TF:利用sklearn自带数据集使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线—Jason niu
import tensorflow as tf
from sklearn.datasets import load_digits
#from sklearn.cross_validation import train_test_split
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer # load data
digits = load_digits() X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):
# add one more layer and return the output of this layer
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
# here to dropout
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob)
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs # define placeholder for inputs to network
keep_prob = tf.placeholder(tf.float32)
xs = tf.placeholder(tf.float32, [None, 64])
ys = tf.placeholder(tf.float32, [None, 10]) # add output layer
l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh)
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax) # the loss between prediction and real data
cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1]))
tf.summary.scalar ('loss', cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session()
merged = tf.summary.merge_all()
# summary writer goes in here
train_writer = tf.summary.FileWriter("logs4/train", sess.graph)
test_writer = tf.summary.FileWriter("logs4/test", sess.graph) sess.run(tf.global_variables_initializer()) for i in range(500):
# here to determine the keeping probability
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5})
if i % 50 == 0:
# record loss
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
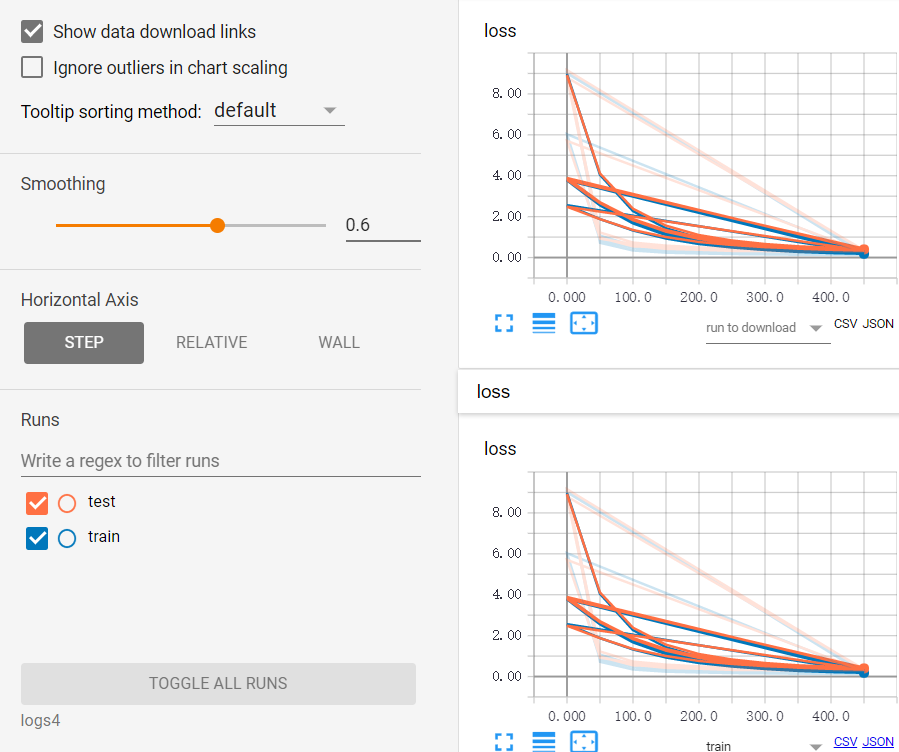
TF:利用sklearn自带数据集使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线—Jason niu的更多相关文章
- TF之NN:matplotlib动态演示深度学习之tensorflow将神经网络系统自动学习并优化修正并且将输出结果可视化—Jason niu
import tensorflow as tf import numpy as np import matplotlib.pyplot as plt def add_layer(inputs, in_ ...
- TF:TF分类问题之MNIST手写50000数据集实现87.4%准确率识别:SGD法+softmax法+cross_entropy法—Jason niu
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data # number 1 to 10 ...
- 利用Linux自带的logrotate管理日志
日常运维中,经常要对各类日志进行管理,清理,监控,尤其是因为应用bug,在1小时内就能写几十个G日志,导致磁盘爆满,系统挂掉. nohup.out,access.log,catalina.out 本文 ...
- GA:利用GA对一元函数进行优化过程,求x∈(0,10)中y的最大值——Jason niu
x = 0:0.01:10; y = x + 10*sin(5*x)+7*cos(4*x); figure plot(x, y) xlabel('independent variable') ylab ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 『Sklearn』框架自带数据集接口
自带数据集类型如下: # 自带小型数据集# sklearn.datasets.load_<name># 在线下载数据集# sklearn.datasets.fetch_<name&g ...
- 利用Sklearn实现加州房产价格预测,学习运用机器学习的整个流程(包含很多细节注解)
Chapter1_housing_price_predict .caret, .dropup > .btn > .caret { border-top-color: #000 !impor ...
- 利用jdk自带的运行监控工具JConsole观察分析Java程序的运行
利用jdk自带的运行监控工具JConsole观察分析Java程序的运行 原文链接 一.JConsole是什么 从Java 5开始 引入了 JConsole.JConsole 是一个内置 Java 性能 ...
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
随机推荐
- 【进阶1-5期】JavaScript深入之4类常见内存泄漏及如何避免(转)
这是我在公众号(高级前端进阶)看到的文章,现在做笔记 https://mp.weixin.qq.com/s/RZ8Lpkyk8lz6z5H8Q8SiEQ 垃圾回收算法 常用垃圾回收算法叫做**标记清除 ...
- js-DOM事件
var EventUtil = { addHandler:function(elm,type,handler){//添加事件 if(elm.addEventListener){ elm.addEven ...
- Confluence 6 数据库表-内容(Content)
这部分的内容描述了有关 Confluence 存储内容所使用的表格.内容是用户在 Confluence 存储和分享的信息. attachmentdata 附件文件的二进制数据.当 Confluence ...
- Confluence 6 为空白空间编辑默认主页
希望编辑默认(空白)空间内容模板: 在屏幕的右上角单击 控制台按钮 ,然后选择 General Configuration 链接. 在左侧的面板中选择 全局模板和蓝图(Global Templates ...
- nginx实践(一)之静态资源web服务
静态资源服务场景CDN 配置语法-文件读取(nginx优势之一sendfile) 配置语法-tcp_nopush 简单的说就是把多个包合并,一次传输给客户端 配置语法-tap_nodelay 配置语法 ...
- mvc 模式和mtc 模式的区别
首先说说Web服务器开发领域里著名的MVC模式,所谓MVC就是把Web应用分为模型(M),控制器(C)和视图(V)三层,他们之间以一种插件式的.松耦合的方式连接在一起,模型负责业务对象与数据库的映射( ...
- 对Swoole、Workerman和php自带的socket的理解
为什么php自带的socket不怎么听说,基本都是用swoole,workerman去实现? 1.PHP的socket扩展是一套socket api,仅此而已. swoole,用C实现,它的socke ...
- django----注意事项
不用带参数 必须要带参数:
- Java 获取屏幕的宽、高
import java.awt.Toolkit; public class GetScreenSize { public static void main(String[] args) { int s ...
- HDU 1247 Hat’s Words(字典树活用)
Hat's Words Time Limit : 2000 / 1000 MS(Java / Others) Memory Limit : 65536 / 32768 K(Java / Othe ...