Python高性能编程
一、进程池和线程池
1.串行
import time
import requests url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] start_time = time.time()
for url in url_lists:
response = requests.get(url)
print(response.text)
print("Runtime: {}".format(time.time()-start_time)) # Runtime: 1.95
2.多进程
import time
import requests
from multiprocessing import Process url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
print(response.text) if __name__ == '__main__':
p_list = []
start_time = time.time()
for url in url_lists:
p = Process(target=task, args=(url,))
p_list.append(p)
p.start()
for p in p_list:
p.join() print("Runtime: {}".format(time.time() - start_time)) # Runtime: 1.91
3.进程池(1)
import time
import requests
from concurrent.futures import ProcessPoolExecutor """
Py2里 没有线程池 但是有进程池
Py3里 有线程池 有进程池
""" url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
print(response.content) if __name__ == '__main__':
start_time = time.time()
pool = ProcessPoolExecutor(10)
for url in url_lists:
pool.submit(task,url)
pool.shutdown(wait=True)
print("Runtime: {}".format(time.time() - start_time)) # Runtime: 2.00
# 进程池 + 回调函数 import time
import requests
from concurrent.futures import ProcessPoolExecutor """
Py2里 没有线程池 但是有进程池
Py3里 有线程池 有进程池
""" url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
return response.content def callback(future):
print(future.result()) if __name__ == '__main__':
start_time = time.time()
pool = ProcessPoolExecutor(10)
for url in url_lists:
v = pool.submit(task,url)
v.add_done_callback(callback)
pool.shutdown(wait=True)
print("Runtime: {}".format(time.time() - start_time))
3.进程池(2)
import time
import requests
from multiprocessing import Pool url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
return response.content
def callBackFunc(content):
print(content) if __name__ == '__main__':
start_time = time.time()
pool = Pool(10)
for url in url_lists:
pool.apply_async(func=task,args=(url,),callback=callBackFunc)
pool.close()
pool.join()
print("Runtime: {}".format(time.time() - start_time)) # Runtime: 1.96
2019-03-06 補充
# Parallel 底层調用的是 multiprocessing import time
from joblib import Parallel, delayed def func(idx):
print(idx)
time.sleep(1)
return {'idx':idx} start_ts = time.time() results = Parallel(-1)(
delayed(func)(x) for x in range(4)
) print(results) print('Runtime : {}'.format(time.time()-start_ts))
4.多线程
import time
import requests
from threading import Thread url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
print(response.text) if __name__ == '__main__':
t_list = []
start_time = time.time()
for url in url_lists:
t = Thread(target=task, args=(url,))
t_list.append(t)
t.start()
for t in t_list:
t.join() print("Runtime: {}".format(time.time() - start_time)) # Runtime: 0.49
5.线程池
import time
import requests
from concurrent.futures import ThreadPoolExecutor """
Py2里 没有线程池 但是有进程池
Py3里 有线程池 有进程池
""" url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
print(response.content) if __name__ == '__main__':
start_time = time.time()
pool = ThreadPoolExecutor(10)
for url in url_lists:
pool.submit(task,url)
pool.shutdown(wait=True)
print("Runtime: {}".format(time.time() - start_time)) # Runtime: 0.51
# 线程池 + 回调函数 import time
import requests
from concurrent.futures import ThreadPoolExecutor """
Py2里 没有线程池 但是有进程池
Py3里 有线程池 有进程池
""" url_lists = [
'http://www.baidu.com',
'http://fanyi.baidu.com',
'http://map.baidu.com',
'http://music.baidu.com/',
'http://tieba.baidu.com',
'http://v.baidu.com',
'http://image.baidu.com',
'http://zhidao.baidu.com',
'http://news.baidu.com',
'http://xueshu.baidu.com'] def task(url):
response = requests.get(url)
return response.content def callback(future):
print(future.result()) if __name__ == '__main__':
start_time = time.time()
pool = ThreadPoolExecutor(10)
for url in url_lists:
v = pool.submit(task,url)
v.add_done_callback(callback)
pool.shutdown(wait=True)
print("Runtime: {}".format(time.time() - start_time))
二、异步非阻塞
参考:http://aiohttp.readthedocs.io/en/stable/
参考:http://www.cnblogs.com/wupeiqi/articles/6229292.html
参考:http://blog.csdn.net/u014595019/article/details/52295642
"""
异步非阻塞/异步IO
非阻塞: 不等待
异步: 回调函数 本质:一个线程完成并发操作(前提是执行过程中一定得有IO,这样才能让线程空闲出来去执行下一个任务)
"""
1.asyncio示例1
import asyncio @asyncio.coroutine
def func1():
print('before...func1......')
yield from asyncio.sleep(2)
print('end...func1......') @asyncio.coroutine
def func2():
print('before...func2......')
yield from asyncio.sleep(1)
print('end...func2......') @asyncio.coroutine
def func3():
print('before...func3......')
yield from asyncio.sleep(3)
print('end...func3......') tasks = [func1(), func2(), func3()] loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*tasks))
loop.close() ### 结果 ###
before...func3......
before...func2......
before...func1......
end...func2......
end...func1......
end...func3......
2.asyncio示例2
####################################################################################
# async/await 是 python3.5中新加入的特性,将异步从原来的yield 写法中解放出来,变得更加直观;
# async 写在def前,替代了装饰器@asyncio.coroutine;await 替换了yield from;
#################################################################################### import asyncio async def func1():
print('before...func1......')
await asyncio.sleep(2)
print('end...func1......') async def func2():
print('before...func2......')
await asyncio.sleep(1)
print('end...func2......') async def func3():
print('before...func3......')
await asyncio.sleep(3)
print('end...func3......') tasks = [func1(), func2(), func3()] loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
3.asyncio示例3
import asyncio @asyncio.coroutine
def fetch_async(host, url='/'):
print(host, url)
reader, writer = yield from asyncio.open_connection(host, 80) request_header_content = """GET %s HTTP/1.0\r\nHost: %s\r\n\r\n""" % (url, host,)
request_header_content = bytes(request_header_content, encoding='utf-8') writer.write(request_header_content)
yield from writer.drain()
text = yield from reader.read()
print(host, url, text)
writer.close() task_list = [
fetch_async('www.cnblogs.com', '/standby/'),
fetch_async('www.cnblogs.com', '/standby/p/7739797.html'),
fetch_async('www.cnblogs.com', '/wupeiqi/articles/6229292.html')
] loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*task_list))
loop.close()
4.asyncio+aiohttp示例1
import asyncio
import aiohttp
import async_timeout async def fetch(session, url):
with async_timeout.timeout(10):
async with session.get(url) as response:
return await response.text() async def fetch_async(url):
async with aiohttp.ClientSession() as session:
html = await fetch(session, url)
print(html) tasks = [
fetch_async('https://api.github.com/events'),
fetch_async('http://aiohttp.readthedocs.io/en/stable/'),
fetch_async('http://aiohttp.readthedocs.io/en/stable/client.html')] event_loop = asyncio.get_event_loop()
results = event_loop.run_until_complete(asyncio.gather(*tasks))
event_loop.close()
或者
import asyncio
import aiohttp
import async_timeout async def fetch_async(url):
async with aiohttp.ClientSession() as session:
with async_timeout.timeout(10):
async with session.get(url) as resp:
print(resp.status)
print(await resp.text()) tasks = [
fetch_async('https://api.github.com/events'),
fetch_async('http://aiohttp.readthedocs.io/en/stable/'),
fetch_async('http://aiohttp.readthedocs.io/en/stable/client.html')] event_loop = asyncio.get_event_loop()
results = event_loop.run_until_complete(asyncio.gather(*tasks))
event_loop.close()
5.asyncio+requests示例
import asyncio
import requests @asyncio.coroutine
def fetch_async(func, *args):
loop = asyncio.get_event_loop()
future = loop.run_in_executor(None, func, *args)
response = yield from future
print(response.url, response.content) tasks = [
fetch_async(requests.get, 'http://aiohttp.readthedocs.io/en/stable/'),
fetch_async(requests.get, 'https://api.github.com/events')
] loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
import time
import asyncio
import requests async def fetch_async(func, *args):
loop = asyncio.get_event_loop()
future = loop.run_in_executor(None, func, *args)
response = await future
print(response.url, response.content) tasks = [
fetch_async(requests.get, 'http://aiohttp.readthedocs.io/en/stable/'),
fetch_async(requests.get, 'https://api.github.com/events')
] loop = asyncio.get_event_loop()
results = loop.run_until_complete(asyncio.gather(*tasks))
loop.close()
async/await
补充:
有时候会遇到 RuntimeError: Event loop is closed 这个错误
参考:https://stackoverflow.com/questions/45600579/asyncio-event-loop-is-closed 在 fetch_async 函数里添加一下语句即可
asyncio.set_event_loop(asyncio.new_event_loop())
6.gevent+requests示例
import gevent
import requests
from gevent import monkey
from gevent.pool import Pool
monkey.patch_all() def fetch_async(method, url, req_kwargs):
print(method, url, req_kwargs)
response = requests.request(method=method, url=url, **req_kwargs)
print(response.url, response.content) # ##### 发送请求 #####
# gevent.joinall([
# gevent.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}),
# gevent.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}),
# gevent.spawn(fetch_async, method='get', url='https://github.com/', req_kwargs={}),
# gevent.spawn(fetch_async, method='get', url='https://api.github.com/events', req_kwargs={}),
# ]) # ##### 发送请求(协程池控制最大协程数量) #####
# pool = Pool(None)
pool = Pool(3)
gevent.joinall([
pool.spawn(fetch_async, method='get', url='https://www.python.org/', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://www.yahoo.com/', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://www.github.com/', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://api.github.com/events', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://www.baidu.com', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://www.ibm.com', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://www.intel.com', req_kwargs={}),
pool.spawn(fetch_async, method='get', url='https://www.iqiyi.com', req_kwargs={}),
])
使用gevent协程并获取返回值示例:
def get_single_chart_data_flux(single_data_param):
import gevent
from gevent import monkey
from gevent.pool import Pool as gPool
monkey.patch_socket()
ip,port,timestamp,time_length,type_name,subtype_name,filter_str_list,appid,legend = single_data_param
ModelClass = get_model_class(type_name)
func = apps.get_app_config('serverdata').service.get_single_chart_data
pool = gPool(len(filter_str_list))
func_li = []
for filter_str in filter_str_list:
func_li.append(pool.spawn(func,ModelClass,ip,port,timestamp,time_length,subtype_name,filter_str,appid,legend))
ret_li = gevent.joinall(func_li)
# view_logger.debug(ret_li[0].get('value'))
result_li = [{'filter_con':item.get('value')[2], 'value':item.get('value')[1], 'legend':item.get('value')[3]} for item in ret_li]
return result_li
7.Twisted示例
from twisted.web.client import getPage, defer
from twisted.internet import reactor def all_done(arg):
reactor.stop() def callback(contents,url):
print(url,contents) deferred_list = [] url_list = [
'http://www.bing.com',
'http://www.baidu.com',
'https://www.python.org',
'https://www.yahoo.com',
'https://www.github.com'
]
start_time = time.time()
for url in url_list:
deferred = getPage(bytes(url, encoding='utf8'))
deferred.addCallback(callback,url)
deferred_list.append(deferred) dlist = defer.DeferredList(deferred_list)
dlist.addBoth(all_done) reactor.run()
8.Tornado示例
以上均是Python内置以及第三方模块提供异步IO请求模块,使用简便大大提高效率;
而对于异步IO请求的本质则是【非阻塞Socket】+【IO多路复用】
三、自定义异步非阻塞模块
1.简单示例
"""
异步非阻塞/异步IO
非阻塞: 不等待
异步: 回调函数 本质:一个线程完成并发操作(前提是执行过程中一定得有IO,这样才能让线程空闲出来去执行下一个任务) IO 多路复用 + socket
- IO多路复用: select epoll 用于检测socket对象是否发生变化(是否连接成功,是否有数据到来)
- socket : socket客户端 - IO请求是不占用CPU的,计算型的才占用CPU
""" import socket
import select conn_list = []
input_list = [] for url in range(20):
client = socket.socket()
client.setblocking(False)
try:
client.connect(('61.135.169.121',80))
except BlockingIOError as e:
pass
conn_list.append(client)
input_list.append(client) while True:
rlist, wlist, errlist = select.select(input_list, conn_list, [], 0.05)
for sock in wlist:
sock.sendall(b"GET / HTTP/1.0\r\nHost: www.baidu.com\r\n\r\n")
conn_list.remove(sock)
for sock in rlist:
data = sock.recv(8192)
sock.close()
input_list.remove(sock)
print(data)
if not input_list:
break
2.自定义异步非阻塞模块
#!/usr/bin/python3.5
# -*- coding:utf-8 -*- """
异步非阻塞/异步IO
非阻塞: 不等待
异步: 回调函数 本质:一个线程完成并发操作(前提是执行过程中一定得有IO,这样才能让线程空闲出来去执行下一个任务) IO 多路复用 + socket
- IO多路复用: select epoll 用于检测socket对象是否发生变化(是否连接成功,是否有数据到来)
- socket : socket客户端 - IO请求是不占用CPU的,计算型的才占用CPU
""" import socket
import select
from urllib import parse class Request():
def __init__(self,sock,url,callback):
"""
初始化
:param sock: client's socket
:param callback: callback function
:param url: page url which wanna crawling
"""
self.sock = sock
self.url = url
self.callback = callback def fileno(self):
return self.sock.fileno()
@property
def host(self):
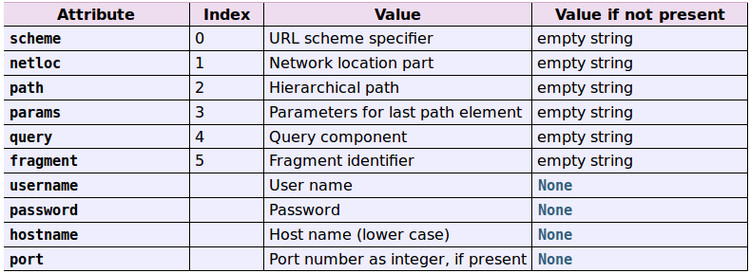
domain = parse.urlparse(self.url)
return domain.netloc
@property
def pathinfo(self):
domain = parse.urlparse(self.url)
return domain.path def async_request(url_list):
conn_list = []
input_list = []
for li in url_list:
sock = socket.socket()
sock.setblocking(False)
obj = Request(sock, li[0], li[1])
try:
sock.connect((obj.host,80))
except BlockingIOError as e:
pass
conn_list.append(obj)
input_list.append(obj) while True:
# 监听socket是否已经发生变化 [request_obj,request_obj....request_obj]
# 如果有请求连接成功:wlist = [request_obj,request_obj]
# 如果有响应的数据: rlist = [request_obj,request_obj....client100]
rlist, wlist, errlist = select.select(input_list, conn_list, [], 0.05)
for obj in wlist:
# print("链接成功,发送请求...")
# obj.sock.sendall("GET {0} HTTP/1.0\r\nHost: {1}\r\n\r\n".format(obj.pathinfo,obj.host).encode('utf-8'))
obj.sock.sendall(bytes("GET {0} HTTP/1.0\r\nHost: {1}\r\n\r\n".format(obj.pathinfo,obj.host),encoding='utf-8'))
conn_list.remove(obj)
for obj in rlist:
# print("获取响应...")
data = obj.sock.recv(8192)
obj.callback(data)
obj.sock.close()
input_list.remove(obj)
if not input_list:
break if __name__ == '__main__':
def callback1(data):
print("cnblogs...", data)
def callback2(data):
print("csdn...", data)
def callback3(data):
print("tornadoweb...", data) url_list = [
['http://www.cnblogs.com/standby/p/7589055.html', callback1],
['http://www.cnblogs.com/wupeiqi/articles/6229292.html', callback1],
['http://blog.csdn.net/vip_wangsai/article/details/51997882', callback2],
['http://blog.csdn.net/hjhmpl123/article/details/53378068', callback2],
['http://blog.csdn.net/zcc_0015/article/details/50688145', callback2],
['http://www.tornadoweb.org/en/stable/guide.html', callback3],
['http://www.tornadoweb.org/en/stable/guide/async.html', callback3],
['http://www.tornadoweb.org/en/stable/guide/coroutines.html#python-3-5-async-and-await', callback3]
] async_request(url_list)
3.牛逼的异步IO模块
import select
import socket
import time class AsyncTimeoutException(TimeoutError):
"""
请求超时异常类
""" def __init__(self, msg):
self.msg = msg
super(AsyncTimeoutException, self).__init__(msg) class HttpContext(object):
"""封装请求和相应的基本数据""" def __init__(self, sock, host, port, method, url, data, callback, timeout=5):
"""
sock: 请求的客户端socket对象
host: 请求的主机名
port: 请求的端口
port: 请求的端口
method: 请求方式
url: 请求的URL
data: 请求时请求体中的数据
callback: 请求完成后的回调函数
timeout: 请求的超时时间
"""
self.sock = sock
self.callback = callback
self.host = host
self.port = port
self.method = method
self.url = url
self.data = data self.timeout = timeout self.__start_time = time.time()
self.__buffer = [] def is_timeout(self):
"""当前请求是否已经超时"""
current_time = time.time()
if (self.__start_time + self.timeout) < current_time:
return True def fileno(self):
"""请求sockect对象的文件描述符,用于select监听"""
return self.sock.fileno() def write(self, data):
"""在buffer中写入响应内容"""
self.__buffer.append(data) def finish(self, exc=None):
"""在buffer中写入响应内容完成,执行请求的回调函数"""
if not exc:
response = b''.join(self.__buffer)
self.callback(self, response, exc)
else:
self.callback(self, None, exc) def send_request_data(self):
content = """%s %s HTTP/1.0\r\nHost: %s\r\n\r\n%s""" % (
self.method.upper(), self.url, self.host, self.data,) return content.encode(encoding='utf8') class AsyncRequest(object):
def __init__(self):
self.fds = []
self.connections = [] def add_request(self, host, port, method, url, data, callback, timeout):
"""创建一个要请求"""
client = socket.socket()
client.setblocking(False)
try:
client.connect((host, port))
except BlockingIOError as e:
pass
# print('已经向远程发送连接的请求')
req = HttpContext(client, host, port, method, url, data, callback, timeout)
self.connections.append(req)
self.fds.append(req) def check_conn_timeout(self):
"""检查所有的请求,是否有已经连接超时,如果有则终止"""
timeout_list = []
for context in self.connections:
if context.is_timeout():
timeout_list.append(context)
for context in timeout_list:
context.finish(AsyncTimeoutException('请求超时'))
self.fds.remove(context)
self.connections.remove(context) def running(self):
"""事件循环,用于检测请求的socket是否已经就绪,从而执行相关操作"""
while True:
r, w, e = select.select(self.fds, self.connections, self.fds, 0.05) if not self.fds:
return for context in r:
sock = context.sock
while True:
try:
data = sock.recv(8096)
if not data:
self.fds.remove(context)
context.finish()
break
else:
context.write(data)
except BlockingIOError as e:
break
except TimeoutError as e:
self.fds.remove(context)
self.connections.remove(context)
context.finish(e)
break for context in w:
# 已经连接成功远程服务器,开始向远程发送请求数据
if context in self.fds:
data = context.send_request_data()
context.sock.sendall(data)
self.connections.remove(context) self.check_conn_timeout() if __name__ == '__main__':
def callback_func(context, response, ex):
"""
:param context: HttpContext对象,内部封装了请求相关信息
:param response: 请求响应内容
:param ex: 是否出现异常(如果有异常则值为异常对象;否则值为None)
:return:
"""
print(context, response, ex) obj = AsyncRequest()
url_list = [
{'host': 'www.google.com', 'port': 80, 'method': 'GET', 'url': '/', 'data': '', 'timeout': 5,
'callback': callback_func},
{'host': 'www.baidu.com', 'port': 80, 'method': 'GET', 'url': '/', 'data': '', 'timeout': 5,
'callback': callback_func},
{'host': 'www.bing.com', 'port': 80, 'method': 'GET', 'url': '/', 'data': '', 'timeout': 5,
'callback': callback_func},
]
for item in url_list:
print(item)
obj.add_request(**item) obj.running()
Python高性能编程的更多相关文章
- Python猫荐书系列之五:Python高性能编程
稍微关心编程语言的使用趋势的人都知道,最近几年,国内最火的两种语言非 Python 与 Go 莫属,于是,隔三差五就会有人问:这两种语言谁更厉害/好找工作/高工资…… 对于编程语言的争论,就是猿界的生 ...
- 《Python高性能编程》——列表、元组、集合、字典特性及创建过程
这里的内容仅仅是本人阅读<Python高性能编程>后总结的一些知识,用于自己更好的了解Python机制.本人现在并不从事计算密集型工作:人工智能.数据分析等.仅仅只是出于好奇而去阅读这本书 ...
- 进阶《Python高性能编程》中文PDF+英文PDF+源代码
入门使用高性能 Python,建议参考<Python高性能编程>,例子给的很多,讲到高性能就会提到性能监控,里面有cpu mem 方法的度量,网络讲了一点异步,net profiler 没 ...
- python高性能编程方法一
python高性能编程方法一 阅读 Zen of Python,在Python解析器中输入 import this. 一个犀利的Python新手可能会注意到"解析"一词, 认为 ...
- python高性能编程方法一-乾颐堂
阅读 Zen of Python,在Python解析器中输入 import this. 一个犀利的Python新手可能会注意到"解析"一词, 认为Python不过是另一门脚本语言. ...
- python高性能编程 读书笔记
GIL 确保 Python 进程一次只能执行一条指令 ====分析工具cProfile 分析函数耗时line_profiler 逐行分析 heapy 追踪 Python 内存中所有的对象— 这对于消 ...
- python核心编程第二版笔记
python核心编程第二版笔记由网友提供:open168 python核心编程--笔记(很详细,建议收藏) 解释器options:1.1 –d 提供调试输出1.2 –O 生成优化的字节码(生成 ...
- python核心编程--笔记
python核心编程--笔记 的解释器options: 1.1 –d 提供调试输出 1.2 –O 生成优化的字节码(生成.pyo文件) 1.3 –S 不导入site模块以在启动时查找pyt ...
- Python高级编程和异步IO并发编程
第1章 课程简介介绍如何配置系统的开发环境以及如何加入github私人仓库获取最新源码. 1-1 导学 试看 1-2 开发环境配置 1-3 资源获取方式第2章 python中一切皆对象本章节首先对比静 ...
随机推荐
- vsftpd 安装与配置
下载安装vsftpd服务,db4用来支持文件数据库yum install -y vsftpd db4-utils ftp 建立宿主用户 vsftpduseradd -s /sbin/nologin - ...
- shell 中的 ${} 、## 、%% 使用范例
日常使用范例见如下例子: 利用 ${ } 还可针对不同的变数状态赋值 (沒设定.空值.非空值): ${file-my.file.txt} :假如 $file 沒有设定,則使用 my.file.txt ...
- Bug预防体系(上千bug分析后总结的最佳实践)
Bug预防体系(上千bug分析后总结的最佳实践) 原创 2017-08-16俞美玲 光荣之路 吴老的<selenium webdriver 实战宝典>出版了! web常见产品问题及预防 ...
- Bomb HDU - 5934 (Tarjan)
#include<map> #include<set> #include<ctime> #include<cmath> #include<stac ...
- [APIO2008]免费道路(生成树)
新亚(New Asia)王国有 N 个村庄,由 M 条道路连接.其中一些道路是鹅卵石路,而其它道路是水泥路.保持道路免费运行需要一大笔费用,并且看上去 王国不可能保持所有道路免费.为此亟待制定一个新的 ...
- NOIP2011Mayan游戏(模拟)
Mayan puzzle是最近流行起来的一个游戏.游戏界面是一个77 行\times 5×5列的棋盘,上面堆放着一些方块,方块不能悬空堆放,即方块必须放在最下面一行,或者放在其他方块之上.游戏通关是指 ...
- 【php】php实现数组分块
有时候需要将一个大数组按一定大小分块,那么可以实现这个功能,代码如下: /** * @param array $arr * @param int $size <p> * @param bo ...
- Java 多个文件压缩下载
有时候会有多个附件一起下载的需求,这个时候最好就是打包下载了 首先下面这段代码是正常的单个下载 public void Download(@RequestParam("file_path&q ...
- Codeforces Round #523 (Div. 2) D. TV Shows
传送门 https://www.cnblogs.com/violet-acmer/p/10005351.html 题意: 有n个节目,每个节目都有个开始时间和结束时间. 定义x,y分别为租电视需要的花 ...
- nginx搭建分布式简单配置
1.下载安装nginx 2.编辑nginx.conf文件 upstream 172.100.10.52 { ip_hash; #保证每一个用户访问同一个网站 server 172.100.10.21: ...