InfluxDB基本概念和操作
InfluxDB基本概念
1、数据格式
在 InfluxDB 中,我们可以粗略的将要存入的一条数据看作一个虚拟的 key 和其对应的 value(field value)。格式如下:
|
1
|
cpu_usage,host=server01,region=us-west value=0.64 1434055562000000000 |
虚拟的 key 包括以下几个部分: database, retention policy, measurement, tag sets, field name, timestamp。
- database: 数据库名,在 InfluxDB 中可以创建多个数据库,不同数据库中的数据文件是隔离存放的,存放在磁盘上的不同目录。
- retention policy: 存储策略,用于设置数据保留的时间,每个数据库刚开始会自动创建一个默认的存储策略 autogen,数据保留时间为永久,之后用户可以自己设置,例如保留最近2小时的数据。插入和查询数据时如果不指定存储策略,则使用默认存储策略,且默认存储策略可以修改。InfluxDB 会定期清除过期的数据。
- measurement: 测量指标名,例如 cpu_usage 表示 cpu 的使用率。
- tag sets: tags 在 InfluxDB 中会按照字典序排序,不管是 tagk 还是 tagv,只要不一致就分别属于两个 key,例如 host=server01,region=us-west 和 host=server02,region=us-west 就是两个不同的 tag set。
- tag--标签,在InfluxDB中,tag是一个非常重要的部分,表名+tag一起作为数据库的索引,是“key-value”的形式。
- field name: 例如上面数据中的 value 就是 fieldName,InfluxDB 中支持一条数据中插入多个 fieldName,这其实是一个语法上的优化,在实际的底层存储中,是当作多条数据来存储。
- timestamp: 每一条数据都需要指定一个时间戳,在 TSM 存储引擎中会特殊对待,以为了优化后续的查询操作。
2、与传统数据库中的名词做比较
| influxDB中的名词 | 传统数据库中的概念 |
| database | 数据库 |
| measurement | 数据库中的表 |
| points | 表里面的一行数据 |
3、Point
Point由时间戳(time)、数据(field)、标签(tags)组成。
Point相当于传统数据库里的一行数据,如下表所示:
| Point属性 | 传统数据库中的概念 |
| time | 每个数据记录时间,是数据库中的主索引(会自动生成) |
| fields | 各种记录值(没有索引的属性) |
| tags | 各种有索引的属性 |
4、Series
Series 相当于是 InfluxDB 中一些数据的集合,在同一个 database 中,retention policy、measurement、tag sets 完全相同的数据同属于一个 series,同一个 series 的数据在物理上会按照时间顺序排列存储在一起。
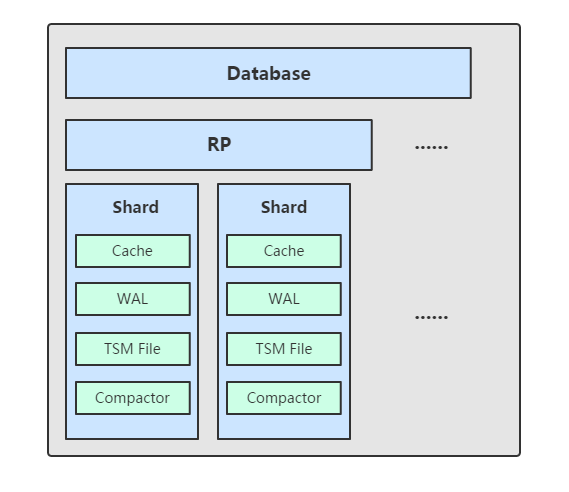
5、Shard
Shard 在 InfluxDB 中是一个比较重要的概念,它和 retention policy 相关联。每一个存储策略下会存在许多 shard,每一个 shard 存储一个指定时间段内的数据,并且不重复,例如 7点-8点 的数据落入 shard0 中,8点-9点的数据则落入 shard1 中。每一个 shard 都对应一个底层的 tsm 存储引擎,有独立的 cache、wal、tsm file。
6、组件
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
1)Cache:cache 相当于是 LSM Tree 中的 memtabl。插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
2)WAL:wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
3)TSM File:单个 tsm file 大小最大为 2GB,用于存放数据。
4)Compactor:compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
7、目录与文件结构
InfluxDB 的数据存储主要有三个目录。默认情况下是 meta, wal 以及 data 三个目录。
meta 用于存储数据库的一些元数据,meta 目录下有一个 meta.db 文件。
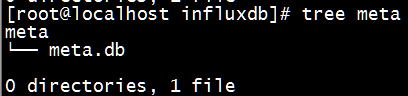
wal 目录存放预写日志文件,以 .wal 结尾。
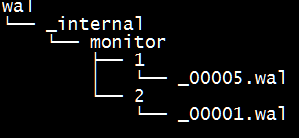
data 目录存放实际存储的数据文件,以 .tsm 结尾。
上面几张图中,_internal为数据库名,monitor为存储策略名称,再下一层目录中的以数字命名的目录是 shard 的 ID 值。
存储策略下有两个 shard,ID 分别为 1 和 2,shard 存储了某一个时间段范围内的数据。再下一级的目录则为具体的文件,分别是 .wal 和 .tsm 结尾的文件。
InfluxDB基本操作
InfluxDB提供多种操作方式:
1)客户端命令行方式
2)HTTP API接口
3)各语言API库
4)基于WEB管理页面操作
客户端命令行方式操作
进入命令行
|
1
|
influx -precision rfc3339 |

1、InfluxDB数据库操作
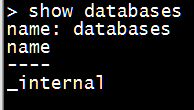
- 显示数据库
|
1
|
show databases |
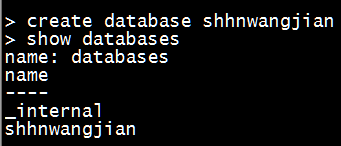
- 新建数据库
|
1
|
create database shhnwangjian |
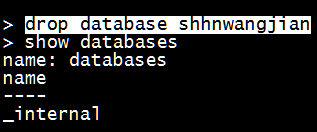
- 删除数据库
|
1
|
drop database shhnwangjian |
- 使用指定数据库
|
1
|
use shhnwangjian |

2、InfluxDB数据表操作
在InfluxDB当中,并没有表(table)这个概念,取而代之的是MEASUREMENTS,MEASUREMENTS的功能与传统数据库中的表一致,因此我们也可以将MEASUREMENTS称为InfluxDB中的表。
- 显示所有表
|
1
|
SHOW MEASUREMENTS |
- 新建表
InfluxDB中没有显式的新建表的语句,只能通过insert数据的方式来建立新表。
|
1
|
insert disk_free,hostname=server01 value=442221834240i |
其中 disk_free 就是表名,hostname是索引(tag),value=xx是记录值(field),记录值可以有多个,系统自带追加时间戳

或者添加数据时,自己写入时间戳
|
1
|
insert disk_free,hostname=server01 value=442221834240i 1435362189575692182 |

- 删除表
|
1
|
drop measurement disk_free |
3、数据保存策略(Retention Policies)
influxDB是没有提供直接删除数据记录的方法,但是提供数据保存策略,主要用于指定数据保留时间,超过指定时间,就删除这部分数据。
- 查看当前数据库Retention Policies
|
1
|
show retention policies on "db_name" |

- 创建新的Retention Policies
|
1
|
create retention policy "rp_name" on "db_name" duration 3w replication 1 default |
rp_name:策略名;
db_name:具体的数据库名;
3w:保存3周,3周之前的数据将被删除,influxdb具有各种事件参数,比如:h(小时),d(天),w(星期);
replication 1:副本个数,一般为1就可以了;
default:设置为默认策略
- 修改Retention Policies
|
1
|
alter retention policy "rp_name" on "db_name" duration 30d default |
- 删除Retention Policies
|
1
|
drop retention policy "rp_name" on "db_name" |
4、连续查询(Continuous Queries)
InfluxDB的连续查询是在数据库中自动定时启动的一组语句,语句中必须包含 SELECT 关键词和 GROUP BY time() 关键词。
InfluxDB会将查询结果放在指定的数据表中。
目的:使用连续查询是最优的降低采样率的方式,连续查询和存储策略搭配使用将会大大降低InfluxDB的系统占用量。而且使用连续查询后,数据会存放到指定的数据表中,这样就为以后统计不同精度的数据提供了方便。
- 新建连续查询
|
1
2
3
4
5
|
CREATE CONTINUOUS QUERY <cq_name> ON <database_name>[RESAMPLE [EVERY <interval>] [FOR <interval>]]BEGIN SELECT <function>(<stuff>)[,<function>(<stuff>)] INTO <different_measurement>FROM <current_measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<stuff>]END |
样例:
|
1
|
CREATE CONTINUOUS QUERY wj_30m ON shhnwangjian BEGIN SELECT mean(connected_clients), MEDIAN(connected_clients), MAX(connected_clients), MIN(connected_clients) INTO redis_clients_30m FROM redis_clients GROUP BY ip,port,time(30m) END |
在shhnwangjian库中新建了一个名为 wj_30m 的连续查询,每三十分钟取一个connected_clients字段的平均值、中位值、最大值、最小值 redis_clients_30m 表中。使用的数据保留策略都是 default。
不同database样例:
|
1
|
CREATE CONTINUOUS QUERY wj_30m ON shhnwangjian_30 BEGIN SELECT mean(connected_clients), MEDIAN(connected_clients), MAX(connected_clients), MIN(connected_clients) INTO shhnwangjian_30.autogen.redis_clients_30m FROM shhnwangjian.autogen.redis_clients GROUP BY ip,port,time(30m) END |
- 显示所有已存在的连续查询
|
1
|
SHOW CONTINUOUS QUERIES |

- 删除Continuous Queries
|
1
|
DROP CONTINUOUS QUERY <cq_name> ON <database_name> |
参考文章:
http://blog.fatedier.com/2016/08/05/detailed-in-influxdb-tsm-storage-engine-one/
http://www.linuxdaxue.com/noun-interpretation-of-influxdb.html
InfluxDB基本概念和操作的更多相关文章
- clearcase 中一些概念和操作
clearcase 中一些概念和操作 视图 常用命令 ClearCase 安装和使用的一些FAQ 参考 ClearCase具体的说是做配置管理的工具,只是SCM管理工具其中的一种.是RATIONAL公 ...
- 基本数据结构——堆(Heap)的基本概念及其操作
基本数据结构――堆的基本概念及其操作 小广告:福建安溪一中在线评测系统 Online Judge 在我刚听到堆这个名词的时候,我认为它是一堆东西的集合... 但其实吧它是利用完全二叉树的结构来维护一组 ...
- TensorFlow简易学习[1]:基本概念和操作示例
简介 TensorFlow是一个实现机器学习算法的接口,也是执行机器学习算法的框架.使用数据流式图规划计算流程,可以将计算映射到不同的硬件和操作系统平台. 主要概念 TensorFlow的计算可以表示 ...
- Linux 基本概念和操作2
接着上一篇 "Linux 基本概念和操作" 1.删除文件 有时候我们想要删除的文件是只读文件,直接使用rm 文件名,会报错.这时使用" -f " 参数强制删除. ...
- Linux基本概念及操作
基本概念及操作 一.实验介绍 1.1 实验内容: 实验楼环境介绍 常用 Shell 命令及快捷键 Linux 使用小技巧 1.2 实验知识点 Linux 基本命令 通配符的使用 基本软件安装 查看帮助 ...
- InfluxDB从原理到实战 - InfluxDB常用的基础操作
0x00 基础操作介绍 在本文中将介绍InfluxDB常用的基础操作,帮助读者建立对InfluxDB的感性认识,快速的动手玩起来,持续查询(Continuous Queies).Group by.Se ...
- Maven基本概念和操作
最近在学Java,找来一个开源项目练手,它是用 Spring Boot 搭建的框架,于是去学 Spring Boot,然而 Spring Boot 需要有 Spring 框架和 Maven 的使用经验 ...
- [转]C#网络编程(基本概念和操作) - Part.1
本文转自:http://www.tracefact.net/CSharp-Programming/Network-Programming-Part1.aspx 引言 C#网络编程系列文章计划简单地讲述 ...
- DOM基本概念和操作
1.基本概念 DOM是文档对象模型(TEXT),对象是指文档中的每一个元素. 2.Window对象操作 打开方式: _blank 在新窗口还是自身窗口. Window.open 也有返回值,返回值为 ...
随机推荐
- Android Studio 使用Intent
1.显式Intent Intent intent=new Intent(yzj.this,MainActivity.class);//当前活动的实例,要去的实例 startActivity(inten ...
- JSJ—案例谈面向对象
有人告诉我那里遍地都是对象——我们把所有的程序代码放在main()里面,事实上,那根本就不是面向对象的做法,在Java的面向对象中,我们也会看到类和对象的不同,以及对象是如何让你的生活更美好(至少程序 ...
- java关于字符串的一些实用操作工具类方法
package cn.edu.stdu; import java.util.ArrayList; import java.util.LinkedHashSet; import java.util.Se ...
- CPU 实用工具
系统版本:CentOS 7.4 top 17:49:04 // 当前时间 up 3:55 // 系统运行时间,格式为时:分 2 users // 当前登录用户数 load average // 三个值 ...
- es6 语法 (模块化)
//export export let A=123; //导出 //导出函数 export function test(){ console.log('test'); } //导出类 export c ...
- js匹配字符串
lastIndexOf() 方法可返回一个指定的字符串值最后出现的位置,在一个字符串中的指定位置从后向前搜索 var str = 'Hello World' str.lastIndexOf('Hell ...
- 利用Fiddler修改请求信息通过Web API执行Dynamics 365操作(Action)实例
本人微信和易信公众号: 微软动态CRM专家罗勇 ,回复261或者20170724可方便获取本文,同时可以在第一间得到我发布的最新的博文信息,follow me!我的网站是 www.luoyong.me ...
- 人工智能改进传统云ERP的10种方法
http://blog.itpub.net/31542119/viewspace-2168809/ 随着数字化转型的进程加快,企业开始重新评估ERP的作用.传统ERP经过多年僵硬化定制过于追求生产的一 ...
- Android为TV端助力 最详细的动画大全,包括如何在代码和在XML中使用
一.动画类型 Android的animation由四种类型组成:alpha.scale.translate.rotate XML配置文件中 alpha 渐变透明度动画效果 scale 渐变尺寸伸缩动画 ...
- Windows服务System权限下在当前用户桌面创建快捷方式C#实例程序
Windows服务一般运行在System权限下,这样权限比较高,方便执行一些高权限的操作. 但是,Environment.GetFolderPath等函数获取的也是System用户下的,而不是当前用户 ...