11-SQLServer的事务、存储过程和触发器
一. 概述
1. 什么是存储过程?
存储过程可以理解为是使用T_SQL编写的一组代码段,将一系列SQL操作(增删改查)封装在一起,组成一个代码块,方便每次调用。同时存储过程是数据库和应用程序间的桥梁,是二者之间的编程接口,比如:ADO.NET、EF等技术都可以在代码中调用存储过程。
一句话总结:存储过程是数据库为了实现特定业务需求而将一系列SQL操作封装成代码段存放在数据库服务器上便于应用程序来调用。
2. 存储过程的好处
a. 存储过程封装了复杂的SQL操作,简化了操作流程。
b. 加快了应用程序系统的运行速度,因为存储过程只在创建时编译,此后的调用无须重新编译。
c. 实现了模块化的程序设计,存储过程可以被多次调用,为应用程序提供了统一的数据库访问接口,提高了程序的可维护性,充分体现了模块化的开发思想。
d. 提高了代码的安全性,数据库管理员可以为存储过程设定指定的用户可访问的权限。
e. 降低网络流量,有存储过程是存放在服务器上的,所以在应用程序与服务器通信过程中,不会产生大量的T_SQL代码。
3. 存储过程的缺陷
a. 与数据库依赖性太强,不同类型数据库间的存储过程不能简单的相互移植。
b. 不支持服务器集群。
c. 没法采用面向对象的思想进行封装。
4. 存储过程的种类
(1). 系统存储过程
系统存储过程是 SQL Server系统自身提供的存储过程,可以作为命令执行各种操作。系统存储过程主要用来从系统表中获取信息,使用系统存储过程完成数据库服务器的管理工作,为系统管理员提供帮助,为用户查看数据库对象提供方便,系统存储过程位于数据库服务器中,并且以sp_开头,系统存储过程定义在系统定义和用户定义的数据库中,在调用时不必在存储过程前加数据库限定名。
例如:sp_rename系统存储过程可以修改当前数据库中用户创建对象的名称,sp_helptext存储过程可以显示规则,默认值或视图的文本信息,SQL SERVER服务器中许多的管理工作都是通过执行系统存储过程来完成的,许多系统信息也可以通过执行系统存储过程来获得。
系统存储过程创建并存放在与系统数据库master中,一些系统存储过程只能由系统管理员使用,而有些系统存储过程通过授权可以被其它用户所使用。
(2). 自定义存储过程
自定义存储过程即用户使用T_SQL语句编写的、为了实现某一特定业务需求,在用户数据库中编写的T_SQL语句集合,自定义存储过程可以接受输入参数、向客户端返回结果和信息,返回输出参数等。创建自定义存储过程时,存储过程名前加上"##"表示创建了一个全局的临时存储过程,存储过程前面加上"#"时,表示创建的局部临时存储过程。局部临时存储过程只能在创建它的回话中使用,会话结束时,将被删除。这两种存储过程都存储在tempdb数据库中。
用户定义的存储过程分为两类:T_SQL 和CLR
T_SQL:存储过程是值保存的T_SQL语句集合,可以接受和返回用户提供的参数,存储过程也可能从数据库向客户端应用程序返回数据。
CLR:存储过程是指引用Microsoft.NET Framework公共语言的方法存储过程,可以接受和返回用户提供的参数,它们在.NET Framework程序集是作为类的公共静态方法实现的。
(3). 扩展存储过程
扩展存储过程是以在SQL SERVER环境外执行的动态连接(DLL文件)来实现的,可以加载到SQL SERVER实例运行的地址空间中执行,扩展存储过程可以用SQL SERVER扩展存储过程API编程,扩展存储过程以前缀"xp_"来标识,对于用户来说,扩展存储过程和普通话存储过程一样,可以用相同的方法来执行。
二. 存储过程
整体规则:
A. 存储过程用 procedure表示,也可以缩写为 proc 。
B. 删除存储过程用drop 。
C. 创建存储过程前,通常加一段代码,用来判断存储过程是否存在,避免重复创建的问题。代码如下:
D. 存储过程的参数形式:输入参数和输出参数(可以给输入参数设置默认值)
加载前面的代码:
if (exists (select * from sys.objects where name = '存储过程名'))
drop proc 存储过程名
1. 创建无参的存储过程
if (exists (select * from sys.objects where name = 'GetAllUserInfor'))
drop proc GetAllUserInfor
go
create procedure GetAllUserInfor
as
select * from UserInfor -- 调用存储过程
exec GetAllUserInfor;
2. 修改指定存储过程的内容
go
alter proc GetAllUserInfor
as
select * from UserInfor where userName = 'ypf' -- 调用存储过程
exec GetAllUserInfor;
3. 删除存储过程
drop proc GetAllUserInfor;
4. 重命名存储过程(调用系统自带的存储过程来实现)
-- 4. 重命名存储过程(调用系统自带的存储过程来实现)
-- 将名为“GetAllUserInofor”的存储过程改为 “proc_GetAllUserInofor”
go
sp_rename GetAllUserInfor,GetAllUserInfor2; -- 调用存储过程
exec GetAllUserInfor2;
5. 创建带参数的存储过程
PS:
输入参数:用于向存储过程传入值,类似C#值传递。
输出参数:用于调用存储过程后,返回结果,类似C#引用传递。
5.1 创建带1个输入参数的存储过程
-- 5.1 创建带1个输入参数的存储过程
--(根据用户ID来查询用户信息)
if (exists (select * from sys.objects where name = 'GetUserById'))
drop proc GetUserById
go
create proc GetUserById(
@userId varchar(32)
)
as
select * from UserInfor where id=@userId; --执行该存储过程
exec GetUserById '';
exec GetUserById '';
5.2 创建带两个输入参数的存储过程
--(根据用户id和用户姓名来查询用户信息)
if (exists (select * from sys.objects where name = 'GetUserByIdAndName'))
drop proc GetUserByIdAndName
go
create proc GetUserByIdAndName(
@userId varchar(32),
@userName varchar(50)
)
as
select * from UserInfor where id=@userId and userName=@userName; -- 执行该存储过程
--参数需要按顺序来写
exec GetUserByIdAndName '','ypf1';
--参数可以不按照顺序随意写
exec GetUserByIdAndName @userName='ypf1',@userId=''
5.3 创建带有输出参数(返回值)的存储过程
--注:纠正一个概念,输出参数是1个符合数据库类型的值,而不能是1个集合。
-- (根据主键id来查询用户的姓名,并输出该表中用户的总数量)
if (exists (select * from sys.objects where name = 'GetMsg'))
drop proc GetMsg
go
create proc GetMsg(
@id varchar(32), --输入参数,无默认值
@userName varchar(50) output, -- 输出参数,无默认值
@count int output --输出参数 ,无默认值
)
as
select @userName=userName from UserInfor where id=@id;
select @count=COUNT(*) from UserInfor; -- 执行该存储过程
declare @myUserName varchar(50); --声明变量来接收存储过程的返回值
declare @myCount int; --声明变量来接收存储过程的返回值
exec GetMsg @id='',@userName=@myUserName output,@count=@myCount output;
select @myUserName as '姓名',@myCount as '总条数'; --或者这样调用
--declare @myUserName varchar(50); --声明变量来接收存储过程的返回值
--declare @myCount int; --声明变量来接收存储过程的返回值
--exec GetMsg '002',@myUserName output,@myCount output;
--select @myUserName,@myCount
注:纠正一个概念,输出参数是一个符合数据库类型的值,而不能是一个集合。
5.4 创建带通配符的存储过程
if (exists (select * from sys.objects where name = 'GetInfor'))
drop proc GetInfor
go
create proc GetInfor(
@userName varchar(50) --输入参数
)
as
select * from UserInfor where userName like @userName; -- 执行该存储过程
exec GetInfor 'y%'; --userName 以y开头
exec GetInfor '%p%'; --userName 中间有个p
exec GetInfor '_p%'; --userName p为第二个字符,p前有一个字符,p后不定
6. 加密存储过程(with encryption)
-- with encryption 用户隐藏存储过程的文本
if (exists (select * from sys.objects where name = 'GetInforWithEncry'))
drop proc GetInforWithEncry
go
create proc GetInforWithEncry
with encryption
as
select * from UserInfor; -- 给该存储过程的文本加密
exec sp_helptext 'GetInforWithEncry'; --系统存储过程获取关于加密的信息
-- 执行该存储过程(加密不影响执行)
exec GetInforWithEncry;
7 .不缓存存储过程(with recompile)
if (exists (select * from sys.objects where name = 'GetInforNoCache'))
drop proc GetInforNoCache
go
create proc GetInforNoCache
with recompile
as
select * from UserInfor; -- 执行该存储过程
exec GetInforNoCache;
8. 分页的存储过程案例
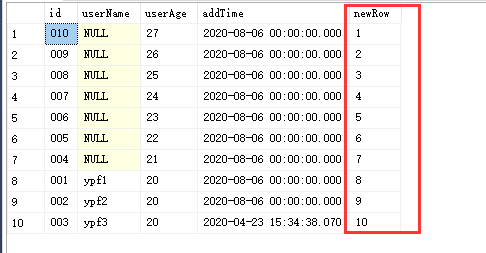
方案一:利用ROW_NUMBER() over() 和 between and,进行分页。ROW_NUMBER() over() 表示把该表按照某个字段进行排序,然后新生成一列,从1到n,如下图:
over里的排序要晚于外层 where,group by,order by
会按照over里面的排序,新增一列(1----n),比如 newRow, 然后基于这一列,使用between and 进行区间获取
可以将出来的数据进行排列1-----n,即多了一列
select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor
演变过程:
select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor select * from
(select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor) as t select * from
(select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor) as t
where t.newRow between 1 and 2
方案2: 利用offset-fetch (SQLServer2012后开始支持),分页实现的思路:
--在分页实现中,使用Order By子句,按照指定的columns对结果集进行排序;
--使用offset子句跳过前N页:offset (@PageIndex-1)*@RowsPerPage rows;
--使用fetch子句取N页:fetch next @RowsPerPage rows only;
--跨过3行取剩下的
select * from UserInfor order by userAge desc
offset 3 rows --跨过3行取剩下2行
select * from UserInfor order by userAge desc
offset 3 rows
fetch next 2 rows only
封装成存储过程:(这里基于方案一、方案二各一种,然后基于方案一写了一个万能的分页)
-- 基于"方案一"的存储过程分页
if (exists (select * from sys.objects where name = 'FenYe1'))
drop proc FenYe1
go
create proc FenYe1(
@pageSize int=3, --输入参数:每页的条数,默认值为2
@pageIndex int=1, --输入参数:当前页数,默认值为1
@totalCount int output, --输出参数:总条数
@pageCount int output --输出参数:总页数
)
as
select * from
(select *, ROW_NUMBER() over(order by userAge desc) as newRow from UserInfor) as t
where t.newRow between ((@pageIndex-1)*@pageSize)+1 and (@pageSize*@pageIndex);
select @totalCount=COUNT(*) from UserInfor;
set @pageCount=CEILING(@totalCount * 1.0 /@pageSize); --执行该分页的存储过程
declare @myTotalCount int, --声明变量用来接收存储过程中的输出参数
@myPageCount int --声明变量用来接收存储过程中的输出参数
exec FenYe1 2,1,@myTotalCount output,@myPageCount output; --每页2条,求第1页的数据
select @myTotalCount as '总条数',@myPageCount as '总页数'; -- 基于"方案二"的存储过程分页
if (exists (select * from sys.objects where name = 'FenYe2'))
drop proc FenYe2
go
create proc FenYe2(
@pageSize int=3, --输入参数:每页的条数,默认值为2
@pageIndex int=1, --输入参数:当前页数,默认值为1
@totalCount int output, --输出参数:总条数
@pageCount int output --输出参数:总页数
)
as
select * from UserInfor order by userAge desc
offset (@pageIndex-1)*@pageSize rows fetch next @pageSize rows only;
select @totalCount=COUNT(*) from UserInfor;
set @pageCount=CEILING(@totalCount * 1.0 /@pageSize); --执行该分页的存储过程
declare @myTotalCount int, --声明变量用来接收存储过程中的输出参数
@myPageCount int --声明变量用来接收存储过程中的输出参数
exec FenYe2 4,2,@myTotalCount output,@myPageCount output; --每页4条,求第2页的数据
select @myTotalCount as '总条数',@myPageCount as '总页数'; --基于"方案一"创建一个万能表的分页
if (exists (select * from sys.objects where name = 'WangNengFenYe'))
drop proc WangNengFenYe
go
create proc WangNengFenYe(
@TableName varchar(50), --表名
@ReFieldsStr varchar(200) = '*', --字段名(全部字段为*)
@OrderString varchar(200), --排序字段(必须!支持多字段不用加order by)
@WhereString varchar(500) =N'', --条件语句(不用加where)
@PageSize int, --每页多少条记录
@PageIndex int = 1 , --指定当前为第几页
@TotalRecord int output --返回总记录数
)
as
begin
--处理开始点和结束点
Declare @StartRecord int;
Declare @EndRecord int;
Declare @TotalCountSql nvarchar(500);
Declare @SqlString nvarchar(2000);
set @StartRecord = (@PageIndex-1)*@PageSize + 1
set @EndRecord = @StartRecord + @PageSize - 1
SET @TotalCountSql= N'select @TotalRecord = count(*) from ' + @TableName;--总记录数语句
SET @SqlString = N'(select row_number() over (order by '+ @OrderString +') as rowId,'+@ReFieldsStr+' from '+ @TableName;--查询语句
--
IF (@WhereString! = '' or @WhereString!=null)
BEGIN
SET @TotalCountSql=@TotalCountSql + ' where '+ @WhereString;
SET @SqlString =@SqlString+ ' where '+ @WhereString;
END
--第一次执行得到
--IF(@TotalRecord is null)
-- BEGIN
EXEC sp_executesql @totalCountSql,N'@TotalRecord int out',@TotalRecord output;--返回总记录数
-- END
----执行主语句
set @SqlString ='select * from ' + @SqlString + ') as t where rowId between ' + ltrim(str(@StartRecord)) + ' and ' + ltrim(str(@EndRecord));
Exec(@SqlString)
END --执行
--对UserInfor表进行分页,根据userAge排序,每页4条,求第2页的数据 declare @totalCount int
exec WangNengFenYe 'UserInfor','*','userAge desc','',4,2,@totalCount output;
select @totalCount as '总条数';--总记录数。
三. EFCore调用各种存储过程
这里以EF Core 3.x版本为例,详细参考:
!
- 作 者 : Yaopengfei(姚鹏飞)
- 博客地址 : http://www.cnblogs.com/yaopengfei/
- 声 明1 : 本人才疏学浅,用郭德纲的话说“我是一个小学生”,如有错误,欢迎讨论,请勿谩骂^_^。
- 声 明2 : 原创博客请在转载时保留原文链接或在文章开头加上本人博客地址,否则保留追究法律责任的权利。
11-SQLServer的事务、存储过程和触发器的更多相关文章
- MSSQL 事务,视图,索引,存储过程,触发器
事务 事务是一种机制.是一种操作序列,它包含了一组数据库操作命令,这组命令要么全部执行,要么全部不执行. 在数据库系统上执行并发操作时事务是作为最小的控制单元来使用的.这特别适用于多用户同时操作的数据 ...
- 走向面试之数据库基础:三、SQL进阶之变量、事务、存储过程与触发器
一.变量那点事儿 1.1 局部变量 (1)声明局部变量 DECLARE @变量名 数据类型 ) DECLARE @id int (2)为变量赋值 SET @变量名 =值 --set用于普通的赋值 SE ...
- Sqlserver中存储过程,触发器,自定义函数(二)
Sqlserver中存储过程,触发器,自定义函数: 自定义函数:1.函数类型:2.函数的参数和返回值: 1.函数类型:标量值函数,返回的是一个标量值表值函数:内联表值函数:多语句表值函数. 标量值函数 ...
- Sqlserver中存储过程,触发器,自定义函数(一)
Sqlserver中存储过程,触发器,自定义函数 1.存储过程有关内容存储过程的定义:存储过程的分类:存储过程的创建,修改,执行:存储过程中参数的传递,返回与接收:存储过程的返回值:存储过程使用游标. ...
- Sqlserver中存储过程,触发器,自定义函数
Sqlserver中存储过程,触发器,自定义函数: 1. 触发器:是针对数据库表或数据库的特殊存储过程,在某些行为发生的时候就会被激活 触发器的分类: DML触发器:发生在数据操作语言执行时触发执行的 ...
- 转:SQL进阶之变量、事务、存储过程与触发器
一.变量那点事儿 1.1 局部变量 (1)声明局部变量 DECLARE @变量名 数据类型 DECLARE @name varchar(20) DECLARE @id int (2)为变量赋值 SET ...
- T-SQL应用,视图、存储过程、触发器、游标、临时表等
sqlserver常用操作: 视图.存储过程.触发器.函数 --*********************批处理********************* --[在一个批处理中存有一个语法错误,则所有 ...
- Oracle打怪升级之路二【视图、序列、游标、索引、存储过程、触发器】
前言 在之前 <Oracle打怪升级之路一>中我们主要介绍了Oracle的基础和Oracle常用查询及函数,这篇文章作为补充,主要介绍Oracle的对象,视图.序列.同义词.索引等,以及P ...
- SQL Server CLR 使用 C# 自定义存储过程和触发器
资源来源:https://www.cnblogs.com/Brambling/p/8016060.html SQL Server CLR 使用 C# 自定义存储过程和触发器 这一篇博客接着上一篇博 ...
- SQL Serever学习14——存储过程和触发器
存储过程 在数据库中很多查询都是大同小异,编写他们费时费力,将他们保存起来,以后执行就很方便了,把SQL语句“封装”起来. 存储过程的概念 存储过程是一组SQL语句集,经过编译存储,可以”一次编译,多 ...
随机推荐
- vi编辑光标跳到文件开头和结尾以及清空文件命令
vi编辑光标跳到文件开头和结尾以及清空文件命令 按esc退出编辑模式 跳到文件开头: :1 跳到文件结尾: :$ 清空文件内容: 小写的 d 加上大写的 G
- 自学华为IoT物联网_02 常见物联网通信技术
点击返回自学华为IoT物流网 自学华为IoT物联网_02 常见物联网通信技术 两类技术: 有线通信技术 无线通信技术 一. 有线通信技术 1.1 物联网有线技术介绍及对比 ETH 主要用于支持以太网标 ...
- android 读取EXcel 文件 读取文件内存卡的权限
android 采用Java的读取xls文件的方式实现. 需要导入第三方Jxl.jar 包. 代码改自 其他博主 : 这只摘录下 读取xls文件的部分代码,当然这个代码在安卓平台需要添加下面的权限 ...
- Mysql 允许远程连接
授权的方式允许任何主机访问mysql服务器: mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'password' W ...
- jsp (1)
一.jsp介绍: jsp是servlet的一种包装.是html+js+css+servlet. jsp文件无需配置,如果修改了jsp文件不需要reload应用. jsp访问方法:直接访问文件名.jsp ...
- 如何设计出优秀的Restful API?
https://mp.weixin.qq.com/s?__biz=MzU0OTE4MzYzMw==&mid=2247485240&idx=1&sn=b5b9c8c41659d2 ...
- What can Reactive Streams offer EE4J?
https://developer.lightbend.com/blog/2018-02-06-reactive-streams-ee4j/index.html By James Roper (@jr ...
- 【UR #3】链式反应
http://uoj.ac/problem/50 %炮姐 好博客 树形结构 枚举根节点的儿子是哪两个 然后列出方程: 然后有EGF的影子! 倍增? 泰勒展开可以把未知数从函数里拿出来!并且变成1次项, ...
- Java基本类型占用字节数(或 bit数)
背景:面试时候问到int类型占用几个字节,以及表示的大小,居然一脸懵逼,任何细节都不能放过. Java基本类型占用字节数(或 bit数) java是跨平台的语言,所以不论在什么系统中这些东西在内存中所 ...
- 用宏定义代替printf函数
来自:http://blog.csdn.net/yannanxiu/article/details/52506451 #define _DEBUG_ 1 #if _DEBUG_ #define PR( ...