day9文件操作---从即日起时景丽阳老师给我们讲课
os.walk()递归获取文件,深度优先查找
path = "D:\lmj_work_file\标注数据\Annotation\im"
def get_inner_files(arg):
count_round =
for root, dirs, files in os.walk(arg):
# print("root>>", root, type(root)) # 这里打印的是根目录,因为是递归查找文件夹,所以每次循环的根目录不一样
# print("dirs>>", dirs, type(dirs)) # 这里打印的是root下面的文件目录名称,仅限一级目录下的文件夹名称,返回值是列表
print("list iterable files>>", [os.path.join(root, name)for name in files], "\n") # 打印当前文件路径
print("files>>", files, type(files), "\n") # root下的文件名,返回值是列表
# for i in dirs:
# print("each dir>>>", i)
count_round += 1 # 循环的次数,由嵌套的层级决定。
print(count_round) get_inner_files(path)
执行结果如下:

list iterable files>> ['D:\\lmj_work_file\\标注数据\\Annotation\\im\\15311153701.xml', 'D:\\lmj_work_file\\标注数据\\Annotation\\im\\_1A_2_20170615124904411I.xml'] files>> ['15311153701.xml', '_1A_2_20170615124904411I.xml'] <class 'list'> list iterable files>> ['D:\\lmj_work_file\\标注数据\\Annotation\\im\\新建文件夹\\_1A_1_20170523210544357I.xml'] files>> ['_1A_1_20170523210544357I.xml'] <class 'list'> list iterable files>> ['D:\\lmj_work_file\\标注数据\\Annotation\\im\\新建文件夹\\inner_two\\_1A_2_20170518113348657I.xml'] files>> ['_1A_2_20170518113348657I.xml'] <class 'list'> list iterable files>> ['D:\\lmj_work_file\\标注数据\\Annotation\\im\\新建文件夹\\inner_two\\inner_three\\_1A_2_20170616123652362I.xml'] files>> ['_1A_2_20170616123652362I.xml'] <class 'list'> list iterable files>> ['D:\\lmj_work_file\\标注数据\\Annotation\\im\\新建文件夹 (2)\\_1A_1_20170621180306149I.xml'] files>> ['_1A_1_20170621180306149I.xml'] <class 'list'> 5
先在“新建文件夹”下一层一层找下去,找完之后再返回到根目录下找下一个分支,循环的层数跟文件夹数量保持一致。
文件的操作,读,写,只读只写,或者可读同时可写,追加写,以二进制的方式读,以二进制的方式写,以二进制的方式追加。
思维导图:
给你一个文件路径,从中找出所有的文件,方法如下:

# 方法一:(面试要求不使用os.walk)
def print_directory_contents(sPath):
import os for sChild in os.listdir(sPath):
sChildPath = os.path.join(sPath, sChild)
if os.path.isdir(sChildPath):
print_directory_contents(sChildPath)
else:
print(sChildPath) # 方法二:(使用os.walk)
def print_directory_contents(sPath):
import os
for root, _, filenames in os.walk(sPath):
for filename in filenames:
print(os.path.abspath(os.path.join(root, filename))) print_directory_contents('.')
老师的笔记:
内存 存不长久
硬盘 数据储存的持久化
文件操作 —— 数据持久化储存的一种
全栈开发:框架类 初识文件操作:
#找到文件
#打开文件
#操作:读 写
#关闭
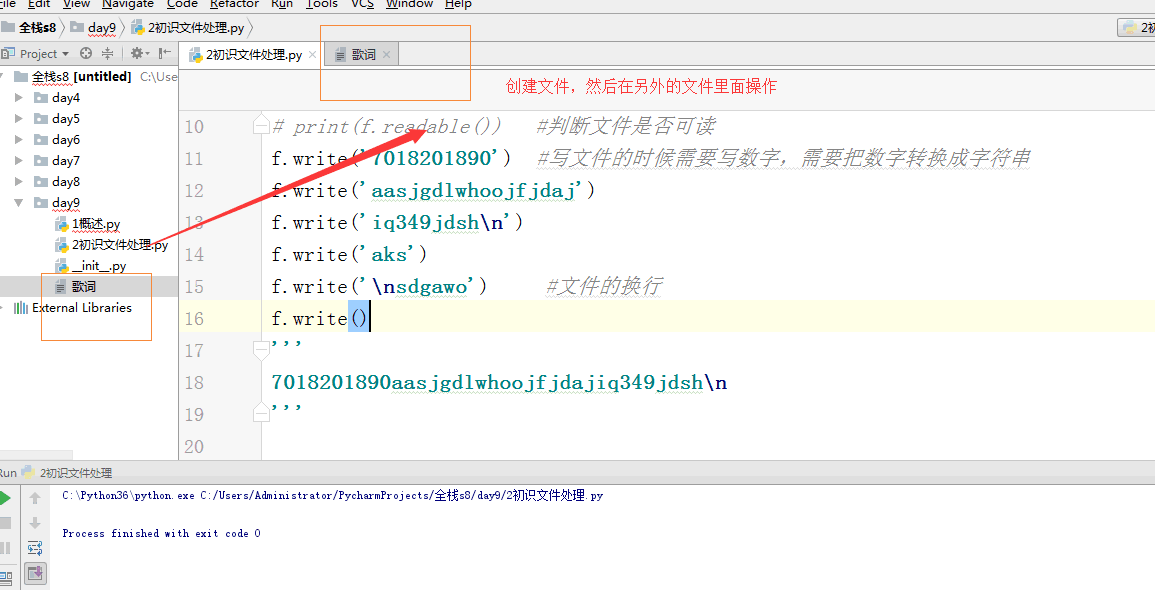
f = open('歌词','w',encoding='utf-8') #f:文件操作符 文件句柄 文件操作对象
f.write('')
f.close()
#open打开文件是依赖了操作系统的提供的途径
#操作系统有自己的编码,open在打开文件的时候默认使用操作系统的编码
#win gbk mac/linux utf-8 #习惯叫 f file f_obj f_handler fh
# print(f.writable()) #判断文件是否可写
# print(f.readable()) #判断文件是否可读
# f.write('7018201890') #写文件的时候需要写数字,需要把数字转换成字符串
# f.write('aasjgdlwhoojfjdaj')
# f.write('iq349jdsh\n')
# f.write('aks')
# f.write('\nsdgawo') #文件的换行
# f.write('志强德胜') #utf-8 unicode gbk
f.close() #找到文件详解:文件与py的执行文件在相同路径下,直接用文件的名字就可以打开文件
#文件与py的执行文件不在相同路径下,用绝对路径找到文件
#文件的路径,需要用取消转译的方式来表示:1.\\ 2.r''
#如果以写文件的方式打开一个文件,那么不存在的文件会被创建,存在的文件之前的内容会被清空
' \\n'
f = open(r'C:\Users\Administrator\Desktop\s8_tmp.txt','w',encoding='utf-8') #文件路径、操作模式、编码
f.write('哈哈哈')
f.close() #关闭文件详解
#打开文件
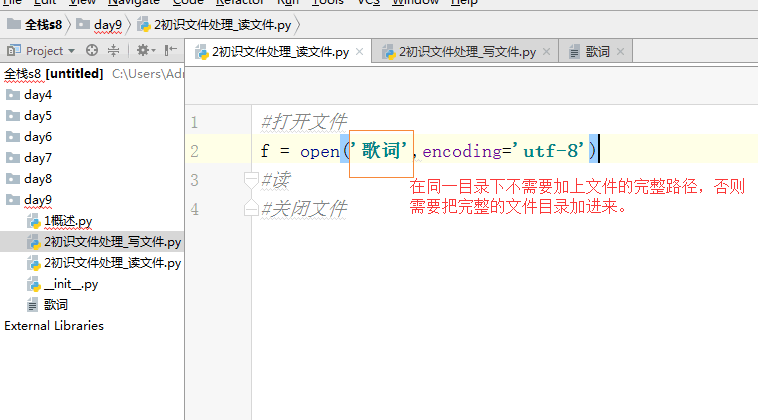
# f = open('歌词','r',encoding='utf-8')
f = open('歌词',encoding='utf-8')
#1.读文件的第一种方式:read方法,用read方法会一次性的读出文件中的所有内容
# content = f.read()
# print('read : ',content)
#2.读一部分内容:read(n),指定读n个单位
# print(f.read(5)) #3.读文件的第三种方式:按照行读,每次执行readline就会往下读一行
# content = f.readline() # print('readline : ',content.strip()) #strip去掉空格、制表符、换行符
# content2 = f.readline()
# print(content2.strip()) # print(1) #--> 1\n
# print('1\n') #--> 1\n\n #4.读文件的第四种方式:readlines,返回一个列表,将文件中的每一行作为列表中的每一项返回一个列表
# content = f.readlines()
# print('readlines : ',content) #5.读:最常用
for l in f:
print(l.strip()) #关闭文件
f.close()
课堂练习:此练习只有后半部分,前半部分需要创建一个文件,里面要存储一些内容,然后用这个练习的方法把内容打印出来,按照一定的格式的方式。
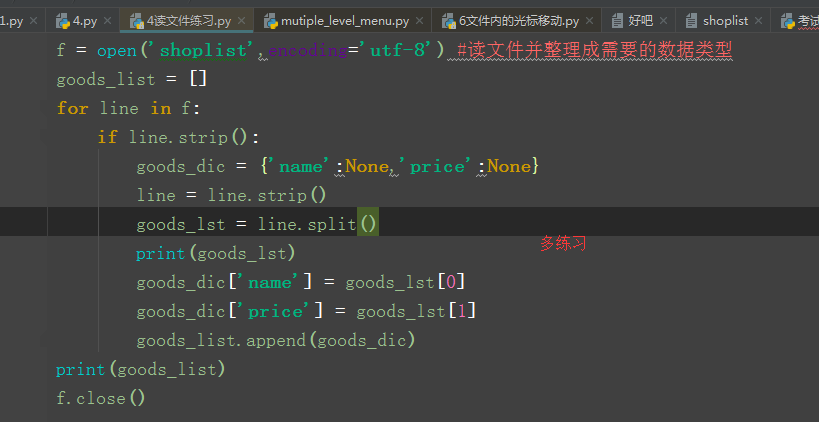
f = open('shoplist',encoding='utf-8') #读文件并整理成需要的数据类型
goods_list = []
for line in f:
if line.strip():
goods_dic = {'name':None,'price':None}
line = line.strip()
goods_lst = line.split()
print(goods_lst)
goods_dic['name'] = goods_lst[0]
goods_dic['price'] = goods_lst[1]
goods_list.append(goods_dic)
print(goods_list)
f.close()
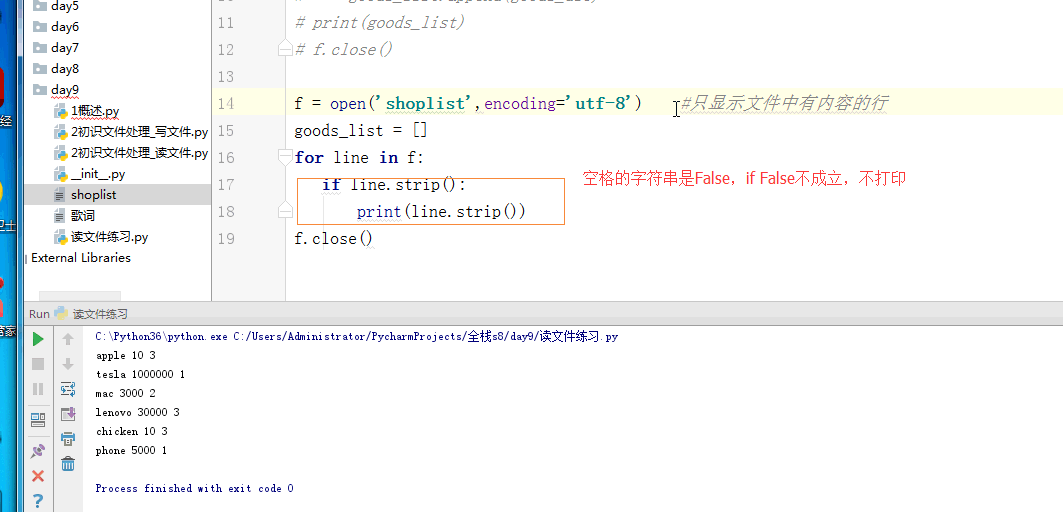
f = open('shoplist',encoding='utf-8') #只显示文件中有内容的行
goods_list = []
for line in f:
if line.strip():
print(line.strip())
f.close()
打开文件的方式:
# f = open('歌词','rb')
# f.close()
#b:图片、音乐、视频等任何文件
#传输:上传、下载
#网络编程:
#修改文件的编码——非常不重要,不重要程度五颗星
#utf-8 用utf8的方式打开一个文件
#读文件里的内容str
#将读出来的内容转换成gbk
#以gbk的方式打开另一个文件
#写入
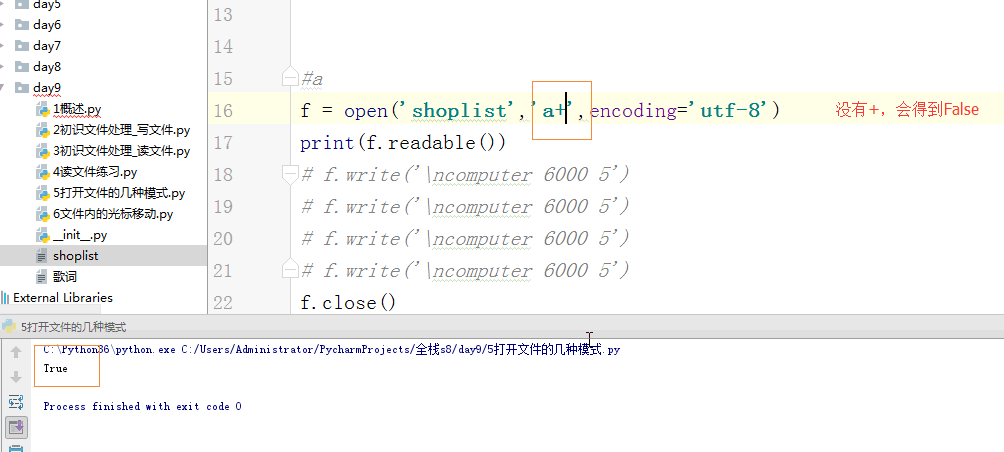
#a+
# f = open('shoplist','a+',encoding='utf-8')
# print(f.readable())
# f.write('\ncomputer 6000 5')
# f.write('\ncomputer 6000 5')
# f.write('\ncomputer 6000 5')
# f.write('\ncomputer 6000 5')
# f.close()
#1.被动接受知识 - 主动提出问题
#2.主动的找到问题,并且找到对应的解决方法
#3.主动的学习
# r+ 可读可写:
#1.先读后写:写是追写
#2.先写后读:从头开始写
# f = open('歌词','r+',encoding='utf-8')
# # line = f.readline()
# # print(line)
# f.write('0000')
# f.close()
# w+ 可写可读:一上来文件就清空了,
# 尽管可读:1.但是你读出来的内容是你这次打开文件新写入的
# 2.光标在最后,需要主动移动光标才可读
# f = open('歌词','w+',encoding='utf-8')
# f.write('abc\n')
# f.write('及哈哈哈')
# f.seek(0)
# print(f.read())
# f.close()
# a+ 追加可读
# f = open('歌词','a+',encoding='utf-8')
# f.write('\nqq星')
# f.seek(0)
# print(f.read())
# f.close()
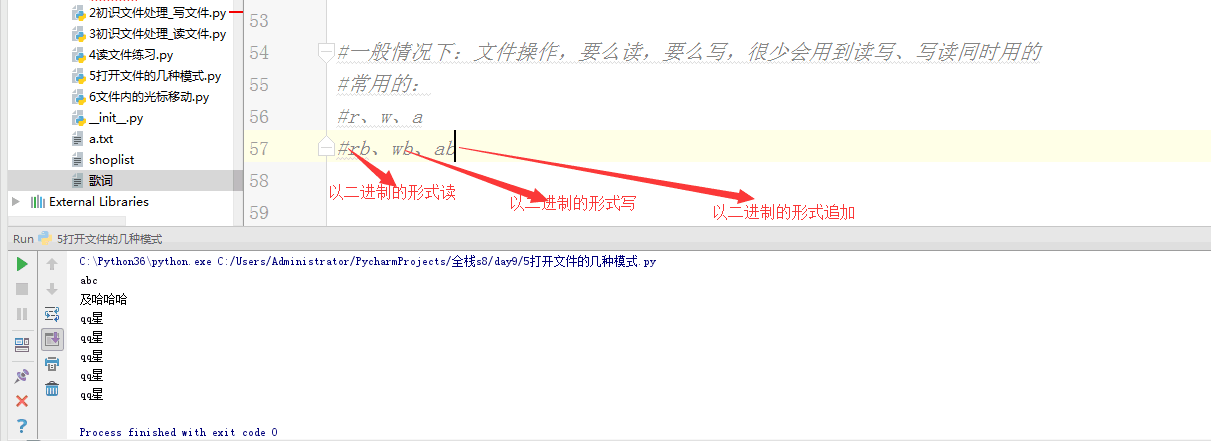
#一般情况下:文件操作,要么读,要么写,很少会用到读写、写读同时用的
#常用的:
#r、w、a
#rb、wb、ab,不需要指定编码了
f = open('歌词','rb')
content = f.read()
f.close()
print(content)
f2 = open('歌词2','wb')
f2.write(content)
f2.close()
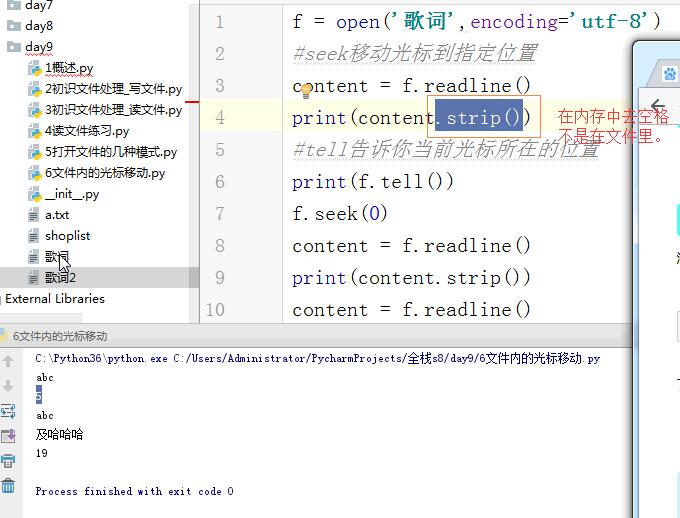
文件内的光标操作:
f = open('歌词','r+',encoding='utf-8')
#seek 光标移动到第几个字节的位置
# f.seek(0) 移动到最开始
# f.seek(0,2) 移动到最末尾
f.truncate(3) #从文件开始的位置只保留指定字节的内容
# f.write('我可写了啊')
#tell 告诉我光标在第几个字节
#seek移动光标到指定位置
# content = f.readline()
# print(content.strip())
#tell告诉你当前光标所在的位置
# print(f.tell())
# f.seek(4) #光标移动到三个字节的地方‘\r\n’
# content = f.read(1) #读一个字符
# print('***',content,'***')
# content = f.readline()
# print(content.strip())
# print(f.tell())
f.close()
#tell
#seek:去最开始、去最结尾
#truncate:保留n个字节
#文件的修改
#文件的删除
#购物车的商品都写在文件里,完成文件的解析之后再写购物车作业
如下是课堂内容的截图:


 绝对路径就是文件的保存路径,查找方法就是点击该文件然后点击右键,点击属性即可查到。
绝对路径就是文件的保存路径,查找方法就是点击该文件然后点击右键,点击属性即可查到。

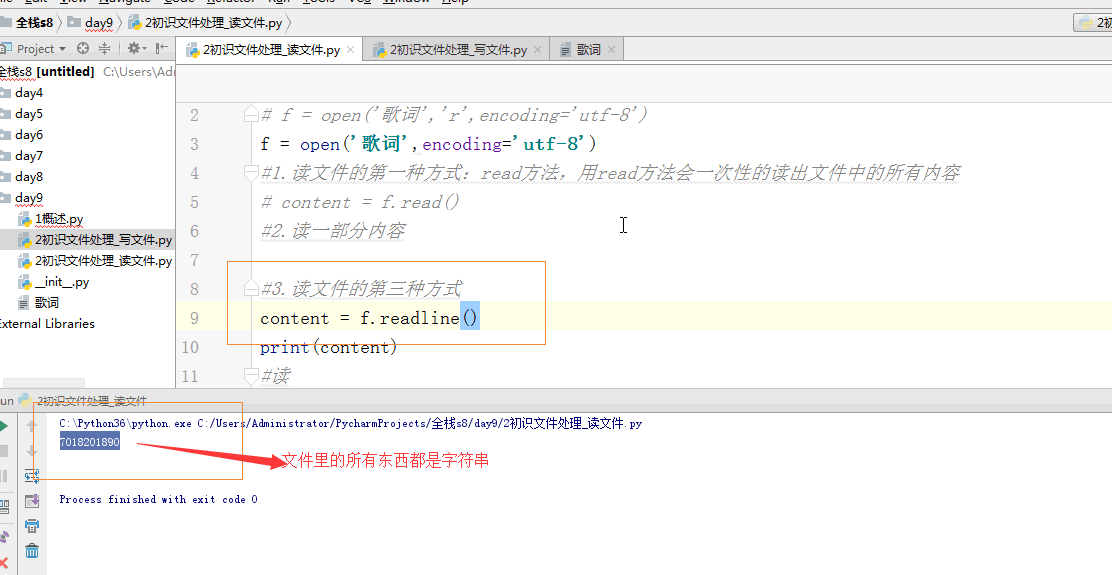

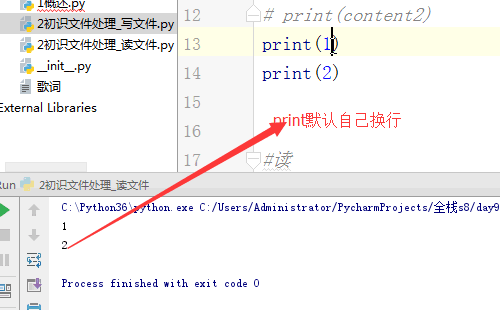
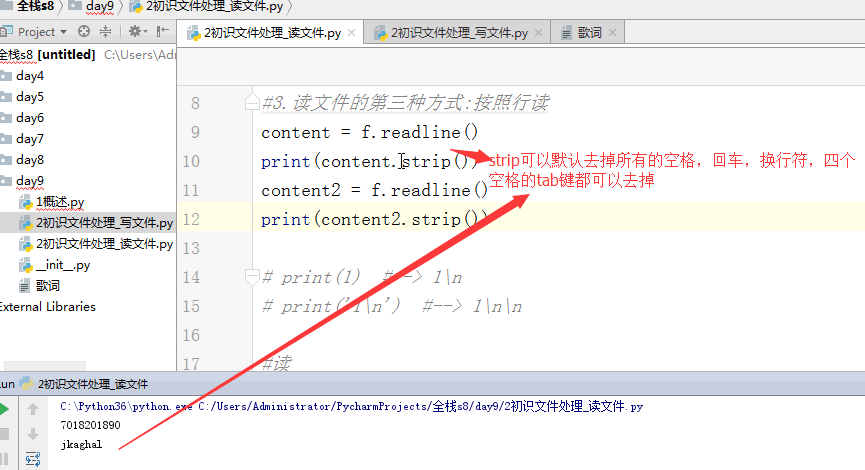


一个\n回车键占两个单位,一个单位是一个字符
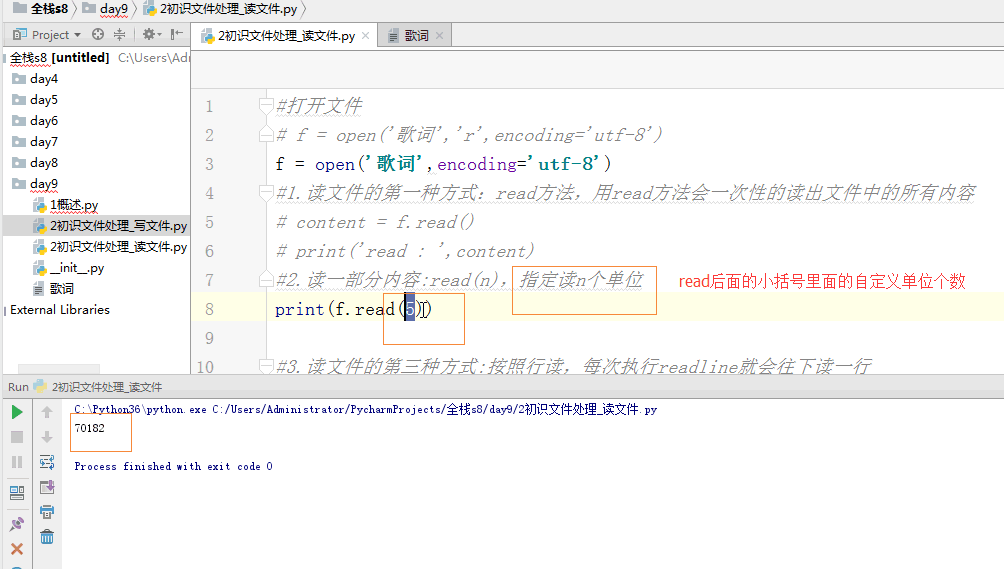


f=open('shoplist',encoding'utf-8')这一句中没有r,也没有w,因为如果不写‘r,w’默认就是‘读’
下图中的if line.strip():这句话翻译过来就是:line.strip()如果字符串就是空的,那么就等于False,if False是不成立的,不会打印。如果文件中有空格的时候这句话的作用就是遇到空格直接掠过,不读取该空格。






day9文件操作---从即日起时景丽阳老师给我们讲课的更多相关文章
- 【学习笔记】--- 老男孩学Python,day9, 文件操作
有 + 就是有光标,注意光标位置 不同模式打开文件的完全列表: http://www.runoob.com/python/python-files-io.html 模式 描述 r 以只读方式打开文件 ...
- day9 python之文件操作
1.文件操作 1.1 基本模式 # 格式 f = open("相对路径/绝对路径",mode = "模式",encoding = "编码级" ...
- day9笔记--文件操作
文件操作 计算机系统分为:计算机硬件,操作系统,应用程序三部分. 我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用 ...
- 013.Python的文件操作
一 文件操作 fp = open("打开的文件",mode="模式选择",encoding="编码集") open 函数 返回一个文件io对 ...
- UWP开发之Template10实践:本地文件与照相机文件操作的MVVM实例(图文付原代码)
前面[UWP开发之Mvvmlight实践五:SuspensionManager中断挂起以及复原处理]章节已经提到过Template10,为了认识MvvmLight的区别特做了此实例. 原代码地址:ht ...
- 【.NET深呼吸】Zip文件操作(1):创建和读取zip文档
.net的IO操作支持对zip文件的创建.读写和更新.使用起来也比较简单,.net的一向作风,东西都准备好了,至于如何使用,请看着办. 要对zip文件进行操作,主要用到以下三个类: 1.ZipFile ...
- Node基础篇(文件操作)
文件操作 相关模块 Node内核提供了很多与文件操作相关的模块,每个模块都提供了一些最基本的操作API,在NPM中也有社区提供的功能包 fs: 基础的文件操作 API path: 提供和路径相关的操作 ...
- SQL Server附加数据库报错:无法打开物理文件,操作系统错误5
问题描述: 附加数据时,提示无法打开物理文件,操作系统错误5.如下图: 问题原因:可能是文件访问权限方面的问题. 解决方案:找到数据库的mdf和ldf文件,赋予权限即可.如下图: 找到mdf ...
- 通过cmd完成FTP上传文件操作
一直使用 FileZilla 这个工具进行相关的 FTP 操作,而在某一次版本升级之后,发现不太好用了,连接老是掉,再后来完全连接不上去. 改用了一段时间的 Web 版的 FTP 工具,后来那个页面也 ...
随机推荐
- 利用zxing生成二维码
使用zxing类库可以很容易生成二维码QRCode,主要代码如下: private Bitmap createQRCode(String str,int width,int height) { Bit ...
- C# 封装微信的模板消息
1.先新建一个类库,以方便以后移植到其他的项目上继续使用,如何新建类库就自己去百度了哈,这里就不描述了,若有不会的朋友请留言哈.标红了的都要注意下咯. 2.先看看WxTemplate这个类文件的代码 ...
- oracle 的sqlplus 工具进行翻译的rlwrap 安装教程
一:下载地址: 链接: https://share.weiyun.com/50R5pBb (密码:dQPc) 或者该QQ群下载: 二:该工具的安装步骤: [oracle@localhost ~]$ l ...
- nginx实践(五)之代理服务(正向代理与反向代理介绍)
正向代理 正向代理代理是为客户端服务,代理负责DNS解析域名到对应ip,并进行访问服务端,返回响应给客户端 反向代理 客户端自己负责请求DNS解析域名到对应ip,服务端通过代理分发流量,进行负载均衡 ...
- linux之cp命令(转载)
Linux中使用cp命令复制文件(夹),本文就日常工作中常用的cp命令整理如下. 一.复制一个源文件到目标文件(夹). 命令格式为:cp 源文件 目标文件(夹) 这个是使用频率最多的命令,负责把一个源 ...
- ActiveMQ消息的发送原理
持久化消息和非持久化消息的发送策略:消息同步发送和异步发送 ActiveMQ支持同步.异步两种发送模式将消息发送到broker上.同步发送过程中,发送者发送一条消息会阻塞直到broker反馈一个确认消 ...
- 水果(map的嵌套)
夏天来了~~好开心啊,呵呵,好多好多水果~~ Joe经营着一个不大的水果店.他认为生存之道就是经营最受顾客欢迎的水果.现在他想要一份水果销售情况的明细表,这样Joe就可以很容易掌握所有水果的销售情况了 ...
- 添加按钮 table增加一行 删减按钮 table去掉一行
需求描述:做的一个AA新增功能,同时可以为这个即将新增的AA添加内容,而且AA的内容默认展示一行列表,点击添加按钮后出现下一行列表 解决思路:页面首先展示一个表头和列表的一行,作为默认展示的一行列表, ...
- PDF如何去除背景,PDF去除背景颜色
PDF文件在使用的时候大多都是单调的白色背景,但是也有小伙伴再制作PDF文件的时候会给PDF文件添加背景颜色,会有影响文字阅读的情况,这个时候就需要把背景颜色去除了,那么该怎么做呢,不会的小伙们就跟小 ...
- JumpServer里的sftp功能报错说明
JumpServer里sftp默认的家目录是/tmp下 修改默认家目录: vim /usr/local/coco/coco/sftp.py class SFTPServer(paramiko.SFTP ...