"
id = db.Column(db.Integer, primary_key=True)
user_id = db.Column(db.Integer, default=0) db.ForeignKey('user.id')
ip = db.Column(db.String(100))
addtime = db.Column(db.DateTime, index=True, default=datetime.now)
orm语句
subqry = db.session.query(Userlog).order_by(Userlog.id.desc()).subquery()
s = aliased(Userlog,subqry)
rs = db.session.query(User, s.ip.label('last_ip'), s.addtime.label('last_time')).outerjoin(s,
User.id == s.user_id).group_by(
s.user_id)
print rs
对应的sql语句
SELECT user.id AS user_id, user.name AS user_name, user.pwd AS user_pwd, user.role_id AS user_role_id, user.email AS user_email, user.addtime AS user_addtime, user.is_active AS user_is_active, user.uid AS user_uid, anon_1.ip AS last_ip, anon_1.addtime AS last_time
FROM user LEFT OUTER JOIN (SELECT userlog.id AS id, userlog.user_id AS user_id, userlog.ip AS ip, userlog.addtime AS addtime
FROM userlog ORDER BY userlog.id DESC) AS anon_1 ON user.id = anon_1.user_id GROUP BY anon_1.user_id
1.多条件组合,可以用and_,or_实现。最外层时,and_可以省略,默认用逗号分开条件。
db.session.query(User).filter(
and_(
or_(User.name==name1,User.name==name2),
or_(User.status==1,User.status==2)
),
User.active==1
).first()
2.动态组合条件。针对不同的场景,可能需要不同的查询条件,类似动态的拼接SQL 语句。
if filter_type == 1:
search = and_(GameRoom.status ==1,or_(
and_(GameRoom.white_user_id == user_id,
GameRoom.active_player == 1),
and_(GameRoom.black_user_id == user_id,
GameRoom.active_player == 0)))
elif filter_type == 2:
search = and_(GameRoom.status ==1,or_(
and_(GameRoom.white_user_id == user_id,
GameRoom.active_player == 0),
and_(GameRoom.black_user_id == user_id,
GameRoom.active_player == 1)))
elif filter_type == 3:
search = GameRoom.create_by == user_id db.session.query(GameRoom).filter(search).all()
3.关联查询。对应SQL的join和left join等。
session.query(User, Address).filter(User.id == Address.user_id).all()
session.query(User).join(User.addresses).all()
session.query(User).outerjoin(User.addresses).all()
4.使用别名用aliased,aliased在orm包中。当要对同一个表使用多次关联时,可能需要用到别名。同时,如果查询的结果有多个同名的字段,可以使用label重命名。
black_user = orm.aliased(User)
white_user = orm.aliased(User)
db.session.query(
GameRoom,
black_user.score.label("black_score"),
white_user.score.label("white_score")
).outerjoin(black_user,GameRoom.black_user_id==black_user.user_id).outerjoin(
white_user,GameRoom.white_user_id==white_user.user_id).filter(
GameRoom.id==room_id
).all()
5.聚合查询和使用数据库函数。func可以调用各种聚合函数,和当前数据库支持的其它函数。
session.query(User.name, func.count('*').label("user_count")).group_by(User.name).all()
session.query(User.name, func.sum(User.id).label("user_id_sum")).filter(func.to_days(User.create_date)==func.to_days(func.now())).group_by(User.name).all()
6.子查询
stmt = db.session.query(Address.user_id, func.count('*').label("address_count")).group_by(Address.user_id).subquery()
db.session.query(User, stmt.c.address_count).outerjoin((stmt, User.id == stmt.c.user_id)).order_by(User.id).all()
7.直接运行SQL语句查询。如果查询实在太复杂,觉得用SQLAlchemy查询方式很难实现,或者要通过存储过程实现查询,可以让SQLAlchemy直接运行SQL语句返回结果。
sql ="""select b.user_id,b.user_name,b.icon,b.score,a.add_score from
(select user_id, sum(score_new - score_old) as add_score from user_score_log
where year(create_date)=year(now()) and month(create_date)=month(now())
group by user_id) a join users b on a.user_id=b.user_id
order by a.add_score desc limit 50"""
list_top = db.session.execute(sql).fetchall()
8.分页查询。sqlalchemy中分页用到pagination,先不说性能怎么样,使用起来是真的非常方便。
pagination = GameMessage.query.filter(GameMessage.game_id==game_id).\
order_by(GameMessage.id.desc()).\
paginate(page, per_page=20, error_out=True)
pages = pagination.pages
total = pagination.total
items = pagination.items
h.session对象如何实现线程安全?
session有两种创建方式
方式一:
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine engine = create_engine(
"mysql+pymysql://root:123@47.93.4.198:3306/s6?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Session = sessionmaker(bind=engine) # 方式一:
# 由于无法提供线程共享功能,所有在开发时要注意,在每个线程中自己创建 session。
# from sqlalchemy.orm.session import Session
# 具有操作数据库的:'close', 'commit', 'connection', 'delete', 'execute', 'expire',.....
session = Session() # 创建普通的session
print('原生session',session)
# 操作数据库
session.close()
由于无法提供线程共享功能,所有在开发时要注意,在每个线程中自己创建 session
解决办法如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import time
import threading from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
from db import Users engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/s6", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) def task(arg):
session = Session() obj1 = Users(name="alex1")
session.add(obj1) session.commit() for i in range(10):
t = threading.Thread(target=task, args=(i,))
t.start()
多线程执行示例
方式二(推荐):
from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session engine = create_engine(
"mysql+pymysql://root:123@47.93.4.198:3306/s6?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
)
Session = sessionmaker(bind=engine) # 方式二:支持线程安全,自动为每个线程创建一个session,单线程时,只创建一个
# - threading.Local
# - 唯一标识
# ScopedSession对象
# self.registry(), 加括号 创建session
# self.registry(), 加括号 创建session
# self.registry(), 加括号 创建session
from greenlet import getcurrent as get_ident #本地线程的唯一标识的函数,加括号则执行函数
session = scoped_session(Session,get_ident)
# session.add
# 操作数据库
session.remove()
支持线程安全,自动为每个线程创建一个session,单线程时,只创建一个
I.sqlalchemy-utils给SqlAlchemy提供choice功能
SqlAlchemy本身没有chocie,需要安装这个才能提供choice功能
pip install sqlalchemy-utils
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column,Integer,String
from sqlalchemy_utils import ChoiceType
from sqlalchemy import create_engine Base = declarative_base()
class User(Base):
__tablename__ = 'users'
type_choices=(
(1,'北京'),
(2,'上海'),
)
id = Column(Integer, primary_key=True) #必须要有主键
name =Column(String(64))
types=Column(ChoiceType(type_choices,Integer())) # 注意:Integer后面要有括号 __table_args__ = {
'mysql_engine': 'InnoDB',
'mysql_charset': 'utf8'
} def init_db():
"""
根据类创建数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.create_all(engine) def drop_db():
"""
根据类删除数据库表
:return:
"""
engine = create_engine(
"mysql+pymysql://root:123@127.0.0.1:3306/db1?charset=utf8",
max_overflow=0, # 超过连接池大小外最多创建的连接
pool_size=5, # 连接池大小
pool_timeout=30, # 池中没有线程最多等待的时间,否则报错
pool_recycle=-1 # 多久之后对线程池中的线程进行一次连接的回收(重置)
) Base.metadata.drop_all(engine) if __name__ == '__main__':
drop_db()
init_db()
建表
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ = "HuChong"
# Date: 2018/1/12 from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from ru import User engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/db1", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) session = Session() obj1 = User(name="xz",types=1)
obj2 = User(name="zz",types=2)
session.add_all([obj1,obj2])
session.commit()
session.close()
插入数据
#! /usr/bin/env python
# -*- coding: utf-8 -*-
# __author__ = "HuChong"
# Date: 2018/1/12 from sqlalchemy.orm import sessionmaker
from sqlalchemy import create_engine
from ru import User engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/db1", max_overflow=0, pool_size=5)
Session = sessionmaker(bind=engine) session = Session() result_list=session.query(User).all()
print(result_list)
for item in result_list:
print(item.types)
print(item.types.code,item.types.value) session.close() #######打印结果如下########
'''
[<ru.User object at 0x0386D770>, <ru.User object at 0x0386D7D0>]
Choice(code=1, value=北京)
1 北京
Choice(code=2, value=上海)
2 上海
'''
获取值
三、Flask-SQLAlchemy及Flask-Migrate组件
1.Flask-SQLAlchemy
用于将Flask和SQLAlchemy联系起来,使用之前需要装下面这个模块
pip install flask-sqlalchemy
如果使用Flask-sqlalchemy组件,则在使用时有一点变化
# 1. 引入Flask-SQLAlchemy
from flask_sqlalchemy import SQLAlchemy
db = SQLAlchemy() #实例化SQLAlchemy对象
# 2. 注册 Flask-SQLAlchemy
# SQLAlchemy(app)
# 由于这个对象在其他地方想要使用,所有用以下方式注册
db.init_app(app) #读取配置文件,配置文件中写以前在create_engine里面的链接数据
#settings.py中,加上配置
SQLALCHEMY_DATABASE_URI = "mysql+pymysql://root:123@47.93.4.198:3306/s6?charset=utf8"
SQLALCHEMY_POOL_SIZE = 2
SQLALCHEMY_POOL_TIMEOUT = 30
SQLALCHEMY_POOL_RECYCLE = -1
# 追踪对象的修改并且发送信号
SQLALCHEMY_TRACK_MODIFICATIONS = False
# 3. 导入models中的表
from .models import *
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
from app import db # 4. 写类继承db.Model
class Users(db.Model): #再不是继承Base,而且继承db.Model
__tablename__ = 'users' id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False)
pwd = Column(String(32)) __table_args__ = {
'mysql_engine': 'InnoDB', # 指定表的引擎
'mysql_charset': 'utf8' # 指定表的编码格式
} class Group(db.Model):
__tablename__ = 'group' id = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=False) __table_args__ = {
'mysql_engine': 'InnoDB',
'mysql_charset': 'utf8'
}
# 5. 创建和删除表
# 以后执行db.create_all()
# 以后执行db.drop_all()
但是这样不好,我们引入 Flask-Migrate
2.Flask-Migrate
可以通过类似Django里的命令,进行数据迁移,创建表,删除表,更新表
安装 pip install Flask-Migrate
# 5.1 导入
from flask_migrate import Migrate, MigrateCommand
from app import create_app, db app = create_app()
manager = Manager(app)
# 5.2 创建migrate实例
migrate = Migrate(app, db)
#执行命令:
初次:python manage.py db init python manage.py db migrate
python manage.py db upgrade
以后执行SQL时:
方式一:
result = db.session.query(models.User.id,models.User.name).all()
db.session.remove()
方式二:
result = models.Users.query.all()
3.代码规范之生成requestments.txt文件
pip freeze # 获取环境中所有安装的模块以及其对应的版本 pip freeze > requirements.txt # 生成对应的文本文件
由于获取的是所有,我们还得自己手动在文本里删除一些不必要的,所有这个方法不好,我们使用下面的方法
pip install pipreqs
首先安装模块,安装完成以后,我们就可以在终端,执行pipreqs命令
# 获取当前所在程序目录中涉及到的所有模块,并自动生成 requirements.txt 且写入内容。
pipreqs ./
建议在Linux系统下使用,windows环境下会报错

以后使用别人的程序,进入程序目录:
安装requirements.txt依赖
pip install -r requirements.txt
会自动安装文件里,所有对应版本模块
https://segmentfault.com/a/1190000003050954
http://www.cnblogs.com/huchong/p/8797516.html
http://docs.jinkan.org/docs/flask/patterns/sqlalchemy.html
SQLAlchemy外键和关系
http://www.codexiu.cn/python/SQLAlchemy%E5%9F%BA%E7%A1%80%E6%95%99%E7%A8%8B/73/530/
lazy的用法
http://shomy.top/2016/08/11/flask-sqlalchemy-relation-lazy/
Flask-SQLAlchemy常用操作的更多相关文章
- SQLAlchemy常用操作
Models 只是配置和使用比较简单,因为他是Django自带的ORM框架,也正是因为是Django原生的,所以兼容性远远不如SQLAlchemy 真正算得上全面的ORM框架必然是我们的SQLAlch ...
- flask, SQLAlchemy, sqlite3 实现 RESTful API 的 todo list, 同时支持form操作
flask, SQLAlchemy, sqlite3 实现 RESTful API, 同时支持form操作. 前端与后台的交互都采用json数据格式,原生javascript实现的ajax.其技术要点 ...
- 【Flask】Sqlalchemy 常用数据类型
### SQLAlchemy常用数据类型:1. Integer:整形,映射到数据库中是int类型.2. Float:浮点类型,映射到数据库中是float类型.他占据的32位.3. Double:双精度 ...
- flask的orm操作
django是有orm操作的 可想而知 那么flask也是有orm操作的,其实flask的orm操作的使用和djnago的是差不多的 django的orm操作进行条件筛选的时候后面跟着的是objec ...
- SQLAlchemy表操作和增删改查
一.SQLAlchemy介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数 ...
- Flask使用Flask-SQLAlchemy操作MySQL数据库
前言: Flask-SQLAlchemy是一个Flask扩展,简化了在Flask程序中使用SQLAlchemy的操作.SQLAlchemy是一个很强大的关系型数据库框架,支持多种数据库后台.SQLAl ...
- Python Flask SQLALchemy基础知识
一.介绍 SQLAlchemy是一个基于Python实现的ORM框架.该框架建立在 DB API之上,使用关系对象映射进行数据库操作,简言之便是:将类和对象转换成SQL,然后使用数据API执行SQL并 ...
- 【三】用Markdown写blog的常用操作
本系列有五篇:分别是 [一]Ubuntu14.04+Jekyll+Github Pages搭建静态博客:主要是安装方面 [二]jekyll 的使用 :主要是jekyll的配置 [三]Markdown+ ...
- php模拟数据库常用操作效果
test.php <?php header("Content-type:text/html;charset='utf8'"); error_reporting(E_ALL); ...
- Mac OS X常用操作入门指南
前两天入手一个Macbook air,在装软件过程中摸索了一些基本操作,现就常用操作进行总结, 1关于触控板: 按下(不区分左右) =鼠标左键 control+按下 ...
随机推荐
- cookie 和 session区别
cookie 和 session区别 ① cookie介绍说明 cookie 存放在浏览器缓存中---浏览器进行查看(谷歌) [设置]---[高级]---[内容设置]---[cookie]---[所有 ...
- CSS3效果:animate实现点点点loading动画效果(二)
box-shadow实现的打点效果 简介 box-shadow理论上可以生成任意的图形效果,当然也就可以实现点点点的loading效果了. 实现原理 html代码,首先需要写如下html代码以及cla ...
- 2018-08-13 Head First OO分析设计一书略读与例子中文化
注: 此笔记仅为个人学习此教程的布局和材料组织之用. 如有兴趣请自行详阅. 第一章是以吉他商店的存货系统作例子. 第二章设计有狗洞的门. 第三章对第二章基础上, 更改需求后对应设计. 第四章继续改进此 ...
- IBM沃森会成为第一个被抛弃的AI技术吗?
作者|William Vorhies 译者|姚佳灵 编辑|Debra 导读:IBM 的沃森问答机(Question Answering Machine,简称 QAM),因 2011 年参加综艺节目&l ...
- 在Arcmap中加载互联网地图资源的4种方法
前一段时间想在Arcmap中打开互联网地图中的地图数据,如影像数据.基础地图数据等,经过简单研究目前总结了四种方法,整理下与大家分享,有些内容可能理解有误,希望大家多多指教.4种方法如下: a) ...
- 行业观察报告:从SAAS困局看行业趋势 ZT
企业管理软件的演化过程 第一阶段:独立开发 典型代表:IBM 这个阶段是将企业的信息化需求整合成硬件+软件的一体化解决方案,从零开始设计开发,适用于通讯.电力.交通等基础设施建设项目.这个阶段的特点是 ...
- 17.Odoo产品分析 (二) – 商业板块(10) – 电子商务(1)
查看Odoo产品分析系列--目录 安装电子商务模块 1. 主页 点击"商店"菜单: 2. 添加商品 在odoo中,你不用进入"销售"模块,再进入产品列表添加产 ...
- JVM虚拟机学习一:垃圾回收算法总结
1.java虚拟机中涉及到的数据类型 Java虚拟机中,数据类型可以分为两类:基本类型和引用类型. 基本类型的变量保存原始值,即:他代表的值就是数值本身:而引用类型的变量保存引用值.“引用值”代表了某 ...
- Android 直接修改dex破解
直接修改dex破解 一.编写一个简单的验证程序 (1)MainActivity: protected void onCreate(BundlesavedInstanceState) { super.o ...
- Android滑动冲突解决
(1).场景一:外部滑动方向跟内部滑动方向不一致,比如外部左右滑动,内部上下滑动 ViewPager+Fragment配合使用,会有滑动冲突,但是ViewPager内部处理了这种滑动冲突 如果 ...